在上一节课中,我们成功地安装了StableDiffusion,并且创作了属于我们自己的第一幅AI绘画作品。
在创作过程中,输入提示词(prompt)是不可或缺的一步。由于大多数AI绘画作品的提示词都是用英语书写的,而且通常又长又乱,还混杂着各种奇怪的符号,就像是高深莫测的魔法咒语一样。因此,我们形象地称这个输入提示词的过程为“念咒”。
就像魔法师一样,我们需要通过吟唱咒语来召唤出我们想要的结果。在许多情况下,AI并不知道我们想要的是什么,因此需要详尽的提示词来更好地指挥AI作图。这也是为什么在AI绘画领域,念咒这个概念已经逐渐演变成了一门独立的学问,值得我们深入探讨研究。
本节课在提示词的原理上实际上是通用的,你可以将本节课学到的内容迁移到Midjourney的使用上。事实上Midjourney对提示词的依赖程度甚至高过StableDiffusion。
接下来,让我们正式开始吧。
提示词的基本概念介绍
这节课我们来接触StableDiffusion中的文生图功能。
这里面的“文”指的自然就是提示词(Prompts)了。广义的解释Prompts,是指用户输入的文本或图像信息,目的是指导模型根据一些特定需求生成艺术作品。
直白一点说,它是我们用来告诉AI我要画什么,画成什么样的一种语言。
上节课里我们也提过了SD里进行绘制的两种基本方式,文生图和图生图。文生图就是主要以文字来实现这个沟通过程的。而图生图还可以依赖图片来传达信息,但图生图里也有提示词,而且同样重要。甚至你可以将图生图中的图也看成提示词的一种。
提示词中的内容非常广泛。它可能包括主题、风格、人物特征以及一些具体的要素。例如,我画的这张图片就有很多提示词。不同的提示词向AI描述了图片的风格、人物、外表、服装特征、场景内容和一些额外的装饰元素。尽管有那么多词,事实上,许多关于风格和质量控制的提示词是固定的。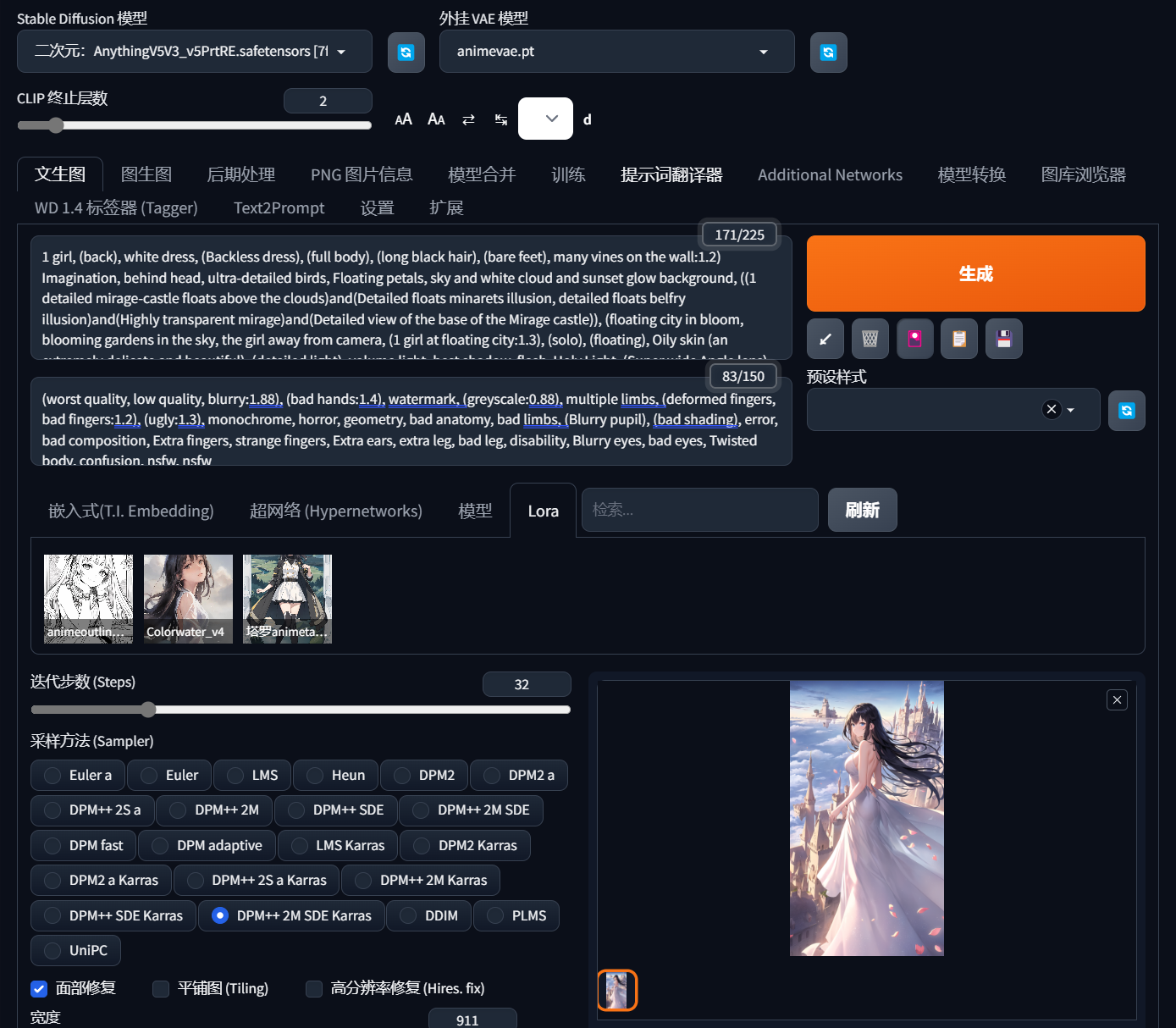

虽然说提示词并非越多越好,但很多时候写多点出来的效果肯定要更很好,且在特定的需求上控制会更为精确。所以要想让AI按照我们的需要去产图的提示词到底应该怎么写呢?
其实写提示词的过程是非常自由的,无论你写什么AI都可以给你画。
提示词的语法(输入、间隔)
尽管自由,但提示词仍然遵循一些基本的语法规则。
首先,提示词应使用英文书写。如果您的英语水平足够好,可以直接使用英语来组织您的描述语言。如果不太熟悉英语,那就得借助翻译软件了,这里我强烈建议使用ChatGPT。
其次,提示词以词组为单位,无需像真实的英语句子那样具有完整的语法结构或从句等。就好像当你想要告诉AI绘画一个又长又宽的面和一个又大又圆的碗时,你可以直接将其拆分为面、长度、宽度以及碗的大小和形状。这样,AI也能理解,甚至有时比第一种方式更理解您的意思。
词组与词组之间需要插入分隔符。基本的分隔符形式是英文中的半角逗号。
在输入提示词时,最好将输入法切换为英文。在关键词中,所涉及的符号基本上都是英文符号。提示词可以换行,但每行的末尾最好添加分隔符。你可以输入一些内容,然后直接点击生成的图像。它可能非常符合你的需求,也可能变得奇怪。AI绘画具有一定的随机性,生成多次,每次生成的结果都会不太一样。
有人将AI绘画比作抽卡,想要得到好的图像,需要依靠运气,但是其实我们可以控制我们的运气。
提示词的分类
以我们上节课的案例来说:一个女生在草原上行走。这其实是一个非常宽泛的描述。这个女孩长什么样子,草原上有什么东西,时间是早上还是晚上,天气如何?这些东西AI都不知道,你的提示词太过于笼统,那他就只能瞎抽卡了。
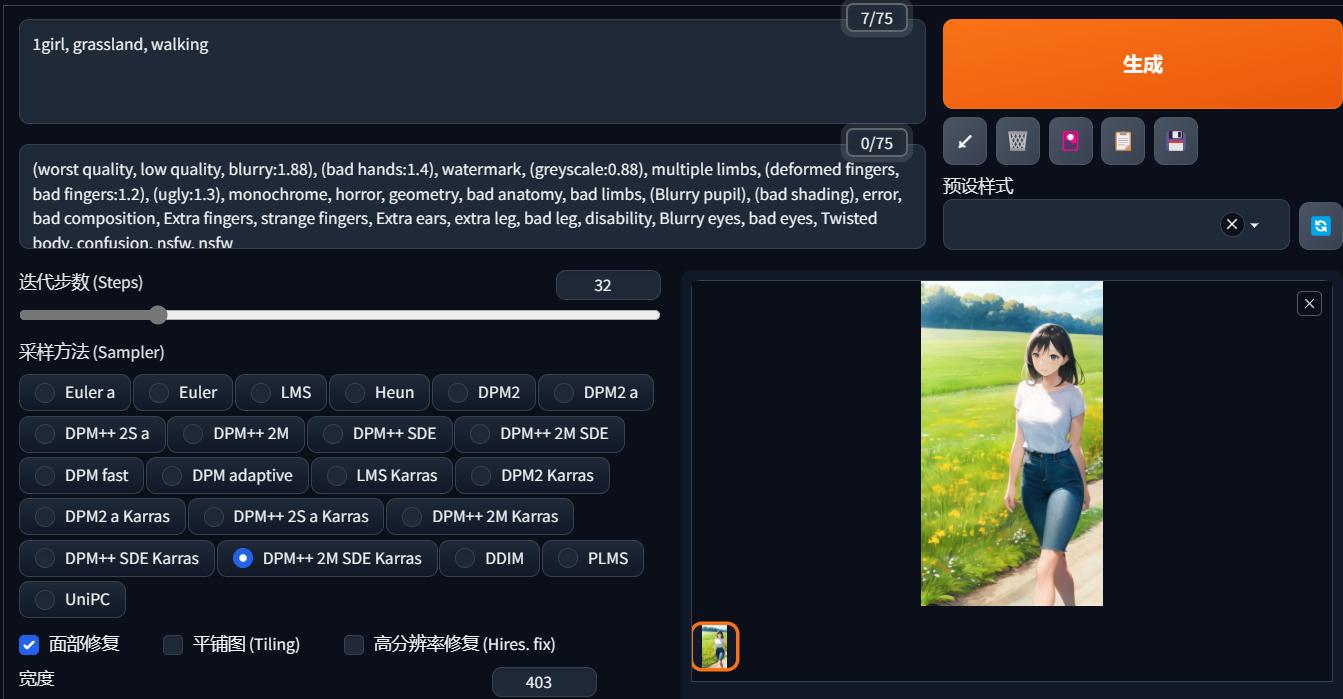
提示词太过笼统的结果(点击图片可查看大图)
但也别担心提示词很多时候不是一下子就写好的,而是先有一个雏形,再慢慢细化补充和微调的。上节课里我们在后面加入的提示词,更多的就是在一些具体的方面对这写内容做控制。
要加些什么呢?其实是有很多不同的分类。这里我把它简单的概括成了如下几大类,方便你对号入座,找到逻辑。
内容型提示词
首先是基于人物或者主体特征的,例如女孩穿的是衬衫还是长裙,头发的颜色和长度,以及脸上的表情,肢体的动作。具体一点,越具体,AI的思路也越清晰。
你可以加入一些形容词,例如beautiful、happy等。他们虽然比较抽象,但也能在一定程度上让画面往你想要的感觉倾斜。
接下来是关于场景特点的部分,比如草原上有很多草,但你也可以加上一些白色的花朵或者一条小路。
还有一个要点,如果你在描述户外场景,最好加上”outdoor“这个词。相反,如果是室内场景,就用”indoor“,这会对整个画面的氛围产生显著影响。
关于环境的描述也可以算作场景的一部分。例如,画面发生在白天,有阳光和多云天空,这些都可以写进去。这些东西其实很好理解,而且也属于具体化的元素。我们在画面中能看到的东西,我把它们归纳为内容性的提示词。
然而,如果只有内容性的提示词,你画出的东西很可能不会令人满意。就像这些作品一样,你会觉得它们模糊不清,细节也不清晰。像这些作品,你会觉得它很模糊,细节也不清晰。这里我们就需要引入其他的提示词来给这个画面打一剂强心针。
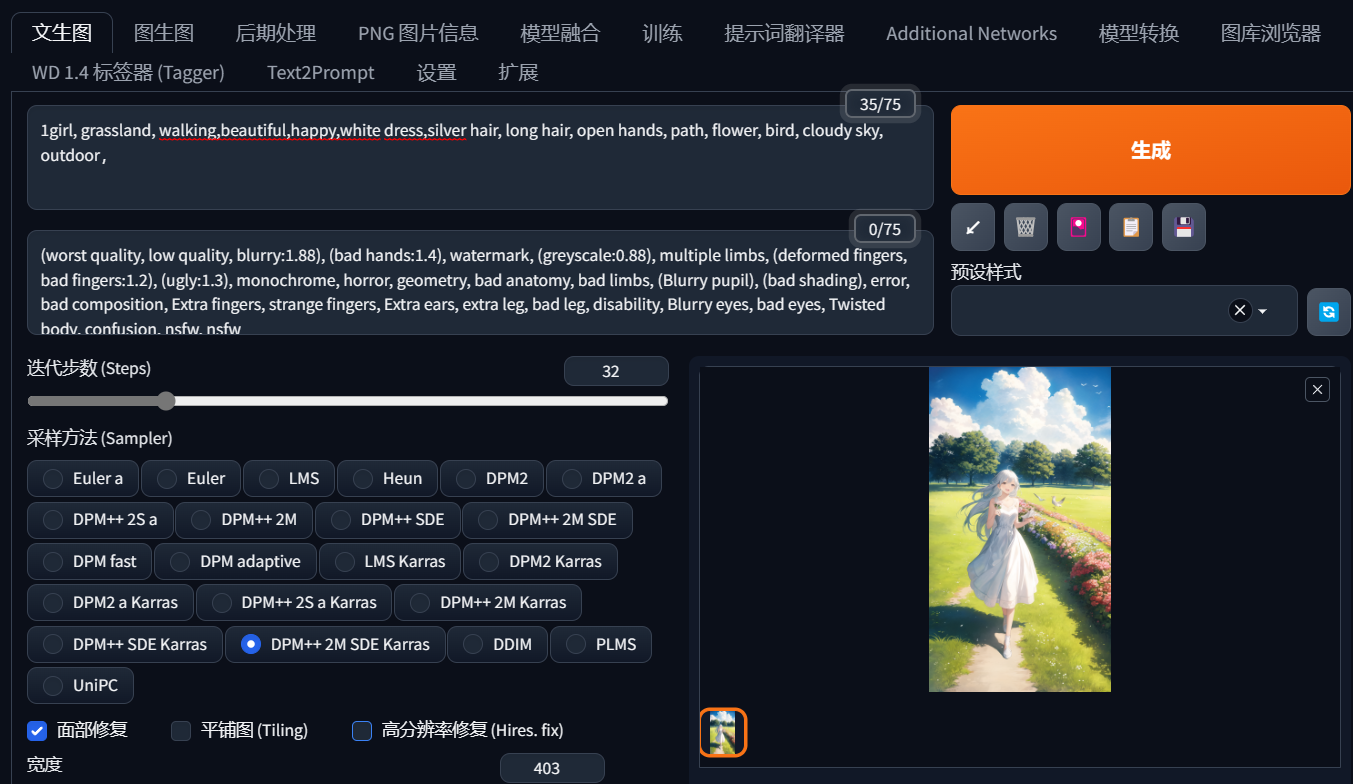
加入内容性提示词后(点击图片可查看大图)
标准化提示词
首先是画质,因为AI学习的图片里面有些是高清的,有些质量比较模糊,我们就可以用这样的提示词让他盯着那些高清的去看,从而让你的作品也产出类似的画面特征。
常用的提示词包括best quality,ultra-detailed,masterpiece, highest,8K等等等。也有一些比较具体的,例如什么extremely Detailed,CG,unity,unreal engine rendered等。他们指向某一种特定形式的艺术作品,而他们往往都具有更为细节化、真实化的特征。
其次是画风,也就是作品的风格,它也是多种多样的。
如果你想要画的是一幅比较偏插画风的画作,那常用的画风提示词包括painting、illustration、drawing等等。想要二次元一点的,可以考虑加入animal comic MC之一的关键词。想要一篇真实系的画风,其实也有对应的风格,关键词,例如photorealistic,realistic等等。
但真实系的创作更依赖基于真实照片训练的模型,这一点在完成后续的学习之后,你会有更深刻的体会。
我把这些提示词统称为标准化的提示词,因为它们能让画面更趋近于某一个固定的标准。加了这些标准化的提示词,画面的质感和细节是不是一下就丰满起来了呢?
分析到这里该怎么写提示词的初步框架就清晰了。一个AI能读懂的好咒语,应该是内容充实丰富,且画面具有清晰标准。这里我也提供了一个基本的模板框架,你可以按照这个方式对号入座的修改里面每一段的内容,从而让你的画作变得更符合需要。
内容型的提示词多数时候是因你想创作的内容而异的,每次都要改成不同的东西。如果你只是需要微调,那其实此词组画的一个好处就会体现出来。当你想要修改某些具体的细节时,不需要重新来组织语言,而是直接找到对应的词组,更改成不同内容,画面内容就针对这一项产生变化。
但标准化的提示词是相对固定,可以抄作业的。所以只要你想画的是比较二次元的高质量插画,你可以每次都把上节课我教给你的这段咒语原封不动复制进去。
:::tips
(masterpiece:1,2),best quality,masterpiece,highres,original,extremelydetailed,walpaper,
perfectlighting,(extremely detailed CG:1.2),drawing,paintbrush,
:::

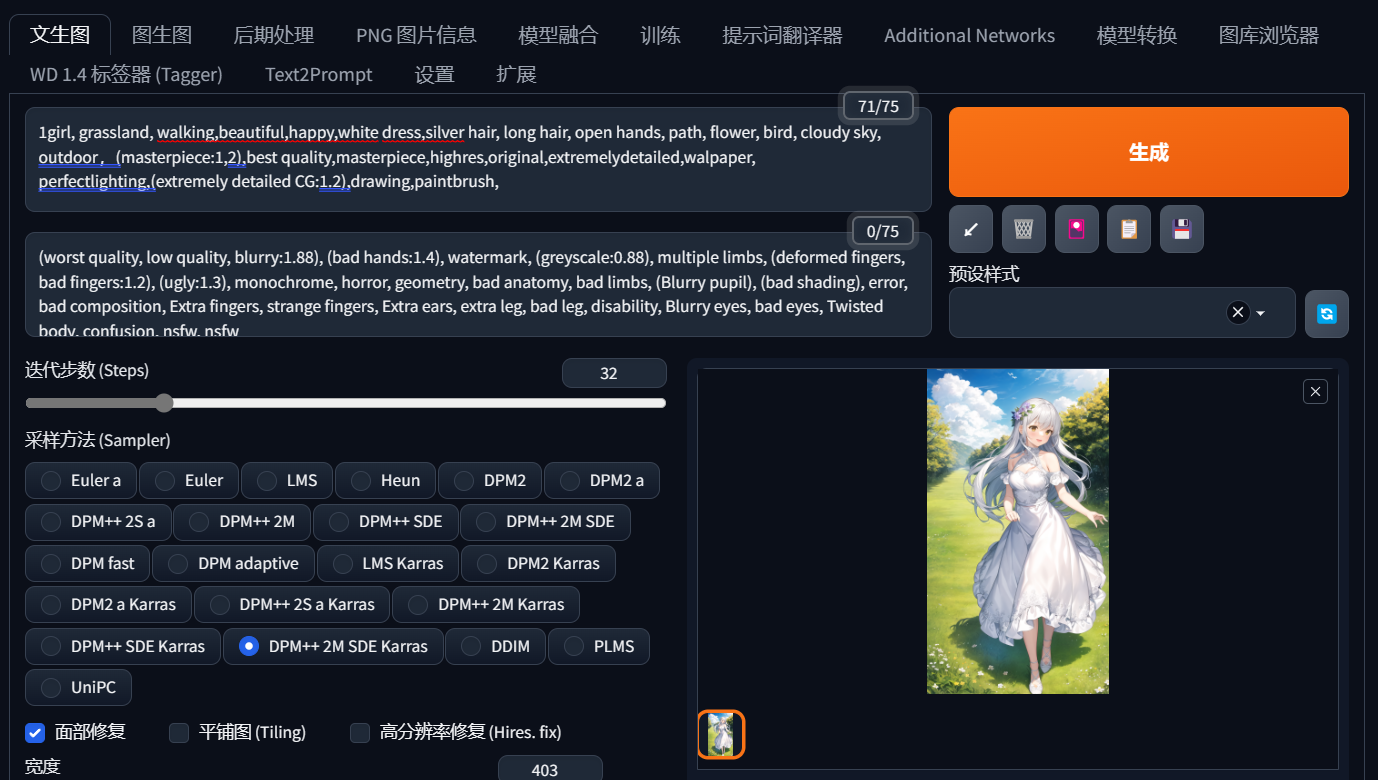
加入标准化提示词后(点击图片可查看大图)
关键词的权重
但在这段咒语里,你可能会看到很多括号和数字,它们是做什么的呢?
其实这些内容是用来增强或者是减弱某些提示词的优先级和权重的。以我们刚刚绘制这个画面为例,虽然我们输入了 flower,但画面的花特别的少。这里面的原因就在于你输入了很多不同元素给AI都要他画。但他在处理的时候不一定get到你最想要的是什么。
如果你就是特别想要花,那就可以用类似的方式把花的权重和优先级增强。
增强的基本方式有两种。
第一种是加括号,在提示层两侧加上这种圆括号,注意还是英文半角的,它的权重就会变成原来的一点1.1倍,相对于其他元素就会更突出。你还可以套多层括号,每套一层就再乘以1.1倍,三层就是1.331倍。看在我们加了三层括号以后,花就多了。

另一种方式是括号加数字权重,加了一种括号以后,你可以直接在后面加一个英文冒号,打一个数字,数字可以直接定义它的权重。比如1.5就是原来的1.5倍。
所以当你觉得这个画面里有你告诉了AI,但他又没有画出来的东西时,就可以借助这些方法来强调加数字的方式明显更准确,而加括号在进行微调的时候就更方便。
比起圆括号,还有这种大括号代表1.05倍调节的效果要更细微一点。而如果你想削弱某一个词的影响,就可以赋予它一个小于1的权重数值,或者用方括号会把权重削成原来的0.9倍。
调节权重的时候,也要注意一件事情,就是尽量避免个别词条权重太高。
我测试后的安全范围在1上下0.5左右。当你赋予个别词条一个2左右甚至更高的数值时,它就容易扭曲画面的内容。这个时候我们一般需要改换思路,通过更多同类型的词条来协同增强它的效应。
还有很多更为深入的语法规则,例如词条的混合迭代、迁移等。通俗点说,你希望这个画里出现什么,就往正向提示字里丢,而不希望它出现什么,就往反向提示词里面丢。
反向的提示词是可以没有的,但一般我们也会选择加入一些通用的项目,主要也是基于标准化的考虑。
比如上节课的魔咒,worst quality, low quality, blurry的目的是杜绝低质量的学习样本。monochrome的意思是单色,ugly不解释,你也知道了,后面这些Extra fingers, strange fingers, Extra ears, extra leg, bad leg之类的有点玄乎。之前不是一直说AI不会画手和四肢吗?
画的时候偶尔会多只手都要推手跟手指之类的。这些提示词,也就是为了避免类似的情况发生。
反向提示词通常情况下也是可以抄作业的。但如果你想要一些特殊一点的风格,偶尔也可以反其道而行之。
:::tips
(worst quality, low quality, blurry:1.88), (bad hands:1.4), watermark, (greyscale:0.88), multiple limbs, (deformed fingers, bad fingers:1.2), (ugly:1.3), monochrome, horror, geometry, bad anatomy, bad limbs, (Blurry pupil), (bad shading), error, bad composition, Extra fingers, strange fingers, Extra ears, extra leg, bad leg, disability, Blurry eyes, bad eyes, Twisted body, confusion, nsfw,
:::
文生图的参数
如果说提示词是咒语,那下面的一系列出图参数就像是魔法师的魔导书一样,控制了这个咒语的具体释放形式。看到这一大堆参数是不是头都有点大了,别担心我们从本质出发来快速梳理一遍。
1、迭代步数
AI生成图像会经过一个加噪再去噪的过程。而去噪就是在用像素一点点的模拟你最终要生成的这个图像,每模拟一次画面就会变得更清晰一点。
理论上迭代步数越多,肯定最终效果越清晰。但实际上,当步数大于20步以后,后面的提升不大,就像80分再到90/100分一样。而增加步数肯定意味着更长的计算时间,所以默认的采用步数一般都是20。你算力充足且想追求更高的细致度,就设置为30到40,最低不要低于10,不然你可能被自己产出的作品吓到。
2、采样方法
采样方法其实可以简单解释成AI进行图像生成的时候使用的某种特定算法。WebUI提供的算法选项非常多,足足十几个。但其中我们常用到的估计也就4到5个。
这其中Eluer的两个适合插画风格,出图比较朴素。DPM2M和2M Karras速度较快,SDE Karras细节会较为丰富,这些评价并不一定绝对准确,也因提示词和模型不同有所差异,但实际使用的时候,我推荐你用最后面面这几个带有加号的,他们是改进过的算法,无论如何应该都比上面的更稳定。
另外大部分模型也有推荐使用某一种特定的算法,这可能是模型制作者自己测试过做的。比如深渊橘的作者,最推荐使用的就是SDE Karras,这个时候照做就好。
3、分辨率设置
下面的宽和高,它代表的就是你最终出图时候的分辨率。分辨率的设置存在一些隐性限制,默认的分辨率是512乘512,但这个分辨率下的图片哪怕细节再丰富,看起来可能都是很模糊的。设备允许的情况下,我们一般会把它提到1000左右相同的提示词。
但是分辨率设置的太高也是会有问题的。
一是你的显卡显存扛不住。我的3060就只能跑到1500像素左右的宽和高。
其二则是分辨率太大了,很容易出现多人多手多脚的情况。这个问题我有特意研究过,它的原因是AI在进行模型训练的时候用的图片分辨率一般都比较小。如果你的分辨率设置太大,它就会认为你是多张图片拼接而成的,但出现多的人就不奇怪了。
要避免这样的问题出现,一般我们会采用低分辨率先绘制,再靠高清修复来放大它。本质上是进行了一次额外的图层图。我们会在之后的课程里面详细讲解。
你也需要通过反复试验了解在你当前的设备条件下,什么分辨率是既能保证质量又能兼顾效率的。
4、面部修复和平铺图
旁边的这两个选项,面部修复一般都会勾选上,它会采用一些对抗算法识别人物的面部,并进行修复。和我们用的美图APP里面智能P脸的功能差不多。
平铺是用来生成那种可以无缝贴满整个屏幕的纹理性图片的。如果你是个擅长3D建模和渲染的工作者,应该对这个功能有很强的需求。
5、提示词引导系数 (CFG Scale)
提示词引导系数其实很好理解,它的数值越高,AI忠实的反应提示词的程度就越高,但和权重一样,我们一般不会浮动太多。7到12之间是比较安全的,数值太高,容易变形。
随机种子也是一个可以用来控制画面内容一致性的重要参数。但我打算放在下节课里再和你慢慢讨论。
6、生成的批次和数量
因为AI绘画的不确定性,即便是同一组提示词,你也需要反复试验,期待他在某一瞬间给到你一个完美符合你需要的画面。这个实验过程有时候会很漫长,可能会经过几十次上百次。如果你想让AI一直不断的按照同一组提示自由参数去出图,那就把批次数调高,绘制的过程会不断重复进行。
结束了以后,它会生成两样东西:除了每个批次出的图,还会有一张像这样拼在一起的格子与蓝图,方便你进行对比。
所以你完全可以让他一口气来上个10次、20次甚至几百次,你自己去吃个饭,睡一觉,让显卡在这里打黑工。
单批数量这个选项我一般不建议你调整,增大它可以让你每批次绘制的图像数量增多,理论上效率会更高。但它是同一批绘制的,方法是把它们拼在一起,看做一张更大的图片依次去画的。所以如果你的设备不好,非常容易爆显存,不如单批话少一点,再用更多的次数去解决这个问题。
最后的话
了解了这些参数的具体含义以后,你应该就更清楚的知道自己想要去做什么样的图片了。讨论了这么多关于提示词和参数的知识,你现在会写提示词了吗?
就我自己摸索经验来看,单纯掌握这些理论上的方法,其实很难一下子就摸到提示词的窍门。所以我还为你准备了几个非常适合新手的在写提示词方面,取巧的方法一定要记牢了。
我总结出来的方法一共有两条,用起来都非常简单。
第一条:翻译大法
其实无论这些提示词再怎么复杂,他们说的还都是人话。因此,当你不知道该如何表达的时候,就用自然的语言去把你想要画的东西一件件的说出来就好了。
还是那句话,SD不认中文,所以你得先用翻译平台把它转成英文。你可以像上节课一样,先描述一个确切的场景,然后再按照我们刚刚的逻辑想到什么,就把新的词组翻译成英文,再加到后面去。虽然这些词语表述有时候不绝对准确,但它至少是在帮你接近那个你想要的画面。而有一些功能插件也会帮助你把不准确的词汇校正成AI的词典。
第二条:借助工具
AI绘画也流行了一段时间了,能意识到提示词难写的人肯定也不止你我而已。因此,有些人专门开发了一些可以帮助你更好的去书写提示词的工具。
在这里我推荐两个可以用于辅助书写提示词的网站,它们的用法都很简单,你可以像选参数一样勾选那些你需要的,它会帮助你自动按照刚刚我们说的那些语法规则整理到一起,然后你再复制粘贴到自己的SD里面就可以了。使用这些工具,像是在经历一个更方便的翻译的过程,但要注意思路,不要被它已有的一些词汇限制住了。如果有其他你想要加进去的东西,也可以尝试自己撰写添加。
1、OPS https://moonvy.com/apps/ops/ 
2、魔导绪论 https://magic-tag.netlify.app/#webview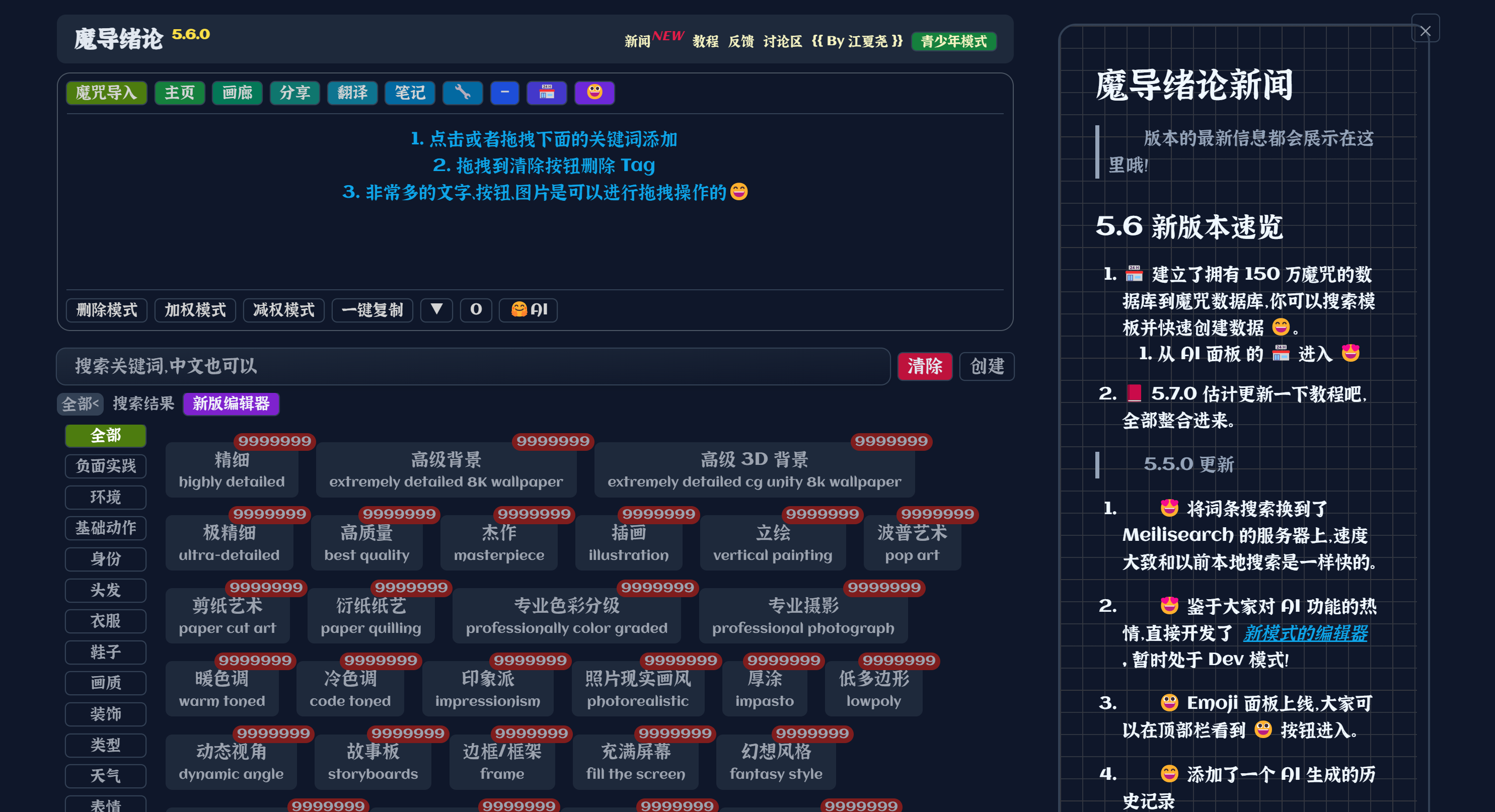
好了,以上就是本节课的所有内容了。在今这期教程里,我们简单探讨了文章图功能以及其中的提示词书写逻辑,了解了提示词的基本逻辑、语法规则、权重调整和负面提示词的作用。
梳理了SD的初步参数设置里面的各项含义,并整理了两条对于新手非常有帮助的书写提示词的辅助方法。
完成这节课以后,你就是一位会念咒能指挥AI的出色魔法师了。
让我们期待下一期吧。

若有收获,就点个赞吧
0 人点赞
