6.1为什么要有Buffer Pool
虽然说Mysql的数据是存储在磁盘里的,但是也不能每次都从磁盘里面读取数据,这样性能是极差的。所以InnoDB存储引擎就设计了一个缓冲池,每次当数据从磁盘取出后,缓存内存中,下次查询同样的数据,直接从内存中读取。
【有了缓冲池后】:
当读取数据时,如果数据存在于Buffer Pool中,客户端就会直接读取Buffer Pool中的数据,否则再去磁盘中读取。当我们查询一条记录时,InnoDB会把整个页的数据加载到Buffer Pool中,因为通过索引只能定位到磁盘中的页,不能定位到页中的一条记录。将页加载到Buffer Pool后,再通过页目录去定位到某条具体的记录。
当修改数据时,首先是修改Buffer Pool中数据所在的页,然后将页设置为脏页,最后由后台线程将脏页写入到磁盘。
【Buffer Pool有多大】?
Buffer Pool是在Mysql启动的时候,向操作系统申请的一篇连续的内存空间,默认配置下Buffer Pool只有128MB,不过可以调整inndb_buffer_pool_size参数来设置Buffer Pool的大小。
【Buffer Pool缓存什么】?
InnoDB会把存储的数据划分成若干个页,以页作为磁盘和内存交互的基本单位,一个页的默认大小为16KB。因此,Buffer Pool同样需要按页来划分。在Mysql启动的时候,InnoDB会为Buffer Pool申请一片连续的内存空间,然后按照默认的16KB大小划分出一个个的页,Buffer Pool中的页就叫作缓存页。此时这些缓存页都是空闲的,之后随着程序的运行,才会有磁盘中的页被缓存到Buffer Pool中。Buffer Pool除了缓存[索引页]和[数据页],还包括了undo页,插入缓存、自适应哈希索引、锁信息等等。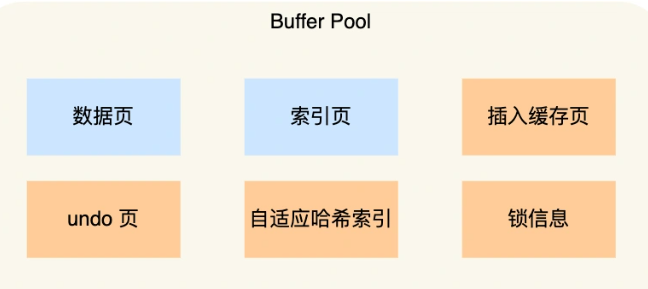
为了能够更好的管理这些Buffer Pool中的缓存页,InnoDB为每一个缓存页都创建了一个控制块,控制块信息包括缓存页的表空间、页号、缓存页地质、链表节点等等。控制块也是占有内存空间的,它放在Buffer Pool的最前,指向缓存页。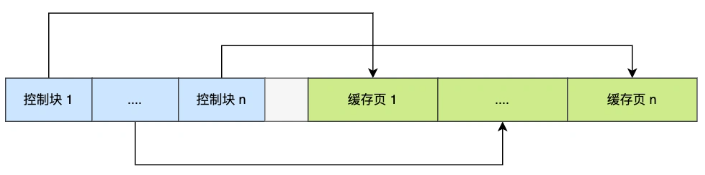
【如何管理空闲页?】
当我们从磁盘读取数据的时候,总不能通过遍历这一片连续的内存空间来找到空闲的缓存页吧,这样效率就太低了。所以为了能够快速找到空闲的缓存页,可以通过链表结构,将空闲缓存页的控制块作为链表的节点,这个链表称为Free链表。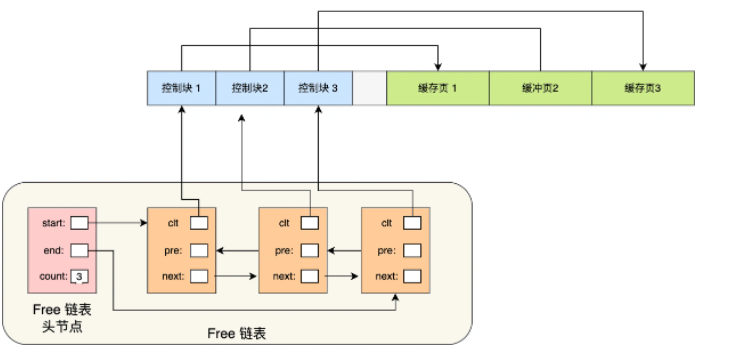
Free链表的头结点是哑结点,存储链表的头结点地址,尾结点地址,以及当前链表中节点的数量信息。
Free链表的节点的其实就相等于是控制块不过是被封装成了链表的节点(就像是AQS中那样将线程封装成节点),每个控制块指向缓存页的地址,所以相当于Free链表节点都对应着一个空闲的缓存页。
有了Free链表以后,每当需要从磁盘加载一个页到Buffer Pool中时,就从Free链表中取出一个空闲的缓存页,并且把该缓存页对应的控制块的信息填上,然后把该缓存页对应的控制块从Free链表中移除。
【如何管理脏页?】
设计BufferPool除了能提高读性能,还能提高写性能,也就是更新数据的时候,不需要每次都写入磁盘,而是将Buffer Pool对应的缓存页标记为脏页,然后由后台线程将脏页写入到磁盘。
为了能够快速知道哪些缓存页是脏页,于是就设计了Flush链表,它与Free链表类似,链表的节点也是控制块,Flush链表的元素都是脏页。后台线程可以遍历Flush链表,将脏页写入到磁盘中。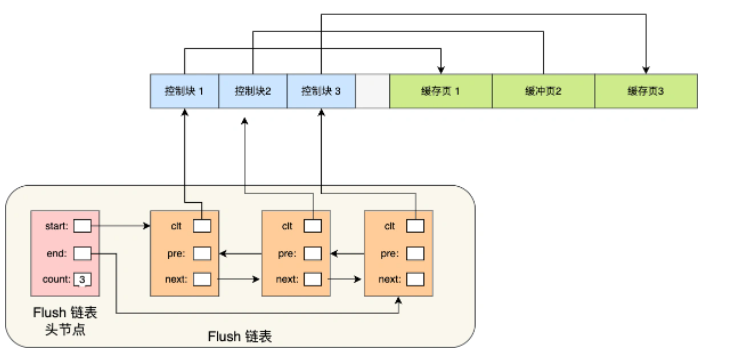
【如何提高缓存命中率?】
Buffer Pool的大小是优先的,对于一些频繁访问的数据我们希望可以一直留在Buffer Pool中,而一些很少访问的数据我们希望可以在某些实际淘汰掉,从而保证Buffer Pool不会因为满了而导致无法再缓存新的数据,同时还能保证常用数据留在Buffer Pool中。
LRU算法,最近最少访问(时间)
该算法的设计思路是,链表的头结点是最近使用的,链表的末尾节点是最久没使用的,那么当空间不够了就需要淘汰掉最久没使用过的节点,从而腾出空间。所以当访问的页在Buffer Pool中,就直接把该页的LRU链表节点移动到移动头部;当访问的页不存在Buffer Pool里,除了要把页放入到LRU链表的头部,还要淘汰链表LRU末尾的节点。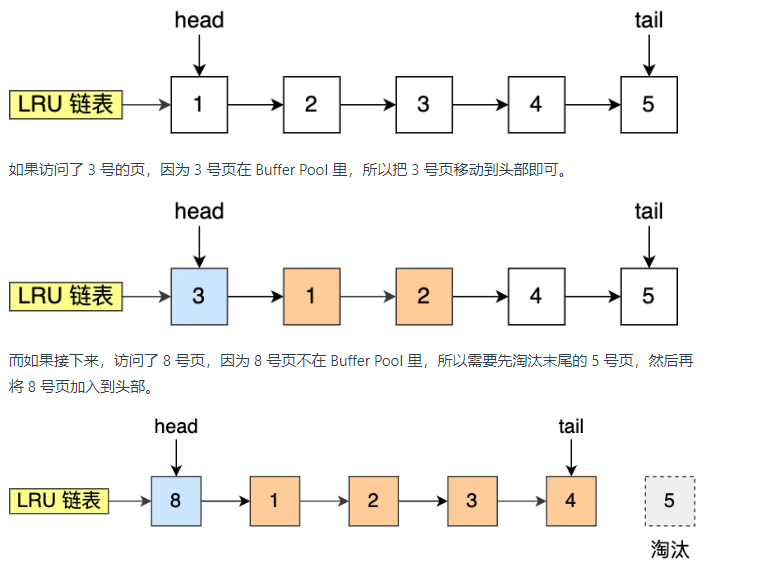
但是普通的LRU算法不能解决预读失效和Buffer Pool污染的问题。
预读失效:Mysql加载数据页的时候,会提前把它相邻的数据页一并加载进来,目的是为了减少磁盘IO。但是可能这些被提前加载进来的数据页,并没有被访问,相当于这个于都是白做了,这就是预读失效。如果使用简单的LRU算法,就会把预读页放入LRU链表头部,而当Buffer Pool空间不够的时候,还需要把末尾的页淘汰掉,但是这些预读页一直没有被访问,就会出现被访问的预读页占用了LRU链表前排的位置,而末尾淘汰的页可能是频繁访问的页,这样就大大降低了命中率。
Mysql是如何解决预读失效的?
Mysql改进了LRU算法,将LRU划分成两个区域:old区域和young区域。young区域在LRU链表的前半部分,old区域在后半部分。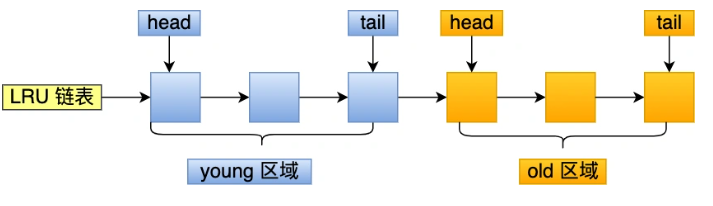
LRU链表中的young区域与old区域的比例是63:37。划分成这两个区域后,预读的页就只需要假如到old区域的头部,当页被真正访问的时候,才将页插入young区域的头部。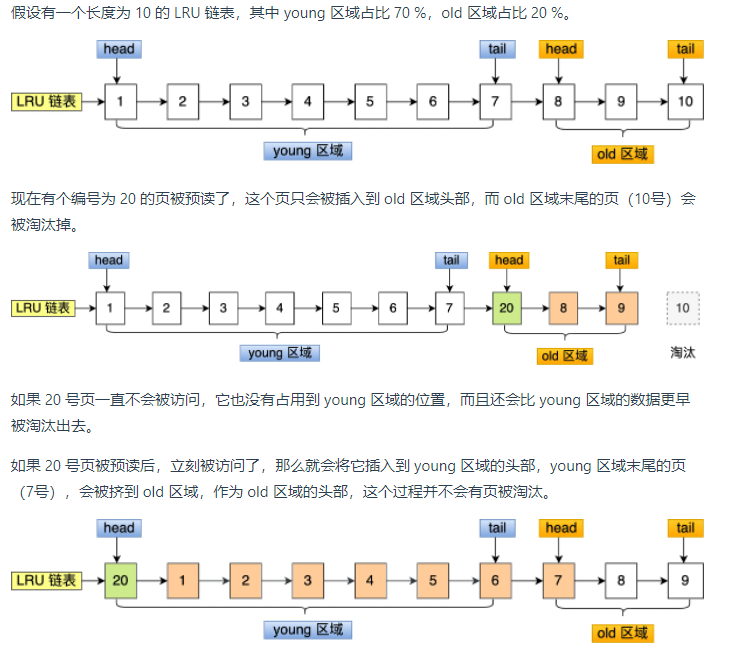
虽然划分old区域和young区域避免了预读失效带来的影响,但还有个问题无法解决,那就是Buffer Pool污染的问题。
【Buffer Pool污染】
当某一个sql语句扫描了大量的数据时,在Buffer Pool空间比较有限的情况下,可能会将Buffer Pool中的所有页都替换出去,导致大量的热数据被淘汰了,等到这些热数据又再次被访问的时候,由于缓存未命中,就会产生大量的磁盘IO,Mysql的性能就会急剧下降,这个过程就被称之为Buffer Pool污染。
select * from t_user where name like “%xiaolin%”;
例如上述语句查询出来的结果就只有几条记录,但是由于这条语句会导致索引失效,所以这个查询过程是全表扫描的,接下来会发生如下的过程:
(1)从磁盘读到的页加入到LRU的old区域头部;
(2)当从页里读取行记录时,也就是当页被访问的时候,就需要将该页放到young区域头部;
(3)接下来拿行记录的name字段和字符串xiaolin进行模糊匹配,如果符合条件,就加入到结果集里;
(4)如此往复,直到扫描完表的所有记录。
经过这一番折腾,原本young区域的热点数据都会被替换掉。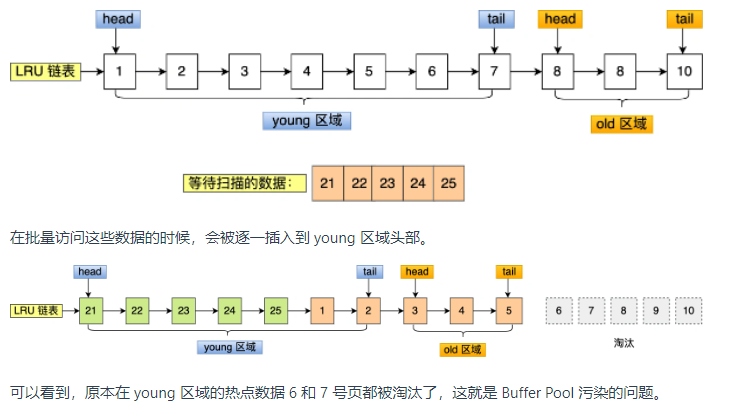
为了解决Buffer Pool污染的问题,Mysql是这样做的:在进入到young区域条件增加了一个停留在old区域的时间判断。
如果缓存页在old区域停留的时间超过了1s,就会被插入到young区域头部,如果没有超过1s,就不会插入到young区域头部。
【脏页什么时候被刷入磁盘?】
引入了Buffer Pool后,当修改数据时,首先修改Buffer Pool中数据所在的页,然后将其页设置为脏页,但是磁盘中还是原数据。因此,脏页需要被刷入磁盘,保证缓存和磁盘数据一直,但是如果每次修改数据都刷入磁盘,则性能会很差,因此一般都会在一定实际进行批量刷盘。
如果脏页还没来得及刷入磁盘,Mysql宕机了,会导致数据丢失吗?答案是不会,Innodb的更新操作采用的是WAL,先写日志,再写入磁盘,通过redo log日记让Mysql拥有崩溃恢复能力。
刷脏时机:
(1)当redo log日志写满了以后,会主动触发脏页刷新到磁盘中;
(2)Buffer Pool空间不足时,需要将一部分数据页淘汰掉,如果淘汰的是脏页,需要先将脏页同步到磁盘;
(3)Mysql认为空闲时,后台线程会定期将适量的脏页刷入磁盘;
(4)Mysql正常关闭之前,会把所有的脏页刷入到磁盘。
6.2说说什么是磁盘IO?
Mysql的Innodb存储引擎选择了B+树作为索引结构,这个与磁盘的特性有着非常大的关系。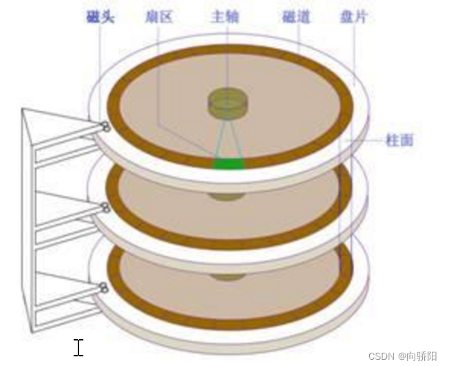
一个磁盘由大小相同且同轴的圆形盘片组成,磁盘可以旋转,各个盘面必须同轴同步转动。在磁盘的一侧有磁头支架,磁头支架固定了一组磁头,每个磁头负责存储一个磁盘的内容。磁头不能转动,能读取到磁盘的内容,依赖于磁盘的转动。可用柱面号、盘面号、扇区号来定位任意一个磁盘块。
读取一个块的内容:1.根据柱面号移动磁臂,让磁头指向指定柱面;2.所有磁头都定位到柱面号对应的磁道上,这时根据盘面号来确定具体磁道;3.磁盘旋转的过程中,指定的扇区会从磁头下面划过,这样就完成了对指定扇区的读写。
磁盘读取是机械运动,分为寻道时间、旋转延迟、传输时间三个部分,这三个部分耗时相加就是一次磁盘IO的时间,一般大概9ms左右。
(1)寻道时间:将读写磁头移动到正确的磁道上需要的时间,这部分时间代价最高;
(2)旋转延迟时间:磁盘旋转将目标扇区移动到读写磁盘下方所需的时间,取决于磁盘转速;
(3)数据传输时间:完成数据传输所需要的时间,纳秒级别,远小于前两部分;
磁盘顺序读写的效率很高,不需要寻道时间,只需很少的旋转时间;一般来说磁盘的顺序读的效率是随机读的40-400倍,顺序写是随机写是10-100倍。

若有收获,就点个赞吧
0 人点赞
