论文题目:Memory Aggregation Networks for Efficient Interactive Video Object Segmentation
作者单位:
主要看点:
该工作很大程度上受到了 FEELVOS 的启发,在看本文之前可以先看下 FEELVOS。下面的描述也都是通过和 FEELVOS 对比展开的。
FEELVOS 是给定初始帧的 Mask 来分割之后的所有帧,该工作中为当前帧的分割引入了全局匹配信息 (通过对比当前帧像素和初始帧Mask的在embedding空间中的相似度,直接传递)和局部匹配信息(当前帧像素和上一帧的预测在embedding空间中的相似度,两两传递)来预测当前帧的 instance mask。
交互分割的工作流程和普通的视频分割不同,初始帧的mask不再提供,取而代之的是用户输入的scribble标注,另外交互过程可以多轮进行(如下图),每一轮的初始帧不局限于是第一帧。
那么如何保留 全局匹配 和 局部匹配 的思想到交互分割上呢?如何更好的利用 scribble 累计的交互信息呢?这就是本文在解决的问题。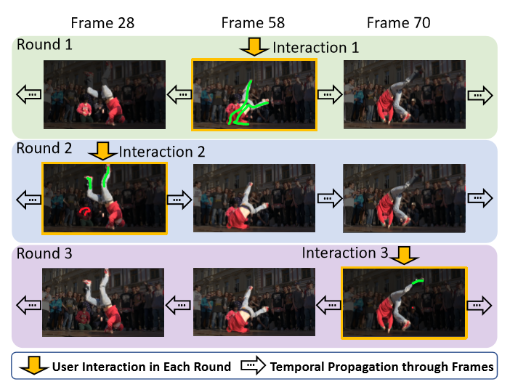
方法部分:
方法主要分为三个部分:
- pixel embedding encode:把 RGB frames 编码到嵌入空间,使得属于同一个物体的pixel距离近,不同物体的pixel距离远;
- interaction branch:利用用户的scribble输入,embedding feature,和上一轮的mask 分割 交互帧instance (更好的交互帧mask给其他帧提供了更好的参考);
- propagation branch:利用 pixel embedding 将用户注释帧(Global)和前一帧(Local)的信息知识传播到当前帧,再依据上一帧的Mask预测当前帧。
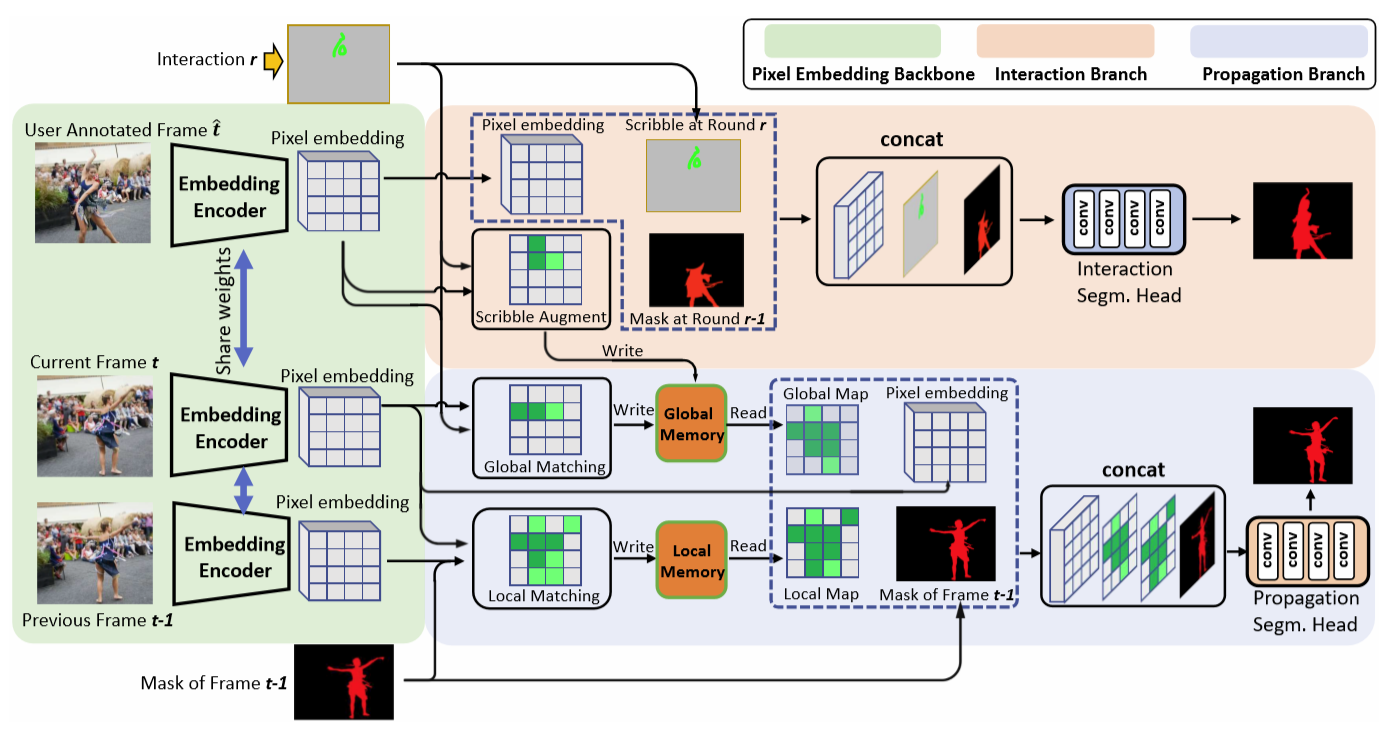
Pixel Embedding Encode.
同 FEELVOS,通过这个模块来学习一个 embedding 空间,在这个空间中,属于同一个物体的的像素距离近,不同物体的像素之间的距离远。
作者采用如下的距离计算在嵌入空间中的两个 vector ![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图5](/uploads/projects/z_zhang@is/585d379c8dcf33667ebdb9abf85ae6b6.svg) :
:![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图6](/uploads/projects/z_zhang@is/6d7e554b90ce40ca3d1fbfd60819eaa6.svg) ,
,
对于这个 embedding network 作者采用了 DeepLabv3+ (ResNet101) 作为 backbone,然后添加了一个 embedding layer (3 × 3,channel = 100,Output Stride 为 4)。
Propagation Branch.
在FEELVOS中,作者提出了 Global Matching 和 Local Matching 相结合的方式。
对于 Video Object Segmentation,初始帧的Mask是提供的,
Global Matching 计算 当前帧 和 初始帧 的分割区域的 distance map,Local Matching 计算 当前帧 和 上一帧 的分割区域的 distance map,
这两个 distance maps 对当前帧的预测提供了丰富的先验信息,
Global Matching 给当前帧直接传递初始帧的信息, Local Matching 使得信息可以在相邻两帧之间传递,
示意图如下: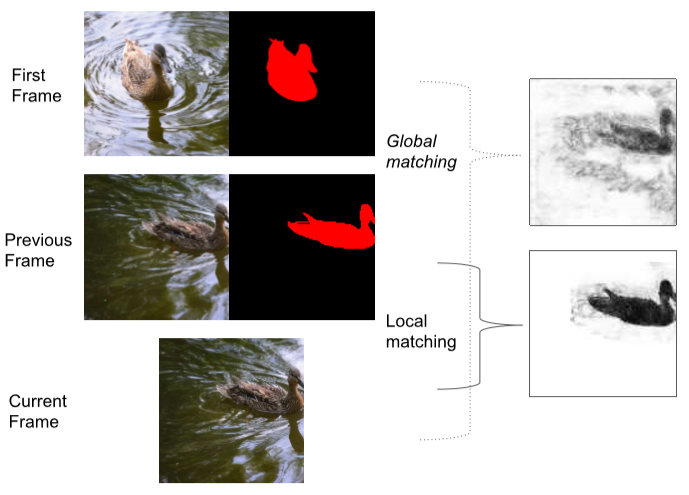
对于交互分割来说,并没有初始帧的mask提供,但是初始帧有用户提供的 scribble,那么上面这套方法 Grobal Matching 部分就不能直接拿来用了,但是 Local Matching 部分还是可以的。
下面要改变下 Grobal Matching, 既然没有 init Mask,那么直接用 scribble 来当作 init Mask 好像也不是不可以?
看左边的部分,Grobal Matching 就变成和scribble的区域做 grobal matching 了,当前帧每个pixel和 scribble 的区域计算距离。具体形式化如下:
首先定义一个第 t 帧第 r 轮的 global matching map ![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图9](/uploads/projects/z_zhang@is/f9544e27b0e7f4eb2efd8e27991128d4.svg)
因为是交互分割,所以存在多论预测,这个轮次 r 之后再解释:![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图10](/uploads/projects/z_zhang@is/2272aff65d58549779ea4d8fa1f5ec5f.svg) :t-th frame 的所有像素(with a stride of 4 in the embedding space);
:t-th frame 的所有像素(with a stride of 4 in the embedding space);![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图11](/uploads/projects/z_zhang@is/7ed17f6907cac4c3008299b40dc1d07b.svg) :t-th frame 在 r-th round 的时候的用户标注的像素。
:t-th frame 在 r-th round 的时候的用户标注的像素。
如下计算 global matching map:![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图12](/uploads/projects/z_zhang@is/c9abc5420cd18569d1a8649b681e3f03.svg) 。d(·)在上一节定义过了。
。d(·)在上一节定义过了。
对第 t 帧第 r 轮 local matching map ![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图13](/uploads/projects/z_zhang@is/0770c68c4b579cd2e6169d9c06c8ebf7.svg) :
:![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图14](/uploads/projects/z_zhang@is/d1f42aeb4acb7987d9c3c45cc1bca998.svg) :(t-1)-th frame 属于 o-th _object 的已经被分出来的pixels;
:(t-1)-th frame 属于 o-th _object 的已经被分出来的pixels;![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图15](/uploads/projects/z_zhang@is/cc9ef3f96070efac894cdb1c73a65a68.svg) :表示_p点周围不远于k个像素的邻居。(为了避免受到 noisy 像素的过多影响,只考虑标注像素一定范围距离内的 Pixel)
:表示_p点周围不远于k个像素的邻居。(为了避免受到 noisy 像素的过多影响,只考虑标注像素一定范围距离内的 Pixel)
local matchingmap 计算如下:![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图16](/uploads/projects/z_zhang@is/41cf67a7fe4ce1fd989f4dfc5b8cf97e.svg) ,其中
,其中![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图17](/uploads/projects/z_zhang@is/04c2f7056b5ecd16153ff4f60ef08254.svg) 。
。
通过上述方式,Grobal Matching就能用到交互分割里面了,不过这只是在第一轮,也就是 r = 1 的时候,在交互分割中,用户可以浏览初始分割效果,并在不满意的帧上做进一步的 交互(添加scribbles)
那么这时又会有新的GT提供出来(由scribble标注),那么肯定要利用好这个信息,但是当然不能把之前初始帧的scribble给忘掉。
所以交互分割的方法必须得具有对多轮scribble标注的信息整合的能力。
一个简单的想法就是先计算出所有帧的 Grobal Matching Maps, 记录到一个存储器,时候有新的 scribbles 添加后在更新对应Pixel值。
这个存储器作者称作 Global Map Memory ![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图18](/uploads/projects/z_zhang@is/21632243ce662bd93138166740b4c38c.svg) ,
,![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图19](/uploads/projects/z_zhang@is/72d90af29ffec084046109ed9b7cc248.svg) , n , o, h, w 分别表示帧的个数、 目标物体,和embedding feature maps的高和宽。
, n , o, h, w 分别表示帧的个数、 目标物体,和embedding feature maps的高和宽。
我们来看下,随着轮数 r 增加的更新过程:
为了统一表达,这个初始化为全1 (表示都不接近目标物体), 之后每一轮(包括初始轮)每个帧的 global distance map ![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图21](/uploads/projects/z_zhang@is/590c211d3af9bc15201173d42f519bc4.svg) 如下更新:
如下更新:![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图22](/uploads/projects/z_zhang@is/5572e501adfca81c91b76ccb1457ecd1.svg) 。
。
也就是说每个像素取多轮所有scribbles标注的像素的embedding vector中取距离最小的那个距离,这一过程用示意图表示出来如下(越黑表示越相似):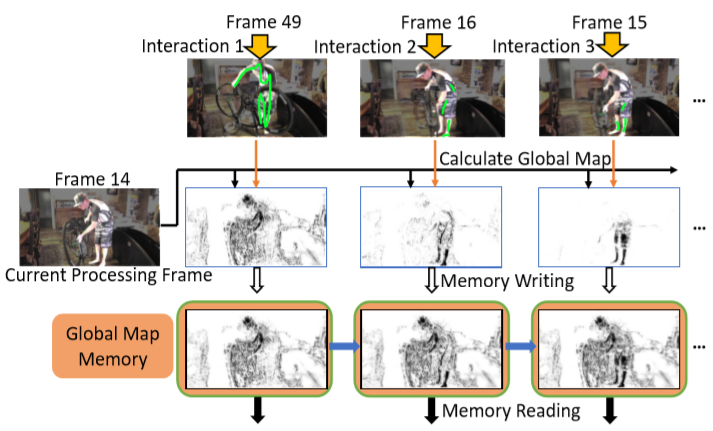
从图中可以看到,虽然没有在第14帧上交互,但是多次的交互都在![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图24](/uploads/projects/z_zhang@is/b939864fe1bd0b48a194ba2ef4c11bc5.svg) 上留下了痕迹。
上留下了痕迹。
那么在存在多轮交互的情况下, Local Matching Maps 应该如何利用多轮交互带来的福利呢?
我们先想下 FEELVOS, 在 FEELVOS 中,Local Matching 的信息是从初始帧开始,两两传递到当前帧的,
在传递过程中,传递的下一帧依赖于上一帧的预测,误差会在这个过程中被逐步放大,如果当前帧和初始帧距离较远,就会受到很大干扰。
但是交互过程中,用户交互帧不一定是第一帧(初始帧),有可能是一个视频序列中的任意一帧,
那么对于当前帧来说,选择距离自己最近的交互帧传来 Local Matching 信息似乎是最准确的。
但是,这种假设也不完全合理,我们要知道,随着交互轮数的增加,分割结果会变得越来越好,
比如在第8轮交互距离较远的帧传来的local matching信息未必比第1轮较近的帧传来的信息差,
因此作者在这里设定了一个遗忘机制(forgetting mechanis),做法是只考虑最近的 R 轮分割的 local matching 信息。
为了实现以上两个改进,作者定义了一个 Local Map Memory ![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图25](/uploads/projects/z_zhang@is/8711dd40c1d188cacd20f979a1dfa06a.svg) ,
,
也许是为了编程方便,![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图26](/uploads/projects/z_zhang@is/14b67c8e2bf99edd53359166e9ac5ac6.svg) ,相比 Global Map Memory 多了一个维度 r 用来记录所有轮次的信息。
,相比 Global Map Memory 多了一个维度 r 用来记录所有轮次的信息。
那么在t-th frame 在 r-th round 的时候,把 local matching map 直接写入内存:![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图27](/uploads/projects/z_zhang@is/d4a4f188251ec2e11397da75c73eb91f.svg) ,
,
最终当前帧 t-th frame 在 r*-th round 的时候可以从取出最终结果:![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图29](/uploads/projects/z_zhang@is/6680d623266f002d949e33eeaf8801db.svg) 。
。
过程如下图所示:
Interaction Branch.
因为后续所有帧都用到了上一帧的Mask作为依靠,所以在每一轮中,一个好的初始分割 Mask 是很重要的。
在 FEELVOS 中,初始帧 Mask 是 GT,直接给定,所以质量是有保证的,
在交互分割中,作者单独拉出啦一个分支,利用用户的交互 scribbles 来分割交互帧。
这个分支利用embedding feature, scribble输入和上一轮的mask  cat 起来输出分割结果。
cat 起来输出分割结果。
这份分支不管要输出mask,还有记录和累计用户的交互信息,以便给后续的跟个提供参考。作者把增强后的scribble标注信息存入 global memory 。
具体地增强方式如下:
:所有像素(with a stride of 4 in the embedding space);![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图34](/uploads/projects/z_zhang@is/30093ace49f301c24a82fb8683ecd1a3.svg) :用户标注的像素。
:用户标注的像素。
对于每个像素![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图35](/uploads/projects/z_zhang@is/a194cf54d440c197412b83d86c3e6f2d.svg) ,计算于与标注的中的最近的像素的相似性。
,计算于与标注的中的最近的像素的相似性。
为了避免受到 noisy 像素的过多影响,作者只考虑标注像素一定范围距离内的 Pixel。这里定义里一个表示p点周围不远于k个像素的邻居。
那么利用 scribbles 增强的map![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图38](/uploads/projects/z_zhang@is/12bdbbc53fe0cf89fb7f4be22ce549ea.svg) 可以定义如下:
可以定义如下:![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图39](/uploads/projects/z_zhang@is/246214760fbb1e14b50c3c22e6a14609.svg) ,其中
,其中![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图40](/uploads/projects/z_zhang@is/5fb53d36c319100fe129d22d632fe624.svg) 。
。
实际效果如下图:
交互帧的 Global Matching Map 的更新有点特殊,不能和自己的分割结果在embedding空间计算,
而是用之前的记录和直接和![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图42](/uploads/projects/z_zhang@is/4b5e2ea9295342e84ce5765775da0326.svg) 比较取最小值:
比较取最小值:![[20 CVPR] Memory Aggregation Networks for Efficient Interactive Video Object Segmentation - 图43](/uploads/projects/z_zhang@is/5ddce45be99eda259826541880e1202b.svg) 。
。
实验结果:
消融实验,看两个matching机制的影响,看来Global Matching的作用更大一些。
下面是关于Local Matching两个参数的实验,一个是 Local windows 和 记忆的轮数 R (看来记忆两轮就够了):

横向的性能对比提升似乎也很多,具体可以看论文。

若有收获,就点个赞吧
0 人点赞
