正则,就是用来处理字符串的一种规则。
- 正则只能用于处理字符串
- 处理一般包含两个方面
- 验证当前字符串是否符合某个规则,正则匹配
- 把一个字符串中国符合规则的字符获取到,正则捕获
正则的使用跟字符串是分不开的,使用正则有两种方法:
- 使用正则实例的方法,需要传入字符串
-
1. 创建正则的方法
字面量方式
字面量方式
方法:两个参数(注意需要转移)(一个是元字符字符串,一个是修饰符字符串)
- 元字符字符串
- 修饰符字符串
例子:let reg2=new RegExp("\\d+","g");console.log(reg2.test("1234444456"));//trueconsole.log(reg2.test("asdsa"));//false
匹配 => 存在字符串a-z A-Z 0-9 ,长度是4至6个
let reg = new RegExp(/^[a-zA-Z0-9]{4,6}$/); // ^表示开始 $表示结束reg.test('axihe');//truereg.test('axihe.com')//false
捕获 => 以数字123开头,以abc结尾
let reg = new RegExp(/^[123][abc]$/);reg.test('123abc')
字符串以数字0-9开头, abc结尾
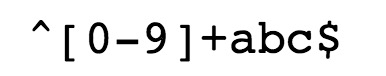
^为匹配输入字符串的开始位置。[0-9]+匹配多个数字,[0-9]匹配单个数字,+匹配一个或者多个。abc$匹配字母abc并以abc结尾$为匹配输入字符串的结束位置- 只允许用户名包含字符、数字、下划线和连接字符 (-),并设置用户名的长度
2. 正则的方法
2.1 test 匹配
查找这个字符串是否满足正则规律,匹配成功返回 true,否则返回 false
正则中没有全局匹配时,每次都是从开头匹配,只要有符合的就返回 true
var reg = /\d{2}/;var str = 'a11a';reg.test(str); //=> true
正则中有全局匹配的时候,每次都会从
reg.lastIndex索引开始匹配,只要匹配到后面都没有,则返回false,此时索引会重置。与exec方法一样。var reg = /\d{2}/g;var str = 'a11a11';reg.test(str); //=> truereg.test(str); //=> truereg.test(str); //=> false
2.2 exec 捕获
在字符串中获取满足正则规律的字符串,匹配成功则返回一个数组,没有匹配到则返回
null
返回一个数组,数组中第一项是匹配的字符串,后面的项是匹配到的分组。
其中还有两个属性:
input:源字符串index:匹配到的开始索引(从0开始)
- 正则中没有全局匹配的时候
- 无论执行多少次,都是从头开始匹配
- 都只能获取到第一个匹配,以及匹配的分组。
var reg = /\d+/;var str = 'aa2018aa2019';reg.exec(str); //=> 2018reg.exec(str); //=> 2018
- 正则中有全局匹配的时候
- 每次执行的时候,会从上一次记录的
reg.lastIndex索引开始查找,也就是每次查找的开始位置不一样 - 即使再次使用该方法传入的字符串不一样,也会从上一次记录的
reg.lastIndex索引开始查找 - 每次使用这个方法,依然只获取第一次匹配到的字符串以及其中的分组
var reg = /\d+/g;var str = 'aa2018aa2019';var str2 = 'aa2018aa2019';reg.exec(str); //=> 2018reg.exec(str2); //=> 2019,说明也是从上一次索引开始查找的reg.exec(str); //=> nullreg.exec(str2); //=> 2018
需要注意的是:
- 当它遍历到最后,再使用此方法,会返回有一个 null,此时 reg.lastIndex 也会重置回 0,之后又会从开头重新遍历
- 使用同一个正则,那么其记录的 reg.lastIndex 是一样的,与字符串无关,这样就会出现不可预料的结果
- 使用同一个正则的 test 或 exec 方法,也是相同的 reg.lastIndex,就会相互影响,结果不可预料
由于 exec 没有办法一次捕获所有匹配的字符串,同时也存在检测不同字符时,不是从开头匹配的 bug
所以,需要自己写一个 execAll 方法,捕获了所有的匹配字符串,并且最终索引都会回到最初。
RegExp.prototype.execAll = function (str) {var temp;//=> 防止后面出现死循环,若没有全局修饰符,直接给它返回匹配到的第一个if(!this.global) {temp = this.exec(str);temp.errorReason = "你没有添加全局修饰符";return temp;}var ary = [];temp = this.exec(str);while (temp) { //=> 当 exec 没有捕获到时,返回 null,同时索引置回最初ary.push(temp[0]);temp = this.exec(str);}return ary;}
3. 正则的懒惰性
正则的捕获有懒惰性:只能捕获到第一个匹配的内容,剩余的默认捕获不到。
正则的懒惰性与正则的 lastIndex 属性有关,它代表正则捕获的时候,下一次在字符串中开始查找的索引。
//=> lastIndex 不变,导致了正则捕获的懒惰性let str = 'aa18bb19';let reg = /\d+/;reg.lastIndex; //=> 0reg.exec(str); //=> ['18']reg.lastIndex; //=> 0reg.exec(str); //=> ['18']//=> 手动改变 lastIndex 值,不起作用reg.lastIndex = 4;reg.lastIndex; //=> 4reg.exec(str); //=> ['18']//=> 需要使用全局匹配let str = 'aa18bb19';let reg2 = /\d+/g;reg2.lastIndex; //=> 0reg2.exec(str); //=> ['18']reg2.lastIndex; //=> 4reg2.exec(str); //=> ['19']reg2.lastIndex; //=> 8reg2.exec(str); //=> nullreg2.lastIndex; //=> 0reg2.exec(str); //=> ['18']
解决正则捕获的懒惰性,需要添加全局修饰符 g,这个是唯一的方法,而且不加 g,不管用什么办法捕获,也都不能把全部匹配捕获到。
4. 正则的贪婪性
出现量词的时候,每次匹配捕获的时候,总是捕获到和正则匹配中最长的内容。
let str = 'aa2018';let reg1 = /\d+/g;reg1.exec(str); //=> '2018'//=> 把问号放在量词元字符后面,代表的就不是出现零次或者一次了,而是取消捕获的贪婪性let reg2 = /\d+?/g;reg2.exec(str); //=> '2'

若有收获,就点个赞吧
0 人点赞
