2.1说说Redis为什么单线程还能这么快?
Redis是单线程主要是指Redis的网络IO和键值对读写是由一个线程来完成的,这也是Redis对外提供键值存储服务的主要流程。但Redis的其他功能,比如持久化、异步删除、集群数据同步等,其实都是由额外的线程来执行的。
使用多线程,可以提高系统吞吐率,提高系统扩展性。的确,但这是在合理的资源分配的情况下,可以提高系统能够同时处理并发请求的数量,但如果采用多线程后,如果没有良好的系统设计,实际得到的结果可能是刚开始增加线程数时系统吞吐率会增加,但是再进一步增加线程时,系统吞吐率增长就迟缓了,甚至还会出现下降的情况。之所以出现这种情况是因为系统中会存在被多线程同时访问的资源,如果多个线程要并发读写这个资源,就会带来额外的开销,比如加锁啊什么的,变成串行执行。所以即使增加了线程,在系统并发数多的情况下,大部分线程也在等待访问共享资源的互斥锁,所以Redis的设计者干脆就直接采用单线程了。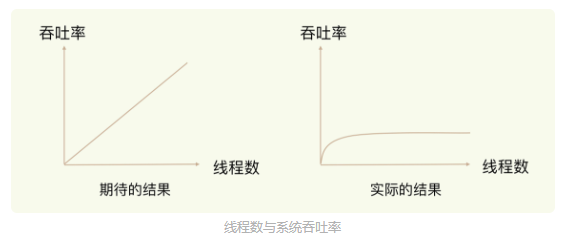
【为什么单线程还能这么快】
Redis的大部分操作都是在内存中完成的,并且Redis采用了高效的数据结构,例如哈希表和跳表,这是他实现高性能的一个重要原因。另一方面,就是Redis采用了多路复用机制,使它在网络IO操作中能并发处理大量的客户端请求,实现高吞吐率。
【基于多路复用的高性能IO模型】
Linux中的IO多路复用机制是指一个线程处理多个IO流,就是select/epoll机制。在Redis只运行单线程的情况下,允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或者数据请求,一旦有请求到达,就会交给Redis线程处理,Reids网络框架调用epoll机制,让内核监听这些套接字,此时Redis线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。所以Redis可以同时和多个客户端连接并处理请求,从而提升并发性。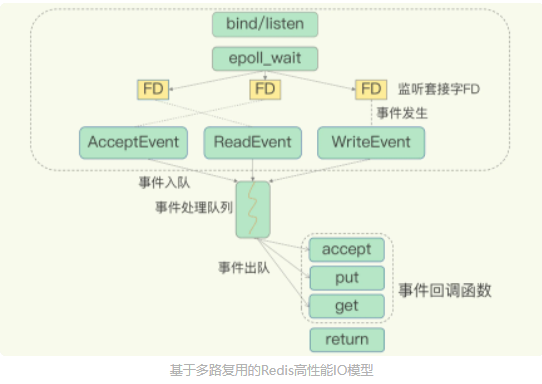
为了在请求到达时能通知Redis,select/epoll机制提供了基于事件的回调机制,就是针对不同事件的发生,调用响相应的处理函数。select/epoll一旦监听到FD上有请求到达时,就会触发相应的事件。这些事件会被放入到一个事件队列中,Redis单线程对该事件队列不断进行处理。这样一来,Redis无需一直轮询是否有请求事件发生,这就可以避免CPU资源浪费。同时,Redis在对事件队列中的事件进行处理时,会调用相应的处理函数,实现基于事件的回调,快速响应客户端。
打个比方:以连接请求和读数据请求为例。
这两个请求分别对应Accept事件和Read事件,Redis分别对这两个事件注册accept函数和read函数。当Linux内核监听到有连接请求或读数据请求时,就会触发Accept事件和Read事件,内核就会回调Redis的accept和get函数进行处理。这就像病人去医院瞧病。在医生实际诊断前,每个病人(等同于请求)都需要先分诊、测体温、登记等。如果这些工作都由医生来完成,医生的工作效率就会很低。所以,医院都设置了分诊台,分诊台会一直处理这些诊断前的工作(类似于 Linux 内核监听请求),然后再转交给医生做实际诊断。这样即使一个医生(相当于 Redis 单线程),效率也能提升。
(1)阻塞式IO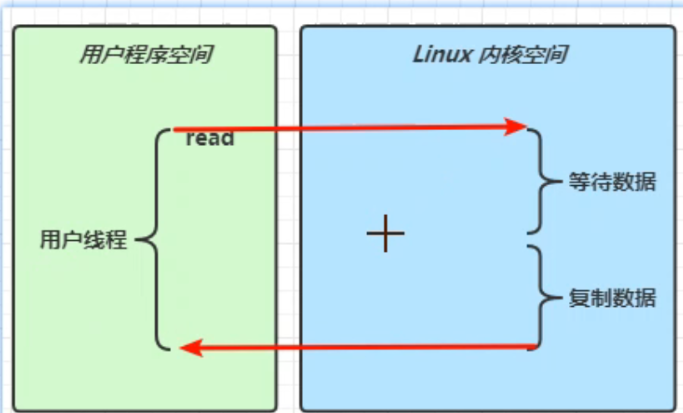
在阻塞式IO模式下,一个线程只能对应去处理一个请求。比如先开启服务端,监听套接字上的连接请求和读写请求,如果监听不到连接请求就会一直阻塞在那里,这时候有一个客户端发出请求,请求与服务端建立连接,通过TCP三次握手,服务端的线程就可以恢复运行了,再去等待读取数据的请求,这时候如果再有其他客户端发出连接请求就无法得到响应也就是说,在单线程模式下一个线程只能处理一个请求。如果要多处理多个请求,来一个请求就要用一个线程去处理。
(2)非阻塞式IO
非阻塞模式下就是一直等待用户的请求,不断循环,不断等待内核的返回结果。如果读到数据就返回>0,如果没读到就返回0,其他啥活也干不了。这就会耗费大量的CPU资源,一直在那里空转。
(3)多路复用
多路复用就是就是内核来监听套接字上的连接请求或者是读写请求,一旦有事件发生就扔进事件队列中,然后redis对这些事件都注册了相应的函数,而且redis也不需要一直从这个事件队列中去取请求一直在那死循环让cpu空转,而是内核直接回调Redis的accept函数或者是read函数,这样Redsi单线程就能够去处理请求。等处理完成以后,Redis又可以去处理别的请求了,不会在阻塞在一个客户端的处理请求上。

若有收获,就点个赞吧
0 人点赞
