- 1.1说说项目的整体架构
- 1.2说说数据库表是怎么设计的?
- 1.3说说怎么使用Maven创建一个聚合工程的?
- 1.4说说用户模块开发了哪些功能?
- 1.5说说用户短信注册登录这个功能怎么开发的?
- 1.6说说你是怎么优化查询用户信息的接口的?
- 1.7说说讲讲如果使用session存储短信验证码会出现什么问题,是怎么做优化的?使用Redis存储验证码是怎么做的,相较于之前方法的好处是什么?
- 1.8说说怎么保证缓存数据库数据的一致性?
- 1.9你的项目中使用了拦截器?知道拦截器的原理吗?具体使用拦截器做了什么?
- 1.10你的项目中使用了SpringAOP吗?具体拿它来做什么?
- 1.11管理员登录时支持密码模式与人脸识别模式是吧?那你怎么保证密码的安全性?
- 1.12说说管理员人脸入库、登录的业务流程
- 1.13做做小笔记,分析数据库查询场景
- 1.14文章阅读数是如何接口防刷的?
- 1.15说说你的文章首页做的优化
- 1.16文章详情页面是如何显示评论的?
- 1.17说说为什么你要使用redis的Set数据类型来保存用户之间的关注、粉丝关系?
- 1.18说说怎么实现用户发文内容审核功能的?
- 1.19数据统计是怎么做的,UV 、DAU都是怎么计算的?
- 1.20项目中使用了Mysql和Redis,为什么还要使用MongoDB?
- 1.21说说什么是页面静态化技术?
- 1.22项目中使用消息队列RabbitMq具体做了哪些功能?
- 1.23说说项目中是怎么使用ElasticSearch的?
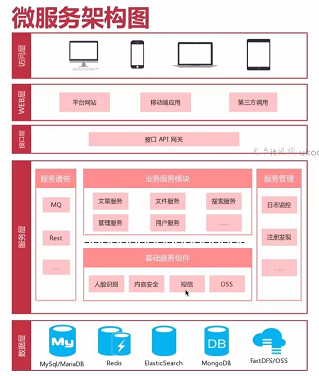
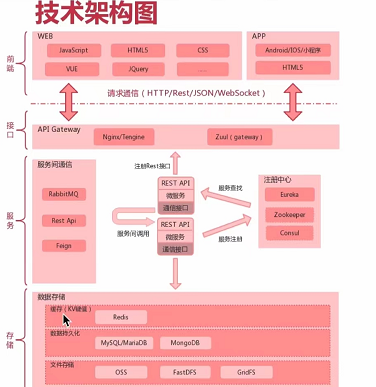
1.1说说项目的整体架构
1.2说说数据库表是怎么设计的?
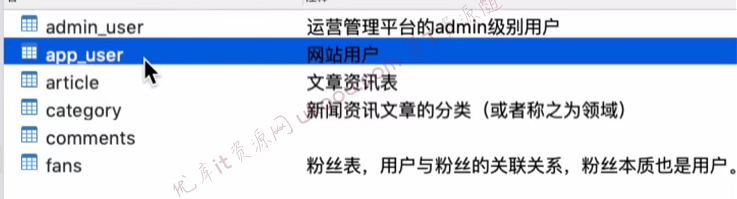
【user表】
user的id是主键索引,并为mobile字段建立了唯一索引。并且这个查询条件也是在经常使用的,比如判断前端传入的一个手机号,该账号是否已经注册、状态是否正常等操作。user表符合数据库三大范式,所有字段都不可再分割(包含地址都拆分成了省市区)、这张表只说明了关于user的信息、并且字段与主键直接相关。
为了保护用户的隐私数据,设计了属性不同的userVo对象,来应对不同的使用场景。
(1)当用户打开个人中心页面时,可以看到自己账号的相关设置信息。以上信息基本都有,并且用户的手机号显示时使用了脱敏处理。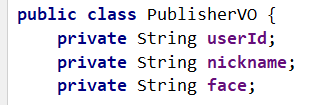
(2)在用户访问文章首页或文章详情页时,都需要看到发布帖子(评论)人的头像和昵称, 且只需要这两项基本信息即可。
【admin表】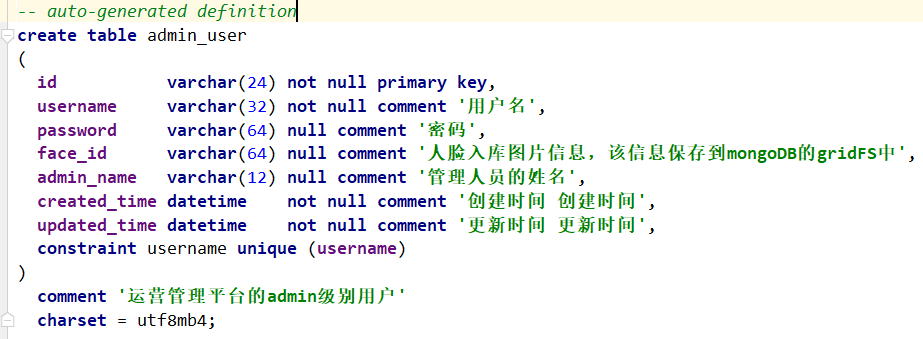
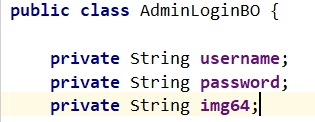
admin表支持人脸识别登录与账号密码登录两种模式。在admin登录时会根据前端传入的参数做验证,如果password为空,则验证img64是否为空,如果都为空就返回错误提示给客户。所以在设计这张表时,允许这两个字段为null值。
【article表】
【comment表】:看1.15
【fans表】:使用redis的set类型来实现
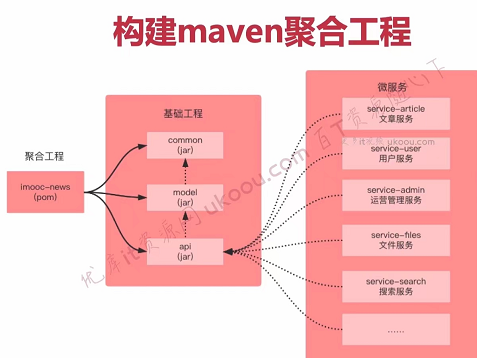
1.3说说怎么使用Maven创建一个聚合工程的?
(1)聚合工程可以分为顶级项目(顶级工程,父工程)与子工程(子module模块), 这两者的关系其实就是父子继承的关系,子工程在maven中可以称之为module,模块与模块之间是平级的,是可以相互依赖的。顶级项目就是整个web项目,其中的common子模块用来存放工具类、枚举类等;其中的model子模块用来存放pojo、entity等类;api模块就是整个web项目的接口。1.整个项目的接口都在这个模块暴露,实现都是在各自的微服务中。好处就是微服务之间的调用都是基于接口的调用,而所有的核心模块都依赖于api模块;如果不这么做的话,接口之间就会有相互依赖的耦合关系,耦合度就相当高了。另外swagger2是基于接口的自动文档生成,所有的配置文件只需要一份,就能在当前项目去构建了,管理起来很方便。
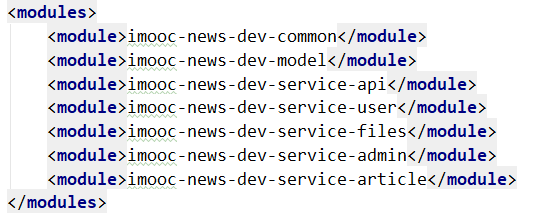
(2)子模块可以使用顶级工程中所有的资源(依赖),子模块之间如果有要使用资源的话,必须构建依赖(构建关系)。

(3) 一个顶级工程是可以由多个不同的子工程共同组合而成。
(4)使用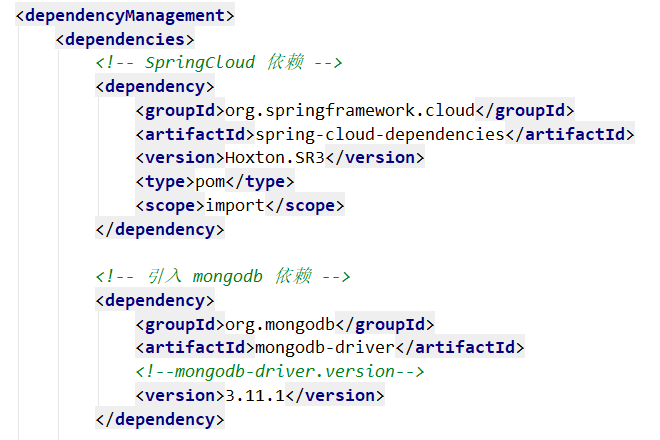
(5)使用
1.4说说用户模块开发了哪些功能?

1.5说说用户短信注册登录这个功能怎么开发的?
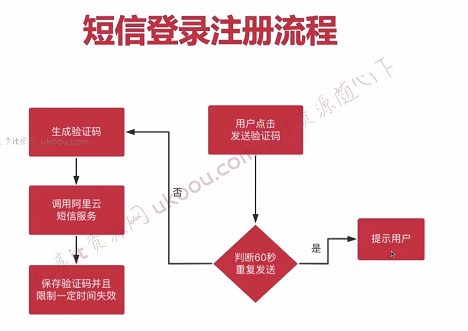
【获取验证码接口和接口防刷】
(1)首先需要定义getSMSCode接口,这个功能传入的参数是用户的手机号以及httpRequest,从请求上下文中去获取用户的ip地址,通过redis的setex命令限制用户ip地址在60s内只能获得一次验证码,redis的key为ip:limit:smscode:+ip地址,value为ip地址。然后通过Random函数生成6位随机数,保存在redis中,这个失效时间可以长一点,我设置的是30分钟。redis的key为mobile:smscode:+用户手机号,value为用户的手机号。
(2)接着通过阿里云的提供的sms短信服务接口,向用户的手机号发送验证码。
(3)接口防刷与倒计时:这个功能主要是针对如果用户频繁刷新浏览器页面,会导致限制用户60s内获取一次验证码的功能失效,解决方法就是添加一层拦截器,来过滤用户的请求。具体就是定义一个PassportInterceptor,实现HandlerInterceptor接口,重写preHandler()。在preHandler方法中从请求上下文去获取用户的ip地址,然后根据ip地址去redis中获取是否存在有这个ip地址的key,如果存在的话就将请求拦截,返回用户信息:短信发送频率过高,请稍微重试。然后将该拦截器注解到InterceptorConfig中。
@Overridepublic GraceJSONResult getSMSCode(String mobile, HttpServletRequest request) {// 获得用户ipString userIp = IPUtil.getRequestIp(request);// 根据用户的ip进行限制,限制用户在60秒内只能获得一次验证码redis.setnx60s(MOBILE_SMSCODE + ":" + userIp, userIp);// 生成随机验证码并且发送短信String random = (int)((Math.random() * 9 + 1) * 100000) + "";// smsUtils.sendSMS(MyInfo.getMobile(), random);// 把验证码存入redis,用于后续进行验证redis.set(MOBILE_SMSCODE + ":" + mobile, random, 30 * 60);return GraceJSONResult.ok();}
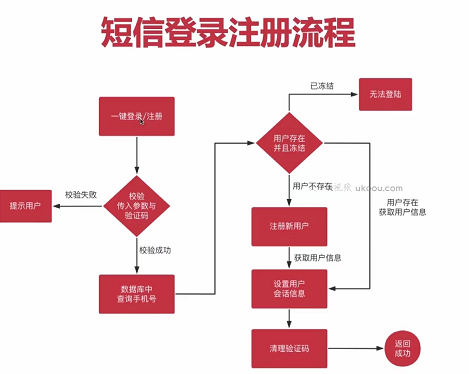
【一键登录注册】
(1)方法行参为RegistLoginBO对象,BindResult,请求,响应;BO对象中包括属性手机号和验证码,使用@NotBlank注解声明在Bo的mobile、smsCode属性上。
(2)开发doLogin接口,使用@Valid注解对前端传递的参数进行验证,判断BindingResult中是否保存了错误的验证信息,如果有,则需要返回。
(3)从Bo对象中获取mobile和smsCode字段的值,然后从redis中根据mobile获取验证码的值,从而进行判断。
(4)通过mobile字段从后端数据库中查询是否存在这个用户,如果用户不为空,并且状态为冻结则直接抛出异常,禁止登陆;如果用户没有注册过,则将注册信息入库。
(5)通过uuid生成会话token,保存userInfo与会话token到redis中,登录成功后如果用户状态已激活会重定向到状态激活页面,用户将自己的基本信息完善即可完成激活操作。
@Overridepublic GraceJSONResult doLogin(@Valid RegistLoginBO registLoginBO,BindingResult result,HttpServletRequest request,HttpServletResponse response) {// 0.判断BindingResult中是否保存了错误的验证信息,如果有,则需要返回if (result.hasErrors()) {Map<String, String> map = getErrors(result);return GraceJSONResult.errorMap(map);}String mobile = registLoginBO.getMobile();String smsCode = registLoginBO.getSmsCode();// 1. 校验验证码是否匹配String redisSMSCode = redis.get(MOBILE_SMSCODE + ":" + mobile);if (StringUtils.isBlank(redisSMSCode) || !redisSMSCode.equalsIgnoreCase(smsCode)) {return GraceJSONResult.errorCustom(ResponseStatusEnum.SMS_CODE_ERROR);}// 2. 查询数据库,判断该用户注册AppUser user = userService.queryMobileIsExist(mobile);if (user != null && user.getActiveStatus() == UserStatus.FROZEN.type) {// 如果用户不为空,并且状态为冻结,则直接抛出异常,禁止登录return GraceJSONResult.errorCustom(ResponseStatusEnum.USER_FROZEN);} else if (user == null) {// 如果用户没有注册过,则为null,需要注册信息入库user = userService.createUser(mobile);}// 3. 保存用户分布式会话的相关操作int userActiveStatus = user.getActiveStatus();if (userActiveStatus != UserStatus.FROZEN.type) {// 保存userInfo、会话token到redisString uToken = UUID.randomUUID().toString();redis.set(REDIS_USER_TOKEN + ":" + user.getId(), uToken);redis.set(REDIS_USER_INFO + ":" + user.getId(), JsonUtils.objectToJson(user));// 保存用户id和token到cookie中setCookie(request, response, "utoken", uToken, COOKIE_MONTH);setCookie(request, response, "uid", user.getId(), COOKIE_MONTH);}// 4. 用户登录或注册成功以后,需要删除redis中的短信验证码,验证码只能使用一次,用过后则作废redis.del(MOBILE_SMSCODE + ":" + mobile);// 5. 返回用户状态return GraceJSONResult.ok(userActiveStatus);}
1.6说说你是怎么优化查询用户信息的接口的?
(1)getUser的接口访问压力肯定是巨大的,如果每次都要从后端数据库中去取值的话,后端数据库的请求压力也会非常大,即使是根据userId的主键去查询user信息也免不了要经过几次磁盘io。所以考虑用redis分布式存储userInfo的基本信息。
(2)使用sessionStorage将用户vo的基本信息保存在客户端的浏览器上,这个基本信息只包括用户id、头像、昵称等基本信息,不包含隐私数据。sessionStorage保存的数据可用于浏览器的一次会话,当会话结束(通常是窗口关闭时),数据会被清空,而LocalStorage保存的数据长期存在,下一次访问该网站的时候,网页也可以直接读取以前保存的数据。保存的数据都是以键值对的形式存在,它们都仅保存在客户端的浏览器上,不占用服务端的资源。
1.7说说讲讲如果使用session存储短信验证码会出现什么问题,是怎么做优化的?使用Redis存储验证码是怎么做的,相较于之前方法的好处是什么?
分布式项目的每个微服务如果要保证高可用,通常会部署多台服务器,而用session存储验证码,会将验证码存储在某一台服务器上。但如果下一次的请求访问了其他服务器,而这台服务器没有之前的session,就会新建一个session,创建两个session,那么就可能造成数据错误,所以要保证session唯一性,其次是session保存在服务器上,随着客户端的访问增多,服务器的压力就会越来越大。
(1)粘性session,通过设置一致性哈希的负载均衡分配策略解决,同一个浏览器ip固定分给同一个服务器去处理,但这样很难保证服务器负载均衡,性能不好。
(2)同步session,当一个服务器创建了session后,就同步给其他的服务器,但这样做同步,服务器之间就会产生耦合关联,影响部署。
(3)部署session服务器,用一台服务器单独保存session,专门存放所有用户的session,等需要使用到session的时候都去找这台服务器,但如果这台服务器挂了,那所有服务器需要使用到session的功能都会瘫痪,违背分布式的原则。
(4)主流方案是:尽量把数据存放到cookie里,敏感数据存到cookie可能就会有安全问题,所以把验证码保存到nosql数据库里,并设置过期时间。
存储的过程是:因为验证码是针对某个用户,所以服务器应该识别这个验证码属于哪个用户。用户请求获取验证码,因为这时候用户还没有登录,所以唯一标识该用户身份的就是ip地址,等用户做登录请求的时候,就可以从redis里根据ip地址取出smsCode与前端传来的code进行对比。另外验证码需要频繁的刷新和访问,对性能要求高,redis能解决这个问题。
1.8说说怎么保证缓存数据库数据的一致性?
public void updateUserInfo(UpdateUserInfoBO updateUserInfoBO) {String userId = updateUserInfoBO.getId();// 保证双写一致,先删除redis中的数据,后更新数据库redis.del(REDIS_USER_INFO + ":" + userId);AppUser userInfo = new AppUser();BeanUtils.copyProperties(updateUserInfoBO, userInfo);userInfo.setUpdatedTime(new Date());userInfo.setActiveStatus(UserStatus.ACTIVE.type);int result = appUserMapper.updateByPrimaryKeySelective(userInfo);if (result != 1) {GraceException.display(ResponseStatusEnum.USER_UPDATE_ERROR);}// 再次查询用户的最新信息,放入redis中AppUser user = getUser(userId);redis.set(REDIS_USER_INFO + ":" + userId, JsonUtils.objectToJson(user));// 缓存双删策略try {Thread.sleep(100);redis.del(REDIS_USER_INFO + ":" + userId);} catch (InterruptedException e) {e.printStackTrace();}}
1.9你的项目中使用了拦截器?知道拦截器的原理吗?具体使用拦截器做了什么?
(1)原理:如果我们定义了一个类,让它实现了HandlerInteceptor接口,就需要重写它的preHandler()、postHandler()、afterCompletion()三个方法。在SpringMVC的执行流程中,使用了设计模式中的适配器模式,在中央调度器根据HandlerMapping中的配置找到具体处理请求的处理器Handler后,通过HandlerAdapter对其进行封装,再以统一的适配器接口对各种handler()进行调用。其中preHandler()以及postHandler()就是在调用handler()方法时进行调用的,preHandler()返回的是一个布尔值,如果返回的是false,那SpringMVC的执行流程就到此终止,直接返回;返回true的话,请求才会放行。afterCompletion()方法是在生成视图view对象并用Model中的模型数据对view对象进行渲染后才被调用。
(2)使用场景:拦截器的功能十分强大,在项目中可以用它来拦截很多非法请求。比如用户未登录、redis中会话token失效、客户端浏览器的会话token失效,它就只能访问作家中心页,无法访问用户个人信息、修改个人信息等url路径的场景。
1.10你的项目中使用了SpringAOP吗?具体拿它来做什么?
(1)一般有三种方式可以对用户的请求进行拦截,三种方式的使用场景都不一样:1.基于网关层的Filter过滤器,它可以是对所有请求包括静态资源的访问都进行拦截;2.基于Controller层的Interceptor拦截器,Controller层作为三层架构的顶层, 在Controller层进行拦截,用户的请求就无法到达Service层以及Mapper层,不对占用系统资源。实现HandlerInteceptor接口,并重写三个方法即可进行对Controller层的拦截。3.除了Controller层以外,所有的bean都可以使用SpringAOP来进行拦截,需要注意的是环绕通知才有拦截的作用,它有目标方法的执行控制权。而其他通知的功能没有环绕通知强大,只是起到一个代理增强的效果。
(2)SpringAOP的功能非常强大,它是一项可以通过运行期动态代理的方式来实现程序功能统一维护的技术。在AOP的思想下,将一批组件共性需求的方法代码独立出来,然后通过配置的方式,声明这些方法在什么地方、什么时候被调用。当满足条件时,AOP会将业务代码织入到我们指定的位置,从而统一解决了问题,又不需要修改这一批组件的原始代码。
(3)在项目中主要使用SpringAOP来实现记录所有service层调用方法耗时的统计日志,主要流程是1.创建ServiceLogAdvice类,并用@Aspect注解和@Component注解声明,表示这是一个切面,这个组件需要由spring容器进行管理。2.在增强方法中通过@Around注解(这个一个环绕通知),然后定义切面表达式,在xxxservice包下的任意service.impl类,任何返回值、任意参数都会被织入通知流程。在proceed()前后分别记录开始时间、结束时间。如果>3s就记录error日志,>2s就记录warn日志,其他记录info日志。
1.11管理员登录时支持密码模式与人脸识别模式是吧?那你怎么保证密码的安全性?
保证密码的安全性,在业务层对前端用户传递来的密码使用了BCrypt算法进行加密,再存入数据库中。Bcrypt是单向Hash加密算法,一般用于密码加密,相对来说,Bcypt比MD5更安全,但是MD5加密会更快速。MD5是一种可反向破解的密码加密,如果你的密文被截获它就可以利用MD5在线解密破解工具来得到密码。而Bcrpy算法不可反向破解,即使黑客截获到密文也无法转换成明文。
BCrypt算法加密的原理是:输入的明文密码通过10次循环加盐后得到myHash,然后存入数据库。系统在验证用户口令时,将前端传来的信息使用相同的算法加密与数据库中的密码进行对比,如果一致则验证通过。
1.12说说管理员人脸入库、登录的业务流程
人脸入库和人脸识别登录是两个不同的操作接口,并且管理员也是支持一键注册、登录的。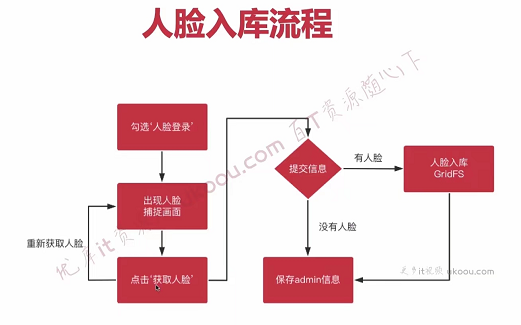
1.13做做小笔记,分析数据库查询场景

【作家中心首页的文章列表展示】:
分析:这个路由地址是首页查询文章列表,order by publish_time desc,隐形查询条件:isAppoint(是否是即时发布,必须是即时发布的文章才能被看到)、 isDelete(文章未被博主撤回)、articleStatu(审核通过的才能被看到);显式字段查询:keyWord(文章关键字)、category(文章分类)。然后再使用PageHelper进行分页。
(1)接口首先通过以上信息从后端数据库去查询文章信息,文章信息中有个user_id字段,记录了文章作者的基本信息,需要从后端数据库中通过user_id字段,取出文章作者的昵称和头像。
(2)通过hashSet构建user_id的去重集合;
(3)发起rest远程调用,article服务请求user服务来获得user基本信息集合。
(4)拼接两个List集合,重组文章列表
【当前文章的详情页面展示】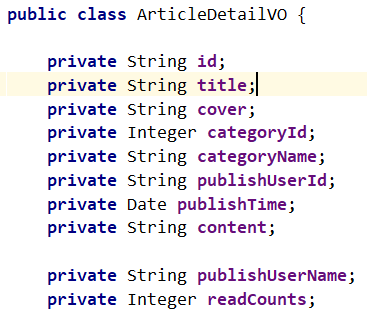
1.14文章阅读数是如何接口防刷的?
使用redis的setnx命令+Inteceptor。
(1)从httpRequest中获得用户的ip,当用户使用当前ip第一次访问文章详情时,拦截器的逻辑是会查询redis中是否存在这个key,第一次肯定是不存在的所以请求放行,setnx+artilceId+ip返回1,设置成功。
@Overridepublic GraceJSONResult readArticle(String articleId, HttpServletRequest request) {String userIp = IPUtil.getRequestIp(request);// 设置针对当前用户ip的永久存在的key,存入到redis,表示该ip的用户已经阅读过了,无法累加阅读量redis.setnx(REDIS_ALREADY_READ + ":" + articleId + ":" + userIp, userIp);redis.increment(REDIS_ARTICLE_READ_COUNTS + ":" + articleId, 1);return GraceJSONResult.ok();}
(2)以后如果再次访问该文章详情页,拦截器就会拦截这个路由,不会执行redis中valueIncr的逻辑。
@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {//在拦截器中,使用setnx命令,将当前用户id与文章id绑定。//如果下次判断redis中存在这个key,就直接限制请求,不予放行。String articleId = request.getParameter("articleId");String userIp = IPUtil.getRequestIp(request);boolean isExist = redis.keyIsExist(REDIS_ALREADY_READ + ":" + articleId + ":" + userIp);if (isExist) {return false;}return true;}
类似的,文章的评论数量、用户的粉丝数量以及关注数量,也使用了redisSDS数据类型的incr与decr命令来实现。
1.15说说你的文章首页做的优化
【优化点】:我们在首页进行文章列表查询的时候会显示该页面所有文章的阅读数量,传统方式是:我们构建一个List集合,然后每次从数据库中拿到一个articleId,都需要到redis中去取出这个文章的阅读数。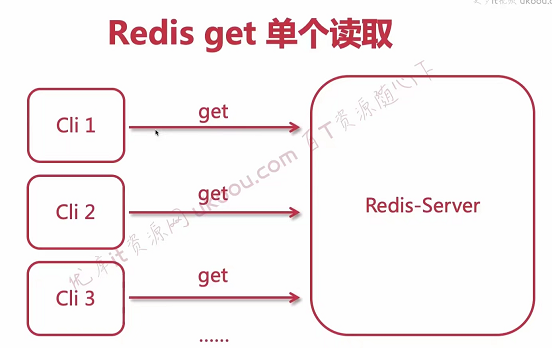
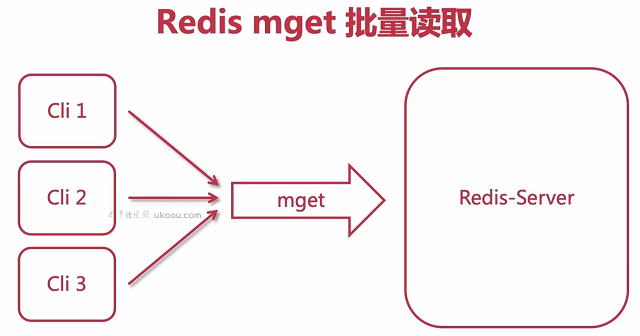
其实这个点可以做一个优化,因为本来在显示文章详情页的时候还需要拿到文章作者的头像与用户名是然后聚合显示一个List
// STARTList<Article> list = (List<Article>)gridResult.getRows();// 1. 构建发布者id列表Set<String> idSet = new HashSet<>();List<String> idList = new ArrayList<>();for (Article a : list) {// System.out.println(a.getPublishUserId());// 1.1 构建发布者的setidSet.add(a.getPublishUserId());// 1.2 构建文章id的listidList.add(REDIS_ARTICLE_READ_COUNTS + ":" + a.getId());}// 发起redis的mget批量查询api,获得对应的值List<String> readCountsRedisList = redis.mget(idList);//for (int i = 0 ; i < list.size() ; i ++) {IndexArticleVO indexArticleVO = new IndexArticleVO();Article a = list.get(i);BeanUtils.copyProperties(a, indexArticleVO);// 3.1 从publisherList中获得发布者的基本信息AppUserVO publisher = getUserIfPublisher(a.getPublishUserId(), publisherList);indexArticleVO.setPublisherVO(publisher);// 3.2 重新组装设置文章列表中的阅读量String redisCountsStr = readCountsRedisList.get(i);int readCounts = 0;if (StringUtils.isNotBlank(redisCountsStr)) {readCounts = Integer.valueOf(redisCountsStr);}indexArticleVO.setReadCounts(readCounts);indexArticleList.add(indexArticleVO);}
1.16文章详情页面是如何显示评论的?
首先介绍数据库中的comment表。
mapper层的sql语句使用了表的自关联查询,因为评论有可能是针对帖子的评论,或者是针对评论的评论(回复)
因为comment表的id是主键,所以这个自关联查询的操作效率也不会太低的。首先从数据库comment表中读取id=#{id},然后再从这个数据记录中取出它的father_id,再从另一张从去寻找有没有id=这个father_id,另一张表也是走的主键索引遍历,所以速度是很快的。
1.17说说为什么你要使用redis的Set数据类型来保存用户之间的关注、粉丝关系?
这里主要是考虑到了项目的应用场景以及扩展性,在选型时考虑了三种方案:
(1)数据库存储用户(偶像->粉丝)之间的关系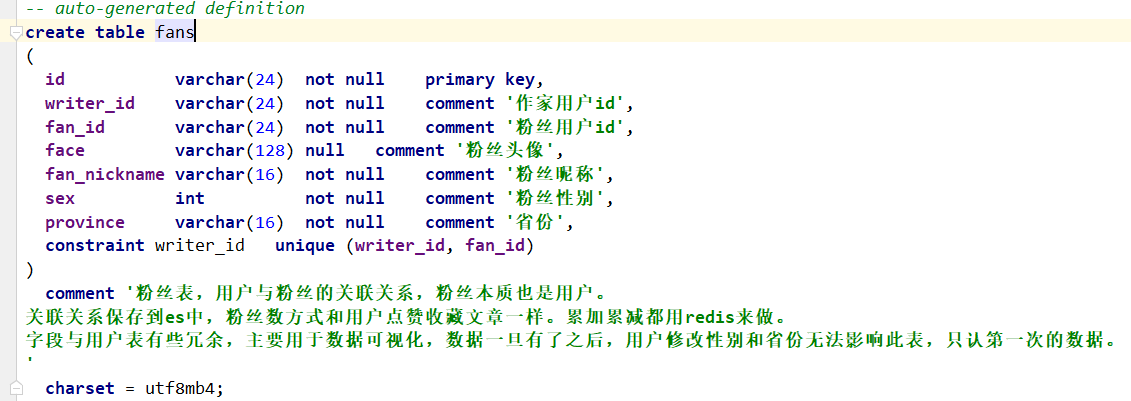
设计fans表,id为主键,idol_id以及fan_id为唯一索引。
//当我们查询某个爱豆的粉丝列表时select fan_nickname,face from fans where idol_id = #{id};//当我们查询某个粉丝的爱豆列表时select idol_id from fans where fan_id = #{id}; //然后再从user表中根据idol_id主键去找用户信息
这样做其实是可以的,而且数据持久化保存在磁盘中,不用担心宕机、掉电数据丢失的风险。而且idol_id以及fan_id也建立了唯一索引,查询的效率也是很快的。但缺点就是可扩展性不强。
(2)使用redis的set数据类型来维护用户idol与fan之间的关系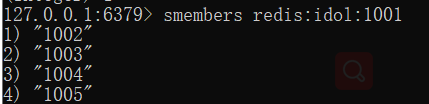
用redis来实现的话,就非常轻松了,比如1001的用户有四位粉丝,分别是1002、1003、1004、1005。同理,1002…等粉丝的偶像列表都插入1001。在业务层,使用redis的multi和exec事务命令来实现。
multi:用于标记一个事物块的开始。事务块内的多条命令会按照先后顺序被放入一个队列中,最后由exec命令原子性地执行。
exec:用于提交一个事务块,事务块队列内的所有命令都会按照顺序执行。
//关注public void follow(int userId,int entityType,int entityId){redisTemplate.execute(new SessionCallback() {@Overridepublic Object execute(RedisOperations operations) throws DataAccessException {String followeeKey= RedisKeyUtil.getFolloweeKey(userId,entityType);String followerKey=RedisKeyUtil.getFollowerKey(entityType, entityId);operations.multi();operations.opsForZSet().add(followeeKey,entityId,System.currentTimeMillis());operations.opsForZSet().add(followerKey,userId,System.currentTimeMillis());return operations.exec();}});}
另外,使用Set数据类型来保存idol与粉丝之间的关系,主要是考虑到了业务可扩展,因为set类型的inner、diff、union命令分别是求多个集合元素的交、差、并集,分别有不同的使用场景。打个比方:
(1)当userA查看userB的关注列表时,不仅可以返回userB的关注列表,还可以返回userA与userB的共同关注队列。这就需要使用sinner命令来快速获得两个集合元素之间的交集。类似的还可以用于实时聊天系统,拉取好友列表时,可以返回我与该好友的共同好友列表。
(2)当userA查看userB的关注列表时,不仅可以返回userB的关注列表,还可以返回userA可能认识的人。这个功能在QQ中也有实现,大致思路就是找出userB列表与userA列表之间差集(独属于userB不属于userA),这样随机返回几个名单即可,不需要全部返回。
使用set数据类型来保存用户之间关系的缺点就是,set集合是无序的,这样遍历时不能按照顺序来返回。而我们查看自己的关注列表时,通常会返回最近关注的一些列表信息,而不希望返回很老的数据信息。所以可以使用redis的zset数据类型来进行存储,zset的权重值scoreJ就是关注时的系统时间,key就是用户id。这样在返回数据时,就可以根据权重值来返回,权重值大的排在前面。如果既需要考虑将来业务扩展,又要求遍历顺序;那可以使用set+zset两种数据类型来维护。就是稍微麻烦了点,而且占用空间开销也会翻倍。
使用redis的zrevrange来实现拉取关注列表。
//查询某个用户关注的人public List<Map<String,Object>> findFollowees(int userId,int offset,int limit){String followeeKey=RedisKeyUtil.getFolloweeKey(userId,ENTITY_TYPE_USER);Set<Integer> targetIds = redisTemplate.opsForZSet().reverseRange(followeeKey, offset, offset + limit - 1);if(targetIds==null){return null;}List<Map<String,Object>> list=new ArrayList<>();for (Integer targetId : targetIds) {HashMap<String, Object> map = new HashMap<>();User user = userService.findUserById(targetId);map.put("user",user);Double score = redisTemplate.opsForZSet().score(followeeKey, targetId);map.put("followTime",new Date(score.longValue()));list.add(map);}return list;}
1.18说说怎么实现用户发文内容审核功能的?
用户发表文章时,表现层对前端传参进行审核,如果没问题就会调用表现层。表现层中会对用户发表文章的内容进行审核,具体是使用阿里云的文本内容检测技术来实现的,一般检测会有三种结果:通过、存疑与失败。通过文章所有游客都可以访问,存疑文章由后台管理员再次进行人工审核,失败的文章直接不予通过。
但阿里ai毕竟是一个收费的技术,即使不使用它,我们依然有办法来对用户发文的敏感内容进行过滤,或者直接请求驳回。这就需要使用到前缀树的数据结构了。前缀树的根节点不包含字符,每个子节点都只包含一个字符,每条路径都是一个敏感词。
(1)首先配置敏感词文本,创建一棵树交由spring容器来管理,使用@PostConstruct注解,在容器实例化这个bean以后,在调用构造器以后这个方法就会被自动调用。
(2)每一行的敏感词中所有字符都存入树中,每一行敏感词的最后一个字符使用boolean位标记。
(3)在客户端调用发布帖子等需要填入和subject和content接口的时候,在service层对客户端传来的subject与content进行敏感词过滤。使用一对快慢指针指向客户端传来的文本字符开头,一个指针指向前缀树,如果不是敏感字就直接添加至StringBuilder中,如果是敏感词需要不断移动指针,如果发现了快指针指向的文本是敏感词的末尾,就把快慢指针所指向的字符中间都用*替换掉。
1.19数据统计是怎么做的,UV 、DAU都是怎么计算的?
(1)uv是根据用户的ip排重统计数据,每次访问都需要进行统计。使用redis的高级数据类型hyperLogLog(超级日志)。它采用基数算法,用于完成独立总数的统计,占据空间小,无论统计多少个数据,只占用12K的内存空间,但它是一种不精确的统计算法,标准误差为0.81%。
(2)dau是根据用户的id排重统计数据,只要用户登录访问过页面就认为他是活跃用户。使用redis的高级数据类型bitMap(位图),性能好,而且可以统计精确的结果。它不是一种独立的数据结构,实际上就是字符串、支持按位存储数据,可以把它看成是byte数组,适合存储大量连续数据的布尔值。
//Service@Servicepublic class DataService {@Autowiredprivate RedisTemplate redisTemplate;private SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyyMMdd");//将指定的ip地址计入UVpublic void recordUV(String ip){String redisKey= RedisKeyUtil.getUVKey(simpleDateFormat.format(new Date()));redisTemplate.opsForHyperLogLog().add(redisKey,ip);}//统计指定日期范围内的UVpublic long calculateUV(Date start,Date end){if(start==null||end==null){throw new IllegalArgumentException("参数不能为空!");}//整理该日期范围内的keyList<String> keyList= new ArrayList<>();Calendar calendar = Calendar.getInstance();calendar.setTime(start);//这个时间小于等于endwhile (!calendar.getTime().after(end)){String redisKey = RedisKeyUtil.getUVKey(simpleDateFormat.format(calendar.getTime()));keyList.add(redisKey);calendar.add(Calendar.DATE,1);}//合并这些数据String redisKey= RedisKeyUtil.getUVKey(simpleDateFormat.format(start),simpleDateFormat.format(end));redisTemplate.opsForHyperLogLog().union(redisKey,keyList.toArray());//返回统计的结果return redisTemplate.opsForHyperLogLog().size(redisKey);}//将指定用户计入DAUpublic void recordDAU(int userId){String redisKey= RedisKeyUtil.getDAUKey(simpleDateFormat.format(new Date()));redisTemplate.opsForValue().setBit(redisKey,userId,true);}//统计指定日期范围内的DAUpublic long calculateDAU(Date start,Date end){if(start==null||end==null){throw new IllegalArgumentException("参数不能为空!");}List<byte[]> keyList= new ArrayList<>();Calendar calendar = Calendar.getInstance();calendar.setTime(start);while (!calendar.getTime().after(end)){String redisKey =RedisKeyUtil.getDAUKey(simpleDateFormat.format(calendar.getTime()));keyList.add(redisKey.getBytes());calendar.add(Calendar.DATE,1);}//进行or运算return (long)redisTemplate.execute(new RedisCallback() {@Overridepublic Object doInRedis(RedisConnection connection) throws DataAccessException {String redisKey = RedisKeyUtil.getDAUKey(simpleDateFormat.format(start),simpleDateFormat.format(end));connection.bitOp(RedisStringCommands.BitOperation.OR,redisKey.getBytes(),keyList.toArray(new byte[0][0]));return connection.bitCount(redisKey.getBytes());}});}}
//拦截器@Componentpublic class DataInterceptor implements HandlerInterceptor {@Autowiredprivate DataService dataService;@Autowiredprivate HostHolder hostHolder;//在Controller执行之前统计@Overridepublic boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {//统计UVString ip = request.getRemoteHost();dataService.recordUV(ip);//统计DAUUser user = hostHolder.getUser();if(user!=null){dataService.recordDAU(user.getId());}return true;}}
注意:
(1)网站独立访客uv计数统计,可以在MVC执行流程的拦截器中实现,用户访问服务器的任意地址,都会被拦截然后redis计数。当然也可以在分布式网关zuul中进行拦截,网关是所有请求、流量的入口。
(2)针对dau的网站用户日活的统计,由于这个项目的user表采用的是雪花算法生成的id,所以实现起来比较难。比如是数据库自增主键id的话实现起来就非常简单了,比如2022-06-27,userId为1、2、3用户访问了网页,那redis的位图索引下标为1、2、3的元素就设为1。如果在这个项目中要实现网页用户日活统计的话,就需要对User表的结构进行迭代,然后业务逻辑也需要发生一些更改。首先user表需要新增一个字段为virtual_id,并为这个字段设置为唯一索引。这个virtual_id字段其实就是我们以前使用的数据库自增主键id,只是自增主键id在分布式环境以及生产环境下下,容易导致id不唯一以及信息暴露等一系列问题。当新增一个用户时,使用redis的incr命令将key对应的value自增1,然后拿到这个自增的全局唯一的id值作为virtual_id。这样就能实现dau统计了。
1.20项目中使用了Mysql和Redis,为什么还要使用MongoDB?
(1)在这个项目中,我使用了mongoDB的gridFS来存储一些文件(比如人脸入库的人脸图片)的数据、Html静态化页面等。
(2)在许多互联网项目中,mongoDB也有许多的使用场景,比如存储历史快照数据:比如在如果我们在淘宝中很久以前就已经购买一些物品,这些数据已经不会再更改了,而且这个订单的详细信息是针对于这一个用户的,那这些订单的详情细节该放在哪里呢?如果放在redis中,内存资源是非常珍贵的,这些历史数据不是热点数据,访问量相对校对,放在redis中不合适。那放在mysql数据库中呢。比如用户浏览记录,在大型互联网项目中一般都会有近期足迹这个功能,这种资源也可以存储在mongoDB中。然后还有就是存储与客服的聊天记录一般也都会存储在mongoDB中。
(3)因为这部分数据并不是整个系统的核心数据,也不是核心业务,不会涉及到整个系统的可用性。所以这部分数据可以就单独剥离出去。哪怕整个mongoDB宕机崩溃了,也不会影响整个系统的核心业务。而使用mongoDB的话可以也分摊一部分的数据库压力。这也是使用mongoDB的好处。
(4)因为MongoDB的索引是使用的B树的数据结构来组织的,B树的所有叶子都保存了真实的数据记录,所以B树的单次单点查询是比Mysql快的。
1.21说说什么是页面静态化技术?
Freemarker,渲染模块数据,生成并展示静态页面
静态化优势:
(1)便于seo(便于网站更容易被搜索引擎去收录)
(2)加速用户访问(最先展示主体部分(文章详情),这部分内容是不会经过请求到后端的,提高网站整体的影响效率。
(3)不经过url请求的话,也会相应得降低数据库的压力
模块引擎技术:jsp\freemarker\thymeleaf、velocity
1.22项目中使用消息队列RabbitMq具体做了哪些功能?
在这个留言板项目中,使用了消息队列主要是体现在了它的一个接口解耦的功能。
(1)在项目中通常我们都会把访问量大的页面使用页面静态化技术例如Freemarker或者是Thymeleaf来渲染模板的数据并展示静态页面,所以在article微服务中,在ArticleController的createArticle()方法中,我们就需要把生成的静态页面html文件上传到mongoDb的gridFS中,因为采用的是分布式架构,后端服务器生成静态页面html,然后前端服务器从gridFS中去下载这个html文件,分别部署在不同的服务器中,所以不能通过单体架构的那种方式来直接本地调用。那么现在就有两种方式了,第一种方式是,在阿里机审通过后或者是管理员审核通过后(即用户发布文章成功后将生成的html静态页面存储到gridFS中),然后rpc远程调用消费者端去下载这个从gridFS中去下载这个html文件,但是这样做的坏处是rpc远程调用肯定是不如本地调用来得快得,而且会产生一定的接口的耦合性。
所以后面我使用了rabbitMQ的topic(通配符)模式来达到一个接口解耦的作用,一旦文章审核通过后就会将html文件上传到gridFS中,这样生产者直接将消息(articleId和mongoId)通过mq发布到mq的交换机中,这样生产者端就算完事了,生产者端只负责把消息发布出去,甚至它都不需要消息是发送到了哪个queue中。因为在配置mq中会需要将queue与交换机绑定,绑定的时候需要配置路由规则,那么exchange交换机就会根据routingKey的匹配规则,去把消息发布到匹配成功的queue中,这时候生产者发布的消息内容就会作为payLoad的载体由交换机推送到相应的queue中。消费者端的话就只需要监听mq中的某个队列即可,一旦监听到的队列中有消息传递过来就可以从queue中去获取并消费,通过载体中传递过来的articleId和MongoId就可以从gridFs中去下载html文件了。
(2)在留言板项目中,用户发布文章不仅支持即时发送而且还支持延期发送。就是在前段页面,用户可以选择一个时间节点去发布文章,如果用户选择的是即时发布的话那么createTime和publishTime是相等的,并且isAppoint字段的标志位传递给后端的值是0;如果是延期发布,那么创建时间是当前时间,发布时间是用户所选择的具体时间,当然发布的整个过程也是需要阿里ai机审或者是人工审核才能通过的,在文章主页面展示我们也只会展示isAppoint字段值为0的文章。所以想要实现延期发布这个功能的话也可以选择两种方式来实现:第一种方式是使用springboot支持的schedule开启定时任务,使用@Configuration注解定义配置类,使用@EnableScheluding注解表示该类支持定时任务,并在相应的任务方法中使用@Scheduled注解编辑cron(“0/3 ?”)的值,我使用的是每隔3秒去执行一次任务,这个具体的任务就是检查数据库中如果文章的数据记录的isAppoinit的值为1并且发布时间<当前时间就会修改isAppoint的值为0,这样也能够达到延期发布的一个效果。但是因为这种方式的话,其实是对数据库做了一次全表扫描,这样频繁得开启线程去执行任务肯定是对系统会造成影响的,如果把时间间隔设置得稍微长一点的话又不太精确,并且如果在数据量特别多的情况下会对整个系统的运行速度产生影响,同时也会增加数据库的压力。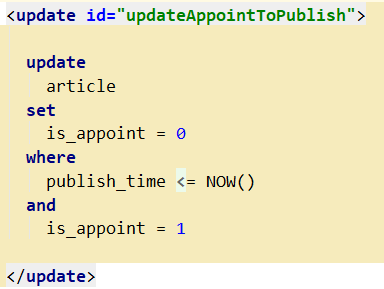
所以无疑使用消息队列来实现这个文章延期发布的功能是更加合适的,并且无论是这样头条项目还是在商城项目中,延期的这个功能也是有许多的应用场景的,所有的大型互联网商城系统都会有用户订单确认收货的功能,如果用户手动确认收货就更改订单表中的字段isReceive,但是如果用户一直没点击这个按钮,那么系统可以设置一定时间比如是七天,七天后就会为用户自动确认收货了;此外还有种场景就是用户在商城首页购买了一件商品,但是一直没有付款,那么也可以设置一段时间间隔后自动为用户取消该笔订单,比如是30分钟后,那么这个功能也是可以使用mq的LazyQueues(延迟队列)来做的。
这个功能具体实现的话也是比较简单的,在配置交换机bean组件的时候,开启delayed属性。然后在生产者端构建一个messagePostProcessor对象,然后设置消息是否持久化,消息延迟的时间。
然后调用rabbitTemplate.convertAndSend()方法中传递该参数,设置延期发布的时间就是页面选择的发布时间减去创建时间的这段时间差值,把文章的主键articleId作为消息载体发送给交换机即可;消费者端主动监听队列,在获取到消息后根据载体中传递过来的主键id来修改单条文章的状态为即时发布的状态,这样也不用像定时任务那样对数据库的整个表做一次全表扫描了。
1.23说说项目中是怎么使用ElasticSearch的?

(1)提供全站搜索服务
- 用户刚点击发文提交时,该文章的审核状态是1(已发布待审核),如果阿里AI验证文章图文以及内容审核通过就会修改文章的审核状态为3(审核通过)。此时通过消息队列,生产者将article_Id作为payload载体,发送到指定交换器上,队列与交换器通过通配符绑定key进行绑定,消费者监听该队列。一旦有消息到达,消费者从队列中拉取消息,然后往ES服务器中插入一条记录。同理,当文章的审核状态为3时(审核通过时),作者用户将该文章撤回,修改文章状态为5,同时也需要通过MQ发送消息给消费者,从ES中删除这条数据记录。
- 当用户在首页使用搜索功能时,通过文章的subject和content进行匹配,匹配到的关键字需要做高亮显示。并且返回的数据记录需要分页显示,按照文章的type(是否置顶)、score(文章的分数)、publish_time(发布时间)三个字段进行倒序排序。

//Service层public Map<String,Object> searchDiscussPost(String keyword,int current,int limit){NativeSearchQuery searchQuery = new NativeSearchQueryBuilder().withQuery(QueryBuilders.multiMatchQuery(keyword,"title","content")).withSort(SortBuilders.fieldSort("type").order(SortOrder.DESC)).withSort(SortBuilders.fieldSort("score").order(SortOrder.DESC)).withSort(SortBuilders.fieldSort("createTime").order(SortOrder.DESC)).withPageable(PageRequest.of(current,limit)).withHighlightFields(new HighlightBuilder.Field("title").preTags("<em>").postTags("</em>"),new HighlightBuilder.Field("content").preTags("<em>").postTags("</em>")).build();SearchHits<DiscussPost> search = restTemplate.search(searchQuery, DiscussPost.class);long totalHits = search.getTotalHits();//得到查询结果返回的内容List<SearchHit<DiscussPost>> searchHits = search.getSearchHits();//设置需要返回的实体类集合ArrayList<DiscussPost> discussPosts = new ArrayList<>();//遍历返回的内容并进行处理for (SearchHit<DiscussPost> searchHit : searchHits) {//高亮的内容Map<String, List<String>> highlightFields = searchHit.getHighlightFields();//将高亮的内容添加到content中searchHit.getContent().setTitle(highlightFields.get("title")==null?searchHit.getContent().getTitle():highlightFields.get("title").get(0));searchHit.getContent().setContent(highlightFields.get("content")==null?searchHit.getContent().getContent():highlightFields.get("content").get(0));//放到实体类中discussPosts.add(searchHit.getContent());}HashMap<String, Object> map = new HashMap<>();map.put("totalHits",totalHits);map.put("discussPosts",discussPosts);return map;}
//Controller层@RequestMapping(path = "/search",method = RequestMethod.GET)public String search(String keyword, Page page, Model model){//搜索帖子Map<String, Object> searchResult = elasticsearchService.searchDiscussPost(keyword, page.getCurrent() - 1, page.getLimit());List<DiscussPost> discussPostList = (List<DiscussPost>) searchResult.get("discussPosts");Number number = (Number) searchResult.get("totalHits");int totalHits = number.intValue();//聚合数据List<Map<String,Object>> discussPosts = new ArrayList<>();if(discussPostList!=null) {for (DiscussPost post : discussPostList) {HashMap<String, Object> map = new HashMap<>();//帖子map.put("post",post);//作者map.put("user",userService.findUserById(post.getUserId()));//点赞数量map.put("likeCount",likeService.findEntityLikeCount(ENTITY_TYPE_POST,post.getId()));discussPosts.add(map);}}model.addAttribute("discussPosts",discussPosts);model.addAttribute("keyword",keyword);//分页信息page.setPath("/search?keyword="+keyword);page.setRows(discussPostList==null?0:totalHits);return "/site/search";}

若有收获,就点个赞吧
0 人点赞
