有什么新鲜事?
这篇论文介绍了一组基础语言模型,参数范围从70亿到650亿。
这些模型在可公开获取的数据集上进行了数万亿次训练。
(Hoffman et al. 2022)(opens in a new tab) 的工作表明,在更小的计算预算下,对更多数据进行训练的较小模型可以实现比其较大的模型更好的性能。论文建议用 200B token训练 10B 的模型。然而,LLaMA 论文发现,即使在 1T token之后,7B 模型的性能也会继续提高。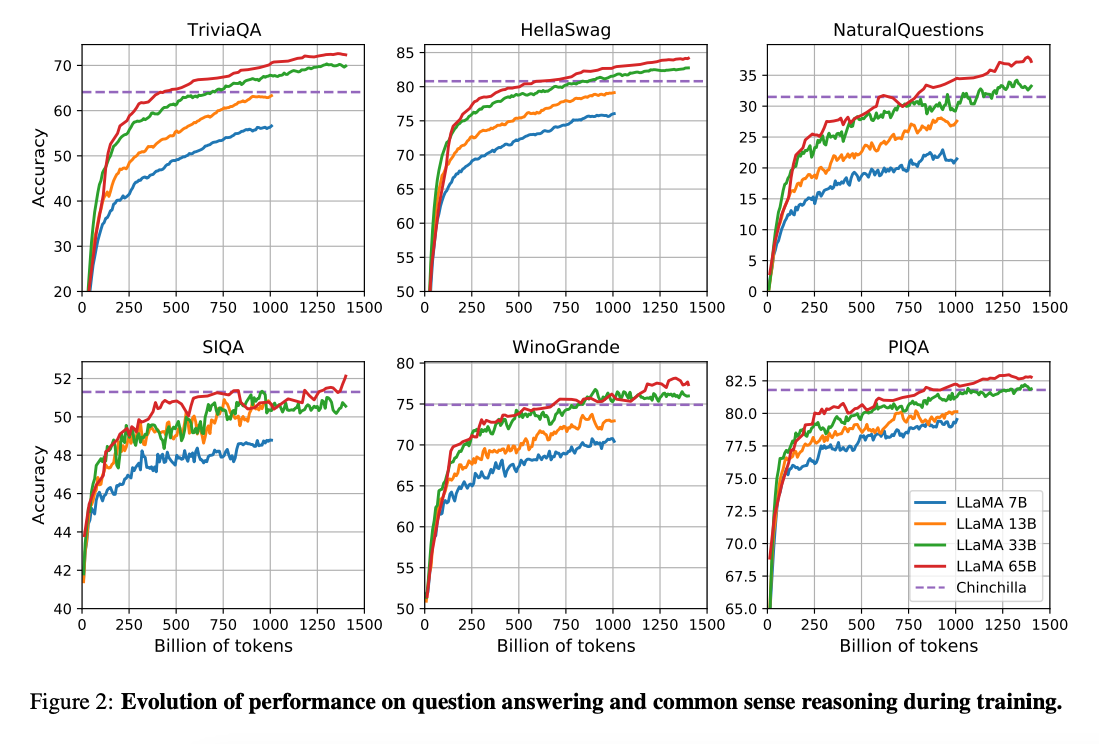
这项工作专注于通过更多的token训练模型(LLaMA),使其在不同的推理预算下实现最佳性能。
能力与关键结果
总的来说,尽管 LLaMA-13B 模型比 GPT-3(175B)小10倍,但在许多基准测试上的表现仍优于 GPT-3,并且可以在单个GPU上运行。LLaMA 65B 与 Chinchilla-70B 和 PaLM-540B 等模型都具有竞争力。
Paper: LLaMA: 开放且高效的基础语言模型(opens in a new tab)
Code: https://github.com/facebookresearch/llama(opens in a new tab)
引用
- Koala: A Dialogue Model for Academic Research(opens in a new tab) (April 2023)
- Baize: An Open-Source Chat Model with Parameter-Efficient Tuning on Self-Chat Data(opens in a new tab) (April 2023)
- Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality(opens in a new tab) (March 2023)
- LLaMA-Adapter: Efficient Fine-tuning of Language Models with Zero-init Attention(opens in a new tab) (March 2023)
- GPT4All(opens in a new tab) (March 2023)
- ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge(opens in a new tab) (March 2023)
- Stanford Alpaca(opens in a new tab) (March 2023)

若有收获,就点个赞吧
0 人点赞
