本文为翻译稿,原文引用自:
https://jalammar.github.io/how-gpt3-works-visualizations-animations/
科技界对GPT3的炒作甚嚣尘上。像GPT3这样的大型语言模型开始让我们感到惊讶。虽然这些模型尚未完全适用于大部分企业与客户的交流,但它们的聪明才智无疑将加速自动化的步伐和智能计算系统的可能性。让我们揭开GPT3的神秘面纱,了解它是如何被训练和工作的。
训练过的语言模型生成文本
我们可以选择性地传入一些文本作为输入,这会影响其输出。
输出是模型在训练期间从大量文本中“学习”得来的。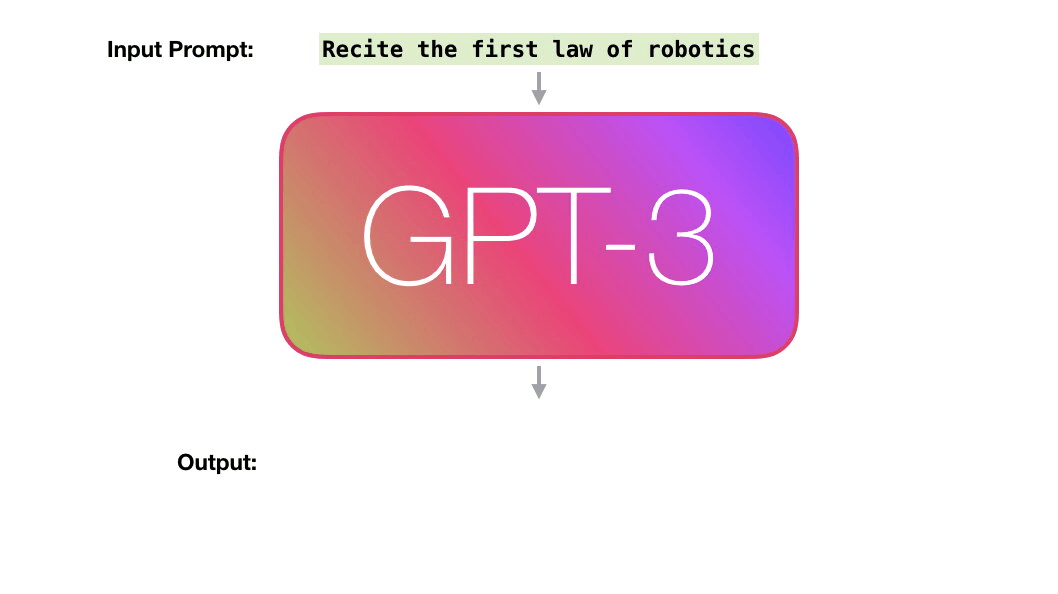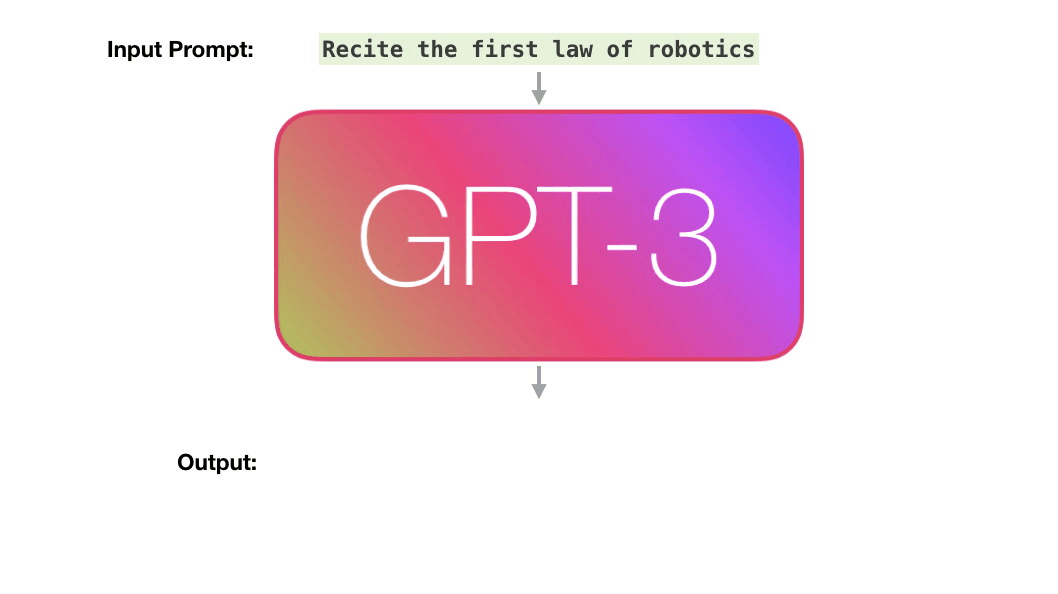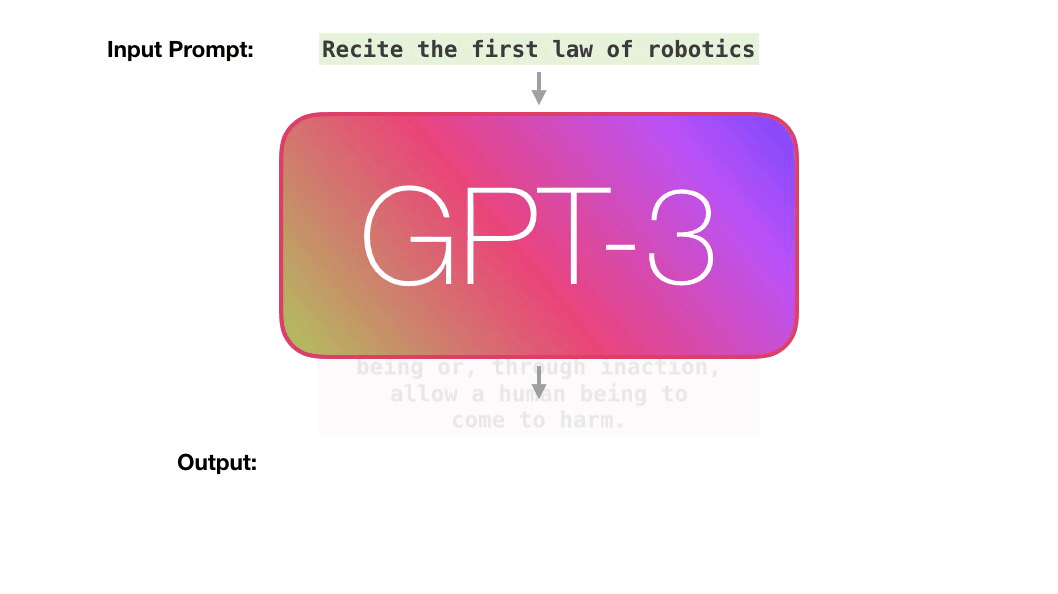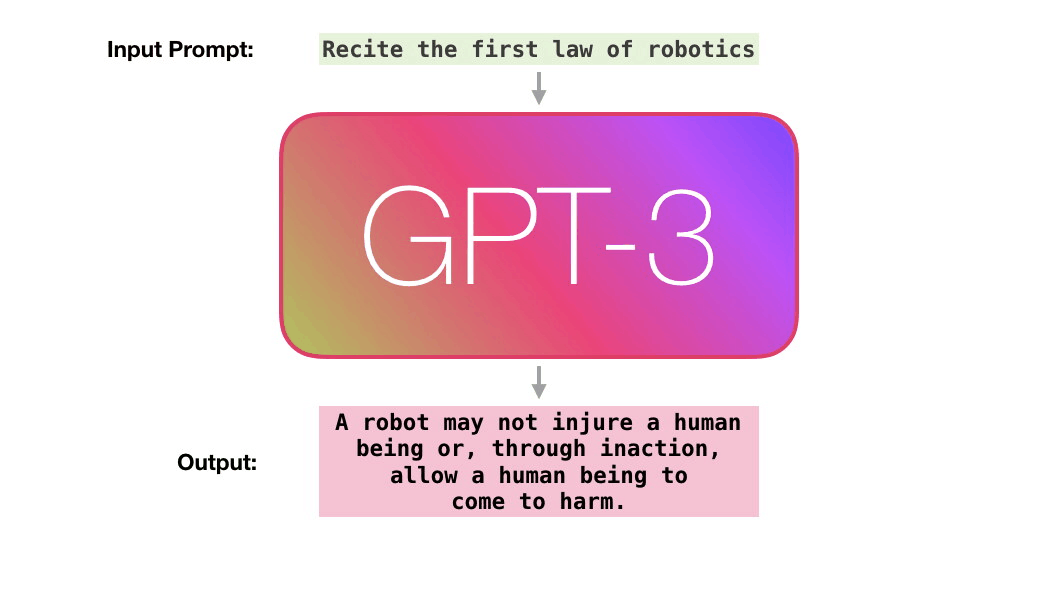
训练是向模型展示大量文本的过程。这个过程已经完成了。你现在看到的所有实验都来自那个已经训练好的模型。估计这个过程耗费了355 GPU年,并且花费了460万美元。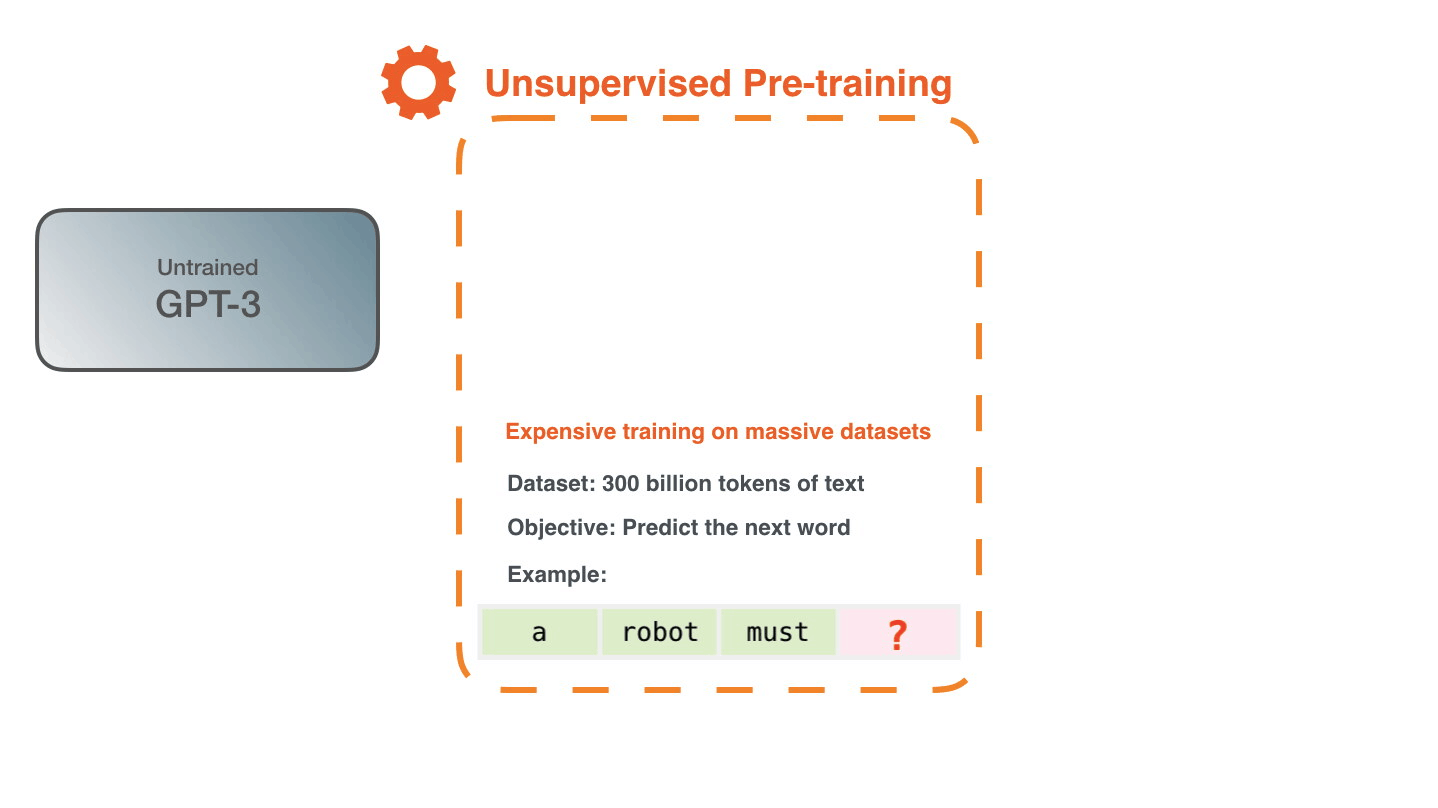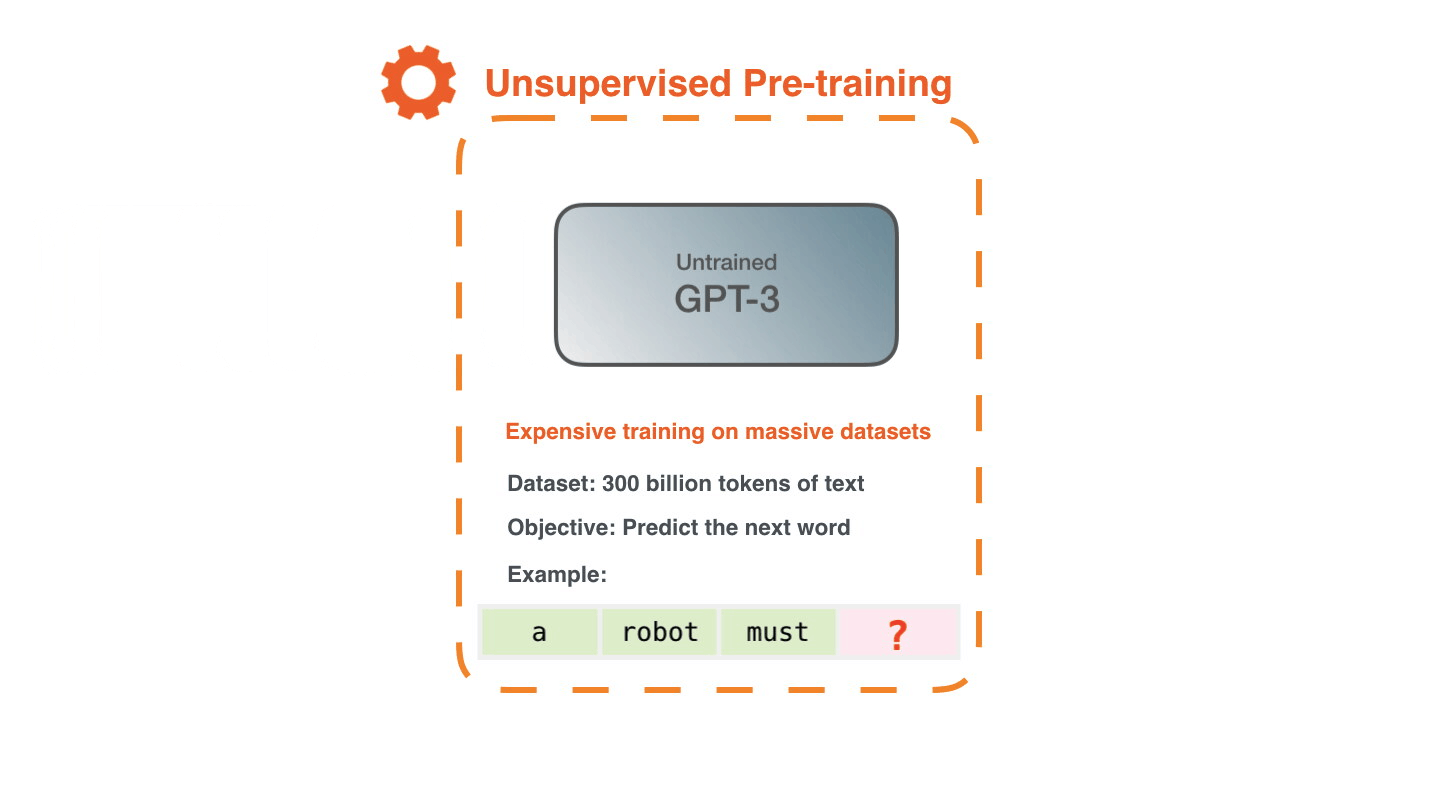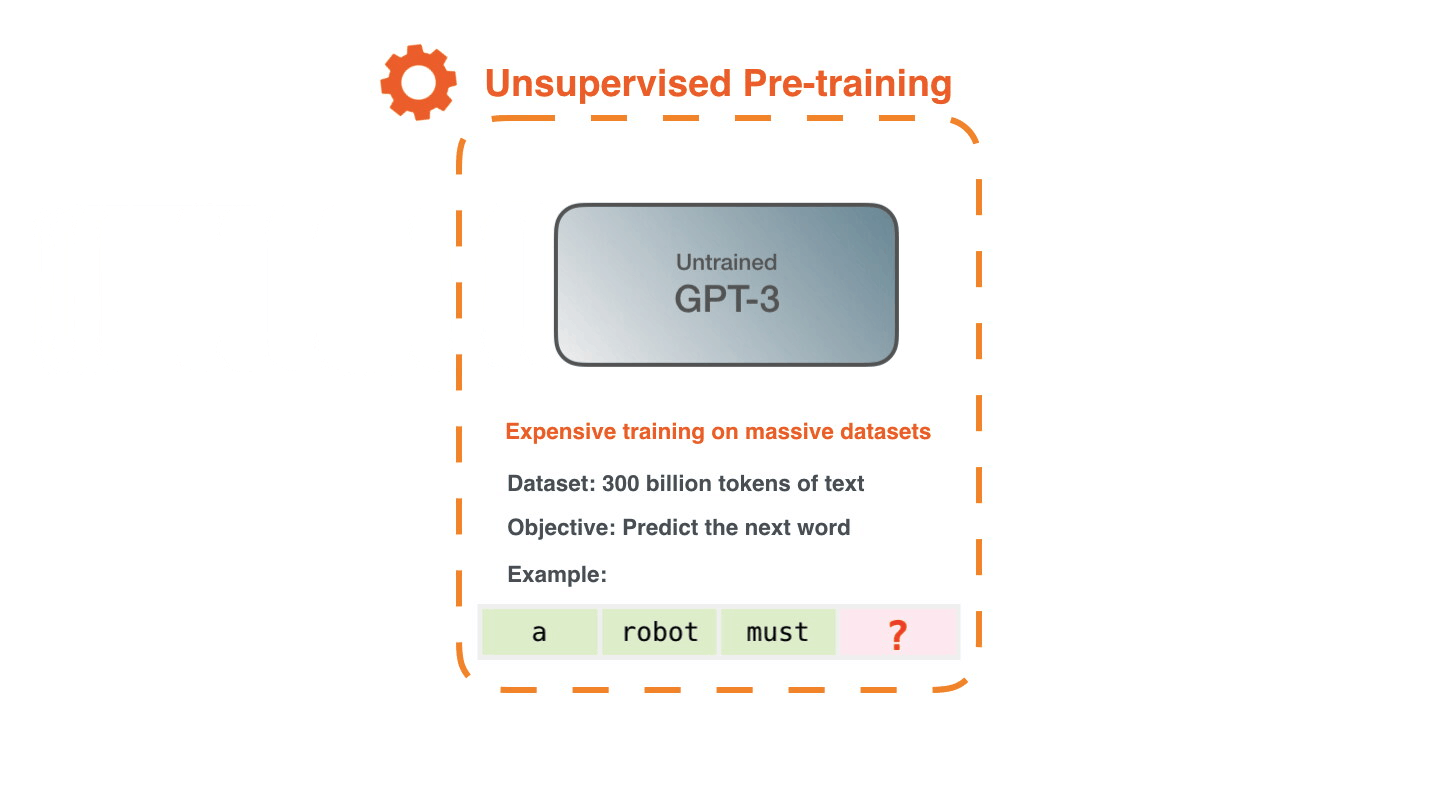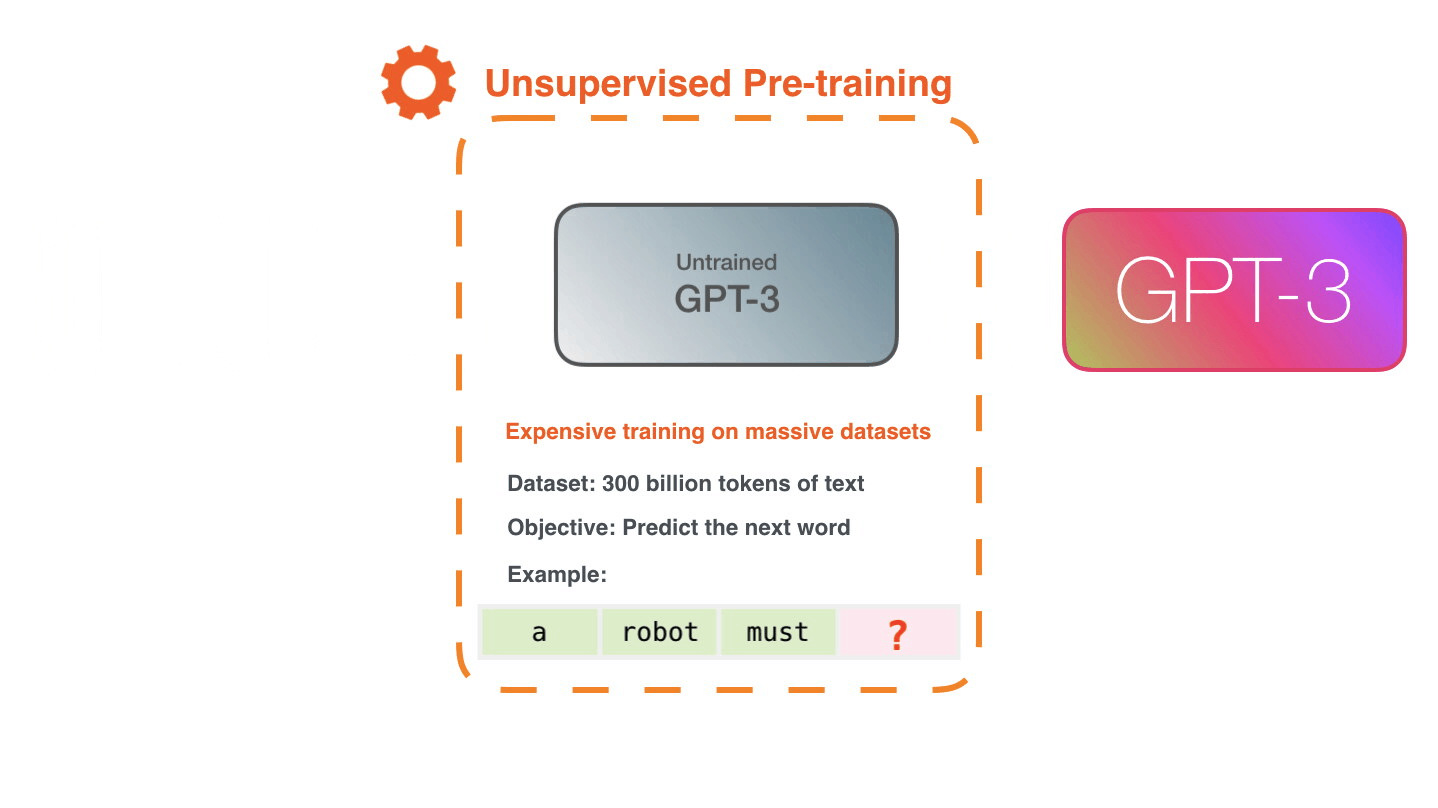
用于为模型生成训练示例的数据集包含3000亿个文本标记。例如,这是从顶部的一句话生成的三个训练示例。
你可以看到如何在所有文本中滑动窗口并生成大量的例子。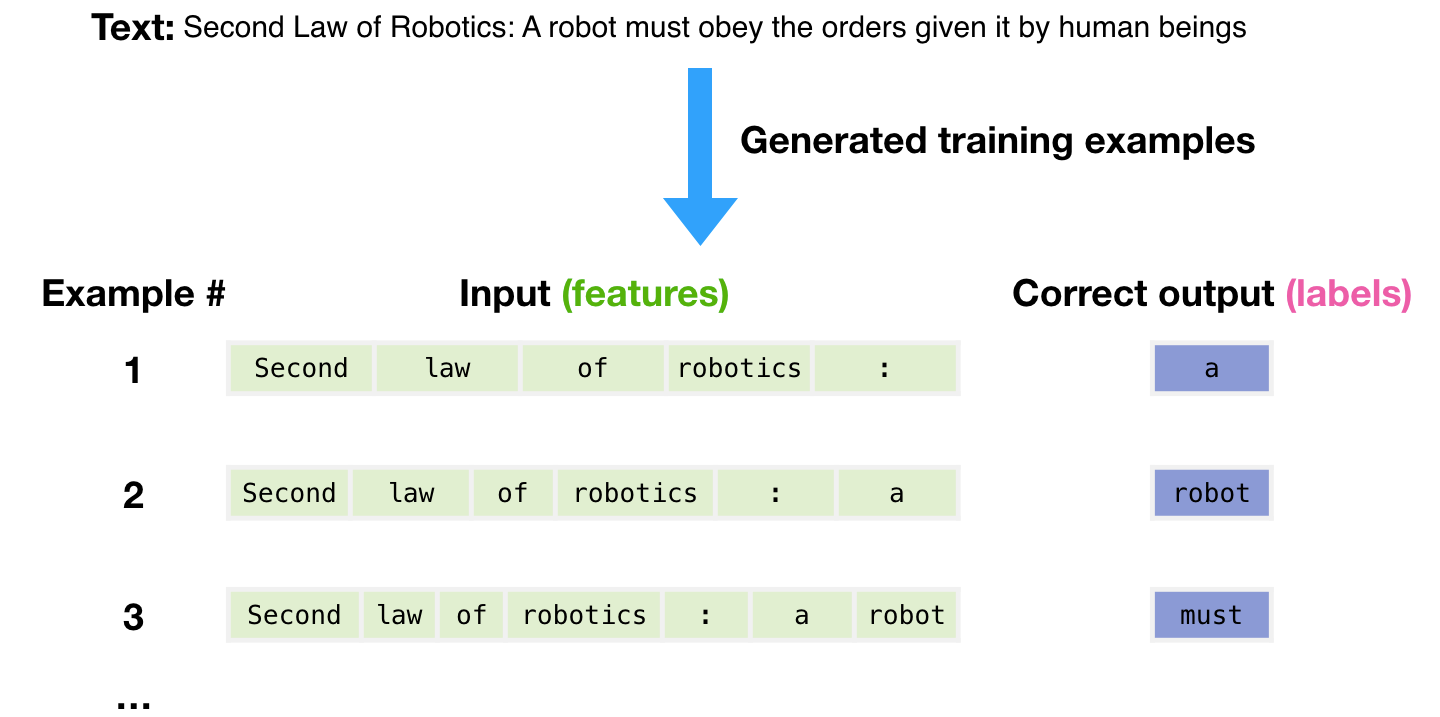
我们向模型提供一个例子。我们只展示特征,让它预测下一个词。
模型的预测会出错。我们计算预测的误差并更新模型,使得下次它能做出更好的预测。
重复这个过程数百万次
现在,让我们更详细地看看这些步骤。
GPT3实际上是一次生成一个标记的输出(我们现在假设一个标记就是一个词)。
请注意:这是对GPT-3如何工作的描述,而不是讨论它的新颖之处(主要是规模大得离谱)。它的架构是一个基于此论文https://arxiv.org/pdf/1801.10198.pdf 的transformer解码器模型。
GPT3是巨大的。它将它从训练中学习到的东西编码为1750亿个数字(称为参数)。这些数字被用来计算在每次运行时生成哪种标记。
未训练的模型开始时参数是随机的。训练找到那些能够导致更好预测的值。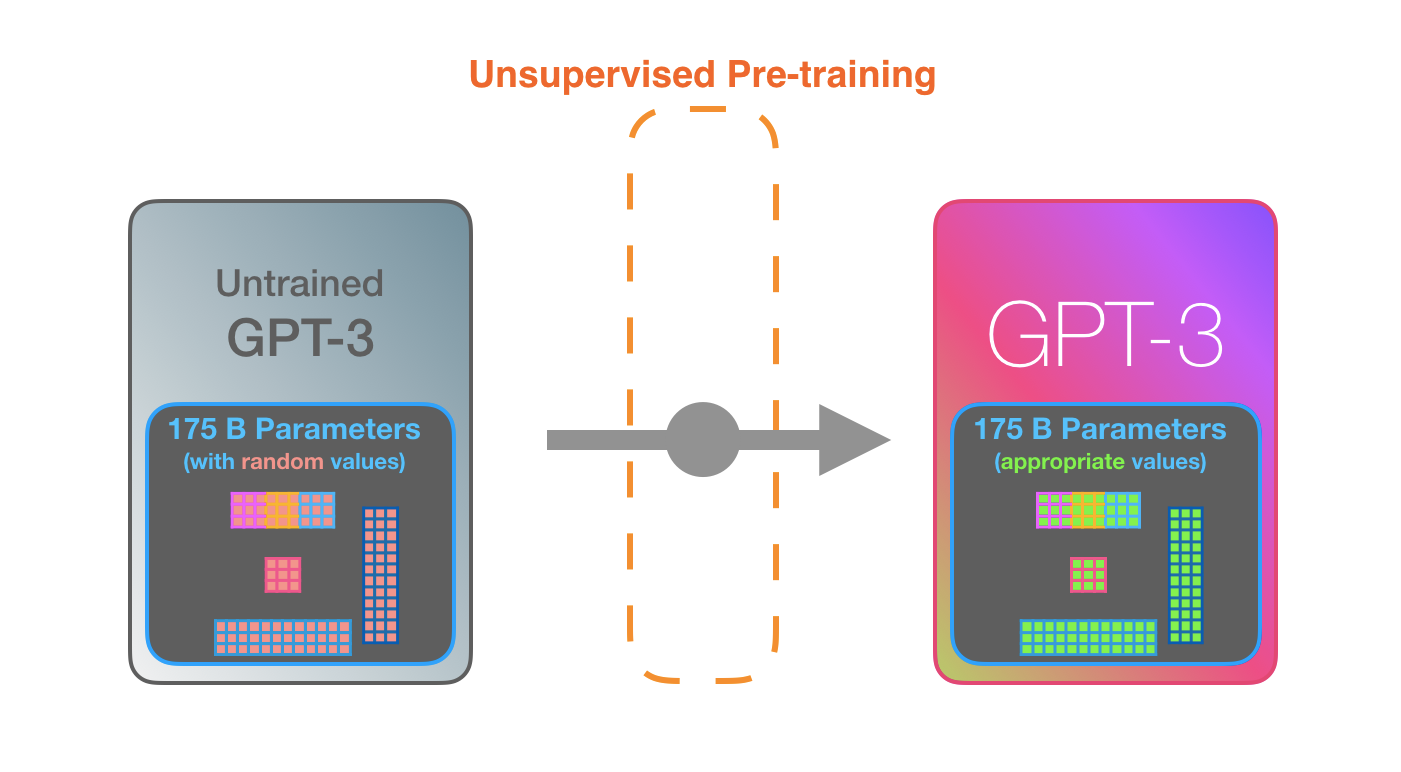 这些数字是模型内部数百个矩阵的一部分。预测主要是大量的矩阵乘法。
这些数字是模型内部数百个矩阵的一部分。预测主要是大量的矩阵乘法。
在我的YouTube上,我展示了一个只有一个参数的简单ML模型。这是解开这个175B怪胎的一个好的开始。
为了揭示这些参数如何分布和使用,我们需要打开模型并看看里面。
GPT3的有2048个标记。这是它的“上下文窗口”。这意味着它有2048个轨道,沿着这些轨道处理标记。
让我们沿着紫色的轨道。一个系统如何处理 “机器人 “这个词并产生 “A”?
高级步骤:
1.将单词转换为代表该词的向量(数字列表)
2.计算预测
3.将得到的向量转换为词
GPT3的重要计算在其96层的transformer解码器层堆栈内部进行。
看到这些层了吗?这就是“深度学习”中的“深度”。
每一层都有自己的18亿参数来进行计算。这就是“魔法”发生的地方。这是那个过程的高级视图:
GPT3与GPT2的不同之处在于它交替使用密集和稀疏的自注意力层。
这是GPT3中的输入和响应(“好的,人类”)的X光图。注意每个标记如何流过整个层堆栈。我们不关心第一个词的输出。当输入完成时,我们开始关心输出。我们将每个词反馈到模型中。

在React代码生成的例子中,描述应该是输入提示(绿色),另外还有一些描述=>代码的例子,我认为。然后像这里的粉红色标记一样,一次生成一个标记的react代码。
我的假设是,引导示例和描述被追加为输入,具有特定的标记来分隔示例和结果。然后将其输入到模型中。
这种工作方式让人印象深刻。因为你只需要等待GPT3的微调出现。其可能性将更为惊人。
微调实际上会更新模型的权重,使模型在某项任务上表现得更好。

若有收获,就点个赞吧
0 人点赞
