论文题目:Dual Super-Resolution Learning for Semantic Segmentation
作者单位:
代码:Github
主要看点:
一个把 Super-Resolution 和 Sematic Segmentation 结合起来的工作,聚焦于高分辨率的特征表示。
目前对于高分辨率特征表示有两个思路
- 始终保持高分辨率,如 DeepLabs 中的 atrous convolution ,还有比如最近的 HRNet。
- hallucinate 高分辨率特征,比如像U-Net, 在 decoding 过程中利用 skip-connection 帮助提升分辨率。
但是作者称,这两种方式都引入了计算代价,关键他们还使用了高分辨率的原始图像作为直接的输入。
如果降低输入分辨率,这些方法的性能会骤降,比如 ESPNetv2 和 DeepLabv3+ 的输入分辨率从 512×1024 降为 256×512 ,它们的精度会降低 10% 左右。
这篇文章的思路很简单:分别用两个并列的分支超分语义分割的feature和普通意义的上的SR feature,之后再用语义分割支路的特征参考SR特征,进行细节修复。从实验效果来看,对性能提升很显著。
方法部分:
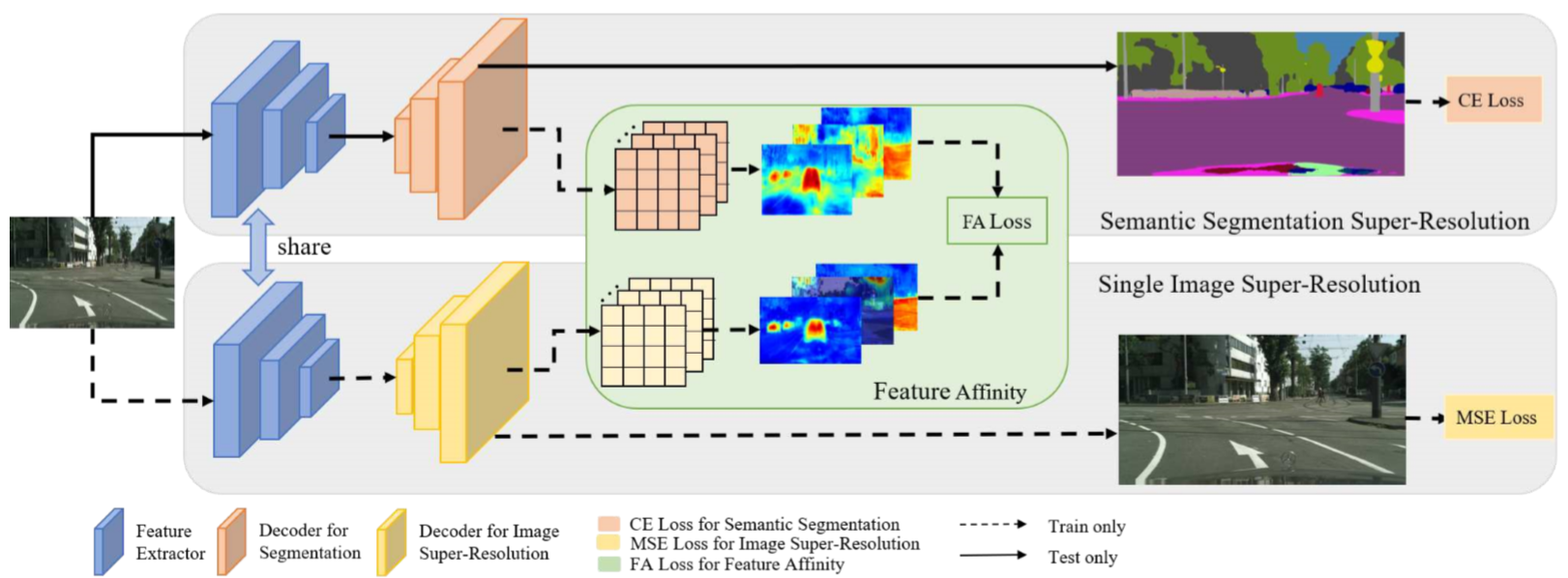
Semantic Segmentation Super-Resolution (SSSR)
这个是网络上方的那个分支,它的输出大小相对于输入是 2× ( 512×1024 —-> 1024×2048),
示意图如下: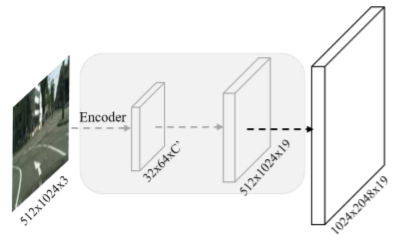
Single Image Super-Resolution (SISR)
其实光靠 SSSR 得到 2× 的高分辨率表征还是太依靠 hallucination。
作者在这里引入了图像超分辨率的思想,希望SSSR hallucination 的 feature 可以参考下 SISR 出来的 feature 来做修正。
这一路的监督就是重建出高分辨率的图像。
我们可以看下 SSSR (中间列) 和 SISR 的可视化特征,SISR 的特征包含了更多细节的结构信息。
Feature Affinity Learning (FA)
FA旨在学习SISR和SSSR分支之间的自相似矩阵的距离,其中相似矩阵主要描述像素之间的成对关系。
![[20 CVPR] Dual Super-Resolution Learning for Semantic Segmentation - 图6](/uploads/projects/z_zhang@is/bfb2c41b3cf2fb4daeb989ae853c69a7.svg)
![[20 CVPR] Dual Super-Resolution Learning for Semantic Segmentation - 图7](/uploads/projects/z_zhang@is/0e17f560869859423941677d51041f1d.svg) 只两路的自相似矩阵。|| || 是 norm, 其中p = 2, q= 1
只两路的自相似矩阵。|| || 是 norm, 其中p = 2, q= 1
为了节省内存,这部分作者又对 feature 做了1/8的采样然后计算,
另外,为了避免两路特征之间分布不一致造成的训练不稳定,在FA操作之前,SSSR分支做了一个特征变换模块,由1×1 conv,BN,ReLU组成。
Loss function
综合三部分,损失函数如下所示:![[20 CVPR] Dual Super-Resolution Learning for Semantic Segmentation - 图8](/uploads/projects/z_zhang@is/faced1af6d8a4ed32c7125b405cf4507.svg)
实验结果:
不同消融实验如下:
直接添加上SISR有效似乎是因为作用于share的encoder。
方法在不同分辨率输入的提升也是普遍的: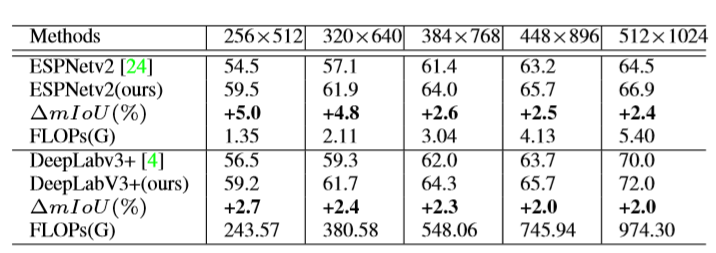
这里是在CityScapes上在不同backbone上的提升:
作者也进行了一些可视化对比,SISR分支的SR效果如下: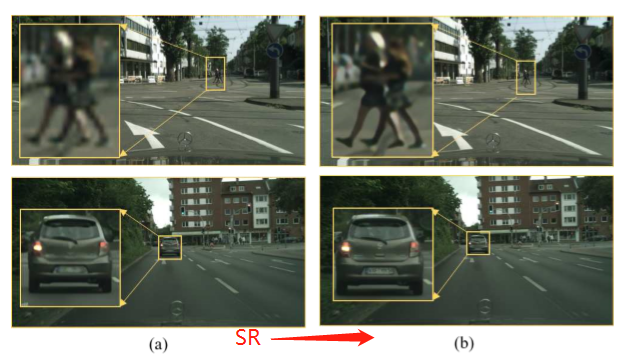
SSSR分支ESPNetv2 (a) 和 改进后的 (b) 的特征对比,的确区域变得更完整均匀。
另外作者还在 Human Pose Estimation 上验证了方法有效性。

若有收获,就点个赞吧
0 人点赞
