作者单位:
主要看点:
传统的语义分割任务在固定类别数目上训练,测试时也只能处理训练集见过的类别。
作者解决的是一个 zero-shot 或者 few-shot 的任务。
这里的 Zero-Label 和 Few-Label 是指的 Pixel-level annotations,在测试的时候还是需要给定待选的语义Label的,比如 {cow, grass, … } 这种。
此时如果用户给了一个张图片,并告诉算法,图片里有两新类别(训练集种没有),那么算法如何在可以分对已见过(seen)的类别,还能把正确的pixel分配给(unseen)没见过的label上呢?
首先,模型分配正确的 pixel 给对应的 label,首先要知道这个 label 是什么。一般的模型是不能理解这几个英文字母的(比如cow, grass),更不用说分配了。
但是不可否认的是,这些单词是包含语义信息的,人看到 “cow” ,脑中就会有意象。
那么一个模型要做到 zero-shot semantic segmentation ,不可避免地需要了解 word(label)的语义信息。
在本文中,作者使用了 word embedding 的方式 (利用pre-trained 的 embedding network),来为模型的训练和测试过程中的 label 提供这些语义信息。
使用 word2vec 等方法,可以将每个 label 用一个 ![[19 CVPR] Semantic Projection Network for Zero- and Few-Label Semantic Segmentation - 图3](/uploads/projects/z_zhang@is/8c3290192815f15f2185fd5cc09f4593.svg) 维度的向量表示。
维度的向量表示。
由于 word embedding 是由一个固定参数的 embedding model 得到的,
现在其实就是引入了一个已知的高维的语义空间,每个label在其中为一个点。
那么如果我们能把每个 pixel 也投影到这个维的语义空间,然后找到距离自己最近的 Label 不就可以完成对每个 Piexl 的分类了?
这么做带来了一个特别好的特性,当新的 labels 给定时候,也可以用 embedding model 得到它们在语义空间的表示,
此时我们就可以知道之前的 label 以及新的 Label 在高维空间的表示点。
那么当 pixel 被嵌入到这个空间中,就可以找最相似的点(label)作为自己的标签,这么一下不管新的还是旧的 label 都可以处理了!
那么这个任务就被重新定义成了一个:两个模态的信息【视觉信息 (pixel) 和 语言信息 (word/ label)】 在高维语义空间的匹配问题。
方法部分:

在上文的描述中,该方法已知的已经有 label 的 embeddding 模型, 和 一个维的语义空间。
那么现在还缺少对视觉信息 embedding 的模型,这就是训练过程要做的事情:
那么在优化过程中,就是有监督地在学习一个视觉信息的嵌入模型。
如上图,网络的结构很简单,重点是理解这么三个张量:
1) Word Embedding Matrix.
Word Embedding Matrix. ![[19 CVPR] Semantic Projection Network for Zero- and Few-Label Semantic Segmentation - 图8](/uploads/projects/z_zhang@is/0a9891c915d5976d3dab5136dfab02a9.svg)
_S_是训练集中包含的类别,这个矩阵每一列是一个 label 的 word embedding;是语义空间的维度。
2)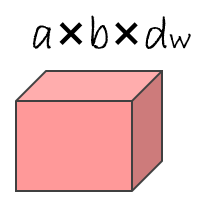 ,我称它为 Pixel Embedding Tensor,**CNN的输出,我们把这个 Tensor 变成一个 Matrix, 令
,我称它为 Pixel Embedding Tensor,**CNN的输出,我们把这个 Tensor 变成一个 Matrix, 令 ![[19 CVPR] Semantic Projection Network for Zero- and Few-Label Semantic Segmentation - 图11](/uploads/projects/z_zhang@is/9c375f0d40773919be94465c5b726dd0.svg) 。
。
那么所有视觉信息(所有像素)和所有语言信息(所有Label)之间的相似度(距离)就可以通过下面的方式计算,作者采用内积计算,
并用了Softmax转换为概率,图中{0.2, 0.1, 0.7}就代表着第1个pixel属于这个三个已知标签的概率分别为 {0.2, 0.1, 0.7},那么该 pixel 就属于 label-3。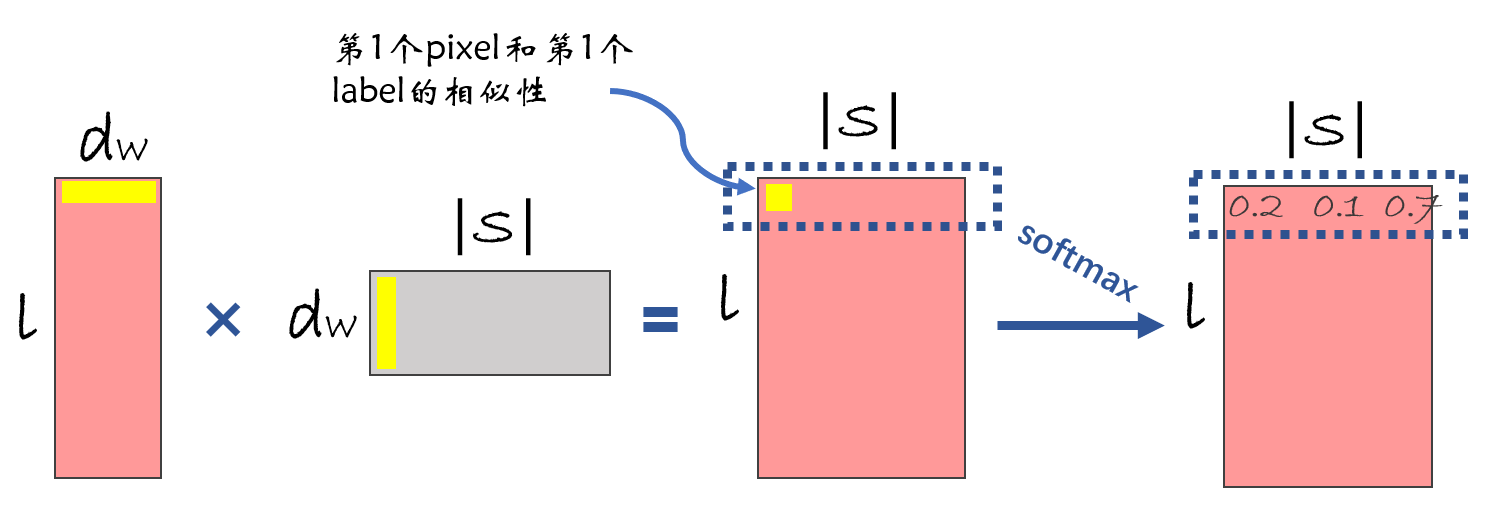
3)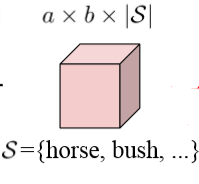 这个是得到的相似性Tensor, 转换为语义分割的标准输出形式
这个是得到的相似性Tensor, 转换为语义分割的标准输出形式  用于监督。
用于监督。
那么在训练集上通过监督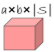 就可以训练视觉嵌入网络了,这样保证之后我们就可以得到一个好的视觉嵌入
就可以训练视觉嵌入网络了,这样保证之后我们就可以得到一个好的视觉嵌入 。
。
上述过程写成公式就是:![[19 CVPR] Semantic Projection Network for Zero- and Few-Label Semantic Segmentation - 图18](/uploads/projects/z_zhang@is/d74e70499d15f83ff3d381bf0a794dcb.svg) 。
。
在测试阶段只要把 word embeddings 改变下,从 变成
变成 就行了,U是Unseen的类别。
就行了,U是Unseen的类别。
当然这个方法可以变得很灵活,可以解决不同的匹配问题,如下表所示: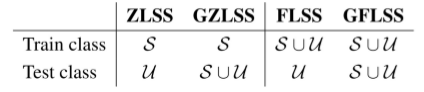
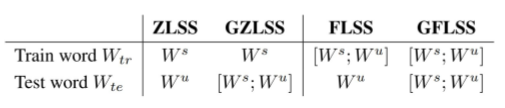
总结
固定在这个框架下,感觉有以下地方可以改进:
- 如何更好地监督训练Pixel Embedding网络;
- 如何更好的度量Pixel Embbedding 和 Word Embedding 的相似性。
- 除了直接比较相似性分类之外,能不能引入其他先验,比如哪些Word可能更容易一起出现{🌴,🌊 },哪些不容易一起出现{🐟,🐦}等。

若有收获,就点个赞吧
0 人点赞
