- [16 NIPS] Dynamic Filter Networks
- [19 NIPS] CondConv: Conditionally Parameterized Convolutions for Efficient Inference
- [20 CVPR] Dynamic Convolution: Attention over Convolution Kernels
- [20 arXiv] DyNet:Dynamic Convolution for Accelerating Convolutional Neural
- [19 ICCV] Dynamic Multi-scale Filters for Semantic Segmentation
- [20 ECCV] Hierarchical Dynamic Filtering Network for RGB-D SOD
- [20 ECCV] Conditional Convolutions for Instance Segmenation
看了 ECCV 这篇 Oral 工作后对动态卷积非常感兴趣,下面梳理一下有关的几个工作。
[16 NIPS] Dynamic Filter Networks
这个工作是动态卷积的鼻祖,用一个生成网络接收 一个条件输入 为另外一个输入生成特异性的卷积核。这个思路好棒。
Filter-generating network
接受一个视图的输入生成 n 个卷积核 ![[20 ECCV] Conditional Convolutions for Instance Segmenation - 图2](/uploads/projects/z_zhang@is/97d9829020ad6326052f3d423bf8e320.svg) ,
,
其中 s 是卷积核的大小,cB 是 Input B 的 Channel,
对于 dynamic convolution 来说 d = 1
对于 dynamic local filtering 来说 d = h ✖️ w
Dynamic Filtering Layer
Dynamic convolution

对于 Dynamic convolution 来说,Filter-generating network 就生成一个普通的卷积核作用于 Input B。
Dynamic local filtering layer
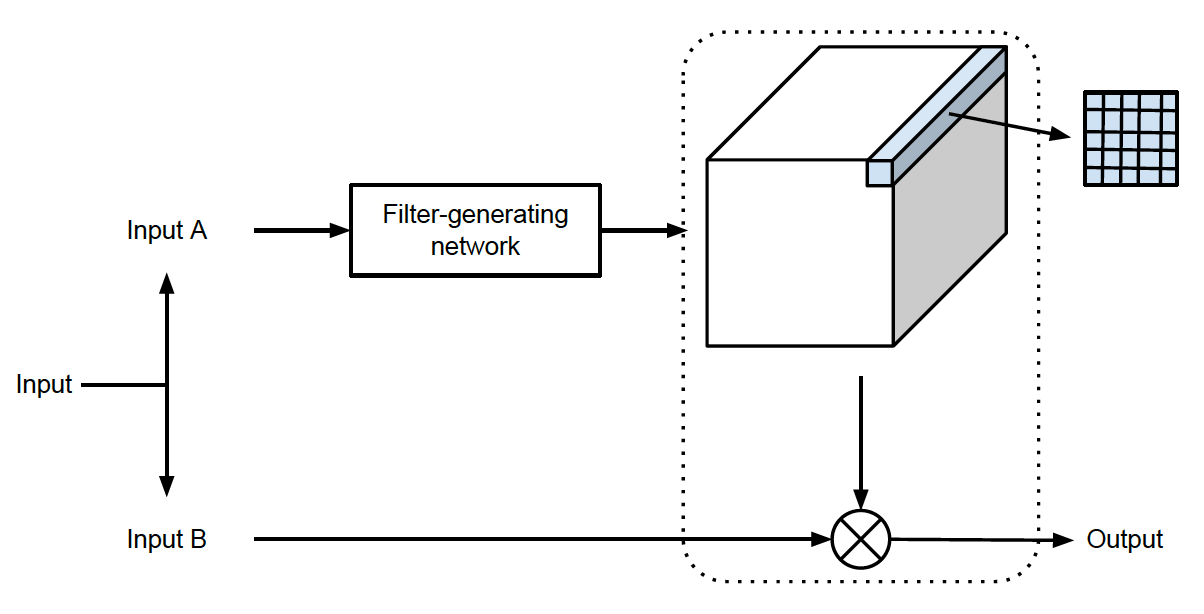
为每个位置生成一个卷积核,这样就做到了 not only sample specific but also position specific。
Demo on vedio
下面使用在视频上的一个例子:
[19 NIPS] CondConv: Conditionally Parameterized Convolutions for Efficient Inference
上面的工作是动态生成卷积核的,这个工作呢是生成了待选的卷积核然后进行加权组合的。
在一个层中常见的是进行多次卷积,然后整合,如下图:
这种可以表示为 ![[20 ECCV] Conditional Convolutions for Instance Segmenation - 图7](/uploads/projects/z_zhang@is/8e5e2c2c1c8987868d97fca05af6cfa9.svg)
可以看到,这需要做多次卷积,在进行整合。
不过在没有非线性层的情况下,上述式子其实可以等价成 ![[20 ECCV] Conditional Convolutions for Instance Segmenation - 图8](/uploads/projects/z_zhang@is/7e8a1251075b167bfeac6b421706d63d.svg)
这样就只要做一次卷积就可以了,减少了计算量。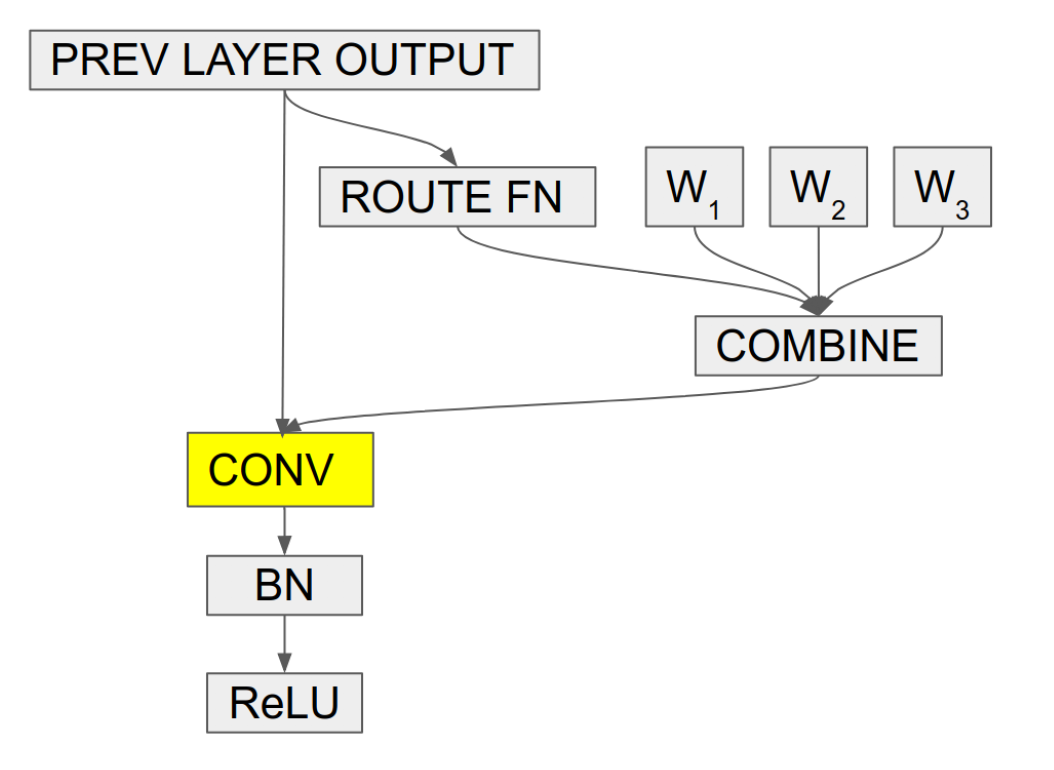
ROUTE FN 用来生成加权的权重,操作是 GAP 后,过一个 FC 层, 然后再 Sigmoid。
[20 CVPR] Dynamic Convolution: Attention over Convolution Kernels
这个和 CondConv 差不多,画的图好看多了🌚。
这个工作和 CondConv 应该是同期工作,出发点不一样, CondConv 从集成的思路解释, DynamicConv 从 Attention 角度解释。两个角度可以欣赏一下。
作者在文中也加入了和 CondConv 的对比,训练上的差异可以看看。
也可以化成这样:
形式化出来如下:
传统卷积:![[20 ECCV] Conditional Convolutions for Instance Segmenation - 图12](/uploads/projects/z_zhang@is/721ad75f4bc900c724cb0ac444d06bad.svg)
Dynamic Convolution: ![[20 ECCV] Conditional Convolutions for Instance Segmenation - 图13](/uploads/projects/z_zhang@is/cdf40cadbfe5523ea24fca586076b34c.svg)
和 CondConv 的区别是用 Softmax 替代了 Sigmoid。
[20 arXiv] DyNet:Dynamic Convolution for Accelerating Convolutional Neural
和上面两个也是类似的。直接看图就好了。本文作者又换了一个角度行文,也可以一看。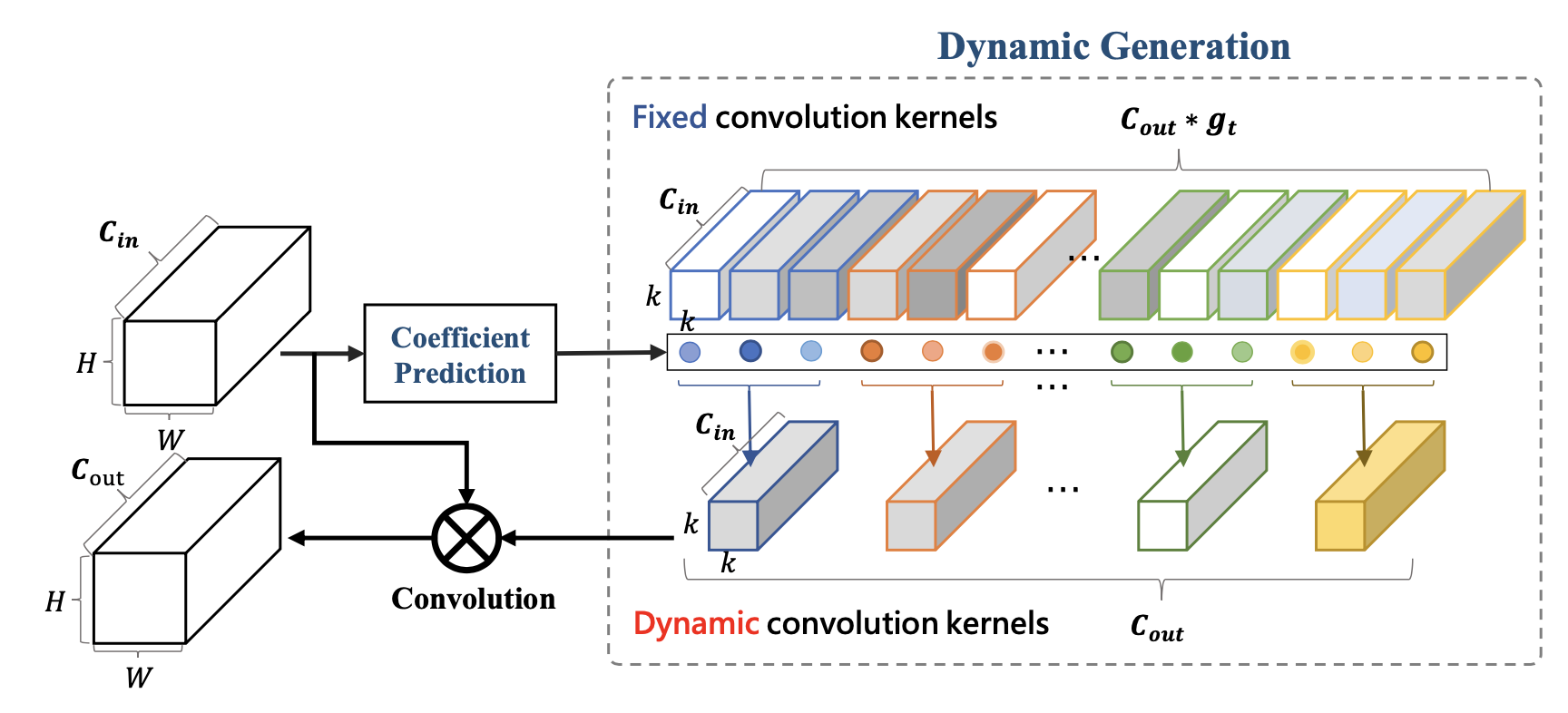

[19 ICCV] Dynamic Multi-scale Filters for Semantic Segmentation
Dynamic Filtering Network 用在生成多尺度卷积核上。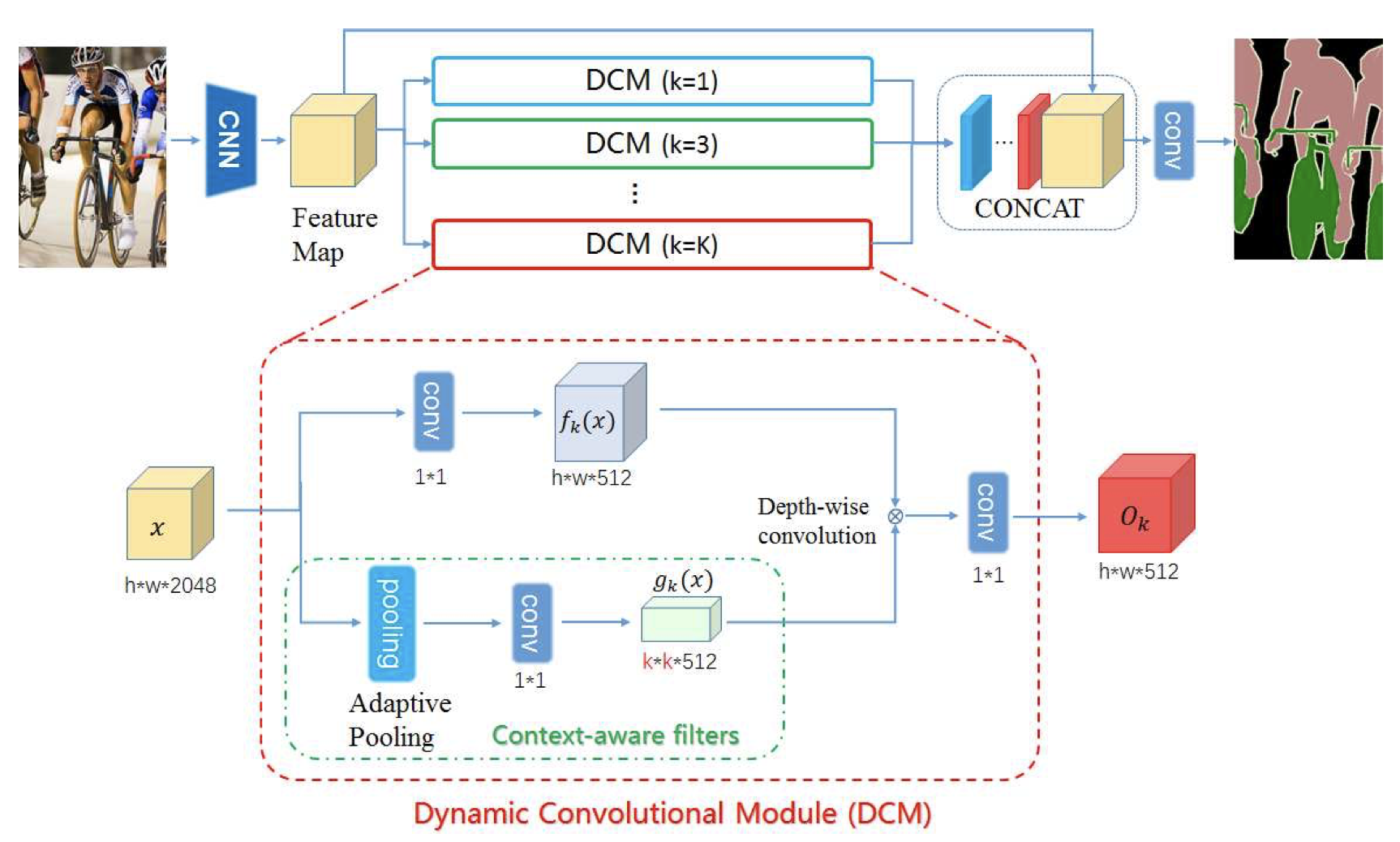
[20 ECCV] Hierarchical Dynamic Filtering Network for RGB-D SOD
代码:Github
Dynamic Filtering Network 在 RGB-D SOD 任务上的应用,这个看图就能明白了,和上一篇做语义分割的也比较类似。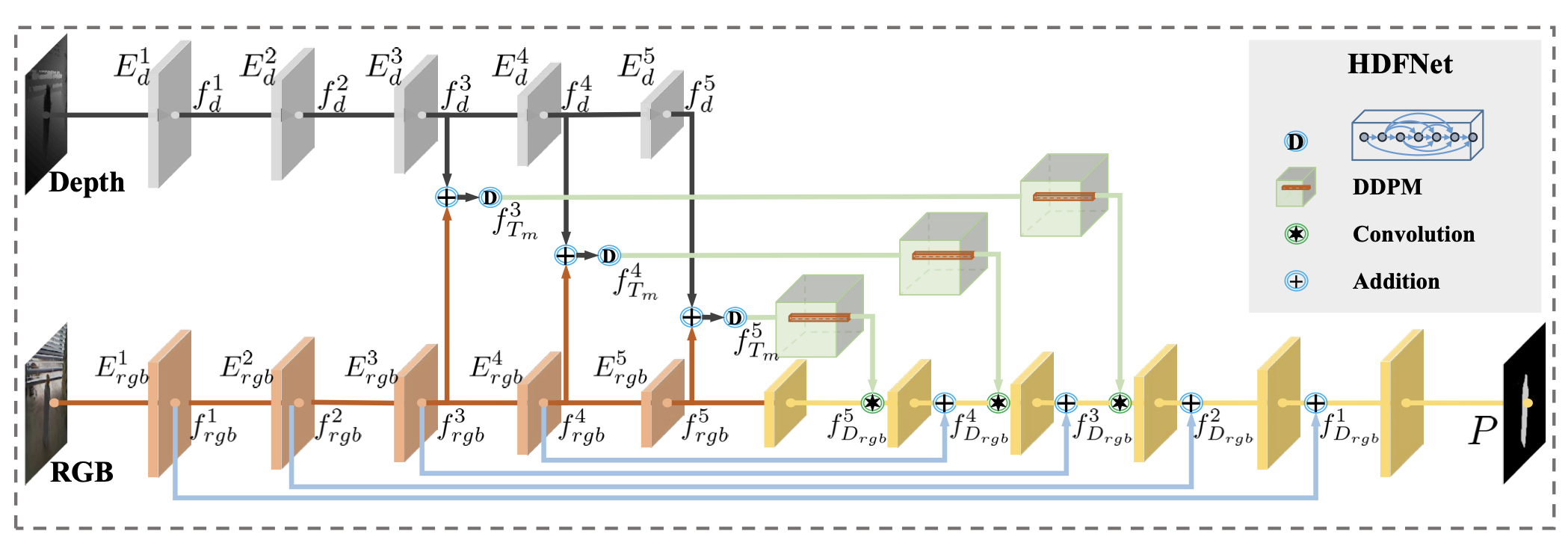

[20 ECCV] Conditional Convolutions for Instance Segmenation
代码:Github
相关讲解:知乎,视频(20:00开始)
知乎
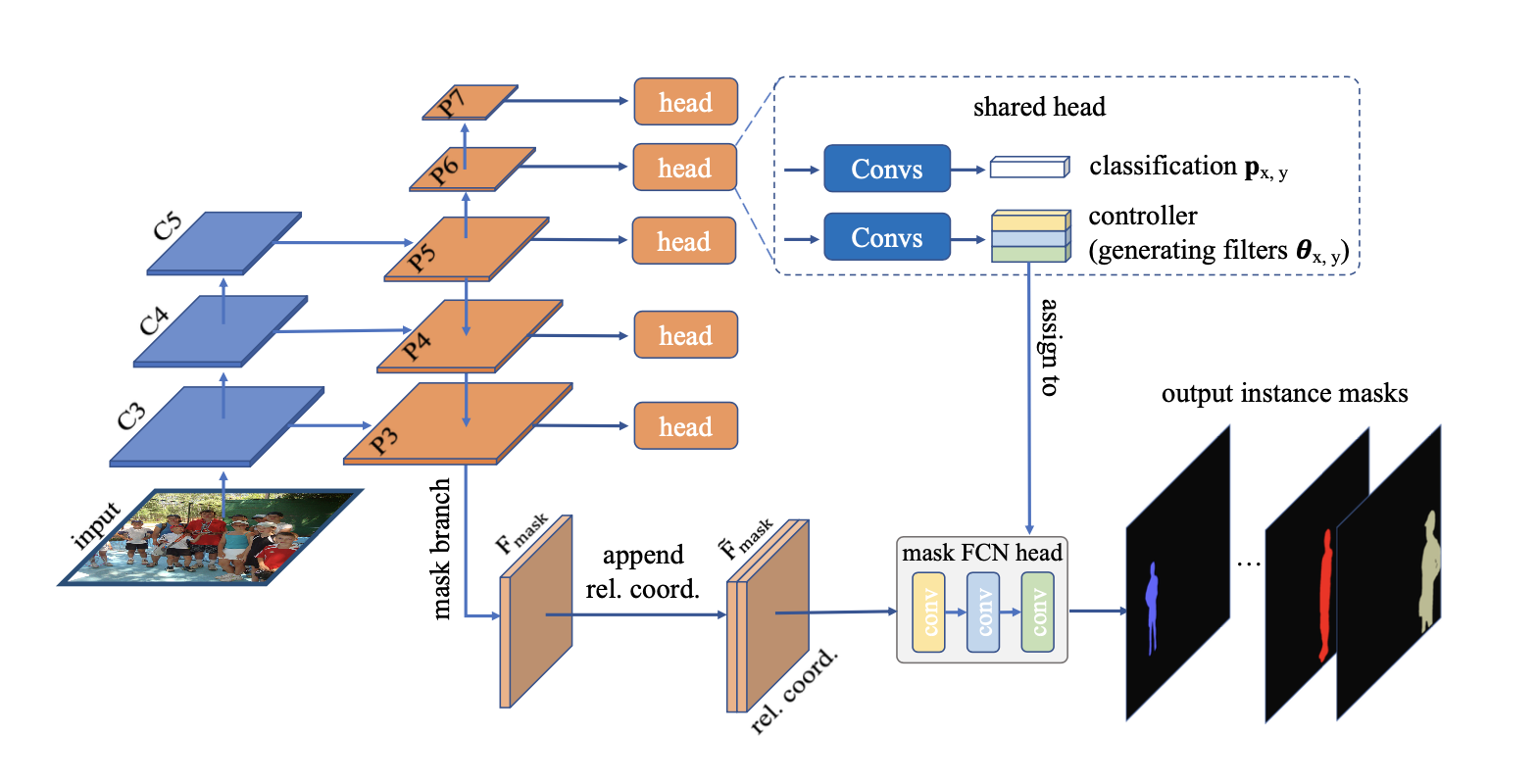
Dynamic Filtering 的代码实现
Batch 中每一个 sample 的每个位置都动态生成 Filter
这个实现来自 Hierarchical Dynamic Filtering Network for RGB-D SOD。策略是学习参数手动进行卷积。
'''https://github.com/lartpang/HDFNet/blob/49455f1215952ef4a11918b61ff391b923ce23ca/module/MyModules.py#L13'''class DepthDC3x3_1(nn.Module):def __init__(self, in_xC, in_yC, out_C, down_factor=4):"""DepthDC3x3_1,利用nn.Unfold实现的动态卷积模块Args:in_xC (int): 第一个输入的通道数in_yC (int): 第二个输入的通道数out_C (int): 最终输出的通道数down_factor (int): 用来降低卷积核生成过程中的参数量的一个降低通道数的参数"""super(DepthDC3x3_1, self).__init__()self.kernel_size = 3self.fuse = nn.Conv2d(in_xC, out_C, 3, 1, 1)self.gernerate_kernel = nn.Sequential(nn.Conv2d(in_yC, in_yC, 3, 1, 1),DenseLayer(in_yC, in_yC, k=down_factor),nn.Conv2d(in_yC, in_xC * self.kernel_size ** 2, 1),)self.unfold = nn.Unfold(kernel_size=3, dilation=1, padding=1, stride=1)def forward(self, x, y):N, xC, xH, xW = x.size()kernel = self.gernerate_kernel(y).reshape([N, xC, self.kernel_size ** 2, xH, xW])unfold_x = self.unfold(x).reshape([N, xC, -1, xH, xW])result = (unfold_x * kernel).sum(2)return self.fuse(result)
卷积操作可以分解成 1)取出局部的数值并展开 2)矩阵乘法 3)reshape 回去相应的维度。Conv = unfold + matmul + fold (or view to output shape)。
首先看一下 torch.nn.Unfold 这个类,这个类的作用是从一批输入张量中提取滑动局部块的内容。
以 2D 为例,输入是 (N, C, H, W), 那么输出就是 (N, C × kh × kw, L) ,L是可以滑动的次数
一个简单的例子
a = torch.randn(1, 3, 10, 12)a_unf = torch.nn.functional.unfold(input=a, kernel_size=(4, 5),dilation=1, padding=0, stride=1)print(a_unf.shape)# 输出为:torch.Size([1, 60, 56])# 60 = 3 * 4 * 5# 56 = (10 - 4 + 1) * (12 - 5 + 1)
在作者代码中 self.gernerate_kernel(y) 会生成一个 (N, xC self.kernel_size 2, xH, xW) 的 tensor,
进一步被 reshape 成 (N, xC, self.kernel_size 2, xH, xW)self.unfold(x) 会生成一个 (N, xC self.kernel_size 2, xH, xW) 的 tensor,
进一步被 reshape 成 (N, xC, self.kernel_size 2, xH, xW)
由 result = (unfold_x * kernel).sum(2) 得到 (N, xC, xH, xW) 的 tensor,完成动态卷积。
Batch 中每一个 sample 都动态生成 Filter,但每个位置共享卷积
实现一:
这个的实现方式只需要让上面的 self.gernerate_kernel(y)生成 (N, xC self.kernel_size * 2, 1, 1)的 tensor 就可以了。
# self.unfold = nn.Unfold(kernel_size=3, dilation=1, padding=1, stride=1)[B, tC, tH, tW] = feat.size()unfold_feat = self.unfold(feat).reshape([B, -1, tH*tW])induced_feat = dynamic_kernel.matmul(unfold_feat)induced_feat = induced_feat.reshape(B, tC, tH, tW)
实现二:
这个实现方式来自 Conditional Convolutions for Instance Segmenation
看 torch.nn.functional.conv2d 中的几个参数,_weight_, _bias_, _groups_
weight – filters of shape (out_channels, ![[20 ECCV] Conditional Convolutions for Instance Segmenation - 图20](/uploads/projects/z_zhang@is/9a4fecc3dc8a4c19aef7f797f32dc572.svg) , kH, kW)
, kH, kW)
bias – optional bias tensor of shape (out_channels). Default: None
groups – split input into groups, in_channels should be divisible by the number of groups. Default: 1
用 groups 来实现动态卷积。
下面是分离参数的参考操作:
'''https://github.com/aim-uofa/AdelaiDet/blob/f9103480b351330774205ecd6376a0683437bcfa/adet/modeling/condinst/dynamic_mask_head.py'''def parse_dynamic_params(params, channels, weight_nums, bias_nums):assert params.dim() == 2assert len(weight_nums) == len(bias_nums)assert params.size(1) == sum(weight_nums) + sum(bias_nums)num_insts = params.size(0)num_layers = len(weight_nums)params_splits = list(torch.split_with_sizes(params, weight_nums + bias_nums, dim=1))weight_splits = params_splits[:num_layers]bias_splits = params_splits[num_layers:]for l in range(num_layers):if l < num_layers - 1:# out_channels x in_channels x 1 x 1weight_splits[l] = weight_splits[l].reshape(num_insts * channels, -1, 1, 1)bias_splits[l] = bias_splits[l].reshape(num_insts * channels)else:# out_channels x in_channels x 1 x 1weight_splits[l] = weight_splits[l].reshape(num_insts * 1, -1, 1, 1)bias_splits[l] = bias_splits[l].reshape(num_insts)return weight_splits, bias_splits
下面这个便是作者写动态卷积参数加载的部分,作者为每个 instance 动态生成了权重,并用分组卷积的方法
def mask_heads_forward(self, features, weights, biases, num_insts):''':param features:param weights: [w0, w1, ...] 长度为层数:param bias: [b0, b1, ...]:return:'''assert features.dim() == 4n_layers = len(weights)x = featuresfor i, (w, b) in enumerate(zip(weights, biases)):x = F.conv2d(x, w, bias=b,stride=1, padding=0,groups=num_insts)if i < n_layers - 1:x = F.relu(x)return x
那么其实如果为每个 Batch 的每个图片生成的话, F.conv2d(x, weight = w, bias=b, ..., groups=N)

若有收获,就点个赞吧
0 人点赞
