KMP算法
字符串匹配问题
所谓字符串匹配,是这样一种问题:“字符串 P 是否为字符串 S 的子串?如果是,它出现在 S 的哪些位置?” 其中 S 称为主串;P 称为模式串。下面的图片展示了一个例子。


主串是莎翁那句著名的 “to be or not to be”,这里删去了空格。“no” 这个模式串的匹配结果是“出现了一次,从S[6]开始”;“ob”这个模式串的匹配结果是“出现了两次,分别从s[1]、s[10]开始”。按惯例,主串和模式串都以0开始编号。
字符串匹配是一个非常频繁的任务。例如,今有一份名单,你急切地想知道自己在不在名单上;又如,假设你拿到了一份文献,你希望快速地找到某个关键字(keyword)所在的章节……凡此种种,不胜枚举。
next数组
next数组是对于模式串而言的。P 的 next 数组定义为:next[i] 表示 P[0] ~ P[i] 这一个子串,使得 前k个字符恰等于后k个字符的最大的k. 特别地,k不能取i+1(因为这个子串一共才 i+1 个字符,自己肯定与自己相等,就没有意义了)。
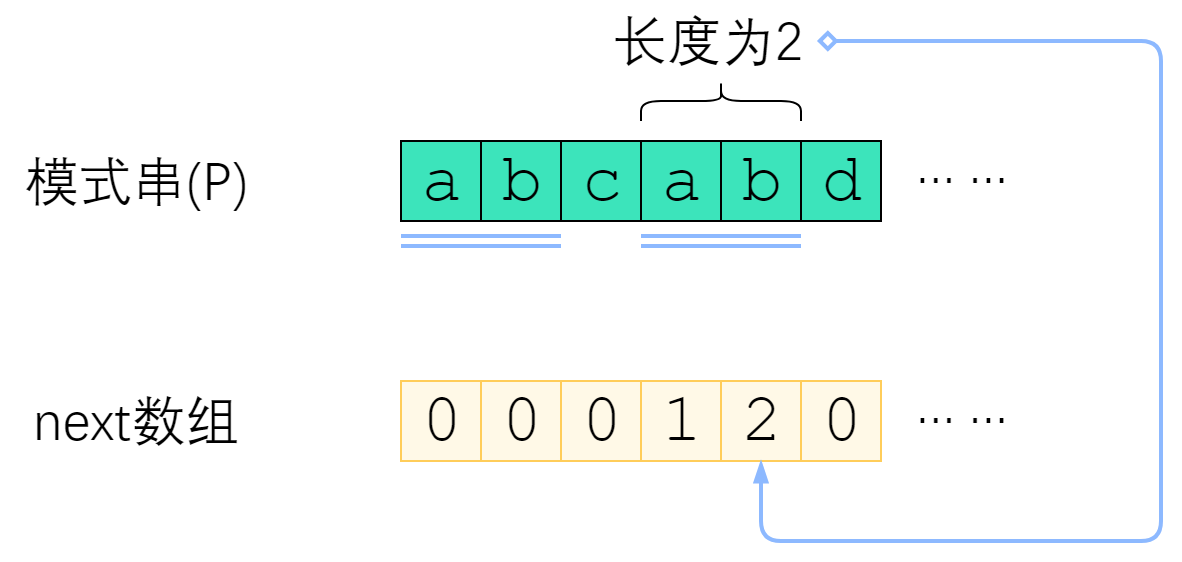
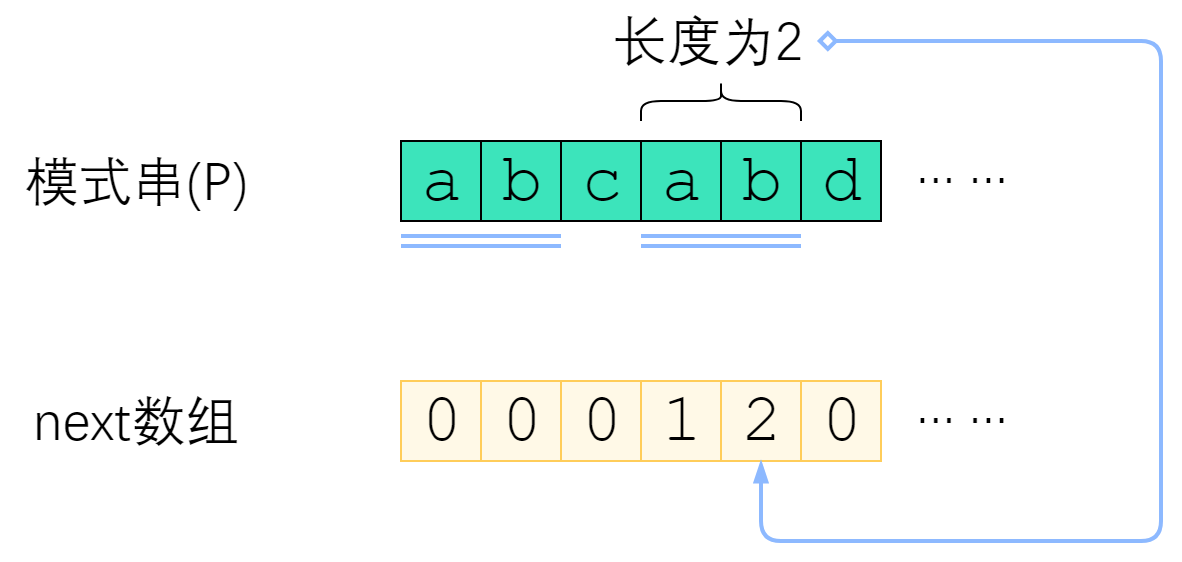
上图给出了一个例子。P=”abcabd”时,next[4]=2,这是因为P[0] ~ P[4] 这个子串是”abcab”,前两个字符与后两个字符相等,因此next[4]取2. 而next[5]=0,是因为”abcabd”找不到前缀与后缀相同,因此只能取0.
如果把模式串视为一把标尺,在主串上移动,那么 Brute-Force 就是每次失配之后只右移一位;改进算法则是每次失配之后,移很多位,跳过那些不可能匹配成功的位置。但是该如何确定要移多少位呢?
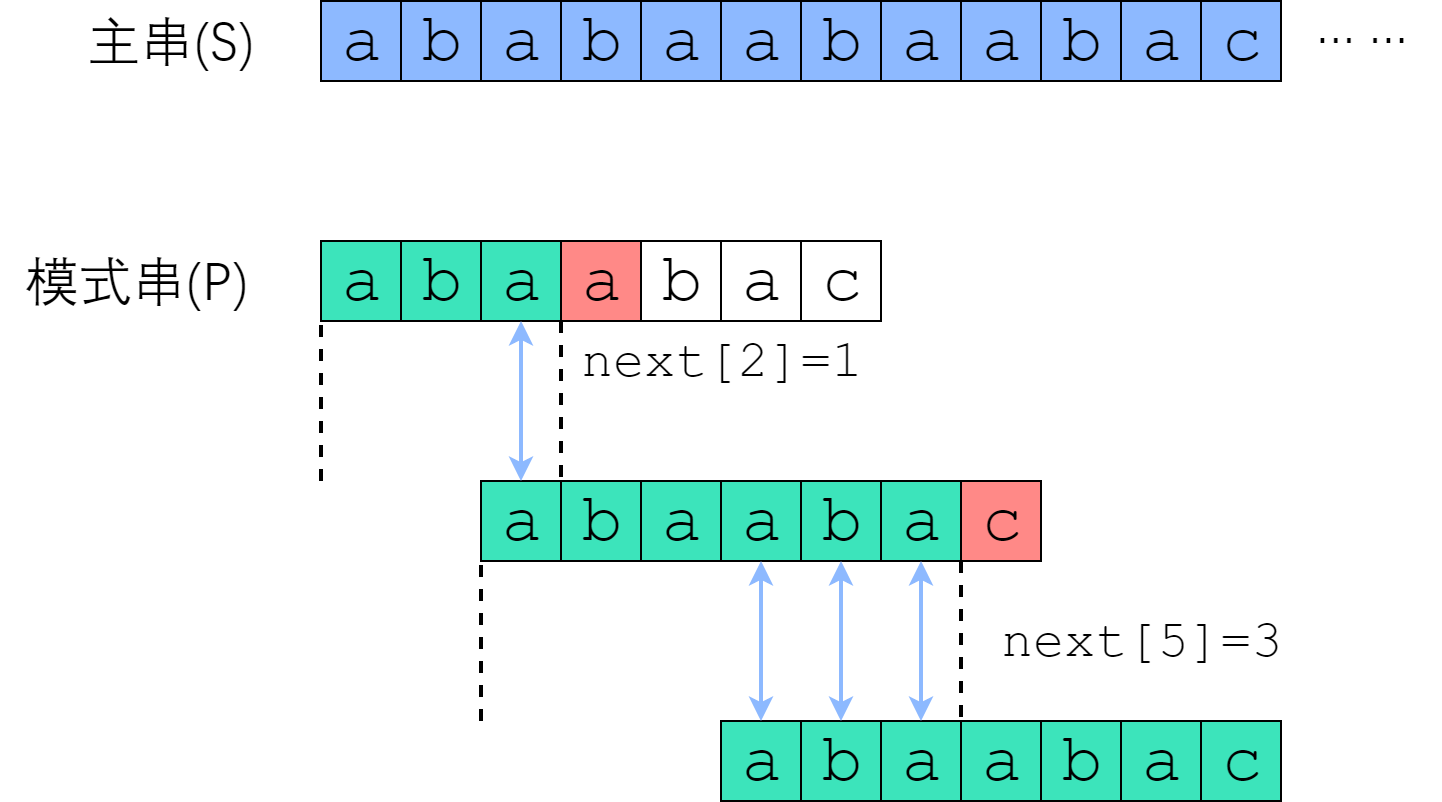

在 S[0] 尝试匹配,失配于 S[3] <=> P[3] 之后,我们直接把模式串往右移了两位,让 S[3] 对准 P[1]. 接着继续匹配,失配于 S[8] <=> P[6], 接下来我们把 P 往右平移了三位,把 S[8] 对准 P[3]. 此后继续匹配直到成功。
我们应该如何移动这把标尺?很明显,如图中蓝色箭头所示,旧的后缀要与新的前缀一致(如果不一致,那就肯定没法匹配上了)!
回忆next数组的性质:P[0] 到 P[i] 这一段子串中,前next[i]个字符与后next[i]个字符一模一样。既然如此,如果失配在 P[r], 那么P[0]~P[r-1]这一段里面,前next[r-1]个字符恰好和后next[r-1]个字符相等——也就是说,我们可以拿长度为 next[r-1] 的那一段前缀,来顶替当前后缀的位置,让匹配继续下去!
您可以验证一下上面的匹配例子:P[3]失配后,把P[next[3-1]]也就是P[1]对准了主串刚刚失配的那一位;P[6]失配后,把P[next[6-1]]也就是P[3]对准了主串刚刚失配的那一位。


如上图所示,绿色部分是成功匹配,失配于红色部分。深绿色手绘线条标出了相等的前缀和后缀,其长度为next[右端]. 由于手绘线条部分的字符是一样的,所以直接把前面那条移到后面那条的位置。因此说,next数组为我们如何移动标尺提供了依据。接下来,我们实现这个优化的算法。
利用next数组进行匹配
了解了利用next数组加速字符串匹配的原理,我们接下来代码实现之。分为两个部分:建立next数组、利用next数组进行匹配。
首先是建立next数组。我们暂且用最朴素的做法,以后再回来优化:

如上图代码所示,直接根据next数组的定义来建立next数组。不难发现它的复杂度是  的。
的。
接下来,实现利用next数组加速字符串匹配。代码如下:

如何分析这个字符串匹配的复杂度呢?乍一看,pos值可能不停地变成next[pos-1],代价会很高;但我们使用摊还分析,显然pos值一共顶多自增len(S)次,因此pos值减少的次数不会高于len(S)次。由此,复杂度是可以接受的,不难分析出整个匹配算法的时间复杂度:O(n+m).
快速求next数组
终于来到了我们最后一个问题——如何快速构建next数组。
首先说一句:快速构建next数组,是KMP算法的精髓所在,核心思想是“P自己与自己做匹配”。
为什么这样说呢?回顾next数组的完整定义:
- 定义 “k-前缀” 为一个字符串的前 k 个字符; “k-后缀” 为一个字符串的后 k 个字符。k 必须小于字符串长度。
- next[x] 定义为: P[0]~P[x] 这一段字符串,使得k-前缀恰等于k-后缀的最大的k.
这个定义中,不知不觉地就包含了一个匹配——前缀和后缀相等。接下来,我们考虑采用递推的方式求出next数组。如果next[0], next[1], … next[x-1]均已知,那么如何求出 next[x] 呢?
来分情况讨论。首先,已经知道了 next[x-1](以下记为now),如果 P[x] 与 P[now] 一样,那最长相等前后缀的长度就可以扩展一位,很明显 next[x] = now + 1. 图示如下。
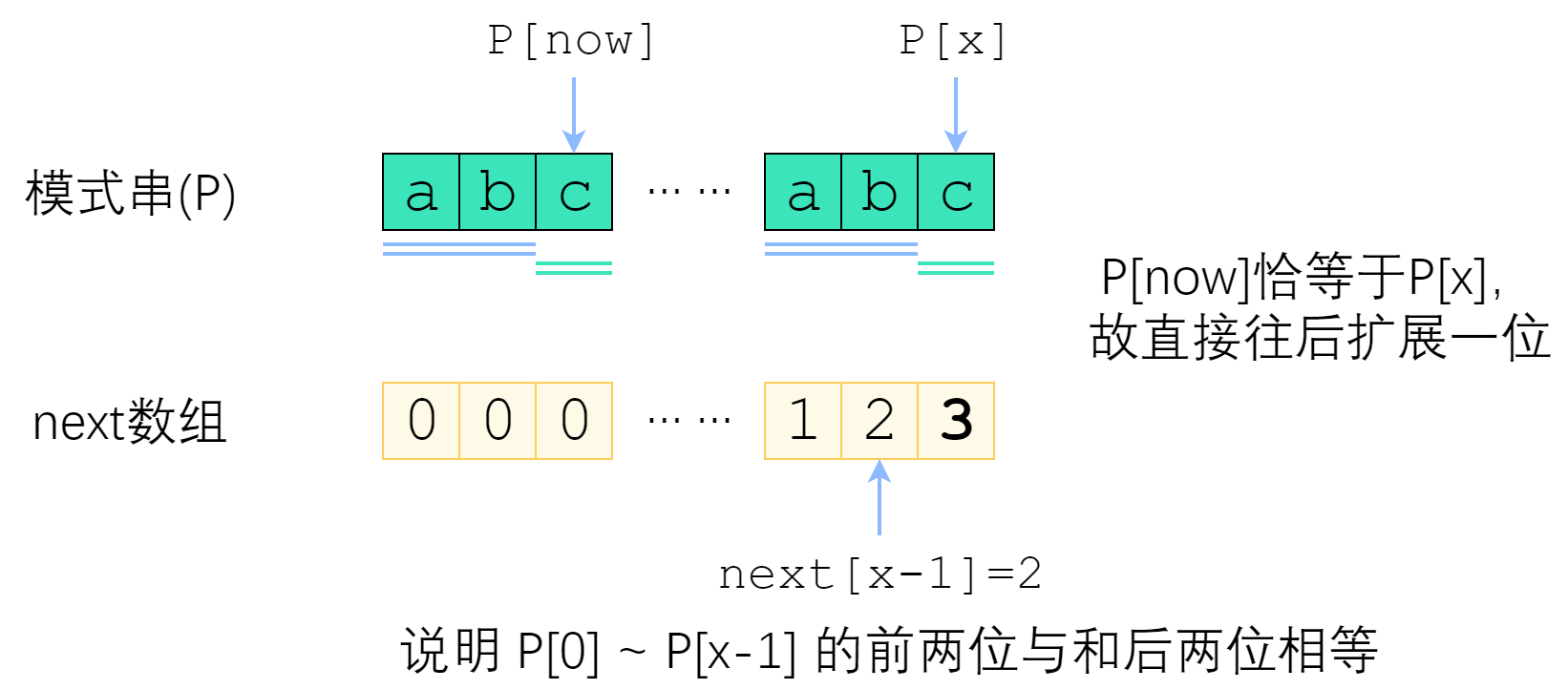
刚刚解决了 P[x] = P[now] 的情况。那如果 P[x] 与 P[now] 不一样,又该怎么办?
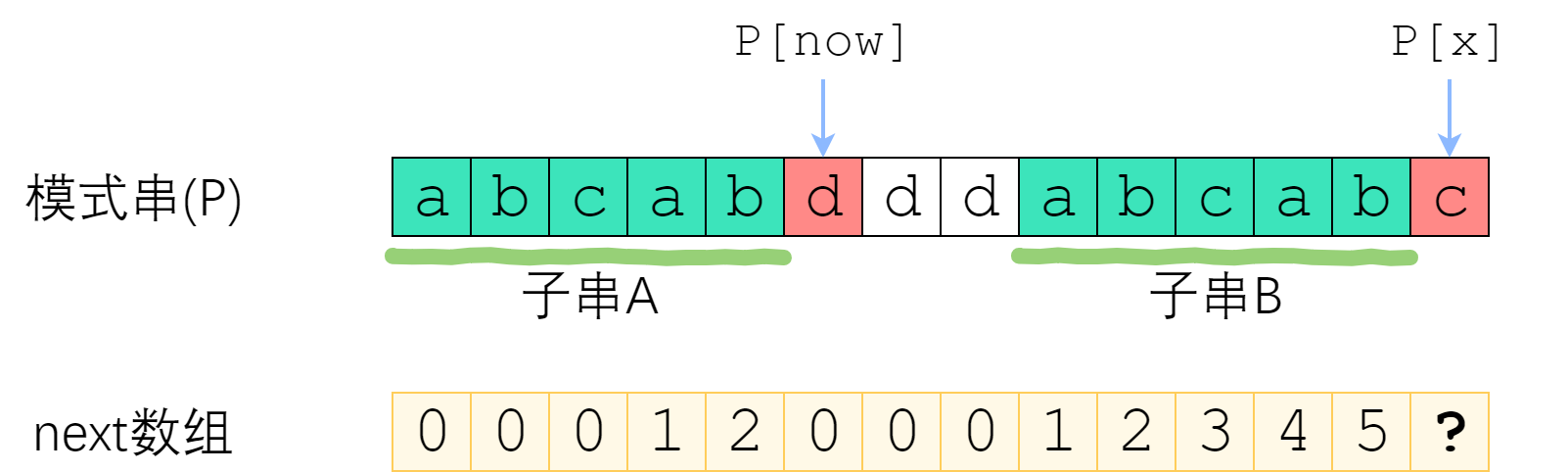
如图。长度为 now 的子串 A 和子串 B 是 P[0]~P[x-1] 中最长的公共前后缀。可惜 A 右边的字符和 B 右边的那个字符不相等,next[x]不能改成 now+1 了。因此,我们应该缩短这个now,把它改成小一点的值,再来试试 P[x] 是否等于 P[now].
now该缩小到多少呢?显然,我们不想让now缩小太多。因此我们决定,在保持“P[0]~P[x-1]的now-前缀仍然等于now-后缀”的前提下,让这个新的now尽可能大一点。 P[0]~P[x-1] 的公共前后缀,前缀一定落在串A里面、后缀一定落在串B里面。换句话讲:接下来now应该改成:使得 A的k-前缀等于B的k-后缀 的最大的k.
您应该已经注意到了一个非常强的性质——串A和串B是相同的!B的后缀等于A的后缀!因此,使得A的k-前缀等于B的k-后缀的最大的k,其实就是串A的最长公共前后缀的长度 —— next[now-1]!
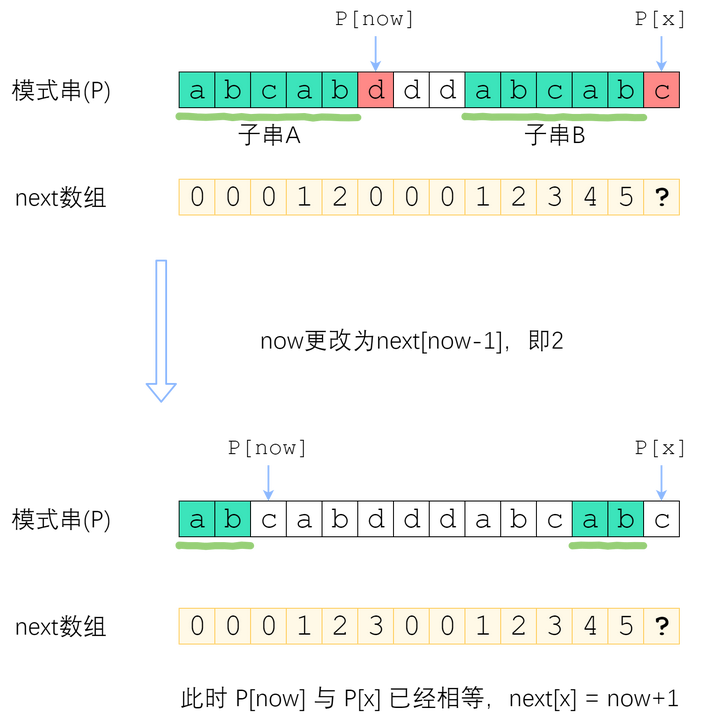
来看上面的例子。当P[now]与P[x]不相等的时候,我们需要缩小now——把now变成next[now-1],直到P[now]=P[x]为止。P[now]=P[x]时,就可以直接向右扩展了。
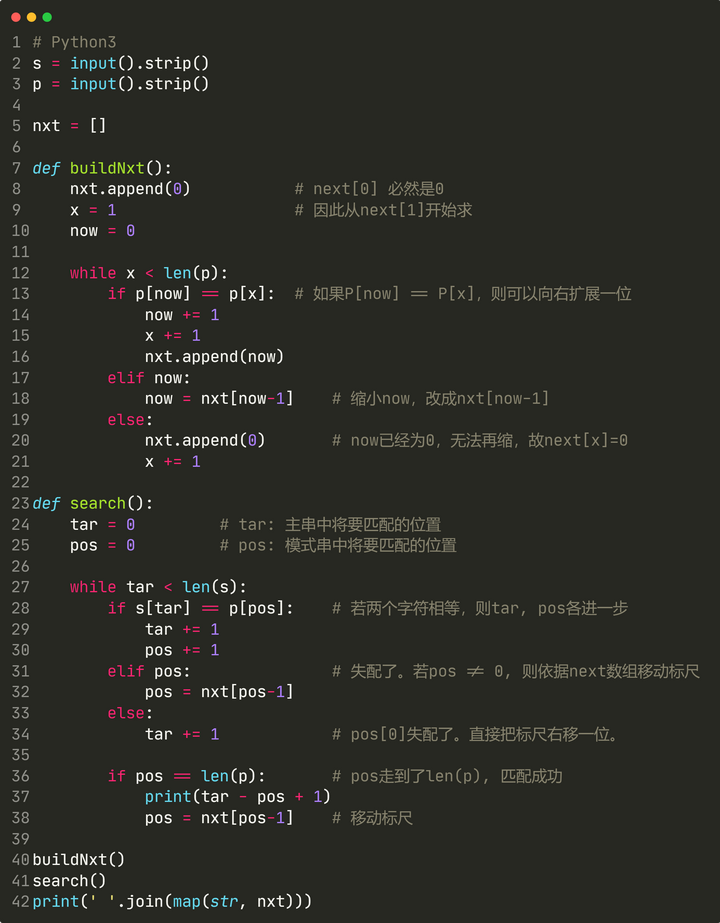
代码实现如下:

应用摊还分析,不难证明构建next数组的时间复杂度是O(m)的。至此,我们以O(n+m)的时间复杂度,实现了构建next数组、利用next数组进行字符串匹配。
以上就是KMP算法。它于1977年被提出,全称 Knuth–Morris–Pratt 算法。让我们记住前辈们的名字:Donald Knuth(K), James H. Morris(M), Vaughan Pratt(P).
完整算法
最后附上洛谷P3375 【模板】KMP字符串匹配 的Python和Java版代码:
c++
#include <iostream>#include <vector>using namespace std;vector<int> buildNext(string p){vector<int> next(p.length());int i=1,now = 0;next[0] = 0;while(i<p.length()){if(p[i]==p[now]){next[i++] = ++now;}else if(now!=0){now = next[now - 1];}else{next[i++] = now;}}return next;}int search(string s, string p,const vector<int>& nxt){//找第一个匹配下标int tar=0,pos=0;while(tar<s.length()&&pos<p.length()){if(s[tar] == p[pos]){tar++;pos++;}else if(pos){pos = nxt[pos];}else{tar++;}}if(pos==p.length()){return tar-pos;}return -1;}int main(int, char**) {string s;///this is the mainstring f;///this is the one to be foundcin>>s>>f;vector<int> nxt = buildNext(f);cout << search(s,f,nxt) << endl;return 0;}
一般参考书上代码:
#include "cstdio"
#include "iostream"
#include "cstring"
using namespace std;
int ne[20];///这个数组中盛放的是匹配字符串的next值
void GetNext(char *a)///这个函数是为了标记匹配字符串的next值
{
int len = strlen(a);///先求字符串的长度,便于循环赋值
int i = 0, j = -1;
ne[0] = -1;
while(i < len - 1)
{
if(j == -1 || a[i] == a[j])
{
ne[++i] = ++j;
}
else j = ne[j];
}
}
///实际上每求一个next值要循环两遍
int KMP(char *a, char *b)
{
int lena = strlen(a);
int lenb = strlen(b);
int i = 0, j = 0;
while (i < lena && j < lenb)
{
if(j == -1 || a[i] == b[j])
{
j++;
i++;
}
else
j = ne[j];
}
if(j == lenb)
return i-j+1;
else
return -1;
}
int main()
{
char s[100];///this is the main
char f[100];///this is the one to be found
scanf("%s", &s);
scanf("%s", &f);
GetNext(f);
cout << KMP(s,f) << endl;
return 0;
}
python:
Java:

两字符串前缀与后缀的最长公共部分
对于给定的两个字符串 T 与 P,求最长的子串,既是 P 的前缀,又是 T 的后缀。
思路
将两个字符串拼接起来,即变成了求一个字符串的后缀与前缀的最大匹配长度,即为 next 数组的含义。
注意两个字符串要找到最短的长度,然后1截取前最短,2截取后最短,然后findNext,注意如果结果比两个字符串的最小长度大的话,结果就是最小长度,不然aaa aa这种情况会出错,所以要处理一下。(也可以在中间插入特殊字符)
#include<iostream>
#include<string>
#include<cstring>
#include<cstdio>
using namespace std;
string strA, strB;
int minX = 0;
int nex[100005];
int findNex() {
int lenA = strA.length();
int lenB = strB.length();
minX = lenA < lenB ? lenA : lenB;
string strC = "";
strC += strA.substr(0, minX);
strC += strB.substr(lenB - minX, lenB);
int i = 1, j = 0;
while(i < strC.length()){
if(strC[i] == strC[j]){
nex[i++] = ++j;
}else if(j != 0){
j = nex[j - 1];
}else{
nex[i++] = 0;
}
}
return nex[strC.length() - 1];
}
int main() {
while(cin>>strA>>strB) {
int res = findNex();
if(res){
if(res > minX) res = minX;
for(int i = 0; i < res; i++){
cout<<strA[i];
}
cout<<" ";
}
cout<<res<<endl;
memset(nex, 0, sizeof(nex));
}
return 0;
}
那么俩字符串最长前后公共部分有什么用呢?其实它与回文串息息相关。
LeetCode 214. Shortest Palindrome
题目描述
You are given a string s. You can convert s to a palindrome by adding characters in front of it.
Return the shortest palindrome you can find by performing this transformation.
Example 1:
Input: s = “aacecaaa”
Output: “aaacecaaa”
Example 2:
Input: s = “abcd”
Output: “dcbabcd”
Constraints:
0 <= s.length <=
s consists of lowercase English letters only.
思路分析
我们需要在给定的字符串 s 的前面添加字符串 s’,得到最短的回文串。这里我们用 s’+s表示得到的回文串。显然,这等价于找到最短的字符串 s’使得 s’+s 是一个回文串。
由于我们一定可以将 s去除第一个字符后得到的字符串反序地添加在 s的前面得到一个回文串,因此一定有 |s’| < |s| ,其中 |s|表示字符串 s 的长度。
例如当 s=abccda 时,我们可以将 bccda 的反序 adccb 添加在前面得到回文串 adccb abccda。
这样一来,我们可以将 s分成两部分:
- 长度为 |s| - |s’|的前缀$ s_1$;
- 长度为 |s’|的后缀
。
即 。记
。记 为 s 的反序,那么最终得到的字符串
可以写成
的形式。
由于 s’+s 是一个回文串,那么 s’的反序就必然与 相同,并且
本身就是一个回文串。因此,要找到最短的 s’等价于找到最长的
。也就是说,我们需要在字符串 s 中超出一个最长的前缀
,它是一个回文串。当我们找到
后,剩余的部分即为
,其反序即为 s’ 。
考虑到 是一个回文串,因此
同样是
 的后缀。而
的后缀。而 可以写成
可以写成 的形式,故而
的形式,故而 。从而这道题其实就是寻找最长字符串
。从而这道题其实就是寻找最长字符串 ,使得
,使得 是即是字符串s的前缀,也是字符串
是即是字符串s的前缀,也是字符串 的后缀。
的后缀。
故而就是上述题目。这里需要注意的是,这里两个字符串长度相等。而且不能简单的把俩字符串拼接起来使用KMP算法。因为会有这种情况:
s = “aabba”,
= “aabbaabbaa”
这样next[s.length() - 1] = 6其实是超过字符串长度的,但这个时候整个字符串并不是回文串,存粹是因为s第一个字符和最后一个字符相同,这样拼起来后 前k个字符恰等于后k个字符的最大的k大于字符串本身长度。所以这种情况下处理应当采用中间插入特殊字符方式。
代码
class Solution {
public:
string shortestPalindrome(string s) {
if(s.length()==0)return s;
string s1;
s1.assign(s.rbegin(),s.rend());//reverse s
//find max common substring between the prefix of s and the suffix of s'
string pattern = s+"#"+s1; //join s,s'
vector<int> next = buildNext(pattern);
int prefix_length = next[pattern.length() - 1];
return prefix_length>=s.length()? s: s1.substr(0,s1.length() - prefix_length)+s;
}
vector<int> buildNext(string p){
vector<int> next(p.length());
int i = 1, now = 0;
next[0] = 0;
while(i<p.length()){
if(p[i]==p[now]){
next[i++] = ++now;
}else if (now == 0){
next[i++] = now;
}else{
now = next[now - 1];
}
}
return next;
}
};

若有收获,就点个赞吧
0 人点赞
