

1. [17 ICCV] Extreme clicking for efficient object annotation
这个方法不是用来主要做交互分割的,而是优化了之前bbox标注的逻辑。 作者称使用极值点来生成bbox比直接拖拽来生成tight要快。原因是:
- 起笔落笔的角落并不一定在物体上,用户需要去找极值点;
- 标注完成后可能没有紧紧包裹住物体,需要再次拖拽调整bbox;
- “单击”,“拖拽”,“调整”是三个不同地任务,需要用户在使用时需要做思想转换;
- 画的矩形和角点都是虚构的,这种心理意象“Mental Imagery”也增加了用户负担。
极值点的优点:
- 极限点不是想象的,而是物体上的物理点,这使得它们易于定位;
- 减少了心理意象;
- 注释器只执行一个任务,因此避免了任务切换;
- 不需要bbox调整步骤;
- 不需要“提交”按钮;四次单击后注释终止。
虽然这么说,在CVPR2020上,IOG似乎提供了一个有效的解决思路: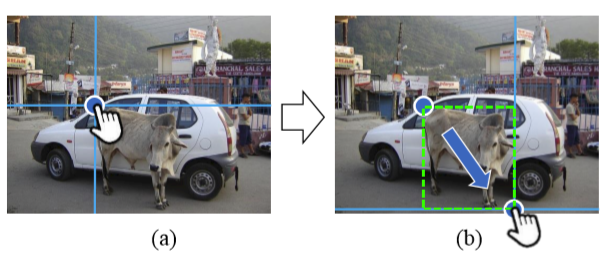
为鼠标提供了一个水平和竖直的参考线,这样减少了“Mental Imagery”,当然这个参考线大家很早就在用了,可以在这里(Polygon RNN++)试试。容易判断落点位置。在实际交互中,传统的bbox交互方式只需要确定两个关键点,交互成本大致是2.5个点,而极值点需要认真确定4个点。
在一些图片上,确定极值点也会出现一些困难,如下图: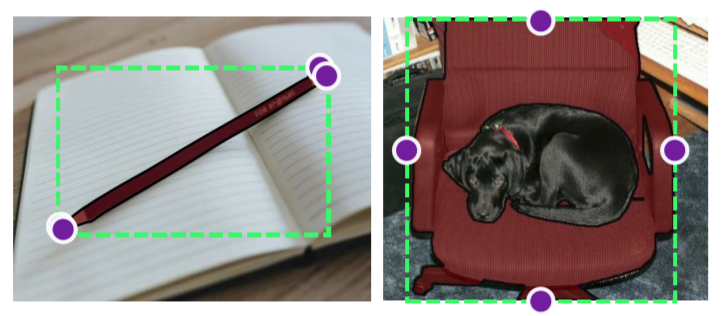
尽管如此,基于极值点的方法似乎包含了更多的信息,不光提供了bbox还提供了四个准确的边界信息,这个标注逻辑的提出激发了后续的DEXTR。
2. [18 CVPR] Deep Extreme Cut: From Extreme Points to Object Segmentation
简称:DEXTR
代码链接:Project
方法部分:
这个工作的做法是将之前的极值点作为一个单独的通道(和原图形成四通道)作为输出,然后直接预测。使用的网络是 ResNet-101 + PSP (Deeplab-v2 model pre-trained on ImageNet, and fine-tuned on PASCAL for semantic segmentation)。
在文中,该网络是可以允许输入第5个点的(在最大错误区域的边界),并且作者采用了 Online Hard Example Mining (OHEM)【1】 的方式进行训。在PASCAL VOC 2012 validation dataset上困难用例的测试结果:
实验观察:


1. Bounding boxes vs. extreme points
作者说extreme points比bbox好👀。
2. Loss
基于Class-balancing的Loss好于传统standard cross entropy Loss。
3. Full image vs. crops
极值点方法做了 50 pixel 的放松Crop,相比于Full image输入有显著提升。
4. Atrous spatial pyramid (ASPP) vs. pyramid scene parsing (PSP) module
在DEXTR中PSP比ASPP效果好。
5. Distance-map vs. fixed points
Fixed point比distance-map好。
【1】 A. Shrivastava, A. Gupta, and R. Girshick. Training regionbased object detectors with online hard example mining. In CVPR, 2016.
3. [19 MICCAI] Large-scale interactive object segmentation with human annotators
代码链接:Github
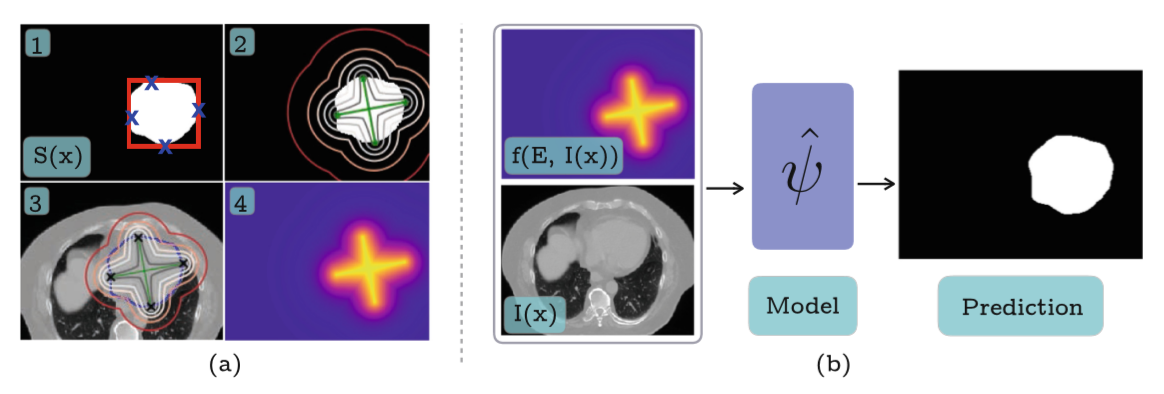
这篇文章和DEXTR的区别是输入从之前的四个高斯点变成了下图中的十字形的Heatmap: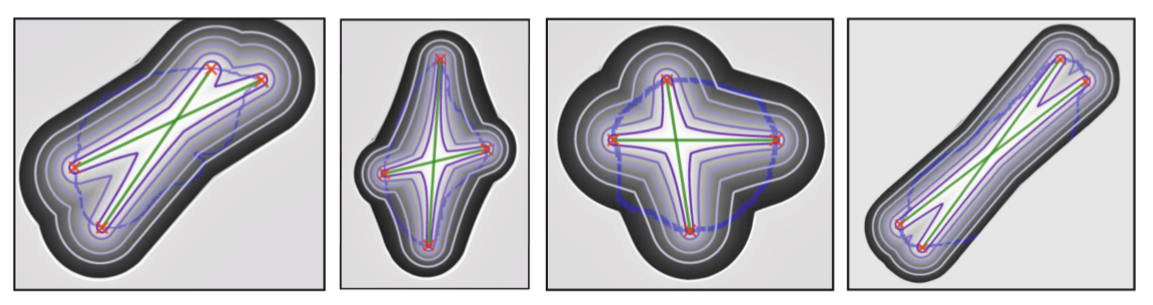

若有收获,就点个赞吧
0 人点赞
