1.1说说什么是全文搜索
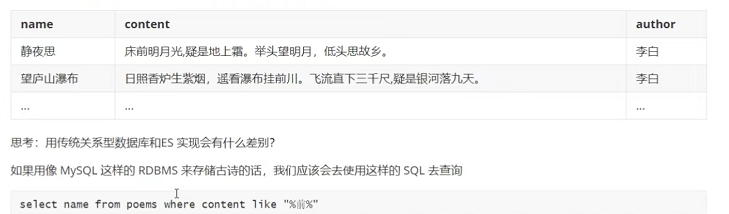
如果使用Mysql的模糊查询,就需要针对每条数据记录的content字段上进行模糊匹配,匹配成功的数据记录就加入到结果集中,直到扫描到叶子叶子的末尾。这种方式也称为顺序扫描法,需要遍历所有的记录进行匹配,效率非常低。
【全文检索】
通过一个程序扫描文本中的每一个单词,针对单词建立索引,并保存该单词在文本中的位置,以及出现的次数。用户查询时,通过之前建立好的索引来查询,将索引中单词对应的文本位置、出现的次数返回给用户,因为有了具体文本的位置,所以就可以通过具体内容读取出来了。
1.2说说你对ES的了解
ES是一个开源的分布式全文搜索引擎,支持全文搜索,数据分析引擎,对海量数据实时处理。es使用Java语言开发,基于Lucene框架实现搜索功能。
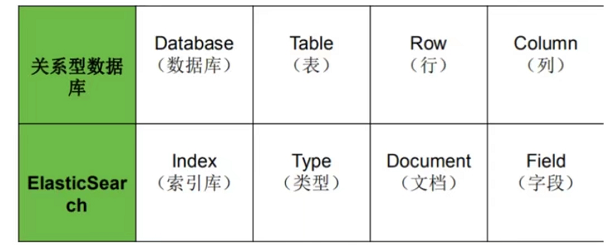
(1)特点:快速搜索,分布式部署,RestFul所有操作可以通过http接口进行
- 分布式的实时文档存储,每个字段都可以被搜索和索引。
- 胜任上百个服务节点的拓展,支持PB以上的结构化和非结构化数据。
分片sharding和副本replicas:index都分散在各个sharding中。每个sharding都有一个或多个备份。可以反映ES集群的健康状态。ES的使用场景非常广泛,可以用在大数据搜索的场景下,另外ES还具有很强大的计算功能。
Lucene的缺点:
(1)只能在Java项目中使用,并且要以jar包的方式直接集成到项目中;
(2)使用非常复杂(创建索引和搜索索引);
(3)不支持集群环境
(4)索引数据如果太多就不行,因为索引库和应用在同一个服务器上,共同占用资源。
1.3如何进行中文分词?用过哪些分词器?
IK分词器、HanLP分词器。有基于字典树的分词和基于NLP机器学习的分词。
1.4ES写入数据的工作原理是什么?
(1)客户端发送写数据请求时,可以发往任意的节点,这个节点就称为协调节点。
(2)计算节点文档要写入的分片,一般是对文档id进行hash再取模运算。
(3)协调节点进行路由,将请求转发给对应的节点上的primary shard。
(4)primary shard处理请求,写入数据,然后将数据同步到replica shard。
(5)当数据写入primary shard和replica shard成功后,就可以返回客户端响应结果了
1.5ES查询数据的工作原理是什么?
(1)客户端的请求可以发往任意节点,这个节点就称为协调节点;
(2)协调节点将查询请求广播到每一个数据节点,这些数据节点的分片就会处理该查询请求;
(3)每个分片进行数据查询,将符合条件的数据放在一个队列当中,并将这些数据的文档ID、节点信息、分片信息都返回给协调节点;
(4)由协调节点将所有的结果进行汇总,并排序;
(5)协调节点向包含这些文档的ID的分片发送get请求,对应的分片将文档数据返回给协调节点,最后协调节点将数据整合返回给客户端。
1.6说说ElasticSearch为什么快?
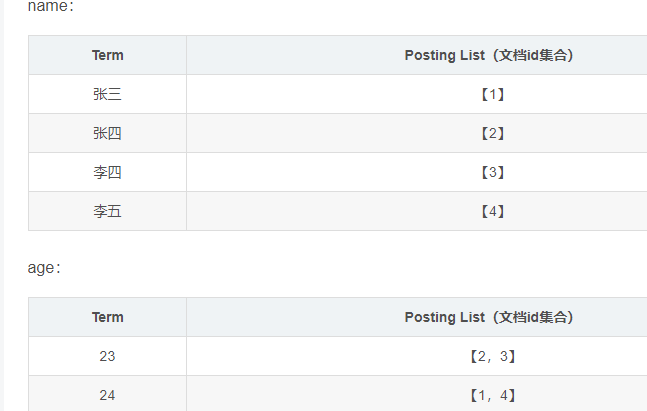
(1)Postring List(倒排列表):往ES中put数据时,经过分词器的分词能够插入出很多个不同的field,ElasticSearch会为拆分出来的每个field都建立一个倒排索引,拆分出来的单词称为一个term,每个term都会有一个对应的PostingList,PostingList就是一个int类型的数据,存储了所有符合这个term的文档Id。
(2)TermDictionary(单词字典):为了快速找到某个特定的term,ES会将所有的term进行排序。再采用二分查找算法来查找某个term,时间复杂度是O(logN)。并且ES是直接通过内存查找这个term,不会去读磁盘。但如果term特别多的话,单词字典会很大,将所有的单词字典都加载到内存中是不太现实的。
(3)TermIndex(单词索引前缀):其实这个就相当于是前缀树的数据结构,它每个节点包含某个单词的一部分,通过term Index可以快速定位到单词字典中的某一项。再加上一些压缩技术,比如FST。termIndex的尺寸可以只有所有term尺寸的几十分之一,使得使用内存缓存整个termIndex成为可能。
(4)InvertedFile(倒排文件):对应的是所有term的document,存储在磁盘中。

若有收获,就点个赞吧
0 人点赞
