1.1介绍一下数据库分页
在mysql中,select语句默认返回所有匹配的行,但是可以通过limit子句返回匹配的前几行,以实现分页查询。
—在所有的查询结果中,返回前10条数据记录
select from ${table_name} limit 10;
—在所有的查询结果中,从第10行开始,返回前10条数据记录
select from ${table_name} limit 10,10
带两个值的limit可以指定从offset开始,返回limit条数据。
【优化limit分页】:
在偏移量非常大的时候,例如limt 10000,20这样的查询,这时mysql需要查询10020条记录然后只返回最后20条,前面的10000条数据记录都将被抛弃,这样的代价是非常高的。如果所有的页面被访问的频率都相同,那么这样的查询平均需要访问半个数据库的表的数据。非常影响效率。
(1)将limit查询转换为已知位置的查询,让mysql通过范围扫描获得对应的结果。例如,如果一个列上有索引,并且预先计算了边界值,上面的查询就可以改为:
select from ${table_name} where id between 10001 and 10010;
或者是
select from ${table_name} where id<10011 order by id desc limit 10; (查找可以依据的最后一条数据记录然后从后往前追溯)
如果使用的是自增主键可以使用上面这种做法。
1.2介绍一下sql的聚合函数
常用的聚合函数有count()、avg()、sum()、max()、min()等等。
(1)count()函数统计数据表中包含的记录行的总数,或者是根据查询结果返回列中所包含的数据行数,它有两种用法:
【1】count(*)计算表中总的行数,不管某列是否有数据或者为空值。
【2】count(字段名)计算指定列下总的行数,计算时可以忽略空值的行。
count()函数可以与group by一起使用来计算每个分组的总和。
(2)avg()函数可以通过计算返回的行数和每一行数据的和,求得指定列数据的平均值。
avg()函数可以与group by一起使用,来计算每个分组的平均值。
(3)sum()函数是一个求总和的函数,返回指定列值的总和。
sum()函数可以与group by一起使用,来计算每个分组的总和。
(4)max()函数可以返回指定列中的最大值。
max()函数可以和group by一起使用,来计算每个分组中的最大值。
max()函数不仅适用于数值查找,也可应用于字符类型。
(5)min()函数与max()函数类似的效果。
1.3表跟表是怎么关联的?
表与表之间常用的关联方式有两种:内连接、外连接。
【内连接】:
内连接通过inner join来实现。如果第一张表的数据可以匹配到第二张表的数据,那么这类数据就会保留。反之,该类数据不会保留。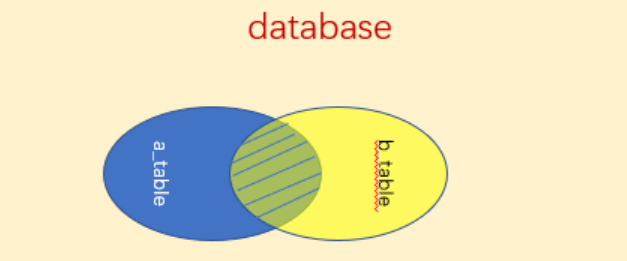
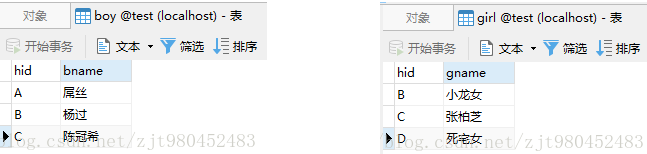
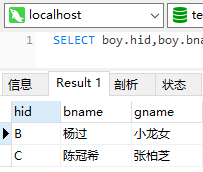
select boy.hid,boy.bname,girl.gname from boy inner join girl on girl.hid = boy.hid;
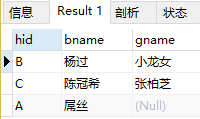
【外连接】:
外连接通过outter join来实现。如果第一张表的数据可以匹配到第二张表的数据,那么这类数据这会保留。反之,该类数据会用Null来填充。外连接又分为左连接和右连接。
左连接:返回左表中的所有记录和右表中满足连接条件的记录。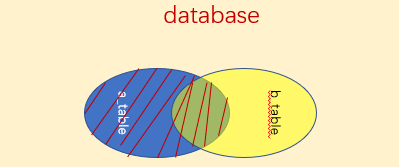
select boy.hid,boy.bname,girl.gname FROM boy left join girl ON girl.hid = boy.hid;
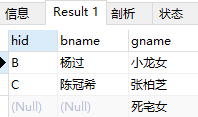
右连接:返回右表中的所有记录和左表中满足连接条件的记录。
select boy.hid,boy.bname,girl.gname from boy right join girl on girl.hid = boy.hid;
1.4mysql是怎么将行转成列的?
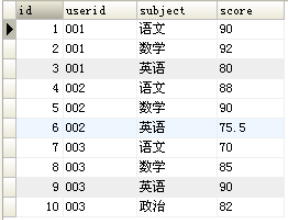
转换以后得到的结果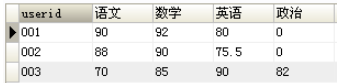
转换思路:将原来的subject字段的多行内容选出来,作为结果集的不同列,并根据userid进行分组显示对应的score。
(1)使用cas…when…then语句实现行转列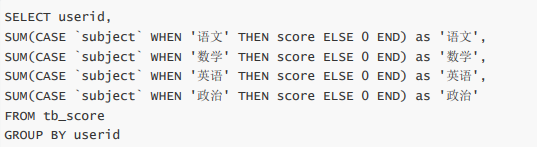
(2)使用if()函数实现行转列
1.5谈谈你对sql注入的理解
sql注入的原理是将sql代码伪装到输入参数中,传递到服务器解析并执行的一种攻击手法。也就是说,在客户端向服务端发起的请求参数中植入一些sql代码,服务端再执行sql操作时,会拼接请求参数,同时也将一些sql注入攻击的”sql”拼接起来,导致会执行一些预期之外的操作。
举个例子:
比如在登录功能中,登录界面需要填写用户名和密码以及提交框,通过post请求传递给服务端。此时调用接口/user/login加上参数username、password,首先连接数据库,然后对请求参数中携带的用户名、密码进行参数校验,通过sql查询;假设正确的用户名和密码是qhh和123456,输入正常的用户名和密码提交,相当于调用了一下sql语句。
select from user where username=’qhh’ and password=’123456’;
sql中会将#以后的字符串当做注释处理,如果我们使用’ or 1=1 #’作为用户名参数,那么服务端构建的sql语句如下:
select from user where username=’ or 1=1 #’ and password=’123456’;
#会忽略后面的语句,把它当做注释,而1=1属性常量型条件,永远成立,因此这个sql将查询出所有的用户。其实上面的sql注入只是在参数层面做了些手脚,如果是引入了一些功能性的sql就就更危险了。
比如上面的登录功能,如果用户名使用了’ or 1=1;delete * from users;#,在’;’之后相当于是另外一条新的sql,这个sql是删除全表,是非常危险的操作,因此sql注入这种问题需要特别注意。
【如何解决sql注入】
(1)严格的参数校验:在一些不该有特殊字符的参数中提前进行特殊字符校验即可。
(2)sql预编译
在知道了sql注入的原理之后,我们同样也了解到mysql有预编译的功能,指的是在服务器启动时,mysql Client把sql语句的模块(变量用占位符进行占位)发送给mysql服务器,mysql服务器对sql语句的模板进行编译,编译之后根据语句的优化分析选择相应的索引进行优化,在最终绑定参数时相应的参数传给sql服务器,进行执行,节省了sql查询时间,以及mysql服务器的资源,达到一次编译、多次执行的目的,除此之外,还可以防止sql注入。
具体是怎样防止sql注入的呢?使用预编译后,黑客注入的参数将不会再进行sql编译,也就是说它后面传递进来的参数,系统不会认为它是一条sql语句,而仅仅是一个参数,参数中的or或者and等也不是sql语法保留字。
Mybatis默认情况下,将对所有的sql进行预编译。Mybatis底层使用PreparedStatement,过程是先将带有占位符?的sql模板发送给mysql服务器,由服务器对无参数的sql进行编译后,将编译结果缓存,然后直接执行带有真实参数的sql,核心是通过#{}实现的。
1.6将一张表的部分数据更新到另一张表,该如何操作呢?
可以采用关联更新的方式,将一张表的部分数据,更新到另一张表内。参考如下代码:
update b set b.col=a.col from a,b where a.id=b.id;
update b set col=a.col from b inner join a on a.id=b.id;
update b set b.col=a.col from b left join a on b.id=a.id;
1.7说说group by与distinct的区别?
distinct的目的就是用来做去重的,而group by的主要目的是用来做分组聚合计算用的,两者虽然都能实现去重的功能,但是在用法上却有很大的不同。distinct支持单列、多列的去重方式,单列去重的方式简单易懂,即相同值只保留一个。多列去重则是指定的列信息都相同,才会被认为是重复的信息。group by的使用频率更高,虽然也能实现去重的目的,但是这不是它的长项。另外如果在条件相等的情况下,使用group by的效率是会更高的,要不然使用explain语句输出信息的Extra字段也不会有Using groupby的信息。
1.8where和having有什么区别?
(1)where是一个约束声明,在查询数据库之前对数据库中的查询条件进行约束,where是在结果返回之前起作用的,where后面不能使用聚合函数。
(2)having是一个过滤声明, 在查询数据库返回结果集之前对查询结果进行的过滤操作,在having中可以使用聚合函数。另一方面,having子句不能使用除了分组字段和聚合函数之外的其他字段。
(3)where条件语句与group by子句一起使用的时候,where在前,group by在后,先对结果集进行where条件筛选,然后再使用grou by进行分组,而使用having子句时,group by在前,having在后,having子组对分组后的结果进行筛选。
(4)从性能的角度来说,having子句中如果使用了分组字段作为过滤条件,应该替换成where字段。因为where可以在执行分组操作和计算聚合函数之前过滤掉不需要的数据,性能会更好。
1.9说说数据库三大范式
(1)第一范式:保证每列的原子性,要求每列都是不可再分的最小数据单元。
比如地址字段还可以拆分成国家、省份、地级市、所属区、门牌号等等。甚至有的程序把user姓名拆分成姓和名。
(2)第二范式:保证每张表的唯一性,一张表只能说明一个事务。
比如现在有张学生表,它有字段:学号id、姓名、年龄、课程名称、成绩、学分。这张表就不符合第二范式,会引发更新异常、删除异常、插入异常、数据冗余。
更新异常:比如现在高等数学的学分是3分,我想把他改成4个学分,就需要把数据库表中的每一行都修改。
插入异常:比如现在如果有学生A没有选课,就无法插入进数据库中,或者课程信息的字段需要为null值。
删除异常:删除所有的学生成绩,就把课程信息全删除了。
数据冗余:每条记录都含有相同的信息,比如在这张表上如果学生A选修了语文和数学课,你就得记录2次学生的基本信息,存在数据冗余。
【修改】学生表:学号、姓名、年龄。 课程信息表:课程名称、学分。 选课关系表:学号、课程名称、成绩。
(3)第三范式:要求数据库表中有主键,非主键列字段需要与主键直接相关,不存在依赖传递的关系。
比如现在一张学生信息表中,它有字段:学号id、姓名、年龄、所在学院、学院联系电话。它存在依赖传递关系:学号->所在学院->学院联系电话。
【修改】:学生表:学号id、姓名、年龄、所在学院。 学院表:学院名称、联系电话。

若有收获,就点个赞吧
0 人点赞
