[20 CVPR] Learning Fast and Robust Target Models for Video Object Segmentation
作者单位:
代码主页:Github
简称:FRTM
主要看点:
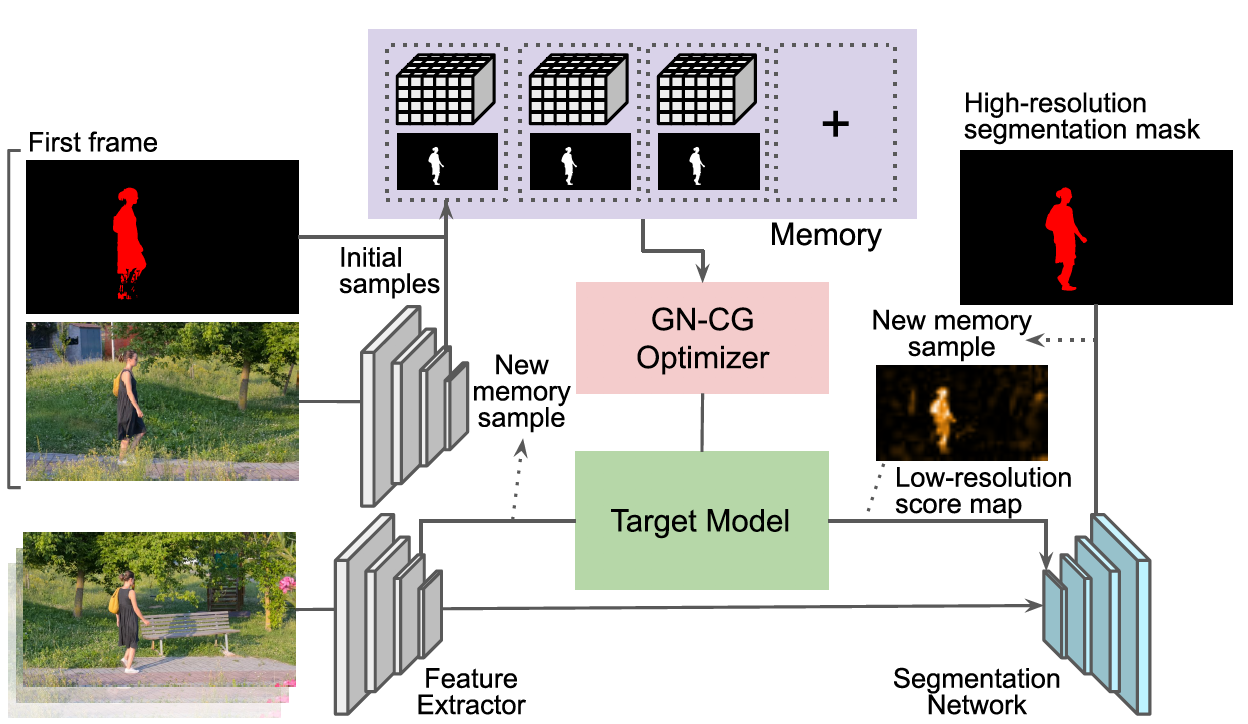
FRTM 也是 VOS 中一个 Online 的方法,但是在 inference 过程中,他只更新模型的一个很小的 Target model (只有两个卷积层)。
FRTM 由两个个模块组成:1)Target Model;2)Segmentation model。 (另外,Feature Extractor 是 fix 住的)
Target Model 通过 Online 的训练,输出一个比较粗糙的分割图 (target specific);
Segmentation model 通过 Offline 的训练,可以将 Target Model 的粗糙输出细化 (target agnostic)。
方法部分:
Inference
Target Model 包含两层: 第一层![[20 CVPR/ECCV] Target Model for VOS - 图6](/uploads/projects/z_zhang@is/fb240be2332ee7e313c4b9f57a3f5e73.svg) 是一个 1✖️1 卷积,把输入通道压缩为 96 个通道;第二层
是一个 1✖️1 卷积,把输入通道压缩为 96 个通道;第二层![[20 CVPR/ECCV] Target Model for VOS - 图7](/uploads/projects/z_zhang@is/3fdc62bc2703d0562a58f71ee316888b.svg) 是一个 3✖️3 卷积,输出单通道预测图。
是一个 3✖️3 卷积,输出单通道预测图。
下面重点来看下,Target Model 是在 inference stage 中是如何更新的:
Target Model 更新采用了 L2 Loss![[20 CVPR/ECCV] Target Model for VOS - 图8](/uploads/projects/z_zhang@is/43169b53d5b607971536d6259d1e5ff5.svg) ,
,
我们看到这个损失的输入并不是仅仅是最后帧的输入特征和预测结果,而是之前的所有(一段时间)内的帧。![[20 CVPR/ECCV] Target Model for VOS - 图9](/uploads/projects/z_zhang@is/0bf13f4b4d02bb48dded44e4d0f03892.svg) 中存储着之前 K = 80 的帧信息
中存储着之前 K = 80 的帧信息 ,这可以防止 model drifting。
,这可以防止 model drifting。
其中 U 代表上采样,D 是 Target Model ,![[20 CVPR/ECCV] Target Model for VOS - 图11](/uploads/projects/z_zhang@is/29aed8f768a4d3958179584221f9c4b6.svg) 是一个Pixel weighting (为了解决前背景不平衡)。
是一个Pixel weighting (为了解决前背景不平衡)。
优化上面的损失作者采用了 Gauss-Newton (CN)策略去迭代优化,并采用 Conjugate Gradient 迭代求解每一步的目标。
更新时候的细节值得注意下:
作者首先对第一帧进行数据增广,如下图, 和首先随机初始化,然后同时使用第一帧的信息更新,后面每隔 t = 8 更新一次。
和首先随机初始化,然后同时使用第一帧的信息更新,后面每隔 t = 8 更新一次。
作者两个模型 Ours 和 Ours-fast 的差别在于 backbone 的不同和 CN/CG 的迭代次数不同。
Offline Train
这一块用来训练 Segmentation model。
由于提取特征的backbone 的参数是 fix 的, Target model 首先可使用第一帧训练好备用。
然后离线训练 Segmentation model。
实验结果:
在 YouTube-VOS 上的消融实验: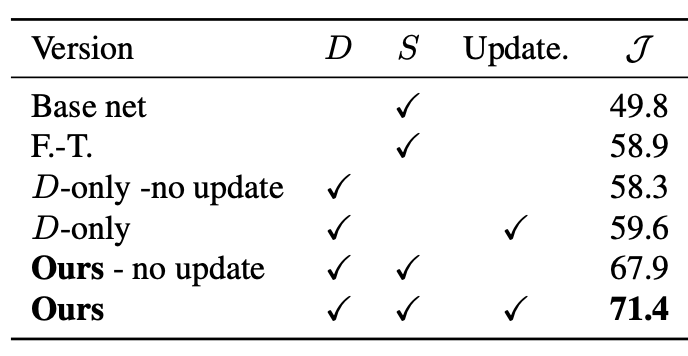
横向的实验结果:
YouTube-VOS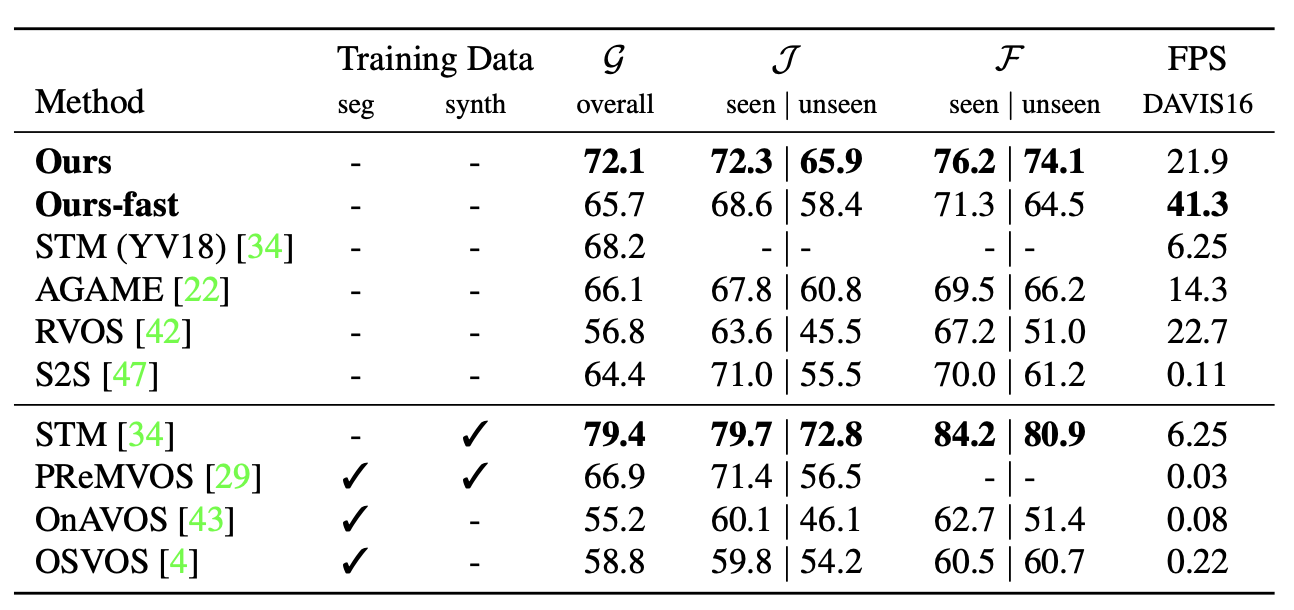
“seg” and “synth” indicate whether pre-trained segmentation models or additional data has been used during training.
DAVIS-2017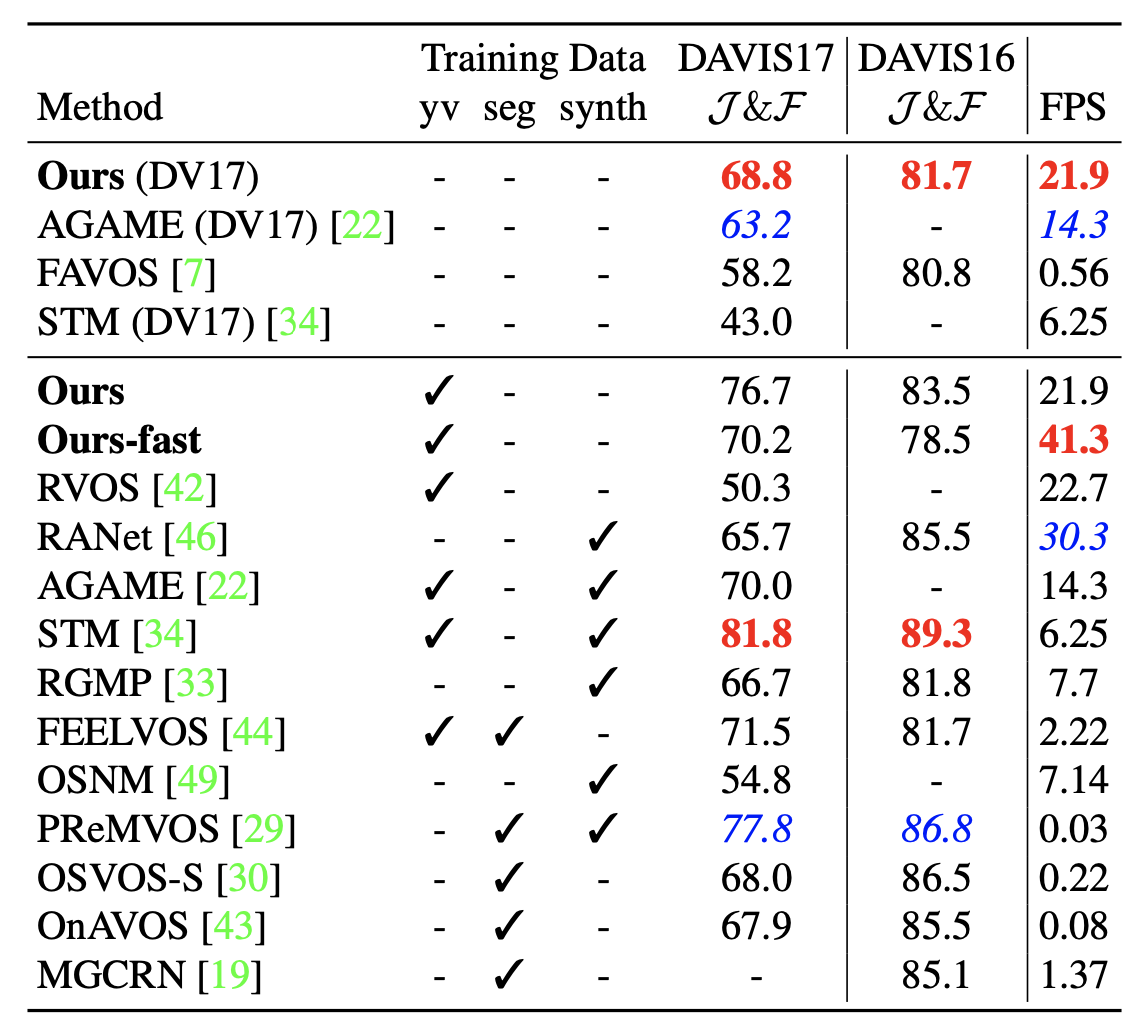
The columns with “yv”, “seg”, and “synth” indicate whether YouTube-VOS, pre-trained segmentation models or additional synthetic data has been used during training.
存在的问题:
主要问题:FRTM 并不是一个 End-to-End 的网络(Target model 优化策略所致)这造成了很多缺点:
- Target model 每次都要从 0 开始训练;
- 训练和测试过程中 Target model 的更新并不一致;
- 特征提取的 Backbone 的参数必须得固定;
另外,Target model 直接预测 一个单通道的 prediction map,并仅仅用这个单通道的 prediction map 指导 segmenation model 损失了大量的信息。
以上的问题会限制模型的精度。
[20 ECCV] Learning What to Learn for Video Object Segmentation
作者单位:
代码主页:Github
主要看点:
这篇工作是 FRTM 的升级版本,作者团队也有重合,解决了 FRTM 主要的痛点。
对于 Target model 来说,
However, directly learning to predict the segmentation mask from a single sample is dicult. More importantly, this approach limits the target-specic information sent to the segmentation decoder to be a single channel mask.
为了解决上述问题,作者提出了 “learning what to learn” 的策略
“learning what to learn” 是指对于 Target model 来说,
需要预测的并不仅仅是一个单通道的 prediction map,而是对后续 segmentation map 更有作用的特征(multi-channel mask)。
至于这些有用的特征是什么,咱们也不知道,这些特征是通过 end-to-end 的训练自动生成出来的。
另外就是,end-to-end 的训练问题。
FRTM 不是一个可以 end-to-end 训练的方法,原因出在 FRTM 中 target model 的优化方式是不可微的,
以至于在 FRTM 中, 特征提取器的参数是固定的,
Target model 是随机初始化的,
而真正参与训练的只有 segmenation model 也就是一个 decoder。
解决这一点也很容易,把 target model 的优化方法变成可微的就行了😂。
方法部分:
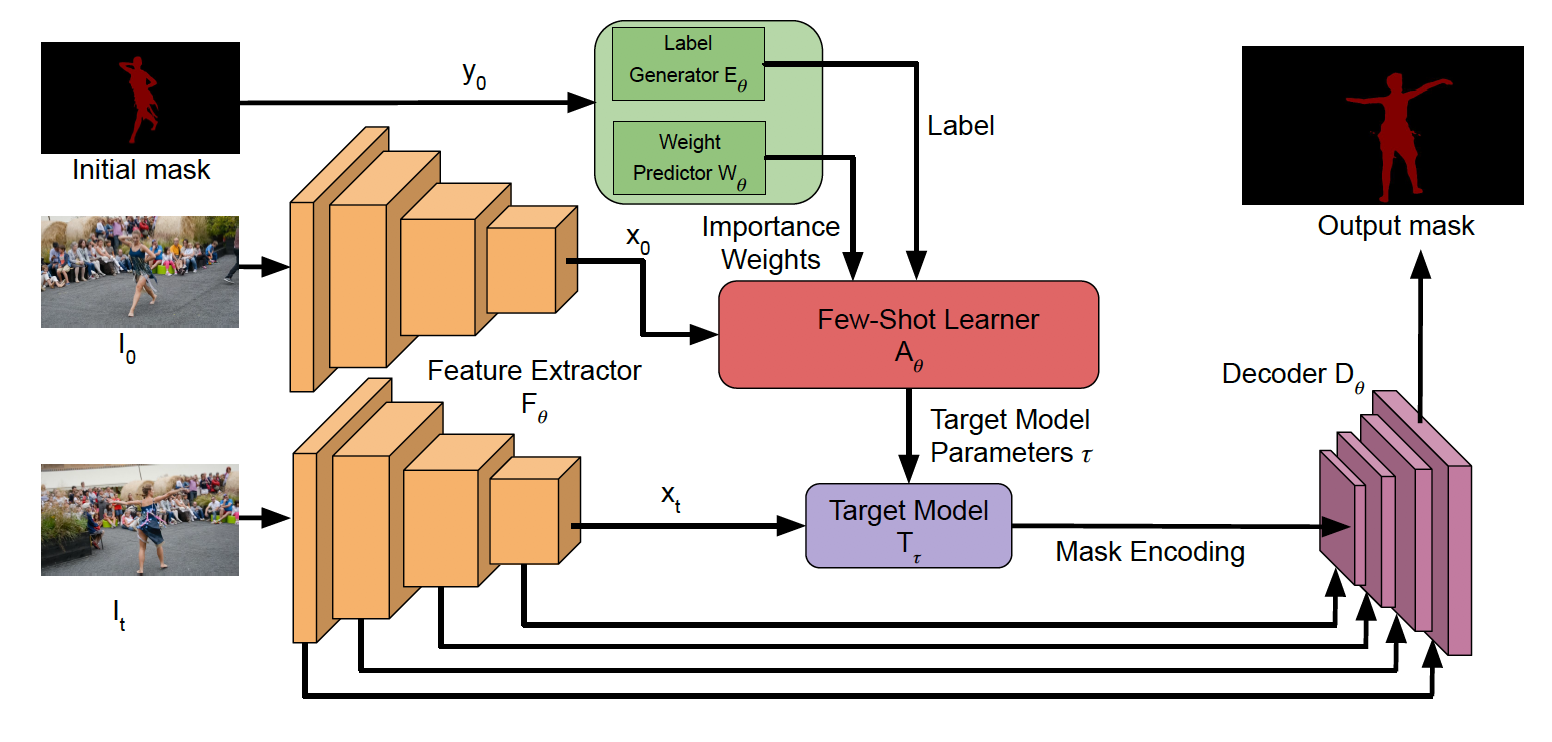
本文通过下面的模块来同时生成多个 channel 的 mask,和每个 mask 的权重。
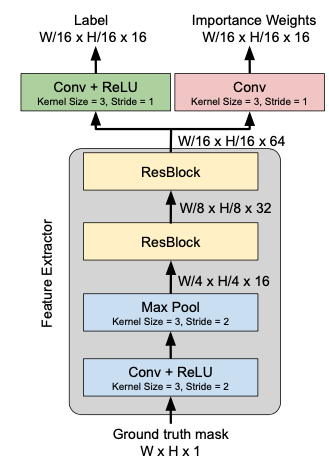
为啥要学习一个权重呢,作者的解释如下:
For instance, it is often beneficial to assign higher weights to target regions in case of small objects, to account for an imbalanced training set. Similarly, it might be beneficial to assign lower weights to ambiguous regions such as object boundaries, and let the segmentation network Sθ handle them.
Target model 优化方法变成了可微的 steepest descent iterations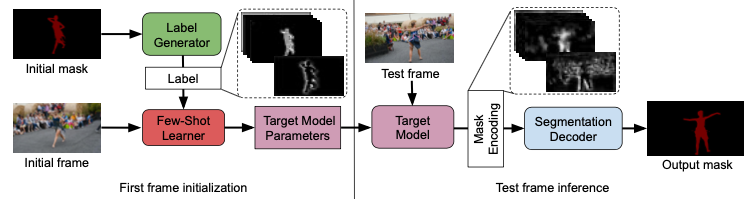
训练方式和上面的 FRTM 不同, 不是间隔着去更新,而是在段序列上(4帧)上更新。
初始帧迭代5次,后续都迭代两次。训练市场大概在4张V100上耗时48小时。
实验结果
在 YouTube-VOS 2019 上的消融实验

若有收获,就点个赞吧
0 人点赞
