1、StableDiffusion的优势在哪儿?
既然点进了这个课程,那么我默认你大概知道StableDiffusion是一款AI绘画的应用。
市面上其实有很多可以被用于AI绘画的应用,例如DALL-E、Midjourney、NovelAI等。但他们中的大部分都依托云端服务器运行,一部分还需要支付会员费,用来购买更多出图的额度。
但StableDiffusion在其中独树一帜。它通过算法迭代,将AI绘画的精细度提升到了一个新的高度,并且能够在极短的时间内完成产出。与其他应用不同的是,StableDiffusion不需要依托云端服务器运行,也不需要支付会员费用来购买更多的出图额度。这使得StableDiffusion成为了一个非常适合个人用户的AI绘画应用。
StableDiffusion可以在任何一台搭载“民用级”显卡的电脑上运行,它的功能也非常强大。通过使用诸如LoRA、Controlnet等衍生功能,StableDiffusion可以实现精准控制美术风格、角色、细节、姿势、动作等,让用户可以轻松地绘制出各种风格的作品,比如动漫风、插画、立绘国风、水墨、3D建模,甚至是照片级的拟真图像。
除了以上介绍的特点以外,StableDiffusion还有一个非常重要的因素,那就是它是全面开源的。这意味着你可以在自己的电脑上部署整个程序并使用它,而且出图作画是完全免费而且不限量的。现在市面上大多数商业级的AI绘画应用都是基于StableDiffusion开发的,因此如果你能掌握它的根本逻辑,就能得心应手地使用任何一款门槛比它更低的工具。
2、StableDiffusion的入门要求
尽管StableDiffusion非常亲民,但它还是一定的配置要求。首先它能在搭载Linux、Windows、Mac等系统的电脑上运行,但我强烈推荐你在Windows系统的电脑使用它,原因我会在接下来讲述。同时在这个系列课里,我也都会在Windows系统上进行教学操作。
其次,它需要一张性能足够强大的独立显卡提供算力进行绘制。虽然理论上任何一个品牌的显卡都能提供他需要的算力。根据大部分使用者的交流经验,N卡表现是最出色且稳定,其中还有开发者为N卡的cuda模块单独优化了AI绘图,并有类似于xFormers等能加快出图速度的框架。这也是我推荐你使用Windows的原因,因为现在大部分的Mac电脑用的都是M系列芯片,已经没有搭载独立显卡了。
要简单判断的话,如果你有一台可以畅玩近两年内的主流3A游戏大作的电脑,应该都是可以跑得动AI绘画程序的。但你肯定也知道,跑得动和玩的爽是两个不同的概念。
不同级别的显卡在算力大小上的差异会极大的影响你做AI绘画时出图的效率。根据一些统计数据和个人分享,建议你使用性能在RTX2060以上的显卡,我自己使用的显卡是3060 12G,绘制一张分辨率512乘512的图像,只需要20秒左右。
如果你的显卡性能较为不足,我其实并不推荐你在这个阶段进行学习。因为想要靠AI绘画产出一张满意的图像,需要反复的尝试和调教。如果出图效率不高,你会把许多时间花费在漫长的等待中,并且面临是不是当机的风险,就会极快的消磨掉你的兴趣和热情。
另外,影响AI绘画的另一个比较重要的因素是显存。显存主要影响的是你可以绘制的图像分辨率大小。简单说,如果你的显存不够大,可能就做不出太过于清晰的图像来。
另外在训练模型时,显存也会影响可以同时进行的训练规模。虽然它属于比较进阶的内容,但如果你想要日后能够比较舒服的进行一些你自己的模型训练工作,显存最好大于8GB。
3、StableDiffusion的下载和安装
那么去哪里下载StableDiffusion这个软件呢?和大部分生产力工具不一样的一点是,StableDiffusion 并不是一个真正的软件。最早它被开源出来的只是一款像我这样的外行人都看不太懂的源代码而已。但得益于强大的开源社区,它的可操作性也在过去的小半年里得到了飞速进化。
这里就不得不提到GitHub上面一位叫做automatic1111的开发者,他将这些代码做了一个基于浏览器网页去运行的小程序。就是我们常说的StableDiffusion webUI了。它集成了许多在代码层面非常繁琐的功能,并将里面的各项参数的条件转化成了非常直观的选项数值与滑块。
但由于webui的配置部署对一般小白来说相对较麻烦,我在这里推荐国内许多走在前面的大佬他们发布的一键整合和安装包。当然如果你对自己从头到尾部署一个StableDiffusion WebUI的过程感兴趣,那么我会在之后的课程中以附录的形式对此进行教学。
第一节附录1 分享搭建Stable Diffusion的几种方法
这里以B站大神 秋葉aaaki 的安装包为例子,让我们在自己的本地部署一个StableDiffusion。下载链接如下:
:::tips
链接: https://pan.baidu.com/s/1OlYzl-UfS75FM8WJKv0J4g?pwd=1111 提取码: 1111
:::
下载整合包后,我们将整合包主体解压到本地剩余空间较大的盘中(请注意,因为后期在出图的过程中,我们会下载很多StableDiffusion所使用的模型,所以你的硬盘占用将会极大)。
安装过程中有几个注意点:
1、解压路径尽量不要有中文。
解压路径,即你放置StableDiffusion WebUI的文件夹及它所属的文件夹,任何一层文件夹里有中文都会导致一些路径索引的过程报错。比如:D:/Program&Files/AI绘画。为减小错误发生概率,也应该尽可能减少输入空格。
2、WebUI应放在较空的盘。
AI绘画需要下载并运用大量模型文件,模型数量多了以后是很占地方的,尽量不要将其堆积在C盘之类的系统盘。文件夹是可以自由拷贝的,不影响使用。
解压完成后,我们直接打开文件夹,双击启动器:
整合包会配置好一切更新和内容,直接点击一键启动,等待片刻,浏览器自动弹出,我们就成功进入到WebUI的界面了。
在启动过程中,你可能会注意到,一个黑色的命令提示行框体会弹出,加载所需的各种文件。在加载的过程中,我们会注意到命令行有闪过如下一串命令: :::tips Running on local URL: http://127.0.0.1:7860 :::
这个是你的WebUI的本地服务器地址,在之后你不小心关掉了浏览器,可以通过[http://127.0.0.1:7860](http://127.0.0.1:7860)重新进入WebUI界面。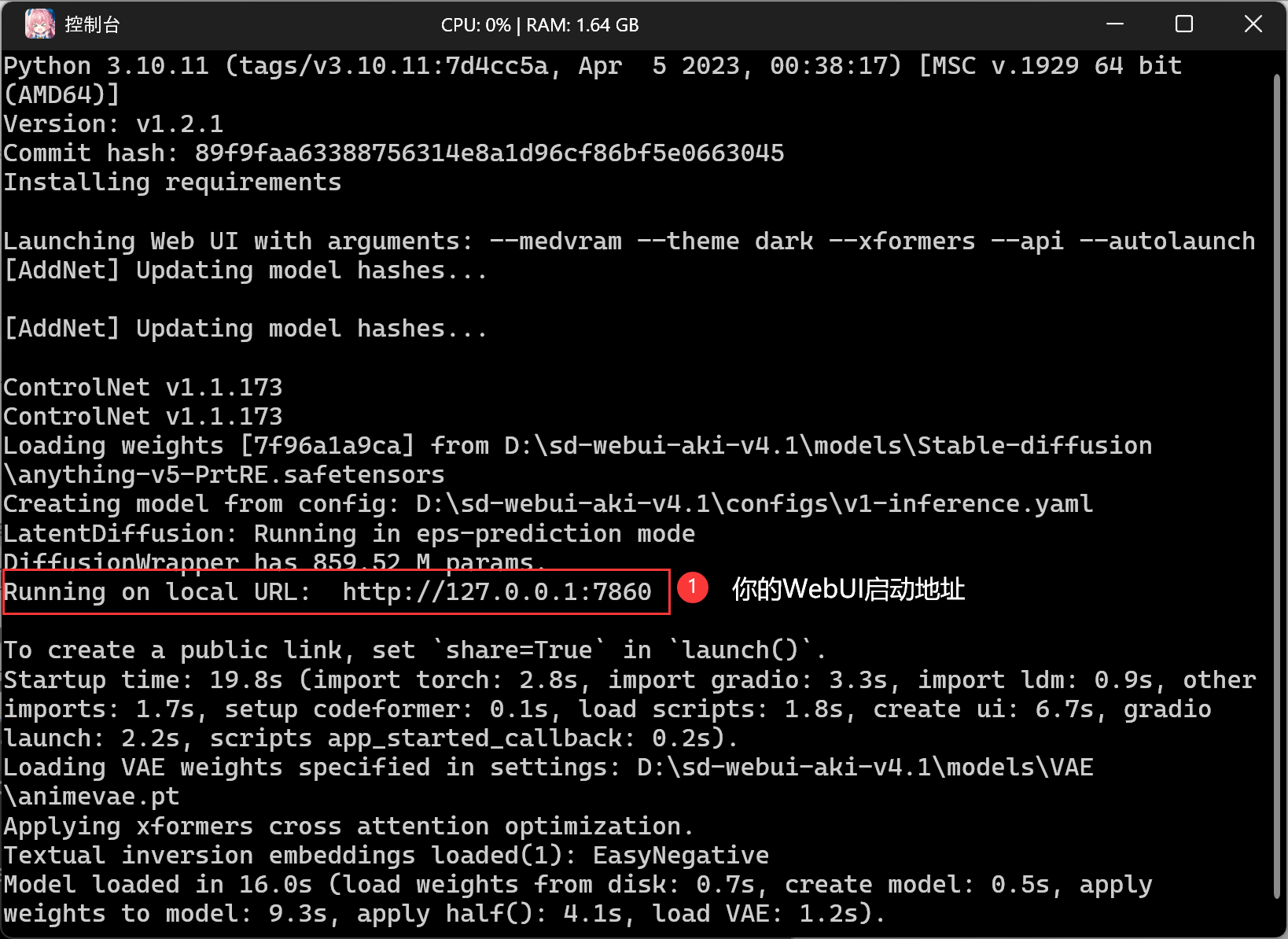
之后,每次开启程序都是重复如上的这个过程。要注意,浏览器里面的这个WebUI只是一个操作界面,而命令行里面这些东西才是你的程序本体进行绘画的进程,你需要保持它的开启结束后再关闭运行。
StableDiffusion需要占用你系统一定的GPU性能与显存,所以请尽可能关闭一些无关软件,尤其是对显卡消耗比较大的。
4、第一次出图
现在我们进入实操环节,当你在浏览器里打开了这个web UI以后,就可以利用它开始作画了。
我们来了解一下这个WebUI的界面: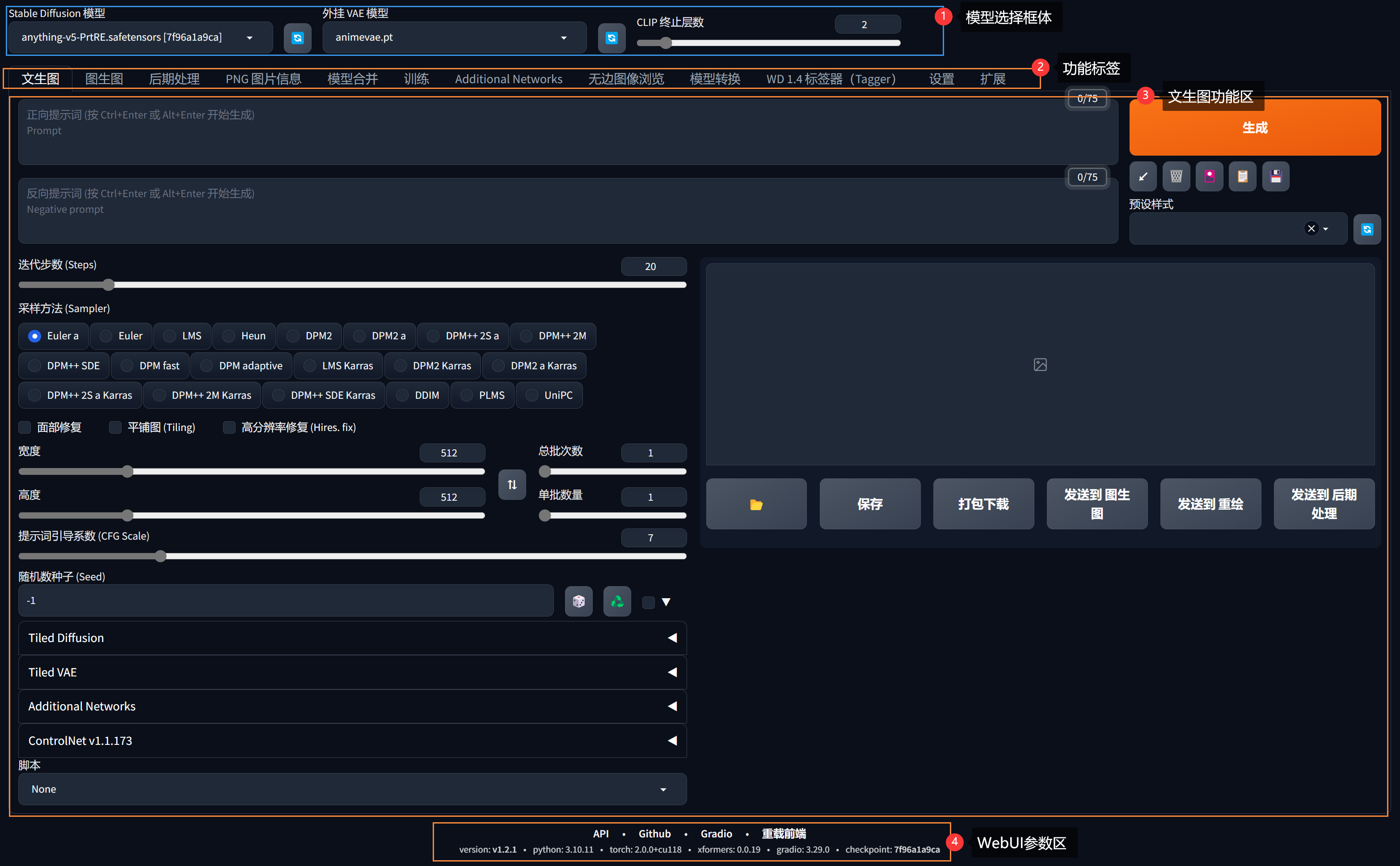
从上图我们来了解一下这个WebUI的界面。上面一整排标签栏对应了webUI的不同功能。我们作图最常用的是前两个文生图与图生图,它代表的是两种进行绘制的基本方式。我们会在接下来的课程中分别展开分析。而第三个后期处理的标签更多主要用于对图片进行AI放大处理。它可以让你生成更清晰的大图。
因为WebUI是浏览器里的界面,所以你可以使用一些上网时的常用手段,让它变得易于操作。例如使用ctrl加滚轮进行大小比例缩放,按F11选屏或者右上角调小窗,就这样很机械的去介绍。
可能过不了多久你就会开始打瞌睡了,不如让我们动手做一张图,做完了你就知道他大概是怎么一回事了。
请查看一下你的界面,左上角这里有一个选择,StableDiffusion模型的选择。
科普一下和模型有关的基础概念。我们刚刚安装的这个Web UI其实只是一个执行的程序,但AI是从哪里学会各种不同的绘画风格的呢?他阅篇无数的经验就来自于使用图片素材训练出来的模型,不同的模型可以给你的作品带来完全不同的画面内容和画风。我们会在之后的课程里对模型的概念做进一步科普。秋叶的安装包里内置了万象熔炉丨AnythingV5的模型,是一个极受欢迎的二次元动漫画风模型。接下来的课程里,我也会向你系统的介绍一些获取模型的方式。而当你的技巧足够成熟以后,还可以尝试自己训练一些符合你需要的模型出来。
选择完模型后,我们打开文生图标签页,所谓的文生图就是指你输入一串文字,它能按照你的文字描述给你生成一幅图片出来。这些被我们输入进去的描述文字就是prompt提示词(这和我们之前教授过的Midjourney一致)。
你可以用自然的语言尝试着描述一画面出来。例如一个女生在草原上行走,月光洒落在她的身上,但注意:提示词不认中文。
这个时候你可以打开任意一个翻译软件,把你刚刚描述下来的话语,翻译成英文,然后复制粘贴到这个提示词框里。
但只有这个还不够。为了让AI能够更准确的读懂我们的意图,同时更充分的施展自己的能力。我们要在后面加串更长的魔咒,你可以尝试着将我提供给你的这一段词语复制粘贴加在刚刚那句描述的话语后面。
:::tips
(masterpiece:1,2), best quality,masterpiece, highres, original, extremelydetailed walpaper, perfectlighting,(extremely detailed CG:1.2)drawing, paintbrush,
:::

提示词框分成两部分,一部分是正向提示词,一部分是反向提示词,分别用来控制你想要在画面里出现的和想要排除在外的内容。针对下面的反向提示词,我也有一段咒语是提供给你使用的,把它复制进去,可以避免你的画面出现一些问题。我会在接下去的课程中细致的讲解这些所谓咒语的含义和里面各种花里胡哨的括号数字的作用。
:::tips
NSFW,(worst quality, low quality, blurry:1.66), (bad hand:1.4), watermark, (greyscale:0.88), multiple limbs, (deformed fingers, bad fingers:1.2), (ugly:1.3), monochrome, horror, geometry, bad anatomy, bad limbs, (Blurry pupil), (bad shading), error, bad composition, Extra fingers, strange fingers, Extra ears, extra leg, bad leg, disability, Blurry eyes, bad eyes, Twisted body, confusion, (bad legs:1.3)
:::

光有提示词还不够,你还需要通过下面这个区域里面的一系列参数来定义图片的尺寸、规格和生成方式。这同样也是接下来的课程中我要讲述的内容。这里你可以先参考我的做法来进行设定。这一组参数会为你生成一张16比9尺寸的横屏壁纸。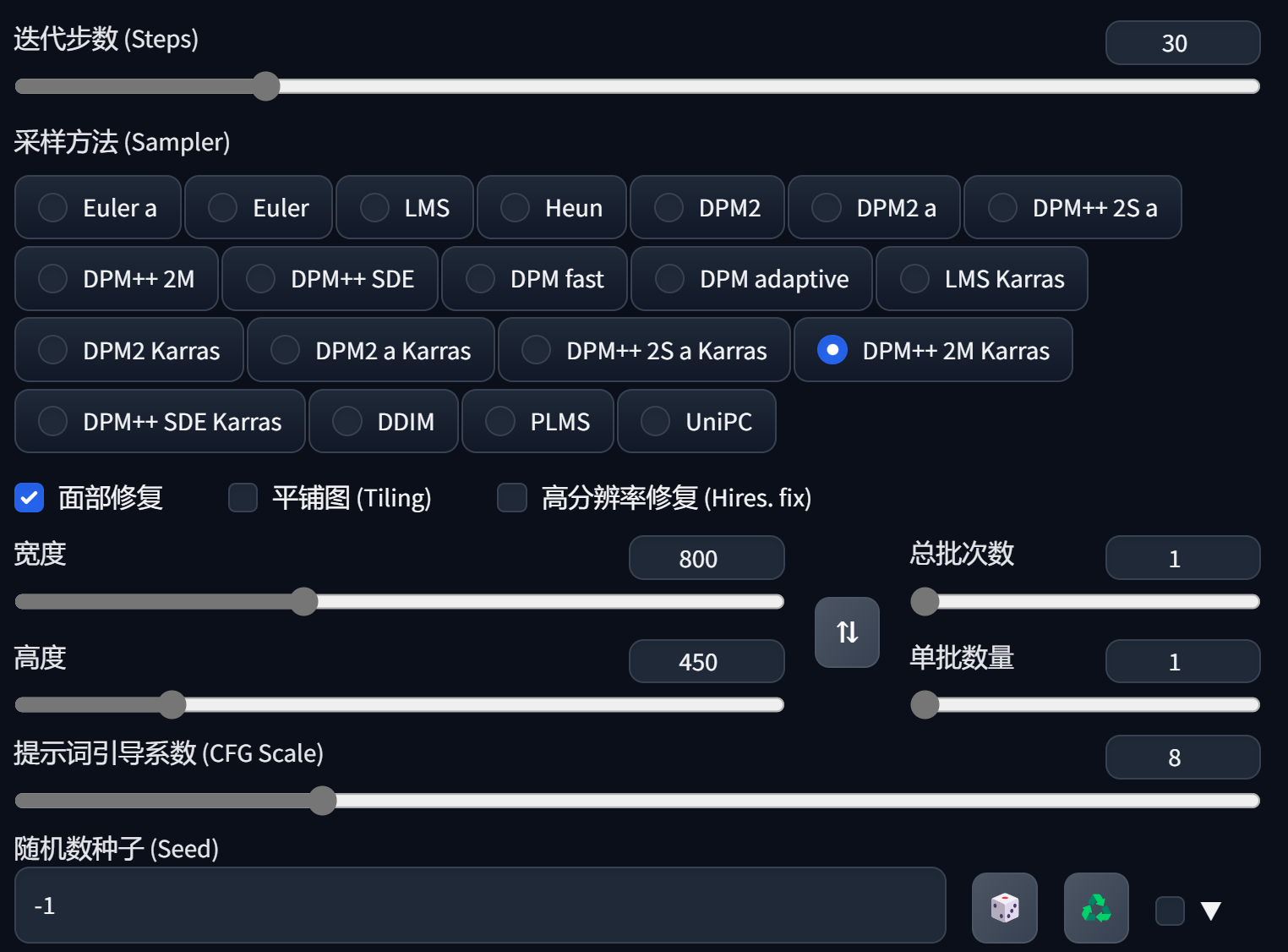
设定完毕,点击右上角的生成,然后静待程序加载片刻之后,你就得到了一张女孩在草原行走的风景图了。这就是你用AI画出的第一幅作品了,对他的效果你满意吗?女孩为什么是背对着我们的呢?这个时候你可以把自己想象成一位无情的甲方,向AI沟通你的需求和需要改进的地方。你对AI说的话,其实就是提示词。如果他没能达到你要的效果,就再对他多逼逼几句补充说明到位就好。
我们在正面提示词的后面添加一个英文的半角逗号,用来分割不同的提示词。
随后我们打三个词进去。第一个looking at viewer,意思是看向镜头,第二个close up,意思是特写近距离,第三个upper body。意思是上半身,每打完一个提示词组,记得都用一个英文逗号和空格将它们间隔开,再点一下生成。看这下它离你的距离不就更近了吗?

希望这个小小的案例可以帮助你充分体会到AI绘画的奇妙之处和乐趣所在,在不断的探索和实践里,你可能会和我一样,越发感受到人工智能的智慧所在。
在完成了AI绘画以后,你不需要去对图片进行特别的保存。因为所有生产上的图片都会在你的本地文件夹里,在上面的标签里有一个图库浏览器。
在这里面你可以按照类目查看到,通过不同方式生成出来的图像。你想要把它导出来,就像在浏览器里保存一张图片一样,右键另存为即可。另外你也可以去WebUI的根目录里找到一个叫做outputs的文件夹,所有的图都存在这里。
图库浏览器还有很多进阶的用途,比如它完整记录了你图像里的各种生成信息,你还可以利用它快速打开一张已经画好的图像,并且对它做图生图局部重绘等等。
5、总结
以上就是本节课的所有教学内容了,来做一个总结。
在今天的这一节课里,我们介绍了StableDiffusion这款非常受欢迎的AI绘画应用,并对它进行本地安装部署。随后我们对SD的基本操作界面进行了简单的介绍,并尝试着在里面只会AI生成了一幅简单的风景人物插画,同时熟悉了对图像进行保存导出的方式。通过这节课的学习,你已经可以说是初步入门了。
在下一节课里,我们将开始针对它的各方面功能做进一步的拓展。首先要攻克的就是文生图(text to image)这一基本的绘制方式了。
我将在其中和你详细的讨论书写prompt提示词的基本逻辑,以及如何利用各种提示词的规则来增强或者去除画面内容,并系统的讲解出图参数的设置要点。
如果你对这期教程有什么建议和疑问,可以在群里和我讨论并且交流,我将不遗余力提供帮助和指导。

若有收获,就点个赞吧
0 人点赞
