💡 这一系列工作是基于这样的 ambiguity—用户点击的位置其实对于所指对象是有歧义的,比如下面的点是指女性手里的❀,还是整个人,还是前景的三个人?
1. [18 CVPR] Interactive Image Segmentation with Latent Diversity
作者及机构:
代码:Github
主要看点:
- 总结来看这个方法还是唯一选择一个分割结果的,并没有解决 ambiguity ,不过选择网络可能可以在一定程度上推测用户的需求(个人感觉是有限的);
- 这种注重 Diversity 的策略会给预测带来一个好处,如下图,预测的多个mask都聚焦到了正确的物体范围,而单一预测可能在训练时为了最小损失,两边兼顾导致预测不伦不类(个人感觉这是可能是提点的主要原因);
- 选择网络和备选方案的排序输出很有意思,一些损失函数值得参考,另外在选择前 shuffle 的 trick 也很可以。

方法部分:
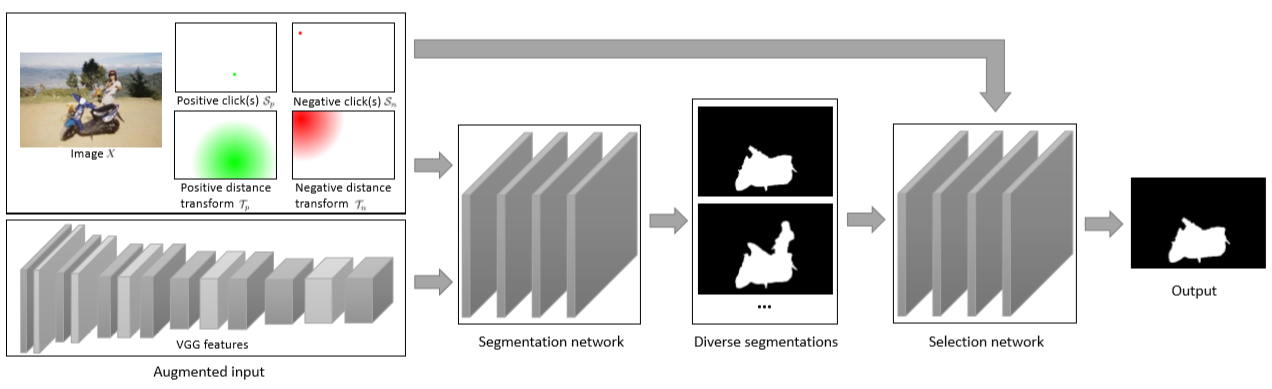
模型结构是一个分割网络 f 和选择网络 g。f 负责输出多种可能性的分割结果, g 负责选择一个最佳结果。
_
分割网络
首先来看 f 怎么保证分割输出多样性的:
hindsight loss :![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图7](/uploads/projects/z_zhang@is/d996c8a60edfc31d2366c4c3911aa3cb.svg) ,网络输出有 M 个Mask,, 用最接近GT的那一个mask算损失,
,网络输出有 M 个Mask,, 用最接近GT的那一个mask算损失,
其中 l(·) 作者选区的是IoU Loss (![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图8](/uploads/projects/z_zhang@is/f5ff143f70ca9595268096abd1a4167f.svg) ),
),
# IoU Lossnw1 = tf.expand_dims(network[:,:,:,0],axis=3)nw2 = tf.expand_dims(network[:,:,:,1],axis=3)...nw6 = tf.expand_dims(network[:,:,:,5],axis=3)iou_d1 = 1-tf.reduce_mean(tf.multiply(nw1,output))/(tf.reduce_mean(tf.maximum(nw1,output))+1e-6)iou_d2 = 1-tf.reduce_mean(tf.multiply(nw2,output))/(tf.reduce_mean(tf.maximum(nw2,output))+1e-6)...iou_d6 = 1-tf.reduce_mean(tf.multiply(nw6,output))/(tf.reduce_mean(tf.maximum(nw6,output))+1e-6)loss_iou = tf.reduce_min([iou_d1, iou_d2, iou_d3, iou_d4, iou_d5, iou_d6])+ 0.0025*(32*iou_d1+16*iou_d2+8*iou_d3+4*iou_d4+2*iou_d5+1*iou_d6)
另外,作者提出了一个基于 click 的 loss:![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图9](/uploads/projects/z_zhang@is/8cb3a088deacdbbcff922092ccb32014.svg) ,其中
,其中![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图10](/uploads/projects/z_zhang@is/d9b8e7ec2d9ea22a919d9d441e64242a.svg) 为元素乘, B为GT。
为元素乘, B为GT。
# add positive/negative clicks as soft constraintsct_mask = tf.cast(input[:,:,:,3],dtype=tf.bool) & tf.cast(input[:,:,:,4],dtype=tf.bool)ct_mask = tf.tile(tf.expand_dims(~ct_mask,axis=3), [1,1,1,6])ct_mask = tf.cast(ct_mask, dtype=tf.float32)ct_mask /= tf.reduce_mean(ct_mask)output_tile = tf.tile(output,[1,1,1,6])ct_loss = tf.reduce_mean(tf.abs(network - output_tile) * ct_mask)
综合以上两项,损失可以写为:![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图11](/uploads/projects/z_zhang@is/398967a27a59ad98ebc5be0077cbe613.svg) 。
。
选择网络:
这个选择网络本质上是一个分类网络,从 f 中分割的多个结果中选择一个较好的结果;
这个网络的输入为: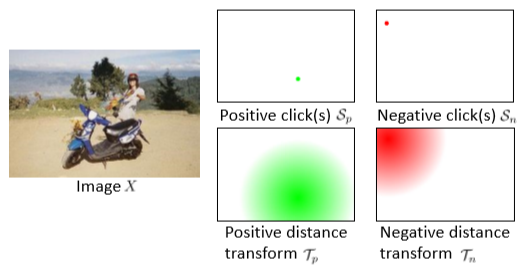 和
和  ;
;
输出为:一个 维度为 M 的 vector。
训练时候的损失函数为 BCELoss, ![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图14](/uploads/projects/z_zhang@is/82ea034dca4dcdf28964a6b16e85665e.svg) ,其中
,其中![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图15](/uploads/projects/z_zhang@is/73c833c8c8c09de28897ba5ac0d88db1.svg) 是 f 的输出,
是 f 的输出,![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图16](/uploads/projects/z_zhang@is/ffea990e9d5390a21aeb278209ca93f5.svg) 是距离GT最近的那个 Mask 的 index。
是距离GT最近的那个 Mask 的 index。
训练的时候有一个小 trick 是将 shuffle 一下,这样网络就是注重 content, 而不会有 channel 上的 bias。
另一个思路 RDL(代替选择网络):
作者还提出了一种候选方案,使用 f 直接对结果进行排序,不通过 g 来选择。这个方法也作为了实验中的一个 baseline 。
通过向![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图18](/uploads/projects/z_zhang@is/2d93e009ee4b3be9aec02cb9bc1497af.svg) 中加入一个新的项,给每个输出channel 加一个惩罚项 (递增或递减),这样输出就会自己动:
中加入一个新的项,给每个输出channel 加一个惩罚项 (递增或递减),这样输出就会自己动:![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图19](/uploads/projects/z_zhang@is/8f0c47342c4a3f524a535c9a991bbf3c.svg) ,
,
这里![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图20](/uploads/projects/z_zhang@is/b6c8ec324e66464f5f59a147185a2c86.svg) 是一个递增序列,比如
是一个递增序列,比如![[18 CVPR & 19 ICCV] Latent Diversity / MultiSeg - 图21](/uploads/projects/z_zhang@is/49aca1d3787fde5fb588aaa98e949da3.svg) ,有意思😀。
,有意思😀。
实验结果:

2. [19 ICCV] MultiSeg: Semantically Meaningful, Scale-Diverse Segmentations from Minimal User Input
作者及机构:
主要看点:
- 保证多样性的方法;
- 把多种预测结果的选择权交给用户的工作流程。
💡 作者Claim的:Our key idea is to produce a set of diverse segmentations as recommendations to the user where each segmentation should conform to the user input.
As the user provides more evidence, the model should quickly converge to one of them.
作者指出的 Latent Diversity 那一篇的问题如下:
- Latent Diversity 中的训练是无约束的,并没有鼓励不同分支(channel)的预测的多样性;
- 最后模型仍然只给出了一个预测结果,(自动的为用户选择),但是在点少的情况下往往是不准确的。并没有真正解决歧义性问题。
方法部分:

使用 UI 如下,点击点后右侧会有多个候选结果,默认第一个,如果需要改变再从候选区中选择。
方法大致如下:
对于这个 FCN ,作者使用的是 Resnet-101, 作为分割结构为 DeepLabv3+的改动版本,改动位置如下:
- 输入适应5通道;
- 输出层一个有 M 个branch,基于用户设定的 M 个sacles;
- Resnet的GAP层后面跟了一个 M 个输出的全连接层来预测每个分支的 score (在decoder之前)。
由于作者没有公布code,我只能根据论文中模糊的描述来推测作者模型的结构:
如左下角图所示,每个Branch算loss的时候只关注自己对应scale的区域(Scale是固定的比如64×64),并且要满足和最外层bbox的IoU超过50%的时候才会更新这一branch的参数。
如果出现没有任何一路IoU超过50%,就把最大的bbox 更新为 最大scale branch的bbox在进行操作。这种训练让每个branch只关注一定scale的物体,有利于 Scale Diversity
另外在训练数据数据生成上,作者把一个Instance的Mask和邻居Mask进行了排列组合,这样可以生成更合理的训练数据。
实验结果:

(a)MultiSeg
(b)Latent Diversity
总结:
这个方法的交互方式是解决这种歧义性的一个非超好的方案,Mulriseg这篇文章是作者基于这个思想的一个略显粗暴的实现(多分支模型加上十分耗时的后处理)。在未来,更高效的保证多样性预测的方法也是值得探究的。

若有收获,就点个赞吧
0 人点赞
