论文名称:Large-scale interactive object segmentation with human annotators
主要看点:
- 关于交互分割设计的一些观察;
- 大规模的用户行为分析。
实验观察:
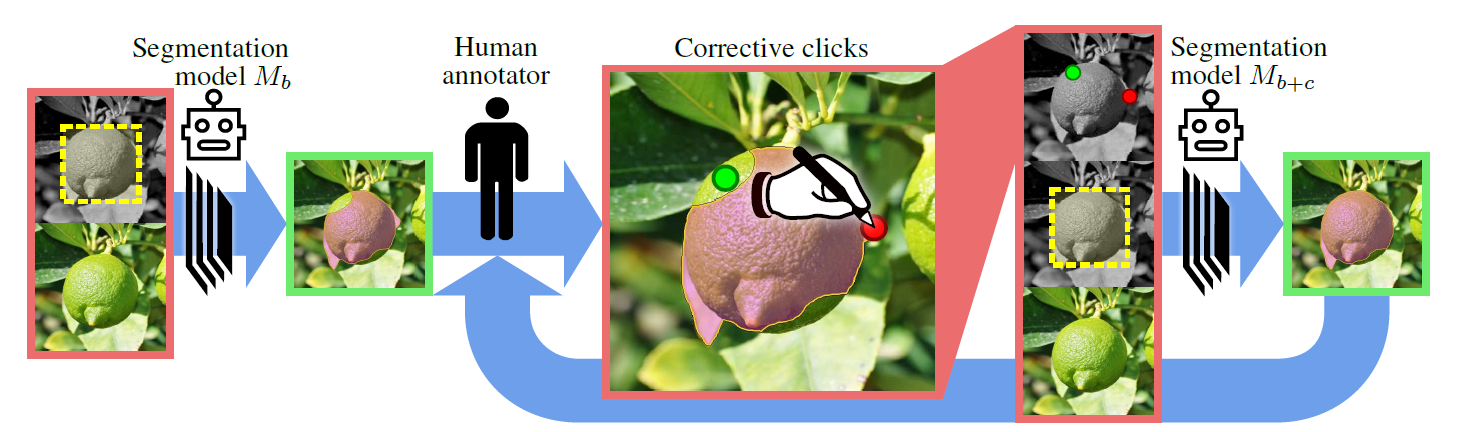
作者训练了三个模型,分别是:
![[19 CVPR] Large-scale interactive object segmentation with human annotators - 图2](/uploads/projects/z_zhang@is/c84c8bb850b4686deb77bc80338b9647.svg) :image+box→mask,基于Deeplabv2 ResNet101在ADE20K的子集上训练;
:image+box→mask,基于Deeplabv2 ResNet101在ADE20K的子集上训练;![[19 CVPR] Large-scale interactive object segmentation with human annotators - 图3](/uploads/projects/z_zhang@is/9098f8eb1ebff1ef8e401f2214756bc5.svg) :image+box+corrections→mask,基于Deeplabv2 ResNet101在ADE20K的子集上训练,训练集不与重合;
:image+box+corrections→mask,基于Deeplabv2 ResNet101在ADE20K的子集上训练,训练集不与重合;![[19 CVPR] Large-scale interactive object segmentation with human annotators - 图5](/uploads/projects/z_zhang@is/1bcba9e3e65a718e681fe213a3b83f86.svg) :一个用于给分割质量无参考打分排序的决策树(主要用于结果筛选),在COCO的一个子集上训练,输入有以下五个维度:
:一个用于给分割质量无参考打分排序的决策树(主要用于结果筛选),在COCO的一个子集上训练,输入有以下五个维度:- 最后一轮的点击数;
- 轮数;
- 当前轮次和上一轮次之间的∆IoU;
- 当前轮次中的单击与上一轮次的掩码之间的最大距离;
- 点击与上一轮次的掩码之间之间的平均距离。

1. Boundary click or region click?

用于修复的点是点在边缘好还是点在前景或者背景的最大错误区域好?
作者通过实验得到的结论是点在前景和背景的最大错误区域会好一点,实验结果如下图: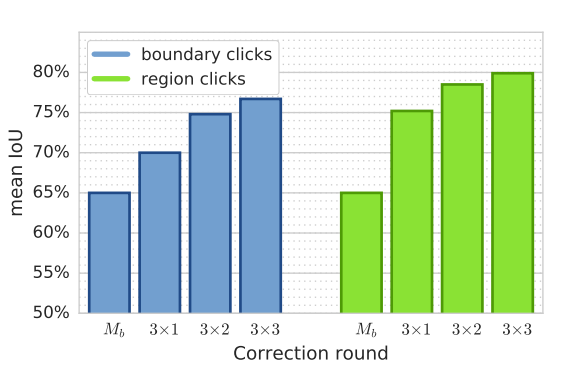
他们给出的理由如下:
- 区域点击更加鲁棒,再点击出现扰动的时候也在区域大致的中心位置,而边界点击经常偏离;
- 点击区域可以提供有关需要添加或删除的内容的更明确信息。
个人感觉:点击边界可以提供更好的范围信息,在训练时加上bias也许可以避免点击偏离问题。
2. Clicks encoding
目前对于点的编码方式有三种1.distance map, 2. Gaussian point,3. a simple binary disk。
实验结果有点神奇,效果最好的竟然是binary disk!
并且作者说将上一轮预测的Mask作为一个通道输入进来,对结果也没有提升。
3.Number of clicks and rounds
这个实验关于点击轮数和每次点击的次数的平衡问题。
(不过现在为了更好地mNoc,一般处理时点击一次出一次Mask来判断是否达到要求。)
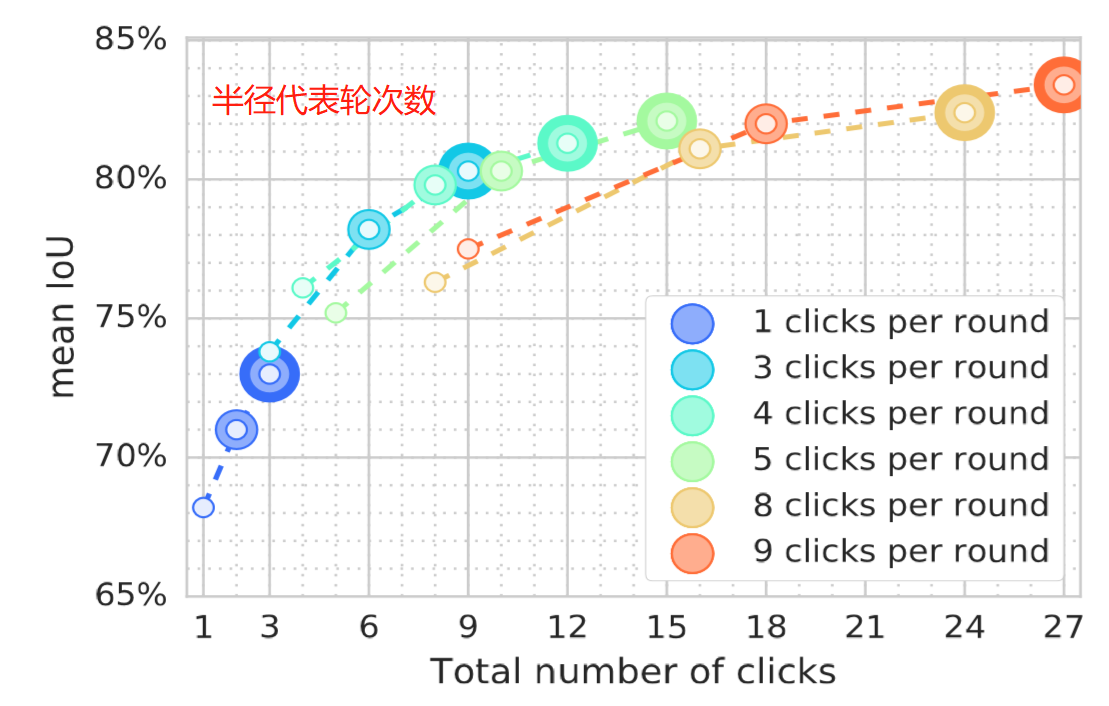
实验结果如上图,图画的很好看。作者推荐使用 3 × 3,4 × 2或者 5 × 2这种配置。
4. Class-agnostic or class-specific?
作者得出的结论是,class-specific的模型对于见过的类别来说,只能提升初始的分割结果,在添加后续的修正点后,class-agnostic 和 class-specific 两种模型是没有显著区别的,因此没有必要训练class-specific的模型。
ADE20K中几乎没有关于Giraffe🦒的类别,只有149张🐂,因此在ADE20K上训练,Giraffe🦒相当于是Unseen的类别。
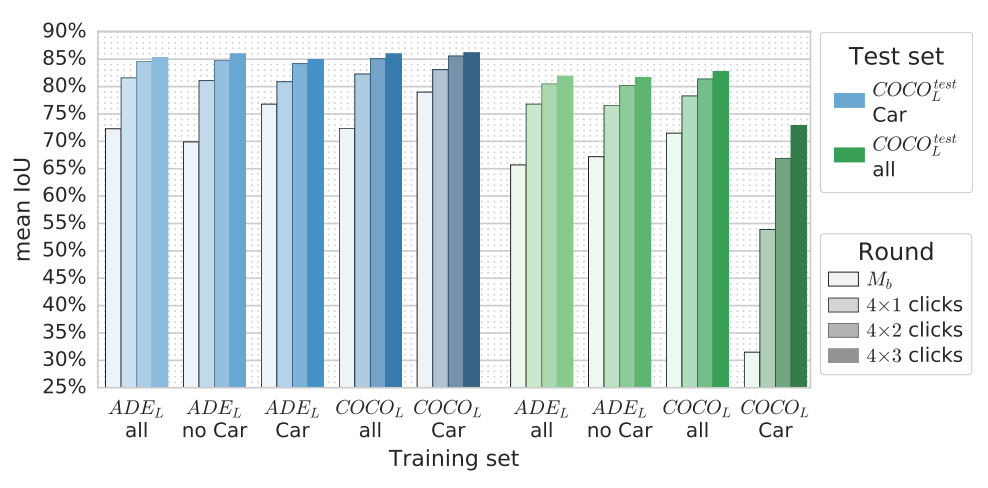
用户行为分析
一些用户行为的总结,对后续后续算法设计和论文支撑也许有用:
- 对于大型实例(大于80×40像素),COCO多边形标注中平均每个实例有33.4个顶点(总体上为24.5个顶点)。假设顶点数为线性时间,我们估计最初用多边形注释COCO所需的时间为每个大型实例108秒(基于论文中的数据)。我们要求我们的注释者在每个实例中花费至少180秒的时间来进行注释,在实践中,平均每个实例需要136s;
- 采用了双用户验证,两个人标注同一个算两个人的mIoU,这一点可以参考;
- 点击时间的时间花费比确定Mask分割的是不是足够好的时间要短;(这样看一轮多次点击可能有道理?)
- 60%的点击是按照错误区域从大到小进行的;
- 区域点击次数几乎与错误区域的面积成线性增长;
- 平均时间随着轮次的增加而增加;

若有收获,就点个赞吧
0 人点赞
