前言
Dreambooth 官方 Github 的 Readme 文档上有着非常详细的文字说明与视频教程,是学习 Dreambooth 炼丹的最佳资料之一,讲解了包括训练集训练轮数Epochs 、同时处理的图片数 Batch Size 、学习率 Learning Rate 等核心超参数在内的各种参数设置与调整建议。
接下来我将结合自己的理解,靠着 GPT4、NewBing 的帮助和大家一起修炼这份炼丹术进阶教程,踏上这炼丹修仙长生之路!

这是Shivam Shriao的Diffusers Repo的一个正在进行中的移植版本,该版本是基于Huggingface Diffusers Repo的默认版本进行修改的,以在低VRAM GPU(低显存显卡)上获得更好的性能。此外,还借鉴了BMaltais的Koyha SS的部分内容。它还添加了其他一些功能,包括同时训练多个概念,以及(即将推出)图像修复训练。
样式说明:灰色正文主要来自官方文档翻译,有些地方不通顺,我会做一定程度的更改。黑色正文则是我自己的理解和总结,如有错漏,欢迎斧正。
Installation 安装
要安装,请在SD Web UI中转到“Extensions(扩展)”选项卡,选择“Available(可用)”子选项卡,选择“Load from:(从…加载)”以加载扩展列表,最后在Dreambooth条目旁边点击“install(安装)”。
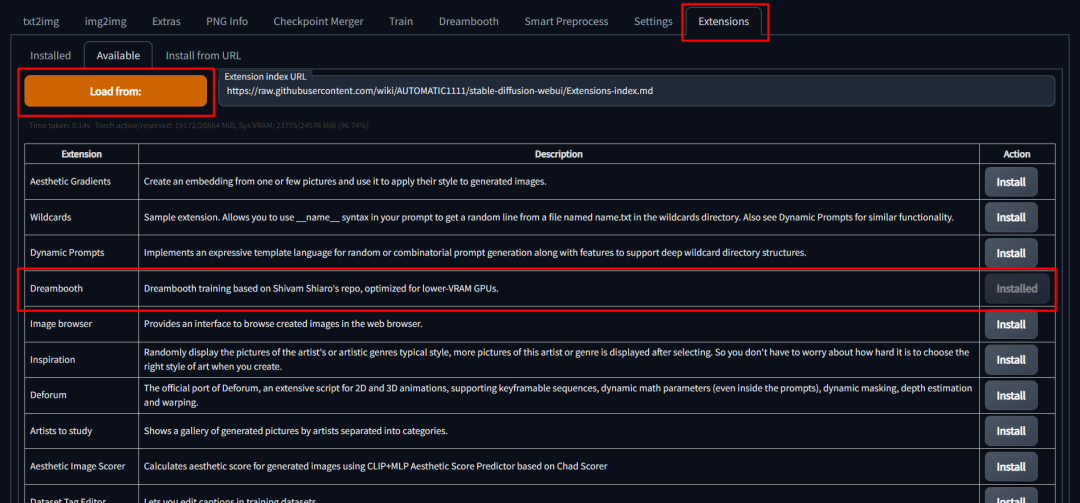
安装完成后,您必须完全重新启动Stable-Diffusion WebUI。重新加载UI将无法安装所需的依赖项。
我们还需要更新版本的diffusers,因为SD-WebUI使用的是0.3.0版本,而DB训练需要>= 0.10.0版本。没有正确的diffusers版本会导致“UNet2DConditionModel”对象没有属性“enable_gradient_checkpointing”的错误消息,以及安全检查器警告。
如果在安装后遇到依赖项问题,请查看以下内容
为了强制sd-web-ui只安装一套依赖项并解决许多安装问题,我们可以指定命令行参数:
set/exportREQS_FILE=.\extensions\sd_dreambooth_extension\requirements.txt
请参考下面的适当脚本,以添加额外的标志来安装依赖项:
https://github.com/d8ahazard/sd_dreambooth_extension/blob/main/webui-user-dreambooth.bat
https://github.com/d8ahazard/sd_dreambooth_extension/blob/main/webui-user-dreambooth.sh
最后,如果您希望完全跳过Dreambooth的“本地”安装过程,您可以设置以下环境标志:
DREAMBOOTH_SKIP_INSTALL=True
这非常适合“离线模式”,您不希望脚本不断从pypi检查内容。
通过WebUI安装后,建议设置上述标志并重新启动整个Stable-diffusion-webui,而不仅仅是重新加载它。
以上主要是安装过程的讲解,我们主要使用B站大佬的整合包,所以略读一下即可。
Dreambooth 视频教程

这个视频介绍了从头开始到高级水平使用 Web UI和DreamBooth扩展进行稳定扩散训练的教程。
内容涵盖了如何安装和更新Web UI的扩展,使用DreamBooth进行训练,准备训练数据集,检查点保存,如何处理过度训练,生成图像,以及如何使用AI进行图像升级等。此外,还介绍了如何在Google Colab中使用训练模型,进行微调和混合训练,以及如何解决内存不足错误等问题。

这个视频介绍了如何将训练好的模型注入到自定义的 Stable Diffusion 模型中,和什么是主模型、次要模型和第三方模型,如何为新注入的主题模型选择合适的提示强度和CFG值等细节教程。

这个视频主要介绍了如何降级CUDA和xformers版本以进行合适的训练,以及如何在仅具备8GB GPU的情况下进行LoRA训练。

这个视频介绍DreamBooth技术的最佳训练设置和参数,并且举了使用0-100张不同张数训练集进行训练的案例,提供了对应的xyz轴对比图。还有文本引导视图合成、属性修改和配饰添加等内容。

这个视频也是介绍各种设置和优化器的比较的,通过对比各实验的x/y/z网格图像来确定最佳训练模型。

这个视频主要是讲如何升级到Torch版本2(PyTorch 2),以实现显著的图像生成和训练速度提升。
视频教程这部分提供的视频很详细,我觉得讲解参数设置对比的视频比较重要,毕竟跑通流程并不难,能掌控参数训练出自己想要的模型才比较难,后续也会继续学习分享视频教程的笔记。
Usage 使用方法
Create a Model 创建一个模型
1.进入Dreambooth选项卡。
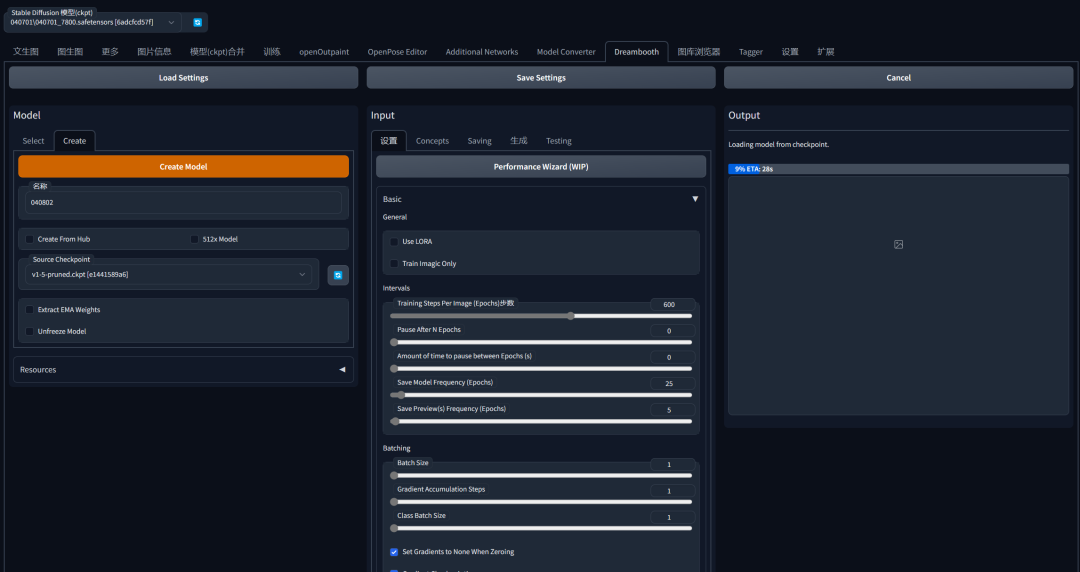
2.在“创建模型”子选项卡下,输入一个新的模型名称,并选择要从哪个源检查点进行训练。如果您想使用HF Hub中的模型,请指定模型URL和令牌。URL格式应为 ‘runwayml/stable-diffusion-v1-5’
源检查点将被提取到models\dreambooth\模型名\working。
点击“创建”。这需要一两分钟的时间,但完成后,界面会提示您已经设置了一个新的模型目录。
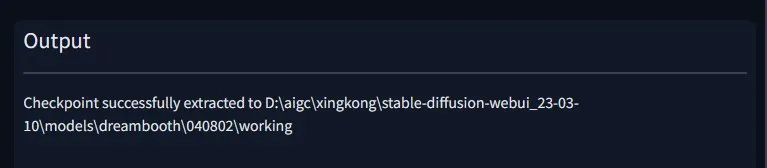
这里是创建模型的过程,需要先选择一个基础模型,创建我们训练的基础文件,搭配上了我的界面截图对照。
Various Top Buttons 各种顶部按钮
Save Params 保存参数 - 保存当前模型的当前训练参数。
Load Params 加载参数 - 从当前选定的模型加载训练参数。可以使用此功能将参数从一个模型复制到另一个模型。
Generate Ckpt 生成检查点 - 从当前保存的权重生成一个当前版本的检查点。
Generate Samples 生成样本* - 在训练过程中点击此按钮,在下一个间隔之前生成样本。
Cancel 取消 - 在当前步骤后取消训练。
Train 训练 - 开始训练
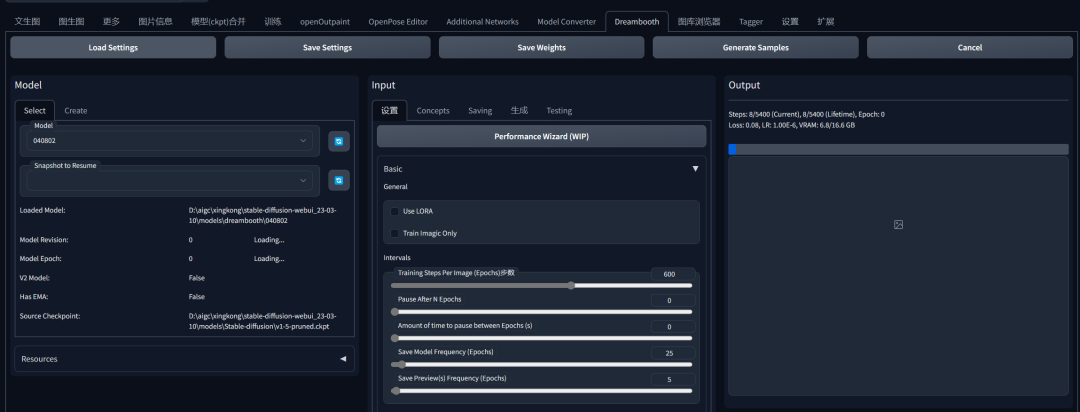
这里对应的是顶部的按钮,跟我的界面有点小区别,但是不大,不影响使用。
Model Section 模型部分
Model 模型 - 要使用的模型。在更改模型时,训练参数不会自动加载到用户界面。
Lora Model Lora模型 - 如果恢复训练,需要加载现有的lora检查点,或者在生成检查点时将其与基础模型合并。
Half Model 半模型 - 启用此选项以使用半精度保存模型。这将生成一个较小的检查点,而图像输出的差异几乎可以忽略不计。
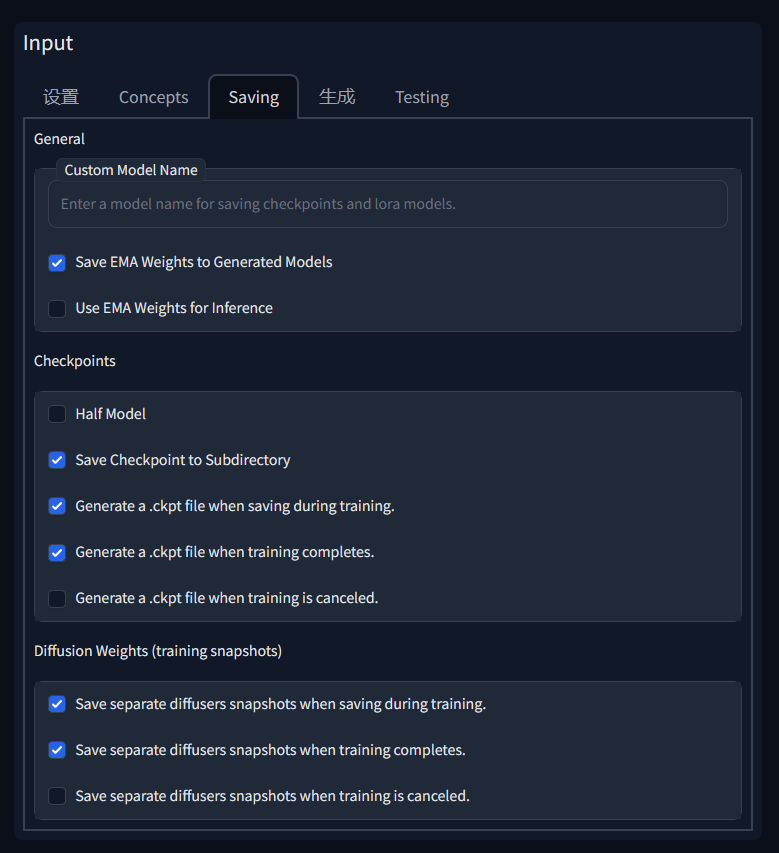
Save Checkpoint to Subdirectory -将检查点保存到子目录 - 使用模型名称将检查点保存到子目录中。
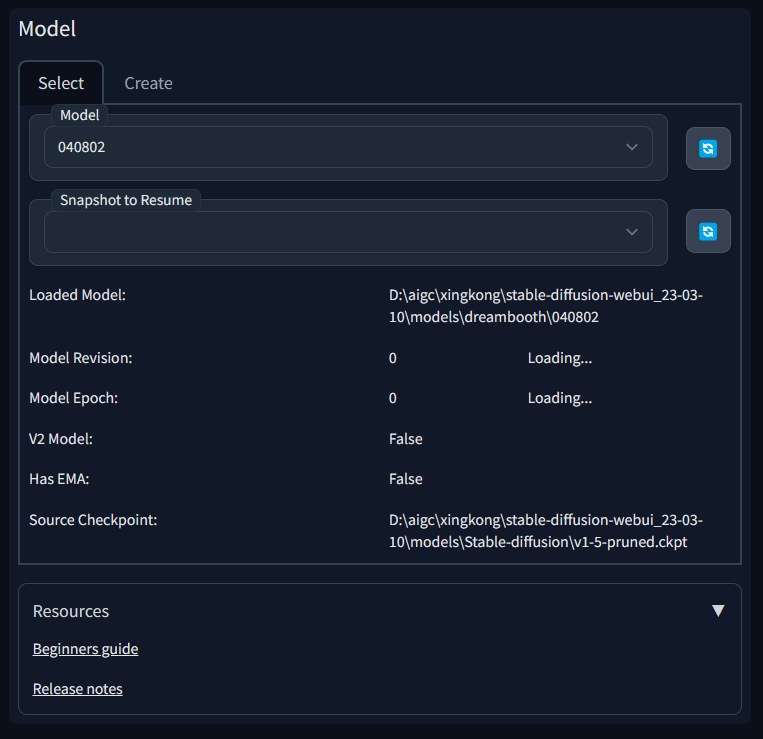
这个部分不是分布在同一个面板,保存功能在Saving标签下的面板里,开始训练只需要选择好模型就可以了,性能压力大的朋友可以勾选Half Model 半模型,Save Checkpoint to Subdirectory -将检查点保存到子目录 建议勾选,更方便文件管理。
Training Parameters训练参数
Performance Wizard (WIP) 性能向导(WIP) - 根据您的GPU的显存量和实例图像的数量尝试设置最佳训练参数。
可能不是完美的,但至少是一个很好的起点。
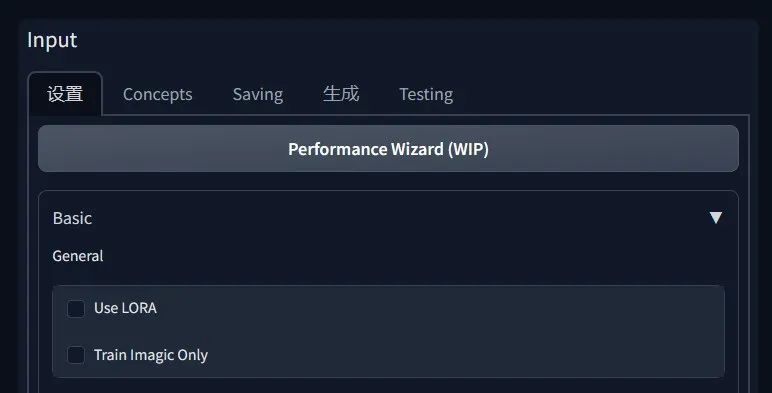
点击这个按钮可以自动设置一组参数,作为训练的起点,比如显存大的4090电脑的Batch Size 就会被设置为3,如果你不知道该怎么开始更好的话,从系统建议开始也是个不错的选择。
Intervals 间隔
本节包含训练过程中事物发生的相关参数。
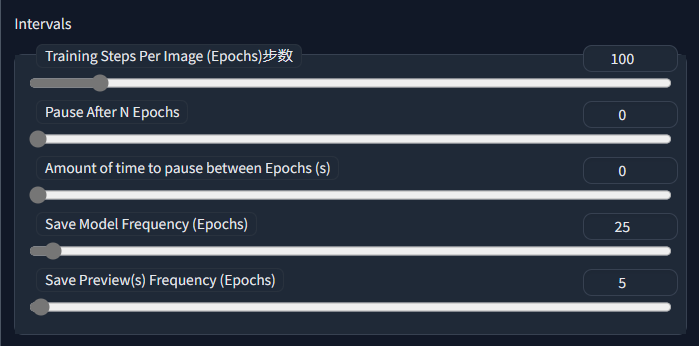
Training**Steps Per Image (Epochs) 训练集的训练轮数**
Training Steps Per Image (Epochs) 训练集的训练轮数 (Epochs) - 顾名思义,一个epoch是对整个实例图像集进行一轮训练。因此,如果我们想要将训练集训练100轮,我们可以将该值设置为100,然后就可以开始了。
在这里我先说这个参数是什么,再说调节这个参数会有什么影响,应该采用怎样的调节策略。最后详细解释具体细节:
是什么
是训练多少轮我们的训练集,可以设想一个厨师在学习制作新菜品。每次尝试制作这道菜(一个 Epoch)都会带来新的经验和教训。随着 Epoch 数的增加,厨师会更熟练地掌握这道菜的制作技巧。
调节影响
“Training Steps Per Image (Epochs)” 值越小,训练时间越短,模型越可能欠拟合,还没学够。
“Training Steps Per Image (Epochs)” 值越大,训练时间越长,模型越可能过拟合,学的太多素材把其他东西都忘光了。
“Training Steps Per Image (Epochs)” 值对显存无明显影响,因为是分步训练的。
调节策略
目前我的理解是设置一个较大的Epoch数,将模型训练到过拟合的地步,然后再去之前的检查点里找表现比较好的平衡点,比较方便。
在 CycleGAN 的论文中,作者通过多个 Epoch 训练模型,并对比了不同 Epoch 下生成的图像质量。结果表明,随着 Epoch 次数的增加,生成图像的 质量逐渐提高。但是,当 Epoch 次数超过一定阈值时,生成图像的质量可能不再显著改善,甚至可能出现退化现象,这表明合适的 Epoch 次数对于生成高质量的图像至关重要。 原文链接:https://arxiv.org/abs/1703.10593\](https://arxiv.org/abs/1703.10593\)
具体细节
训练的总步数由轮数 (Epochs) 实例集图像数得出, 实例集图像多,比如100张,那这一轮就是100次训练,3轮总共300次。实例集图像少,比如9张,那这*一轮就是9次训练,3轮总共27次。
先举一个简单例子来理解一下:
假设我们有一个训练集,其中包含 4 张图片:A、B、C 和 D。如果我们将 “Training Steps Per Image (Epochs)” 设置为 3,那么在训练期间,每张图片将被用来训练 3 次,一共三轮,总共12次。
在这种情况下,训练过程将按以下顺序进行
使用图片 A 训练一次`使用图片 B 训练一次``使用图片 C 训练一次``使用图片 D 训练一次``使用图片 B 训练一次(第二轮)更换图片顺序``使用图片 A 训练一次(第二轮)``使用图片 D 训练一次(第二轮)``使用图片 C 训练一次(第二轮)``使用图片 D 训练一次(第三轮)更换图片顺序``使用图片 B 训练一次(第三轮)``使用图片 A 训练一次(第三轮)``使用图片 C 训练一次(第三轮)`
完成这个过程后,每张图片都被用来训练了 3 次,总共进行了 12 次训练。通过增加 “Training Steps Per Image (Epochs)” 的值,选择合适的 Epoch 数目很重要。太少的 Epoch 可能会导致模型欠拟合,而太多的 Epoch 可能会导致过拟合。
Save Model Frequency (Epochs) 保存模型频率
Save Model Frequency (Epochs) 保存模型频率(Epochs) - 保存检查点将按每个epoch计算,而不是按步数计算。
是什么
是保存模型的频率,决定每几轮训练我们保存一次。
调节影响
Save Model Frequency (Epochs) 值越小,训练时间越长,磁盘空间占用越多,越可能遇到相对前后步骤来说更优秀的模型。
Save Model Frequency (Epochs) 值越大,训练时间越短,磁盘空间占用越少,越容易错过对前后步骤来说更优秀的模型,极端情况下就是过程中不保存模型,训练完成才保存一次。
该怎么调节
综合自己对训练时间,和磁盘空间的预期来调整,如果训练轮数 (Epochs) 较大比如600轮,那么Save Model Frequency (Epochs) 就不能太小,否则存几十个模型可能会占据几百G空间,也会大大拖累训练速度。
具体细节
继续上面的案例:
假设我们有一个训练集,其中包含 4 张图片:A、B、C 和 D。如果我们将设置 “Training Steps Per Image (Epochs)” = 3,Save Model Frequency (Epochs) =1,那么在训练期间,每张图片将被用来训练 3 次,每个Epochs保存1次,一共保存三次。
在这种情况下,训练过程将按以下顺序进行:
使用图片 A 训练一次使用图片 B 训练一次使用图片 C 训练一次使用图片 D 训练一次已经完成一轮(Epochs),保存第一次。使用图片 B 训练一次(第二轮)更换图片顺序使用图片 A 训练一次(第二轮)使用图片 D 训练一次(第二轮)使用图片 C 训练一次(第二轮)第二轮(Epochs),保存第二次。使用图片 D 训练一次(第三轮)更换图片顺序使用图片 B 训练一次(第三轮)使用图片 A 训练一次(第三轮)使用图片 C 训练一次(第三轮)第三轮(Epochs),保存第三次。
完成这个过程后,每张图片都被用来训练了 3 次,总共进行了 12 次训练,3次保存。
下图是设置与结果的对应。

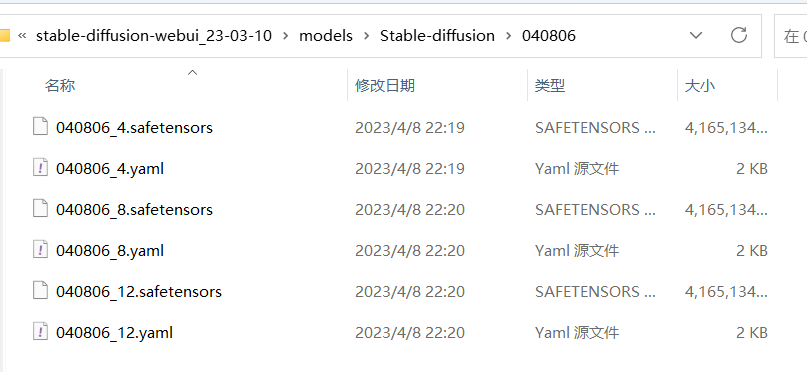
然后我们再来实验复杂一点的案例
设置训练集图片数=4, “Training Steps Per Image (Epochs)” = 100, Save Model Frequency (Epochs) =25,那么在训练期间,训练集会被训练100轮,图片集数量为4,总次数100*4=400次,每个25轮(Epochs)保存1次,一共保存4次。分别在以下节点保存
`第25轮(Epoch)完成时(第100次)``第50个轮(Epoch)完成时(第200次)``第75个轮(Epoch)完成时(第300次)``第100个轮(Epoch)完成时(第400次)`
然后是更复杂的案例
设置训练集图片数=9, “Training Steps Per Image (Epochs)” = 600, Save Model Frequency (Epochs) =25,那么在训练期间,每张图片将被用来训练600 次,一共5400次,每个25Epochs,也就是25*9=225步,保存1次,一共保存24次。
`第25轮(Epoch)完成时(第225次)``第50轮(Epoch)完成时(第450次)``......``第575轮(Epoch)完成时(第5175次)``第600轮(Epoch)完成时(第5400次)`
Save Model Preview (Epochs) 保存预览图频率(Epochs)
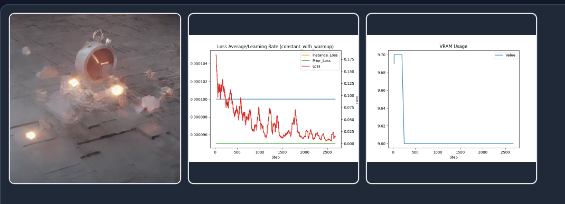
Save Model Frequency (Epochs) 保存预览图频率(Epochs) - 保存检查点将按每个epoch计算,而不是按步数计算。
逻辑与保存模型一致,一般设置为相同数值。生成预览图的同时会生成损失函数Loss 值曲线图,也可以设置的高频一点,更高密度的观察损失函数的变化,中途调整参数。另一张图是显存使用趋势图,控制住不炸显存就好。
Pause After N Epochs 每N个Epochs暂停
Pause After N Epochs 每N个Epochs暂停 - 当设置为大于0的值时,训练将暂停指定的时间。
每个Epoch之间暂停的时间,以秒为单位 - 当N大于零时,每个“N”个Epochs之间暂停的时间,以秒为单位。
Pause After N Epochs 用于手动控制训练过程中的暂停时间,如果你需要在训练途中停下来进行评估模型、调整超参数的话,否则一般设置为0不需要动。
Amount of time to pause between Epochs 在 Epochs 之间暂停的时间
Amount of time to pause between Epochs -在 Epochs 之间暂停的时间,以秒为单位 - 当 N 大于零时,在 N 个 Epochs 之间暂停多长时间,以秒为单位。
例如,设置了在每 5 个 Epochs 后暂停,即Pause After N Epochs =5,并设置暂停时长为 60 秒,即Amount of time to pause between Epochs =60 那么训练将在每 5 个 Epochs 结束后暂停 60 秒,然后再继续训练。
Use Concepts 使用概念
Use Concepts 使用概念 - 是否使用包含多个概念的JSON文件或字符串,或下面的单独设置。
Use Concepts 没在上面找到,我的界面上是被归类到了下方的高级设置中,功能是使用设定好的json格式文件代替界面上的手动设置,新手暂时不用管。
这里的”概念”通常指一组关键词或描述,用于表示某个特定的主题或类别。
总结一下Intervals 间隔 这个板块,关键点就是训练轮数Training Steps Per Image (Epochs) 与Save Model Frequency (Epochs) 保存模型频率的设置,前者跟训练集图片数一起决定训练总次数,后者决定多久保存一次,一起影响训练的总时长和效果,合理搭配才能更好更快的训练出想要的模型。
Batching 批处理
Batch Size 批大小
Batch size 批大小 - 同时进行的训练步数。你可能想把这个值保持在1。
是什么
Batch size 指每次处理抽取几张图片同时进行训练学习。想象一个厨师在为大量顾客制作餐点,Batch size 就像是厨师每次准备的食材的数量。较大的 Batch size 会让厨师每次处理更多食材,从而更快地为顾客提供餐点,但这可能会导致制作质量的降低。
调节有什么变化
batch size 越大,训练时长越短, 显存占用越高,随机性越低,更容易收到较差的局部最优解,泛化能力较差。
batch size 越小,训练时长越长,显存占用越少,随机性越大,更容易找到优秀的局部最优解,但容易导致训练不稳定,损失函数震荡比较大。
该怎么调
选择合适的 batch size 需要权衡训练速度、显存占用和训练效果。通常,我们可以从一个相对较小的 batch size 开始,逐渐增加,直到达到最佳性能或显存限制。这种方法称为“Batch Size 调优”。
Gradient Accumulation Steps 梯度累积步数
gradient Accumulation Steps 梯度累积步数 - 这个值可能应该设置为与训练批大小相同的值。
正常情况下和 batch size 设置一样的数值,将这两个参数设置为相同值可以确保在进行权重更新之前,梯度累积的步数与 Batch size 一致,从而实现较大的有效 Batch size。可以先不用太关注。
Class batch size 类别批大小
Class batch size 类别批大小 - 同时生成的分类图像数量。将其设置为您可以使用Txt2Image安全一次性处理的数量,或者保持原样。
这个暂无研究,保持原样即可。
Set Gradients to None When Zeroing 清零时将梯度设置为None
Set Gradients to None When Zeroing 清零时将梯度设置为None - 而不是设置为零,将梯度设置为None。通常情况下,这会降低显存占用,并可以适度提高性能。
https://pytorch.org/docs/stable/generated/torch.optim.Optimizer.zero_grad.html
显存低的开启,高的可以考虑关闭,可能有轻微的性能提升,不过都影响很小,建议不用管,保持开启。
Gradient Checkpointing 梯度检查点
Gradient Checkpointing 梯度检查点 - 启用此功能以节省显存,代价是略微降低速度。
https://arxiv.org/abs/1604.06174v2
关闭这个功能可以提高训练速度,简化模型实现,有足够多显存的建议关闭。实在不够用的再开启。
Max Grad Norms最大梯度范数 - 梯度归一化的最大数量。
这个在界面中没找到对应选项,后续再研究。
Learning Rate 学习率
这个部分包含与学习率相关的参数。
Learning Rate 学习率
学习率 - 训练对新模型的影响力。较高的学习率需要较少的训练步骤,但容易导致过拟合。建议在0.000006到0.00000175之间选择。
是什么
学习率(Learning rate)是神经网络训练过程中的一个关键超参数,它主要用于控制模型权重更新的幅度。学习率就像是炒菜中的火候控制,如果火候太大,容易糊锅;如果火候太小,又容易导致食材不熟。
调节影响
学习率越大,权重更新幅度越大,训练速度越快,越容易过拟合,可能更不稳定,在局部最优解附近震荡,无法收敛。
学习率越小,权重更新幅度越小,训练速度**越慢**,越容易找到最优解,相对更稳定,有可能陷入局部最优解爬不出坑。
学习率的调节基本不会影响显存的使用。
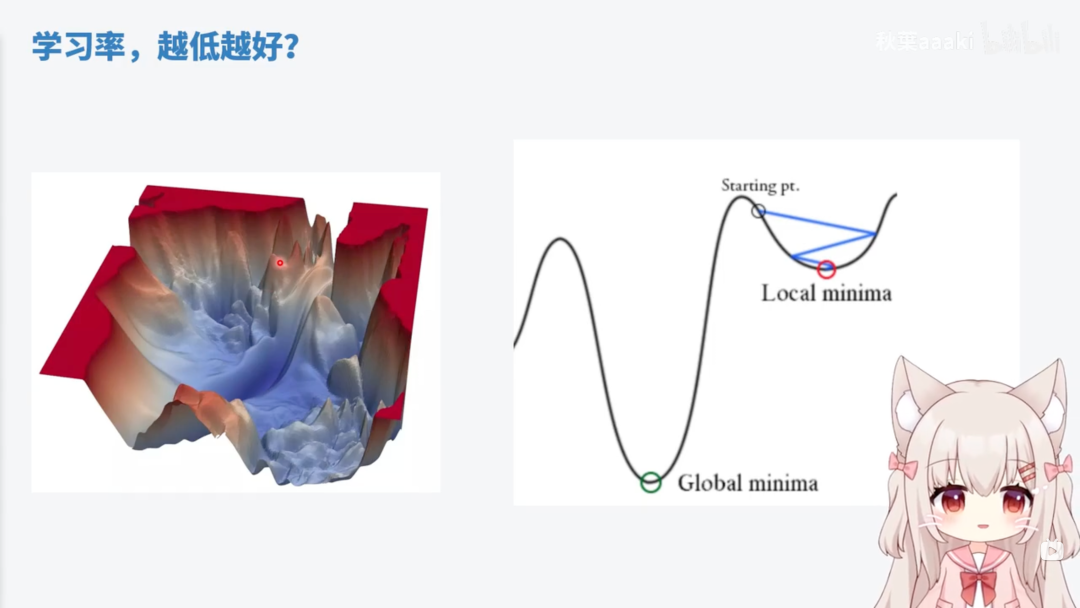
调节策略
学习率的调整应该是动态的,一开始可以考虑使用一个相对大的学习率跨过小水坑,然后再用小的学习率慢慢学,可以重复这个从大变小的周期,也可以采用学习率调度器(设定好的策略),例如余弦退火+重启策略。
在训练过程中,需要密切关注损失函数值、验证集上的性能等指标。如果发现损失函数值波动很大或者性能没有明显提升,可能需要调整学习率。
和损失函数Loss的关系
损失函数(Loss Function)是用于它是用来衡量模型预测结果与真实结果之间的差异的函数。与学习率的关系非常密切,主要体现在以下几点:
损失函数的梯度:在基于梯度的优化方法中,如梯度下降(Gradient Descent)和Adam等,模型参数的更新依赖于损失函数的梯度。学习率决定了参数更新的幅度,进而影响损失函数的下降速度。
收敛速度和稳定性:合适的学习率可以平衡模型的速度与稳定性,体现为平衡损失函数的速度与稳定性。较高的学习率可能导致模型在损失函数的最优解附近震荡,难以收敛;较低的学习率可以使模型更稳定地收敛,但训练过程可能会非常缓慢。
梯度爆炸:较高的学习率可能导致梯度爆炸,使得模型无法正常训练;较低的学习率可以降低梯度爆炸的风险,但可能需要更长时间来训练模型。
具体细节
发现官方文档这个建议的学习率6e-6(0.000006)到1.75e-6 (0.00000175),与在B站和vega学到的1e4(0.0001)差别挺大。这个问题没有定论,我认为可以都尝试一下,看看结果有没有明显差别。
在一次尝试中,我的训练轮数(Epochs)设置为300,Batch Size 设置为1,学习率调度器Loin,9张素材图,然后就迎来了我的第一次梯度爆炸。
学习率一路上升然后Boom~ 错误提示Training interrupted. Total lifetime steps: 296 
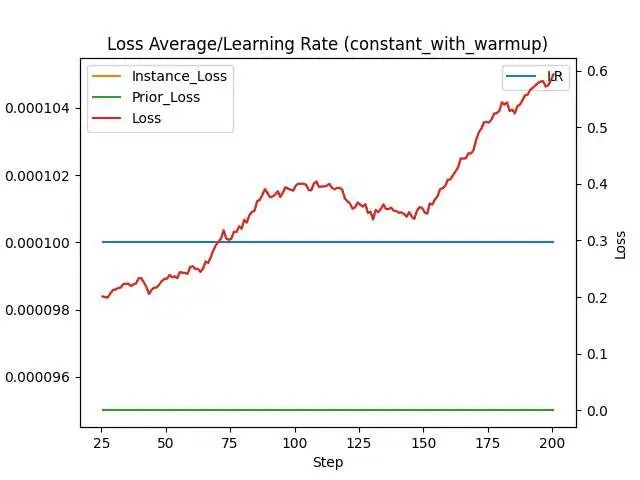
梯度消失和梯度爆炸都是神经网络训练中常见的问题。梯度消失是指梯度在反向传播过程中变得非常小,使得权重更新变得非常缓慢,难以训练。梯度爆炸是指梯度在反向传播过程中变得非常大,导致权重更新过大,使得模型训练变得不稳定。
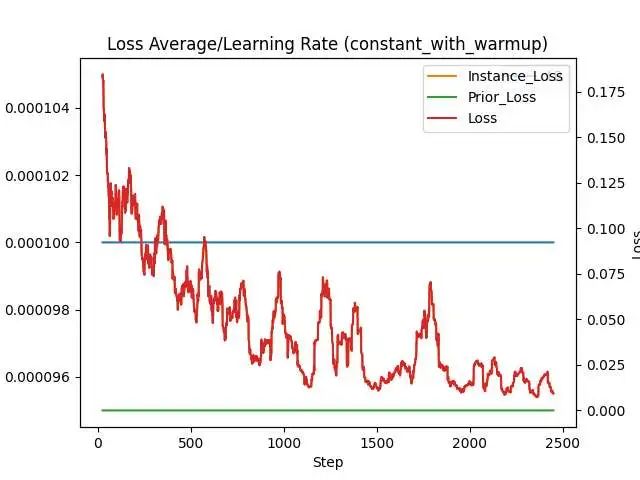
关于如何设置初始学习率,可以我认为可以从官方建议的区间开始,不够满意再切到其他学习率,同时,不同的优化器面对同一个学习率产生的效果也很不一样。
还是同样的参数,只是调度器切换为8Bit AdamW,就收敛的不错,顺利的跑完了全程。
更多扩展内容可以看一下秋叶大佬的科普:
【AI绘画/科普】AI训练中的黑话都是什么意思?AI又是如何训练出来的?如何调节参数?不用一行公式带你看懂梯度下降_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV1A8411775m/
Scale Learning Rate学习率缩放 - 随着时间的推移调整学习率
这是一种在训练过程中根据特定规则动态调整学习率的策略。随着训练的进行,学习率可能会逐渐减小,以帮助模型在损失函数的优化过程中更好地收敛。
当设置为余弦退火类学习率调度器时会出现此选项。
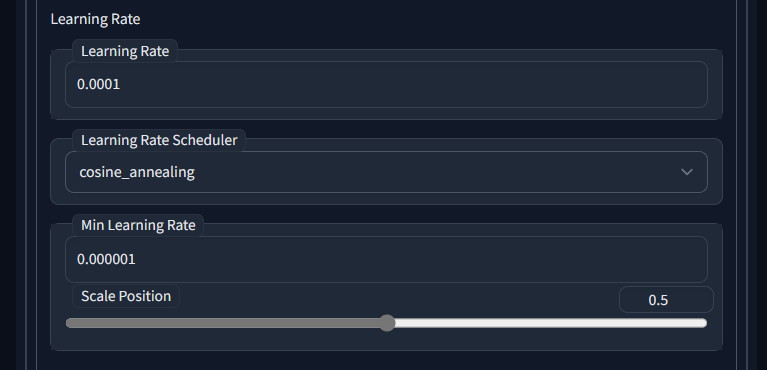
Learning Rate Scheduler 学习率调度器 - 与学习率一起使用的调度器
学习率调度器是一种设定好的学习率变化策略,能够根据情况自动调整学习率。假设你正在使用Stable Diffusion生成一幅风景画。在开始阶段,模型需要学习大致的轮廓和色彩分布,此时学习率调度器会设置较高的学习率。随着训练进程,模型需要逐渐关注细节,学习率调度器会适时降低学习率,使模型能够更精确地学习和生成图像。
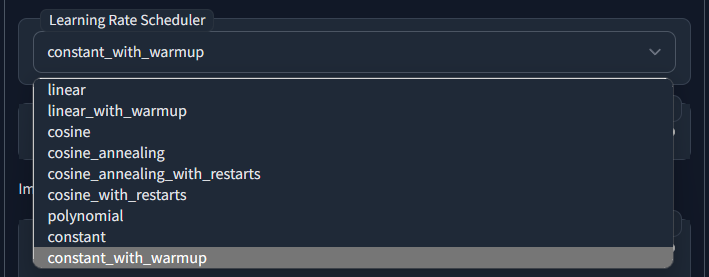
以下是默认自带的学习率调度器的介绍:
- linear(线性):训练过程中学习率线性递减,直至达到最小学习率。
- linear_with_warmup(线性加热身):训练初期进行学习率热身,达到指定步数后,学习率线性递减至最小学习率。
- cosine(余弦):训练过程中学习率根据余弦退火策略进行调整。
- cosine_annealing(余弦退火):学习率按照余弦退火策略逐渐减小,最后保持在较低的值。
- cosine_annealing_with_restarts(带重启的余弦退火):学习率按照余弦退火策略逐渐减小,但在达到预定周期后重启退火过程,使学习率重新增大。
- Im cosine_with_restarts(不完全的带重启余弦退火):类似于带重启的余弦退火,但重启周期可能不完全相同。
- polynomial(多项式):学习率根据多项式退火策略进行调整。
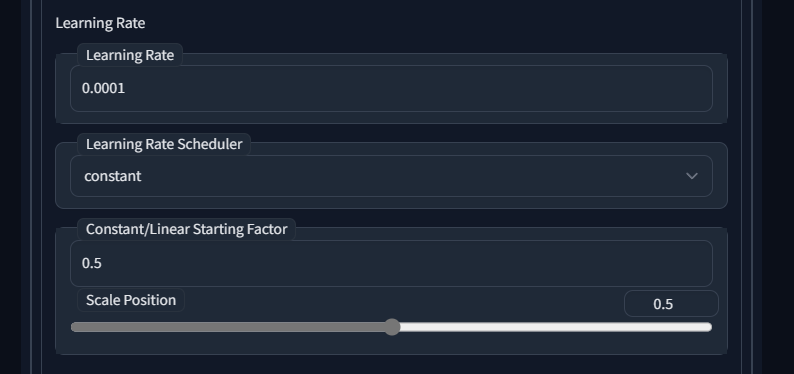
- constant(恒定):训练过程中学习率保持恒定,不进行调整。
- constant_with_warmup(恒定学习率加热身):在训练初期进行学习率热身,达到指定步数后,学习率保持恒定。
有B站大佬 BUL3SKY 建议使用 Cosinewithrestarts” (带重启的余弦退火)的方法, 优点是能够避免陷入局部最优解, 具有较好的鲁棒性和泛化性能。缺点是 需要调整周期、 起始学习率和重启策略。
以下是大佬对其他学习调度器的优缺点解释
“Linear” 线性衰减:优点:简单易用,能够稳定地将学习率降低到零。缺点: 可能需要调整衰减速度和起始学习率。
“Cosine” (余弦退火):优点:具有较好的效果, 在模型训练的后期可以使学习率更加平稳地降低, 有一定的正则化效果。缺点: 需要调整周期和起始学习率。
“Polynomial”(多项式退火):优点: 能够让学习率更快地降低,有一定的正则化效果。缺点: 需要调整衰减速度和起始学习率
“Constant”(恒定学习率):优点: 简单易用,能够让模型快速收敛。缺点:可能会导致模型过拟合,需要手动调整学习率。
“Constantwith warmup” (带预热的恒定学习率):优点:能够快速将学习率提高到合适的水平,有助于模型快速收敛。缺点:可能会导致模型过拟合,需要手动调整预热和恒定阶段的学习率。
更多扩展阅读请看B站大佬视频
【LORA训练】【AI绘画】炼丹常用参数详解 / 参数对模型的影响 / 适用于小白 进阶炼丹师_哔哩哔哩_bilibili
https://www.bilibili.com/video/BV1rs4y1o7V8/
Learning Rate Warmup Steps 学习率热身步数 - 在开始缩放学习率之前运行多少步
当学习率调度器设置为linear_with_warmup(线性加热身)、constant_with_warmup(恒定学习率加热身)等带热身的调度器时,会出现此选项。
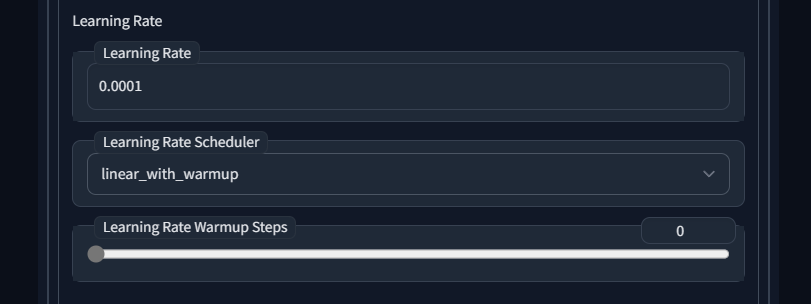
学习率热身是指在训练开始时使用较低的学习率,然后在一定的步数内逐步提高学习率,直至达到预定的最大学习率。这种策略的目的是让模型在初始阶段更平缓地进行训练,避免因过高的学习率导致的梯度爆炸或损失函数收敛困难。学习率热身步数是在开始缩放学习率之前,需要运行的步数。
Warmup是在 ResNet 论文中提到的一种学习率预热的方法,它在训练开始的时候先选择使用一个较小的学习率,训练了一些epoches或者steps (比如4个epoches,10000steps),再修改为预先设置的学习来进行训练。
这里是ResNet论文的链接:https://arxiv.org/abs/1512.03385
这个参数应该不是很重要,如非必要保持默认0即可。
应用场景 (1)训练出现NaN:当网络非常容易nan时候,采用warm up进行训练,可使得网络正常训练;(2)过拟合:训练集损失很低,准确率高,但测试集损失大,准确率低,可用warm up
https://blog.csdn.net/weixin_40051325/article/details/107465843
应用原理/优势来源 这个问题目前还没有被充分证明,目前效果有:(1)有助于减缓模型在初始阶段对mini-batch的提前过拟合现象,保持分布的平稳;(2)有助于保持模型深层的稳定性。在训练期间有如下情况:(1)在训练的开始阶段,模型权重迅速改变;(2)mini-batch size较小,样本方差较大。
https://blog.csdn.net/weixin_40051325/article/details/107465843

总结
全文到这里已逾万字,主要研究了训练集训练轮数 Epochs、同时进行训练的图像数Batch size 、学习率Learning rate等,这些都是训练中非常重要的超参数,值得我们认真研究。
虽然认真研究参数是什么确实很占据篇幅哈哈,而且即使篇幅如此之长,却也才粗略提了下相关内容,更多细节还可以展开讨论很多,就放在后面的文章再与诸君畅谈吧哈哈。
Dreambooth官方文档未解读完的部分将在下一篇文章更新,更多细节讨论也可以加入 Stable Diffusion 炼丹阁 和道友们一起交流丹道奥秘,比如 讨论药材的选取与火候的控制,成丹的评估方案等等~ 仙途漫漫,携手同行哈哈哈



点个在看你最好看

若有收获,就点个赞吧
0 人点赞
