3.1介绍一下java中的IO流
IO是实现对数据的输入与输出操作,java把不同的输入/输出源(键盘、文件、网络等)抽象表述为流。
【按照数据流向】:将流分成输入流和输出流,其中输入流只能读取数据,不能写入数据;而输出流只能写入数据,不能读取数据。
【按照数据类型】:可以将流分成字节流和字符流,其中字节流操作的数据单元是8位的字节,而字符流操作的数据单元是16位的字符。
【按照处理功能】:可以将流分为节点流和处理流,其中节点流可以从/向一个特定的IO设备(磁盘、网络等)读/写数据;而处理流是对节点流的封装,用于简化数据读/写功能或提高效率。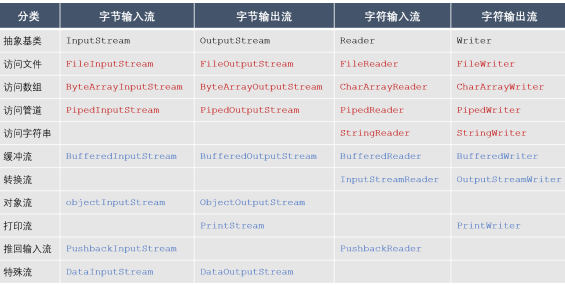
以File开头的文件流用于访问文件;
以ByteArray/CharArray开头的流用于访问内存中的数组;
以Piped开头的管道流用于访问管道,实现进程之间的通信;
以String开头的流用于访问内存中的字符串;
以Buffered开头的缓冲流,用于在读写数据时对数据进行缓存,以减少IO次数;
InputStreamReader、InputStreamWriter是转换流;用于将字节流转换成字符流;
以Object开头的流是对象流,用于实现对象的序列化;
以Print开头的流是打印流,用于简化打印操作;
3.2怎么用流打开一个大文件
打开打文件,应该避免直接将文件中的数据全部读取到内存中,可以采用分次读取的方式。
(1)使用缓冲流。缓冲流内部维护了一个缓冲区,通过与缓冲区的交互,减少与设备的交互次数。使用缓冲输入流时,它每次回读取一批数据将缓冲区填满,每次调用读取方法并不是直接从设备取值,而是从缓冲区取值,当缓冲区为空时,它会再一次读取数据,将缓冲区填满。使用缓冲输出流时,每次调用写入方法并不是直接写入到设备,而是写入缓冲区,当缓冲区填满时它会自动刷入设备。
(2)使用NIO。NIO采用内存映射文件的方式来处理输入/输出,NIO将文件或文件的一段区域映射到内存中,这样就可以像访问内存一样来访问文件了(这种方式模拟了操作系统的虚拟内存的概念),通过这种方式来进行输入/输出比传统的输入/输出要快很多。
3.3为什么java中的Buffered缓冲流使IO效率高?
(1)首先是初始化,如果不指定缓冲区的大小,会默认创建8192长度的数组;
(2)以FileInputStream和BufferedInputStream为例,fis的read()方法有三种读取的方式构成重载,分别是读一个字节、读取一个数组长度的内容到数组中以及从文件off位置读入len这么长的字节到byte数组中。FileInputStream的read方法如果是不带任何参数,每次都从文件从读取一字节的话,就需要交互非常多次。而如果使用Buffered缓冲流的read()方法,默认会从文件中读取8K内容进内存,之后直接从内存中读取数据。如果是二者读取的内容差不多的话,效率应该也是差不多的。Buffered缓冲流是典型地以空间换时间。
3.4说说NIO的实现原理
java的NIO主要由三个核心部分组成:Channel、Buffer、Selector
Channel:基本上,所有的IO在NIO都从一个Channel开始,数据可以从Channel读到Buffer中,也可以从Buffer读到Channel中。Channel有好几种类型,其中比较常用的有FileChannel、DatagramChannel、SocketChannel、ServerSocketChannel等,这些通道涵盖了UDP和TCP网络IO以及文件IO。
Buffer:本质上是一块可以写入数据,然后可以从中读取数据的内存。这块内存被包装成NIO Buffer对象,并提供了一组方法,用来方便的访问这块内存。java Nio里关键的Buffer实现有CharBuffer、ByteBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer。这些Buffer覆盖了你能通过IO发送的基本数据类型。Buffer对象中包含了是哪个重要的属性,分别是capacity、position、limit,其中position和limit的含义取决于Buffer是读模式还是写模式。但不管Buffer处在什么模式,capacity的含义都是一样的。
【capacity】:作为一个内存块,Buffer有个固定的最大值,就是capacity。Buffer只能写capacity个数据,一旦Buffer写满了,需要将其清空才能继续往里边写数据。
【position】:当写数据到Buffer时,position表示当前的数据。初始的position的值为0.当一个数据写到Buffer后,position会向前移动到下一个可插入数据的Buffer单元。position的最大值可为capacity-1。当读取数据时,也是从某个特定位置读。当将Buffer从写模式切换到读模式时,position会重置为0,limit重置为写模式下的position。从Buffer的position处读取数据时,position向前移动到下一个可读的位置。
【limit】:在写模式下,Buffer中的limit表示能最多往Buffer中写多少数据,此时limit=capacity。当切换到读模式下,limit表示你能读到多少数据,limit=写模式下的position。
另外,初始化Buffer的时候是写模式,可使用filp()方法切换到读模式。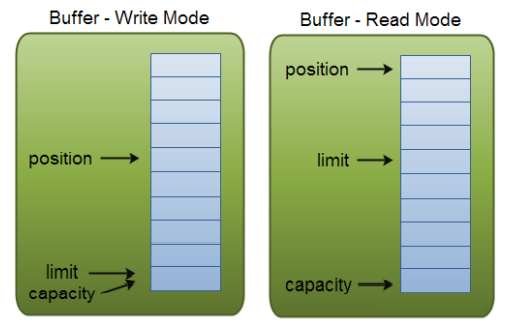
Selector:允许单个线程处理多个Channel。如果你的应用打开了多个连接(通道),但每个连接的流量都很低,使用Selector就会很方便。要使用Selector,就得向Selector注册Channel,然后调用它的select()方法,这个方法会一直阻塞到某个注册的通道有事件就绪。一旦这个方法返回,线程就可以处理这些事件。例如:新的连接事件、读取事件等。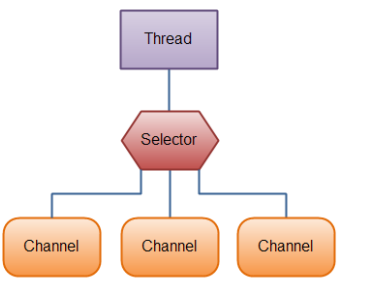
3.5介绍一下java的序列化和反序列化
序列化就是将一个java对象转化成字节序列,这些字节序列可以存储在磁盘上,也可以在网络中传输。
反序列化就是将字节序列再恢复成原来的java对象。如果对象要支持序列化机制,它所在的类就必须实现Serialzable接口,这个接口不提供任何方法,仅表示支持序列化机制,起标识作用,说明该类是支持序列化的。像包装类,String类和Date类就实现了Serizable接口。
如果需要将java对象转化为字节序列,就需要调用ObjectOutputStream的writeObject()方法,以输出对象序列。
如果需要将字节序列恢复成java对象,就需要调用ObjectInputStream的readObject()方法,将对象序列恢复成对象。
3.6Serializable接口为什么需要定义serialVersionUID变量?
serialVersionUid代表的是序列化的版本,通过定义类的序列化版本,在反序列化时,只要对象所存的版本与当前类的版本一直,就允许做恢复数据的操作,否则将会抛出序列化版本不一致的错误。
如果不定义序列化版本,在反序列化时可能出现冲突的情况,例如:
(1)创建该类的实例,并将这个实例序列化,保存在磁盘上;
(2)升级这个类,例如增加、删除、修改这个类的成员变量;
(3)反序列化该类的实例,从磁盘上恢复修改之前保存的数据;
在第三步恢复数据的时候,当前的类已经和序列化的数据的格式起了冲突,可能会发生各种意想不到的问题。增加了序列化版本之后,在这种情况下则可以抛出异常,以提示这种矛盾的存在,提高数据的安全性。
3.7除了java自带的序列化之外,你还了解哪些序列化工具?
【Json】:
(1)目前使用比较频繁的格式化数据工作,简单直观,可读性好,有jackson,gson,fastjson等等。
(2)json进行序列化的额外空间开销大,json序列化器是基于字符串(json串),速度较慢;对于大数据量服务意味着巨大的内存和磁盘开销。
【Kryo】:
(1)和很多其他的序列化框架一样,Kryo 为了提供性能和减小序列化结果体积,提供注册的序列化对象类的方式。在注册时,会为该序列化类生成 int ID,后续在序列化时使用 int ID 唯一标识该类型。
(2)Kryo 不是线程安全的。每个线程都应该有自己的 Kryo 对象、输入和输出实例。因此在多线程环境中,可以考虑使用 ThreadLocal 或者对象池来保证线程安全性。
(3)不需要实现Serializable接口。
(4)相较于 JDK 自带的序列化方式,Kryo 的性能更快,并且由于 Kryo 允许多引用和循环引用,在存储开销上也更小。只不过,虽然 Kryo 拥有非常好的性能,但其自身却舍去了很多特性,例如线程安全、对序列化对象的字段修改等。虽然这些弊端可以通过 Kryo 良好的扩展性得到一定的满足,但是对于开发者来说仍然具有一定的上手难度,不过这并不能影响其在 Java 中的地位。
【Protobuf】:一个用来序列化结构化数据的技术,支持多种诸如c++、java以及python语言,可以使用该技术来持久化数据或者序列化成网络传输的数据。相比较一些其他的xml技术而言,该技术的一个明显特点就是更加节省空间(以二进制存储)、速度更快以及更加灵活。另外Protobuf支持的数据类型相对较少,不支持常量类型。
3.8如果不使用json工具,该如何实现对实体类的序列化?
(1)可以使用java原生的序列化机制,但是效率比较低一点,适合小项目
(2)可以使用第三方类库,比如Kryo、Protobuf等等。

若有收获,就点个赞吧
0 人点赞
