这一系列工作是Sanja Fidler组做的:主页地址在这:Sanja Fidler
和传统的深度交互分割不太相同,之前的是生成概率图然后二值化输出结果(pixel-labeling problem),而这一些列工作是预测点生成标注多边形(polygon prediction task)。
这种方式看起来很炫酷,但是毕竟多边形没办法准确地贴合物体的边缘,一般情况下效果比不过传统方式。不过这个思想还是很值得一看的,指导意义也不一定局限在交互分割上。
1. Annotating Object Instances with a Polygon-RNN

主要看点:
- RNN预测点的序列;
- 交互方式(bbox交互->自动生成多边形顶点->调整顶点位置。
方法部分:
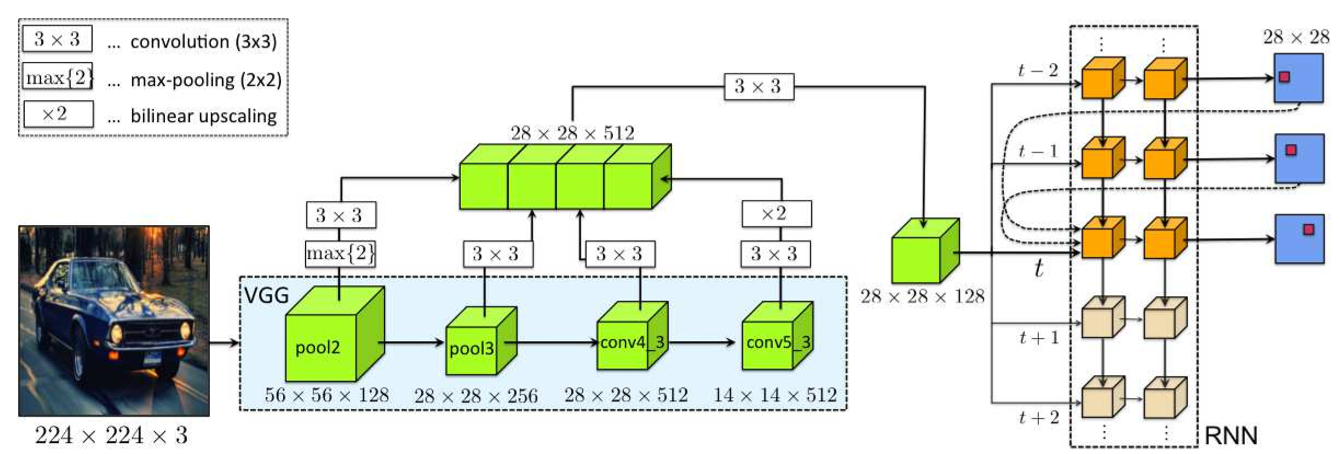
网络很简单,是VGG的多层的输出拼接压缩后送入Convolutional LSTM。
模型中Convolutional LSTM使用了两层,每一层是3×3卷积和16个通道 。
Convolutional LSTM姐解决的是一个分类问题,
输出编码成一个One-hot向量![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图5](/uploads/projects/z_zhang@is/8eb61118488c0719a9c56b9248b12f00.svg) (t-th step),维度是(D × D + 1),D是输出的边长,模型中为D=28。后面加的这个1是结束符的维度(end-of-sequence token)。
(t-th step),维度是(D × D + 1),D是输出的边长,模型中为D=28。后面加的这个1是结束符的维度(end-of-sequence token)。
输入为:
- CNN的特征;
![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图6](/uploads/projects/z_zhang@is/a847d97c1a9bd7ac9e4f363eec03747b.svg) 和
和![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图7](/uploads/projects/z_zhang@is/693712f56b31e68fef0efea28a72ca87.svg) ; (reshape成D×D)
; (reshape成D×D)![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图8](/uploads/projects/z_zhang@is/fa789fc92d00fa86a9cd17206d5cfc03.svg) 。 (reshape成D×D)
。 (reshape成D×D)
对于第一个点来说比较特殊,需要单独预测和训练(不需要RNN)。作者在CNN的最后添加了两个分支,第一个分支预测边缘,第二个分支把上一个分支的边缘预测和图像特征Cat起来作为输入,预测第一个点的位置。
训练细节:
在RNN的每个时间步使用交叉熵损失,损失是预测点和GT上的顶点之间的计算出来的,而不是最后的分割结果。
作者为了不过度惩罚接近GT顶点的错误预测,在每个时间步平滑目标分布。他们将non-zero probability分配给D×D输出网格中距离为2的位置。
在训练的时候,前两个步骤的和是用GT的顶点,而不是模型的预测。
2. Efficient Interactive Annotation of Segmentation Datasets with Polygon-RNN++
代码链接:Project & Pytorch
Demo: Online Polygon RNN++
主要看点:
- 该系列的第二篇工作,基于Polygon RNN的改进如下:
- CNN结构的改变;
- 利用强化学习优化训练过程;
- 使用GNN增加了输出的分辨率,注意Polygon RNN的输出仅仅为28×28;
- 使用online fine-tune,进一步缩短标记新数据集的时间。
方法部分:
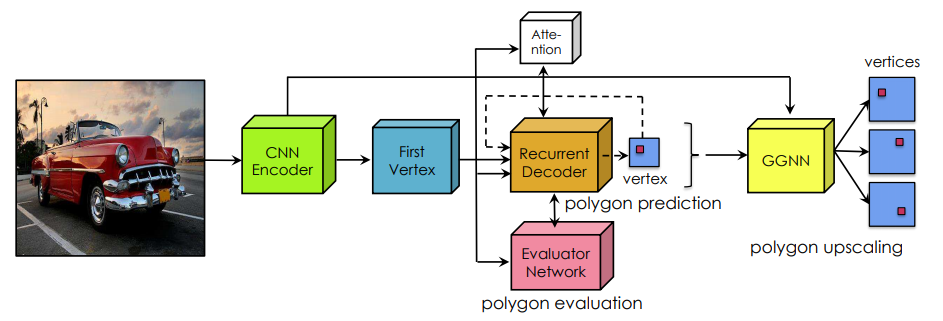
CNN Encoder(  )
)
主体网络如上图所示,我们一部分一部分的来看,首先是CNN Encoder( ),它的结构如下: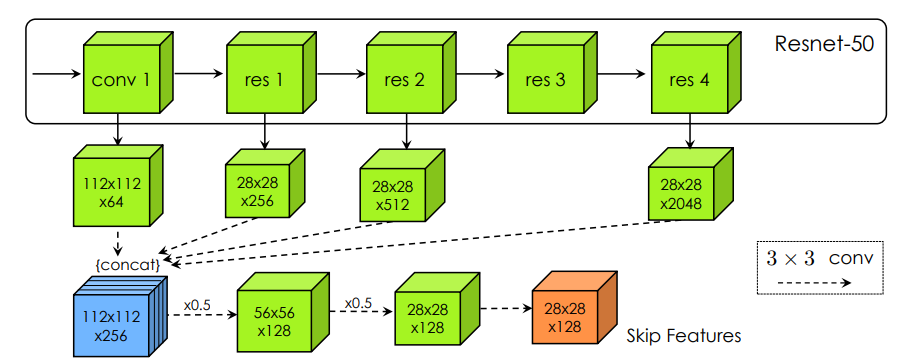
结构没有什么新颖之处,但是要注意这个蓝色部分 ,这一部分跨层连接到后面的GCN
,这一部分跨层连接到后面的GCN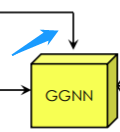 中。这个跨层连接保证了后续从28×28的顶点预测转换为128×128的输出图。
中。这个跨层连接保证了后续从28×28的顶点预测转换为128×128的输出图。
Recurrent Decoder :
:
首先还是两层的ConvLSTM,第一层64通道,第二层16通道。
与Polygon RNN相比,迭代过程中引入了注意力机制,具体来说:![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图18](/uploads/projects/z_zhang@is/bf43a898ff33e18948f146bc2776ec3c.svg)
其中o为元素乘,其中x是CNN的输出 ,
,![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图20](/uploads/projects/z_zhang@is/67d7899f6573ec589d685db9823ba248.svg) 和
和![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图21](/uploads/projects/z_zhang@is/0d12403667d19212b81220e949980eba.svg) 是两层ConvLSTM在t-1步的hidden states。
是两层ConvLSTM在t-1步的hidden states。![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图22](/uploads/projects/z_zhang@is/3d6bf6ae5dc7c38ee6f46c135316e12d.svg) 和
和![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图23](/uploads/projects/z_zhang@is/cca3cc5a97de654fee137d1c8a81135f.svg) 是两个将和映射到
是两个将和映射到![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图26](/uploads/projects/z_zhang@is/25a012f500d9b471ae1646e271a2d193.svg) 的1×1卷积。
的1×1卷积。![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图27](/uploads/projects/z_zhang@is/13f7af916af11b58eccaa3eeb2d9de07.svg) 将其压缩成D×D的atttention map。
将其压缩成D×D的atttention map。
这个![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图28](/uploads/projects/z_zhang@is/8593257feb82dc0ff39fd1051c7b1348.svg) 和上两个步骤的和还有初始点cat在一起,送入下一步,下面是的可视化:
和上两个步骤的和还有初始点cat在一起,送入下一步,下面是的可视化:
作者认为这个Attention机制可以更好让RNN关注到更相关的区域。
另一个问题是关于第一个 vertex 的预测,在Polygon RNN中是在CNN后面加了两个单独的分支(一个预测边缘一个预测点)。Polygon RNN++中只用了一个分支同时预测边缘和点。
训练策略:
下面是训练过程,在Polygon RNN中,作者在每一步都使用 cross entropy loss。但是这样存在三个问题:
- MLE 过分惩罚了预测点(比如有的点预测到了GT的边缘上而不是顶点附近);
- 模型优化的metric和评估指标 IoU十分不同;
- 在训练的时候,前两个步骤的和是用GT的顶点,而不是模型的预测。这种训练被称为teacher forcing,它造成了训练和测试之间的不匹配( exposure bias problem )。
为了解决以上问题,作者提出了一种基于强化学习的训练策略,首先模型初始的时候还是用的MLE训练的,之后把 Recurrent Decoder 看作了 sequential decision making agent。
Reward: Polygon围成的Mask。
TBD
评估网络:
第一个点的选取是很重要的,它会影响后续所有点的预测。比如在物体被遮挡的情形中,第一个点应该远离被遮挡的产生的边界,以保证后续点可以围绕在目标物体上。
那么选择哪一个点作为第一个点呢?(从First vertex mask 中分数最高的K个候选点中选取)
作者为这每个first vertex生成的Polygon通过Evaluator Network(下图)无参考地估计一个IoU值。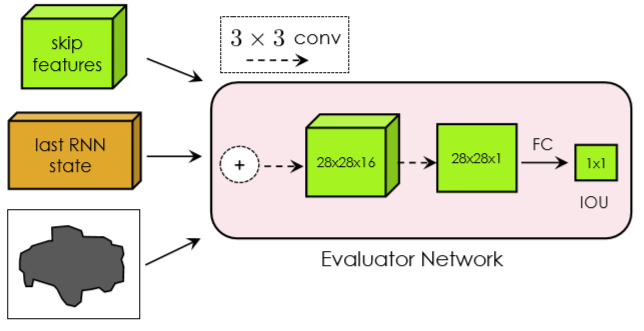
这个单独的网络是用在测试过程中的,训练过程并不使用。该网络接收以下三个输入:1. CNN输出的特征;2. ConvLSTM最后一个state tensor;3. polygon。输出为IoU值。
通过优化下面的损失训练该网络:![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图37](/uploads/projects/z_zhang@is/62c447f134f691ea3e55e00bb02bbfdd.svg) ,其中p映射为IoU,
,其中p映射为IoU,![[17/18/19 CVPR] Polygon-RNN / Curve-GCN - 图38](/uploads/projects/z_zhang@is/45abb62a7af21ee7dbd4f3a55ef1af3c.svg) 是采样的vertices围成的mask,m为GT。
是采样的vertices围成的mask,m为GT。
通过GNN上采样:

TBD
3. Fast Interactive Object Annotation with Curve-GCN
代码链接:Github

主要看点:
- 解决了Polygon-RNN两个工作中修正需要按照顺序(顺时针)来的问题;
TBD

若有收获,就点个赞吧
0 人点赞
