1.1说说MongbDB的业务应用场景
MongbDB是一个介于关系型数据库与非关系型数据库中间的产品,它是一个基于分布式文件存储的数据库,旨在为Web应用提供高性能、高可扩展的数据存储解决方案(相比于Mysql,表的结构在初始化时已经固定,列字段已经固定,而mongbDB的可扩展性更高)。MongbDB将数据存储为一个文档,数据结构由键值对(key、value)组成,mongoDB的文档类似于json对象,字段值可以包含其他文档、数组及文档数组。在高负载的情况下,可以添加更多的节点,保证服务器性能。
MongoDB的最小存储单位就是文档(document)对象,文档对象对应于关系型数据库中的行,数据在MongoDB中以BSON(Binary-json)格式存储在磁盘上。
Bson是一种类json的一种二进制形式的存储格式,bson和json一样,支持内嵌的文档对象和数组对象。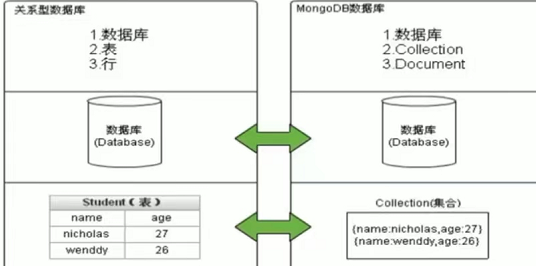
具体的应用场景:
(1)社交场景,使用MongoDB存储用户信息,以及用户发表的朋友圈信息、地理位置信息等等。
(2)物流场景:使用MongbDB存储订单信息,订单状态在运送过程中会不断更新,以MongoDB内嵌数组的形式来存储,一次查询就能将订单所有的变更读取出来。
(3)物联网场景:使用MongoDB存储所有接入的智能设备信息,以及设备汇报的日志信息,并对这些信息进行多维度的分析。
(4)视频直播场景:使用MongbDB存储用户信息、点赞互动信息等。
这些业务场景,数据操作方面的共同特点是:
(1)数据量大;
(2)写入操作频繁,或者读写操作都很频繁;
(3)价值较低的数据,对事务性要求不高;
什么时候选择MongoDB?
(1)除了以上三个特点以外,还需要应用不需要事务以及联表查询;
(2)应用的需求会发生变更,具有不确定性,数据库的模型无法确定且具有快速迭代的场景;
(3)应用需要TB甚至PB级别的数据存储;
(4)应用发展迅速,需要能快速地水平扩展;
(5)应用要求存储的数据不丢失;
(6)应用需求99.9999%的高可用;
(7)应用需要大量的地理位置查询、文本查询;
MongoDB的特点:
(1)高性能:
MongoDB提供高性能的数据持久化。特别是对嵌入式数据模型的支持减少了数据库系统上的IO活动。索引支持更快的查询,并且可以包含来自嵌入式文档和数组的键。(文本索引解决搜索的需求、TTL索引解决历史数据过期的需求、地址位置索引可用于构建各种O2O应用)、GridFS解决文件存储的需求。
(2)高可用:
MongoDB的复制工具称为副本集(replica set),它可以提供自动故障转移和数据冗余。
(3)高可扩展:
MongoDB提供了水平可扩展作为其核心功能的一部分。
分片将数据分布在一组集群的服务器上,支持海量数据存储、业务水平扩展。
从3.4开始,MongoDB支持基于片键创建数据区。在一个平衡的集群中,MongoDB将一个区域所覆盖的读写只定向到该区域内的那些片。
(4)丰富的查询类型:
支持CRUD,数据聚合、文本搜索、地理空间查询等。
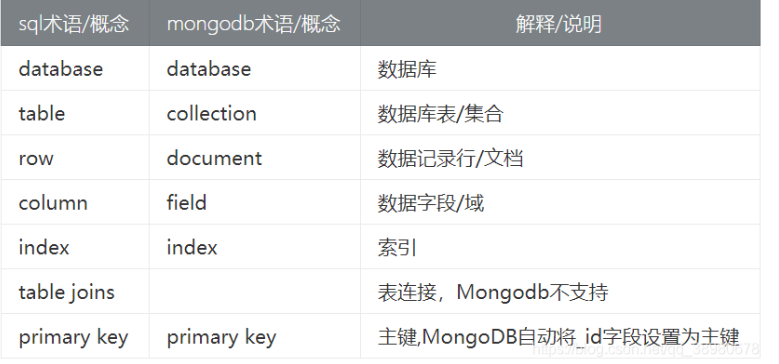
1.2说说MongoDB为什么使用B树作为数据记录的存储结构?
B树与B+树的区别
(1)B树的非叶子节点和叶子节点都存储了真实的数据记录,而B+树的非叶子节点不存储真实的数据记录,只存储索引值。B树相比于B+树来说没有那么矮胖。
(2)B+树的父节点中的索引值在子节点中都存储了一份冗余,这样在范围查询时,B+树的效率是比B树要快不少的。因为B+树的叶子节点之间还通过了双向链表进行组织,可以直接通过指针访问下一叶子节点。而B树在做范围查询时需要通过中序遍历的方式来进行,所以不可避免得回在子节点、父节点中来回切换。
MongoDB之所以使用B树作为存储结构是因为MongoDB认为单个数据记录的查询比遍历数据查询更加常见,因为B树的非叶子节点也存储了真实的数据记录,所以数据如果在非叶子节点命中的话就可以直接返回而不需要访问叶子节点了。所以查询单条数据记录的平均IO次数是比B+树少点的。应用场景永远都是系统设计时需要优先考虑的问题,作为NoSQL的MongoDB,它的应用场景与传统的关系型数据库还是有所分别的。MongoDB作为面向文档的数据库,它更看重以文档为中心的组织方式,所以选择了查询单个文档性能较好的B树。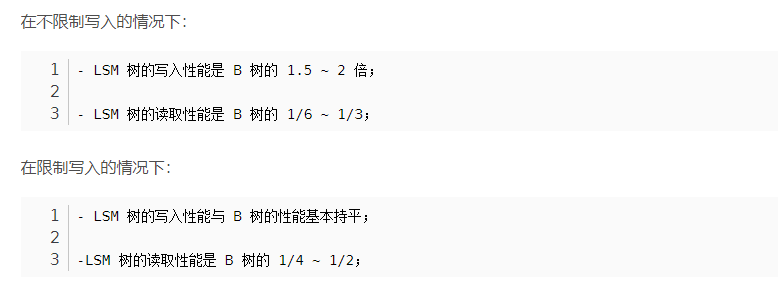
1.3说说GridFS
GridFS是一种将大型文件存储在MongoDB的文件规范;GridFS用于更好得存取大于16M的文件;它存储在MongoDB的集合中。
【工作原理】:
在GridFS存储文件是将文件分块存储,文件会按照256KB的大小分割成多个块进行存储,GridFS使用两个集合存储文件,一个集合是chunks,用于存储文件块的二进制数据;一个集合是files,用于存储文件的元数据信息(文件名称、块大小、上传时间等信息)。
chunks:集合中的每个文档代表一个独立的文件块。用_id来标识块的唯一ObjectID;files_id标识这属于哪个文件下的块;n标识块的序列号,从0开始进行编号;data就是当前块的二进制数据。
从GridFS中读取文件要对文件的各个块进行组装、合并。可以对GridFS存储的文件进行范围查询,也可以从文件的任意部分访问信息,比如跳到视频或者音频的中间部分。

若有收获,就点个赞吧
0 人点赞
