想法非常出彩的两篇工作,BRS中提出了一个有趣的思路,f-BRS又将它进行了升华。
核心思想如下:
💡 用户点击的位置不一定按照预期会被网络预测为正确的标签,因此可以用backpropagating的方式更新输入的distance map或者网络的其他参数,让预测至少符合用户交互点的预期。
需要注意的是这种方式是基于 distance map 输入的,经过我们的实验,那种高斯半径输入的click几乎不会发生预测错误的情况,因此直接使用backpropagating就不合适了。
1. [19 CVPR] Interactive Image Segmentation via Backpropagating Refinement Scheme
作者及单位:
代码:Github
主要看点:
交互分割中 Backpropagating 的应用。 作者对交互点和预测图的结果的观察很有意义,想法非常棒的一个工作。
方法部分:
模型结构:
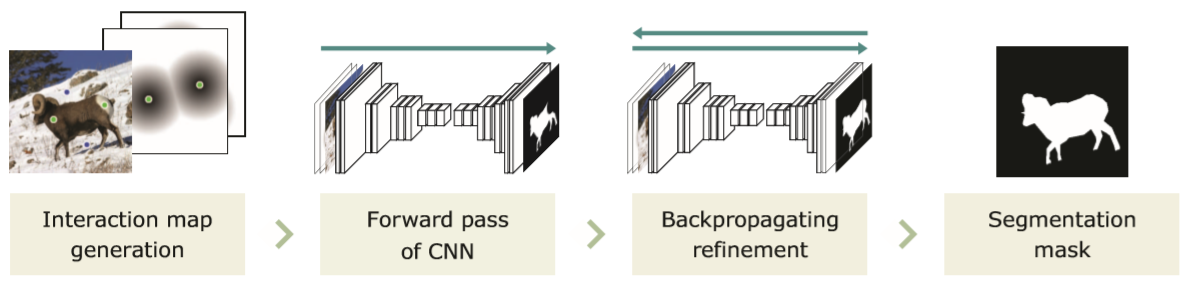
如上图,模型分为两个部分,一个粗糙预测网络和一个精细修复网络。
测试过程:
训练过程与以前的工作类似,但作者在 inference 过程中提出了有意思的干货。
用户点击的点一定会被分配到正确的标签嘛?作者说答案是不一定的。
如果发生这种情况,模型的预测是不符合用户的交互期望的,就会产生损失,那么可不可以在测试过程中优化参数,使得模型再次预测可以预测的符合用户的交互期望呢?
可以看下可以优化的部分有哪些:1. 图像; 2. 交互的distance map ;3. 网络参数。
如果更新网络参数,作者称可能会带来网络的灾难性遗忘,因此最好的选择是更新distance map (其实更新图像也能得到等效的效果吧)。
可以通过最小化下列能量函数实现:![[19/20 CVPR] BRS and f-BRS - 图7](/uploads/projects/z_zhang@is/ff3e29de838294c1faacabb67664fcab.svg) ,其中
,其中![[19/20 CVPR] BRS and f-BRS - 图8](/uploads/projects/z_zhang@is/4e35150887eb95dbfb1d19a9ed079e35.svg) 是distance map (用于优化的)。
是distance map (用于优化的)。
来看下这两个能量项目![[19/20 CVPR] BRS and f-BRS - 图9](/uploads/projects/z_zhang@is/b11c93ee8ca34eb9418bb465a6f2173e.svg) ,
,
![[19/20 CVPR] BRS and f-BRS - 图10](/uploads/projects/z_zhang@is/f2b1eb229eca9248c6dd92a48f0e0044.svg) 是 corrective energy ,定义如下:
是 corrective energy ,定义如下:![[19/20 CVPR] BRS and f-BRS - 图11](/uploads/projects/z_zhang@is/db6f97f79007473488b9dc7c6e2dd31a.svg) ,l(u)是用户标记,1或者0。
,l(u)是用户标记,1或者0。![[19/20 CVPR] BRS and f-BRS - 图12](/uploads/projects/z_zhang@is/5100b7ae9a9f9c6194bfab0b7ce979b2.svg) 是用户标注的像素位置。
是用户标注的像素位置。![[19/20 CVPR] BRS and f-BRS - 图13](/uploads/projects/z_zhang@is/b101f0ff5d32e111d0edc7327c7bd1d6.svg) 是网络输出的。是 inertial energy,定义如下:
是网络输出的。是 inertial energy,定义如下:![[19/20 CVPR] BRS and f-BRS - 图15](/uploads/projects/z_zhang@is/7cc08d33970795c41bd07fb535556354.svg) ,这里,
,这里,![[19/20 CVPR] BRS and f-BRS - 图16](/uploads/projects/z_zhang@is/6b272394e20b2985c61530eb35ecb801.svg) 表示初始的distance map。用这个符号来表示我也很迷,下标i可能是代表第i次用户交互?
表示初始的distance map。用这个符号来表示我也很迷,下标i可能是代表第i次用户交互?
为了更新distance map,对求导,![[19/20 CVPR] BRS and f-BRS - 图18](/uploads/projects/z_zhang@is/bc221dd2370735d0b3f903e247aee393.svg) 。
。
在实践中,使用 L-BFGS 算法,去更新 interaction map。
以上的过程是迭代运行的,注意不是交互迭代,而是每次交互都要迭代。
下图展示了distance迭代的效果,下面三张图得仔细看才能看出来。
从消融实验中来看,效果还是很显著的
f-BRS中的一段话对这个方法的总结很好:
They find minimal edits to the distance maps that result in an object mask consistent with user-provided annotation. For that, they minimise a sum of two energy functions, i.e. corrective energy and inertial energy. Corrective energy function enforces consistency of the resulting mask with userprovided annotation and inertial energy prevents excessive perturbations in the network inputs
并且给出了更清晰的表达式:![[19/20 CVPR] BRS and f-BRS - 图21](/uploads/projects/z_zhang@is/bdd6c40f73edd91d5d530a0a4df5eeef.svg) ,
,
其中![[19/20 CVPR] BRS and f-BRS - 图22](/uploads/projects/z_zhang@is/c9117e8a97bb13189d1684bb4187ee85.svg) 是网络在(u, v)处的输出, l 为交互的label (0或1),用户的交互点集合为
是网络在(u, v)处的输出, l 为交互的label (0或1),用户的交互点集合为![[19/20 CVPR] BRS and f-BRS - 图23](/uploads/projects/z_zhang@is/099cbeb8caff1221f37b1ede4b66696c.svg) ,x为输入的interaction map , ▲x是改变量。
,x为输入的interaction map , ▲x是改变量。
一些困惑😐:
作者说
The training-free conversion, based on the proposed BRS, can convert various CNN-based vision algorithms into interactive ones effectively and easily.
作者说模型可以把一个任何一个模型变成可交互的(因为distance map可优化),并给出下图说明:

首先,c和c不一定相等,这个作为示意图可以理解,
但是疑问是卷积和从(u×u×c)变成了(u×u×2c),多出的卷积核的参数如何确定?
是从RGB通道上拷贝?这也不太对,因为Interaction maps是2个通道,而RGB是三个通道。
是随机的参数?这似乎可以行得通,因为测试的时候 Interaction maps 会迭代优化来适应这个奇怪的卷积核。作者在这里并没有解释清楚。
在BRS的实现中,这多出来的卷积参数是训练的来的,作者release的模型配置的输入可以看出:
文中还有一些符号不清晰,比如在下图中: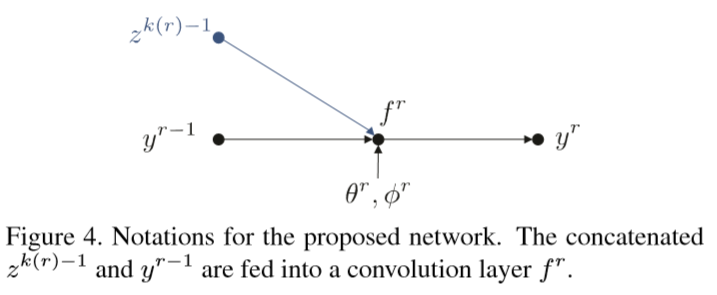
作者的解释如下:
我很难清楚地知道这些符号代表的含义,作者在文中也没有明确的定义。我的猜测如下:
上标 r 应该指当前迭代的轮次(BRS每次交互需要多次迭代 Distance map);
其他的符号我没有才出来具体是什么,z 也许是 Distance map。
z 在图上的上标是 k(r) - 1,在文中的描述为 r - 1 ,不清楚这个不一致是什么,另外函数 k( ) 是什么?🙆♀️
2. [20 CVPR] f-BRS: Rethinking Backpropagating Refinement for Interactive Segmentation
简称:f-BRS (feature backpropagating refinement scheme)
作者及单位:

代码 (nice code):Github
讲解视频:YouTube
主要看点:
- 如何解决之前 backpropagating 需要多次反向以及正向传播整个网络的问题(耗时)。
- 这个工作非常用心了,从开源代码,工具,以及视频制作都很棒。
方法部分:
再来回一下BRS中问题的定义:,
其中是网络在(u, v)处的输出, l 为交互的label (0或1),用户的交互点集合为,x为输入的interaction map , ▲x是改变量。
BRS中是在 interaction map 上做的修改, f-BRS将这个过程迁移到了特征层面:
找一个辅助的参数 p,用这个参数去影响特征,这个参数的初始状态是 z 。这个参数在初始状态是不影响特征层的预测的,也就是说![[19/20 CVPR] BRS and f-BRS - 图32](/uploads/projects/z_zhang@is/97ade4f710b721a0f0b80fbc33e783ed.svg) ,
,
之后去寻找一个![[19/20 CVPR] BRS and f-BRS - 图33](/uploads/projects/z_zhang@is/e980435a675ff479fe66f4f1a240de0d.svg) ,使得
,使得![[19/20 CVPR] BRS and f-BRS - 图34](/uploads/projects/z_zhang@is/61e2e94b277adfcc4af7c13bf87c2e7a.svg) 更符合用户的交互预期。
更符合用户的交互预期。![[19/20 CVPR] BRS and f-BRS - 图35](/uploads/projects/z_zhang@is/4207d6d5bbf070ac93a5725058ddac65.svg) 。
。
关键问题是,这个辅助参数 p 选取的形式。为了达到更好的更正效果,作者提出p的选择应该保证以下原则:
- 更新p不能只影响局部 (localized effect);
- 在训练分割网络的时候,这一块是不用更新的。
作者在f-BRS这个工作中选取的 p 是 channel-wise scaling (weight) 和 bias。这两个参数改变会在全局上影响输出,而不是local sptail region上。
下图展示了 channel 和 spatial 上的作用效果: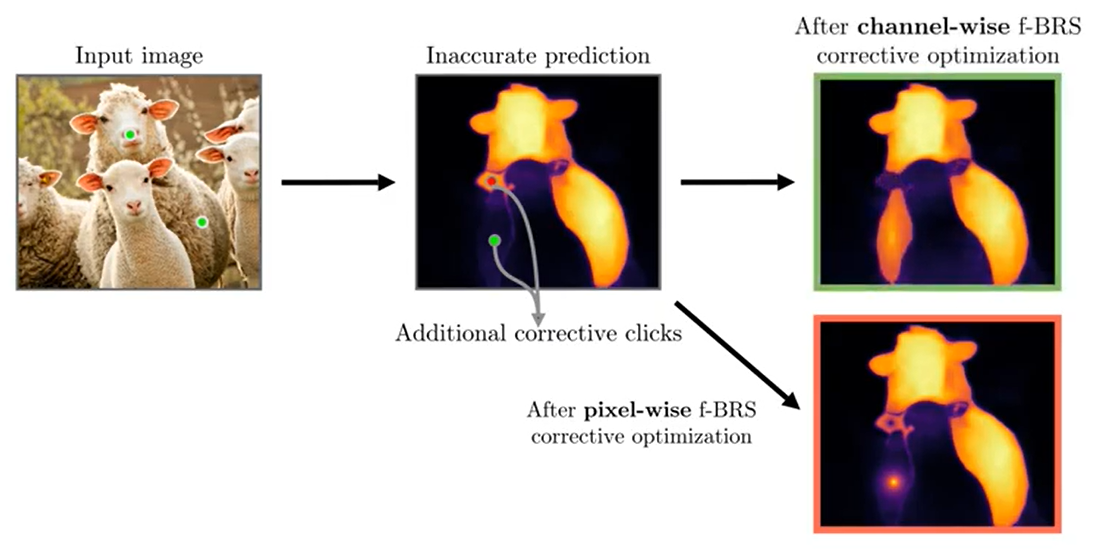
可以看到 spatial 上的容易造成 local overfitting。
假设一个中间层为![[19/20 CVPR] BRS and f-BRS - 图37](/uploads/projects/z_zhang@is/0e78b008787f380af15fc9feab28907b.svg) ,设它的 h 是channel 数目。这里定义一个 reparameterized function
,设它的 h 是channel 数目。这里定义一个 reparameterized function ![[19/20 CVPR] BRS and f-BRS - 图38](/uploads/projects/z_zhang@is/5d11c314d01848adb7e33e5e600e41fa.svg)
![[19/20 CVPR] BRS and f-BRS - 图39](/uploads/projects/z_zhang@is/6bded26114ccc1612d8d55d32a53cce0.svg) ,其中
,其中![[19/20 CVPR] BRS and f-BRS - 图40](/uploads/projects/z_zhang@is/b2c132d0597d8425c7da5b1d85d5f5c9.svg) ,分别是a vector of scaling coefficients 和 a vector of biases,当 s = 1 和 b = 0 的时候不影响网络的预测。
,分别是a vector of scaling coefficients 和 a vector of biases,当 s = 1 和 b = 0 的时候不影响网络的预测。
g()可以当作无意义的,代表网络实现的具体操作。
具体的工作流程如下GIF所示:
Zoom-In for interactive segmentation
这是一个提速的Trick,也能提高一些精度。它的提出基于这样一种假设,前两个交互点已经可以把物体的大致scale预测出来,因此在这个粗糙mask上放松一些边缘像素,crop后图基本上是包含目标物体的,但是size相比于原图会小很多。做法如下图所示:
实验结果:


你看作者对比的 baseline 中有 RGB-BRS,对这三个通道的update得到的效果比distance map还好😶,不过时间稍微长了点。这些模型的update的对象如下图所示: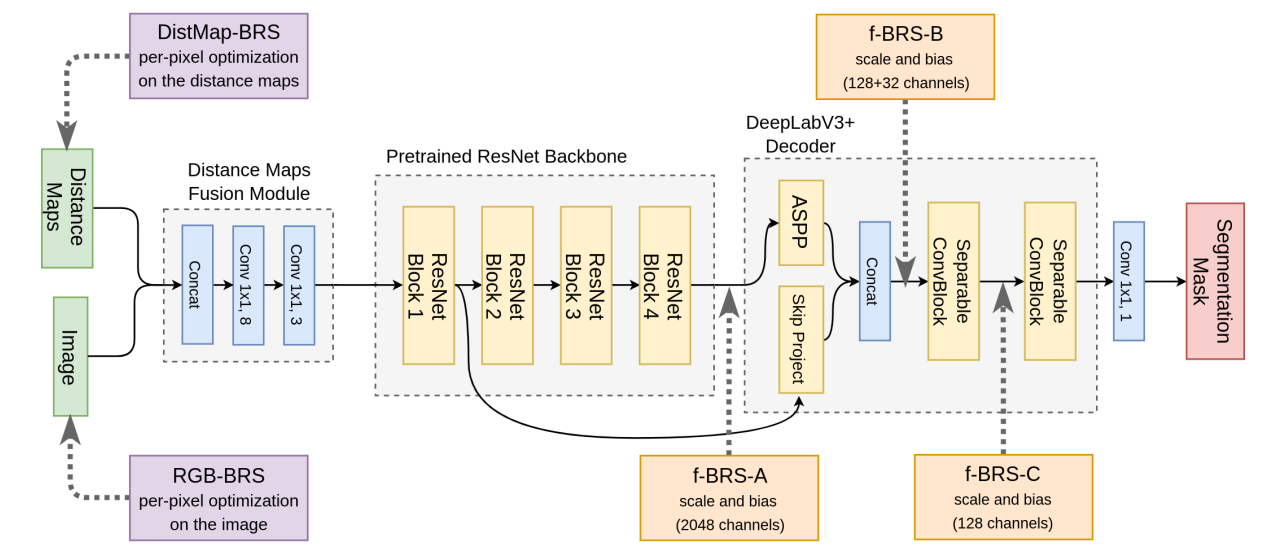

若有收获,就点个赞吧
0 人点赞
