反转单链表的迭代实现不是一个困难的事情,但是递归实现就有点难度了,如果再加一点难度,让你仅仅反转单链表中的一部分,你是否能够递归实现呢?
本文就来由浅入深,step by step 地解决这个问题。如果你还不会递归地反转单链表也没关系,本文会从递归反转整个单链表开始拓展,只要你明白单链表的结构,相信你能够有所收获。
// 单链表节点的结构public class ListNode {int val;ListNode next;ListNode(int x) { val = x; }}
什么叫反转单链表的一部分呢,就是给你一个索引区间,让你把单链表中这部分元素反转,其他部分不变:

注意这里的索引是从 1 开始的。迭代的思路大概是:先用一个 for 循环找到第m个位置,然后再用一个 for 循环将m和n之间的元素反转。但是我们的递归解法不用任何 for 循环,纯递归实现反转。
迭代实现思路看起来虽然简单,但是细节问题很多的,反而不容易写对。相反,递归实现就很简洁优美,下面就由浅入深,先从反转整个单链表说起。
递归反转整个链表
这个算法可能很多读者都听说过,这里详细介绍一下,先直接看实现代码:
ListNode reverse(ListNode head) {
if (head.next == null) return head;
ListNode last = reverse(head.next);
head.next.next = head;
head.next = null;
return last;
}
看起来是不是感觉不知所云,完全不能理解这样为什么能够反转链表?这就对了,这个算法常常拿来显示递归的巧妙和优美,我们下面来详细解释一下这段代码。
对于递归算法,最重要的就是明确递归函数的定义。具体来说,我们的reverse函数定义是这样的:
输入一个节点**head**,将「以**head**为起点」的链表反转,并返回反转之后的头结点。
明白了函数的定义,再来看这个问题。比如说我们想反转这个链表:
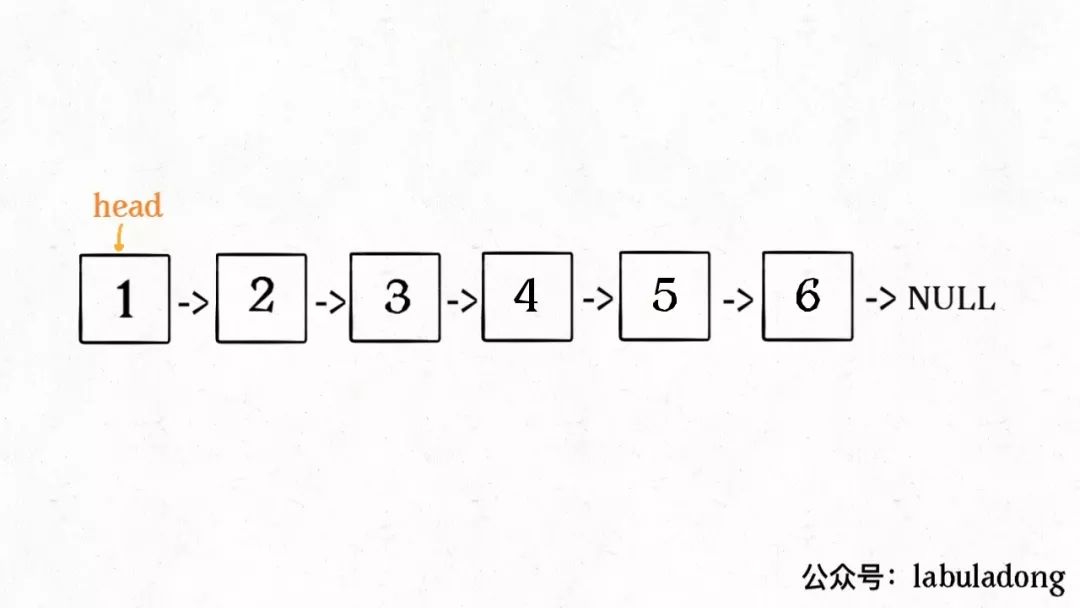
那么输入reverse(head)后,会在这里进行递归:
ListNode last = reverse(head.next);
不要跳进递归(你的脑袋能压几个栈呀?),而是要根据刚才的函数定义,来弄清楚这段代码会产生什么结果:
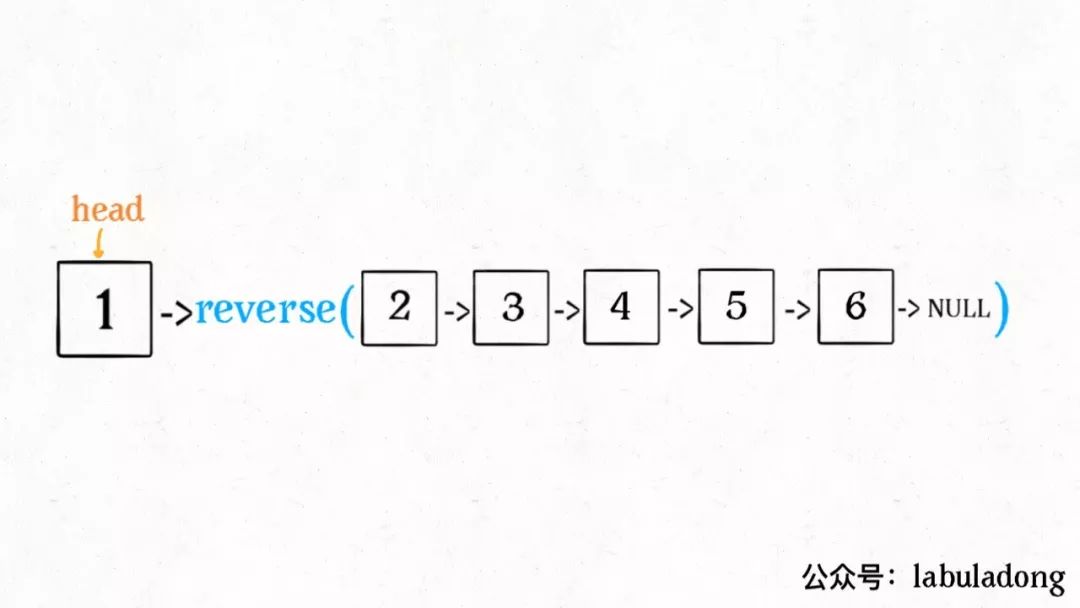
按照定义,这个reverse(head.next)执行完成后,整个链表应该变成了这样:
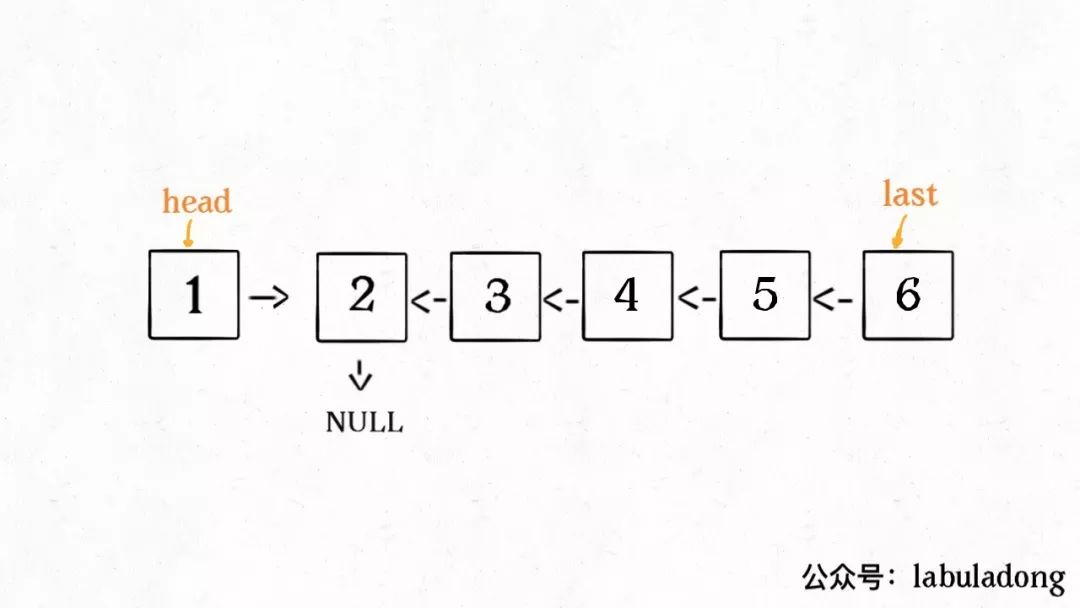
并且根据函数定义,reverse函数会返回反转之后的头结点,我们用变量last接收了。
现在再来看下面的代码:
head.next.next = head;
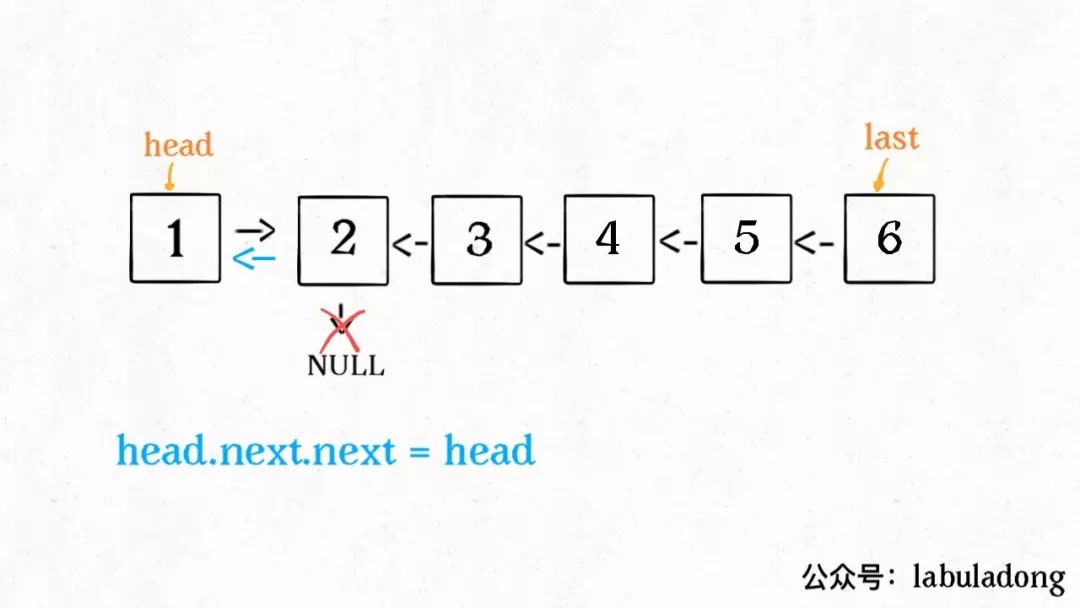
接下来进行的操作:
head.next = null;
return last;

神不神奇,这样整个链表就反转过来了!递归代码就是这么简洁优雅,不过其中有两个地方需要注意:
1、递归函数要有 base case,也就是这句:
if (head.next == null) return head;
意思是如果链表只有一个节点的时候反转也是它自己,直接返回即可。
2、当链表递归反转之后,新的头节点是**last**,而之前的**head**变成了最后一个节点,别忘了链表的末尾要指向 null:
head.next = null;
理解了这两点后,我们就可以进一步深入了,接下来的问题其实都是在这个算法上的扩展。
反转链表前 N 个节点
这次我们实现一个这样的函数:
// 将链表的前 n 个节点反转(n <= 链表长度)
ListNode reverseN(ListNode head, int n)
比如说对于下图链表,执行reverseN(head, 3):
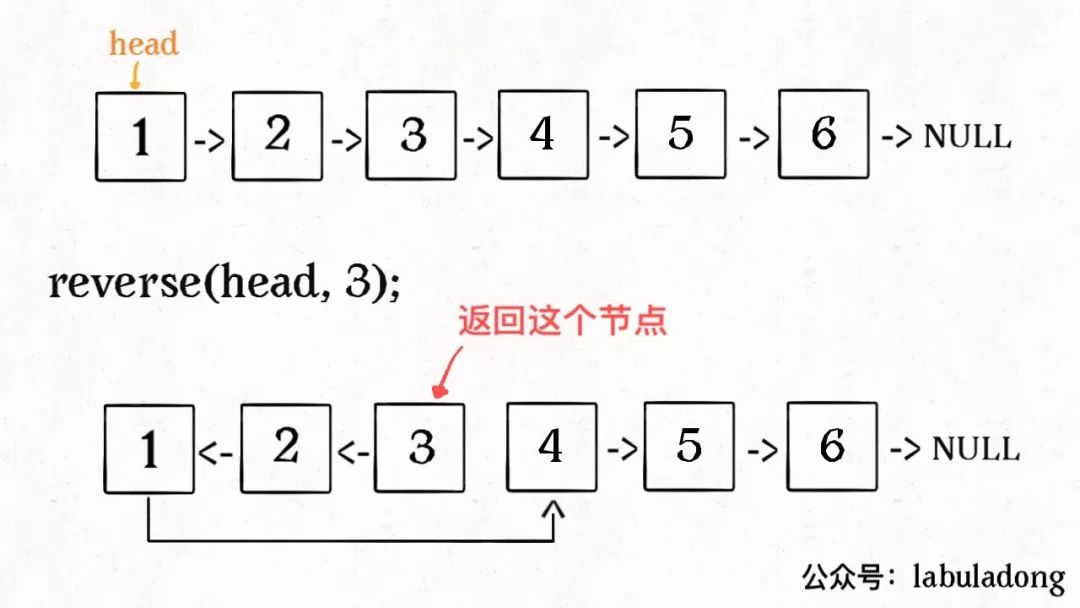
解决思路和反转整个链表差不多,只要稍加修改即可:
ListNode successor = null; // 后驱节点
// 反转以 head 为起点的 n 个节点,返回新的头结点
ListNode reverseN(ListNode head, int n) {
if (n == 1) {
// 记录第 n + 1 个节点
successor = head.next;
return head;
}
// 以 head.next 为起点,需要反转前 n - 1 个节点
ListNode last = reverseN(head.next, n - 1);
head.next.next = head;
// 让反转之后的 head 节点和后面的节点连起来
head.next = successor;
return last;
}
具体的区别:
1、base case 变为n == 1,反转一个元素,就是它本身,同时要记录后驱节点。
2、刚才我们直接把head.next设置为 null,因为整个链表反转后原来的head变成了整个链表的最后一个节点。但现在head节点在递归反转之后不一定是最后一个节点了,所以要记录后驱successor(第 n + 1 个节点),反转之后将head连接上。
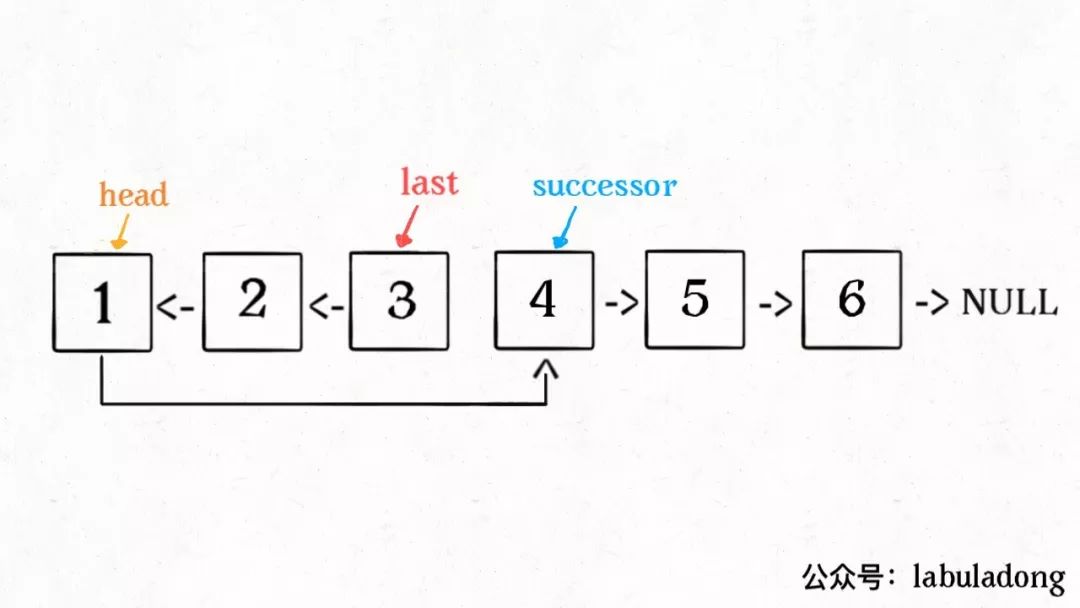
OK,如果这个函数你也能看懂,就离实现「反转一部分链表」不远了。
反转链表的一部分
现在解决我们最开始提出的问题,给一个索引区间[m,n](索引从 1 开始),仅仅反转区间中的链表元素。
ListNode reverseBetween(ListNode head, int m, int n)
首先,如果m == 1,就相当于反转链表开头的n个元素嘛,也就是我们刚才实现的功能:
ListNode reverseBetween(ListNode head, int m, int n) {
// base case
if (m == 1) {
// 相当于反转前 n 个元素
return reverseN(head, n);
}
// ...
}
如果m != 1怎么办?如果我们把head的索引视为 1,那么我们是想从第m个元素开始反转对吧;如果把head.next的索引视为 1 呢?那么相对于head.next,反转的区间应该是从第m - 1个元素开始的;那么对于head.next.next呢……
区别于迭代思想,这就是递归思想,所以我们可以完成代码:
ListNode reverseBetween(ListNode head, int m, int n) {
// base case
if (m == 1) {
return reverseN(head, n);
}
// 前进到反转的起点触发 base case
head.next = reverseBetween(head.next, m - 1, n - 1);
return head;
}
至此,我们的最终大 BOSS 就被解决了。
k 个一组反转链表

这个问题经常在面经中看到,而且 LeetCode 上难度是 Hard,它真的有那么难吗?
对于基本数据结构的算法问题其实都不难,只要结合特点一点点拆解分析,一般都没啥难点。下面我们就来拆解一下这个问题。
分析问题
首先,前文提到过,链表是一种兼具递归和迭代性质的数据结构,认真思考一下可以发现这个问题具有递归性质。
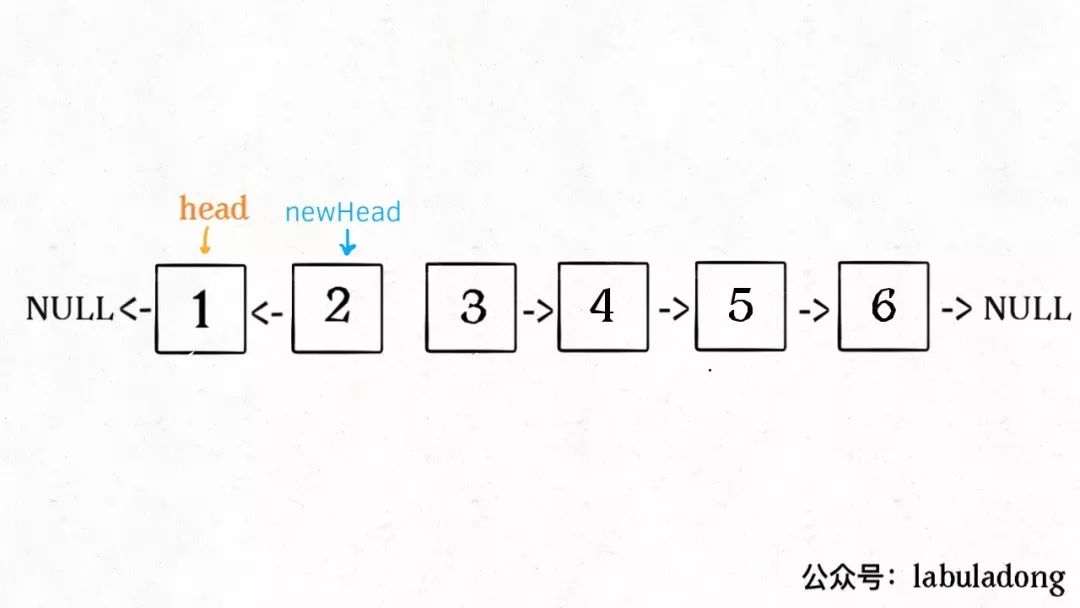
什么叫递归性质?直接上图理解,比如说我们对这个链表调用 reverseKGroup(head, 2),即以 2 个节点为一组反转链表:
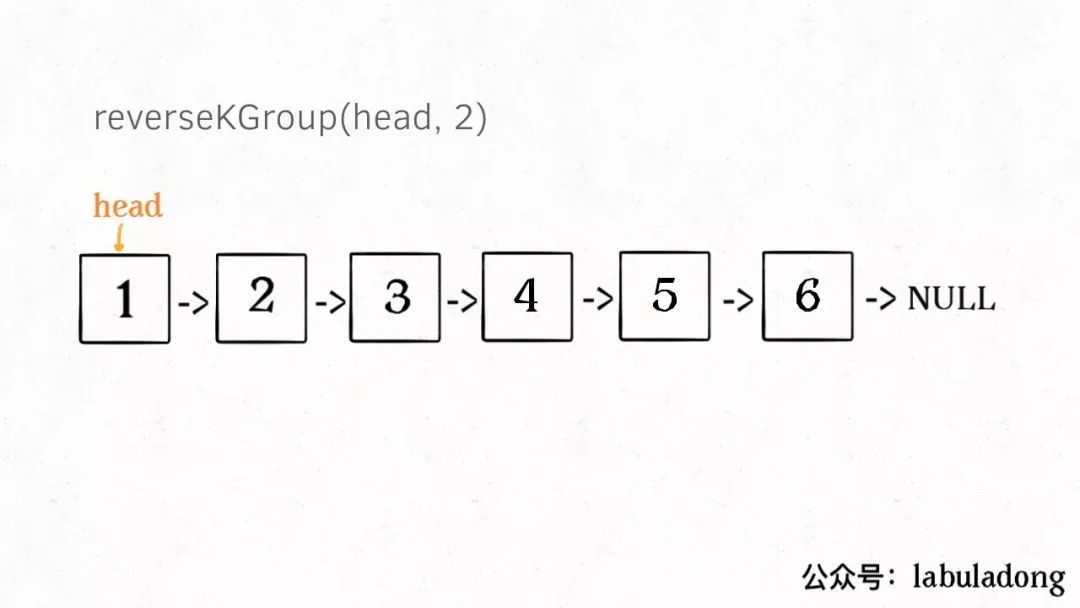
如果我设法把前 2 个节点反转,那么后面的那些节点怎么处理?后面的这些节点也是一条链表,而且规模(长度)比原来这条链表小,这就叫子问题。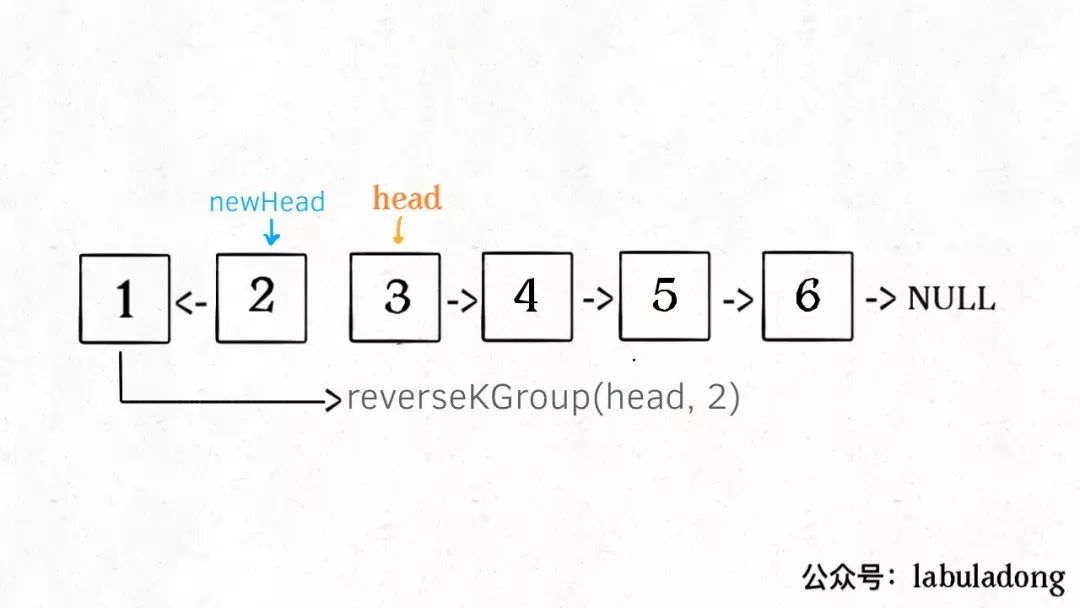
我们可以直接递归调用 reverseKGroup(head, 2),因为子问题和原问题的结构完全相同,这就是所谓的递归性质。
发现了递归性质,就可以得到大致的算法流程:
1、先反转以 **head** 开头的 **k** 个元素。
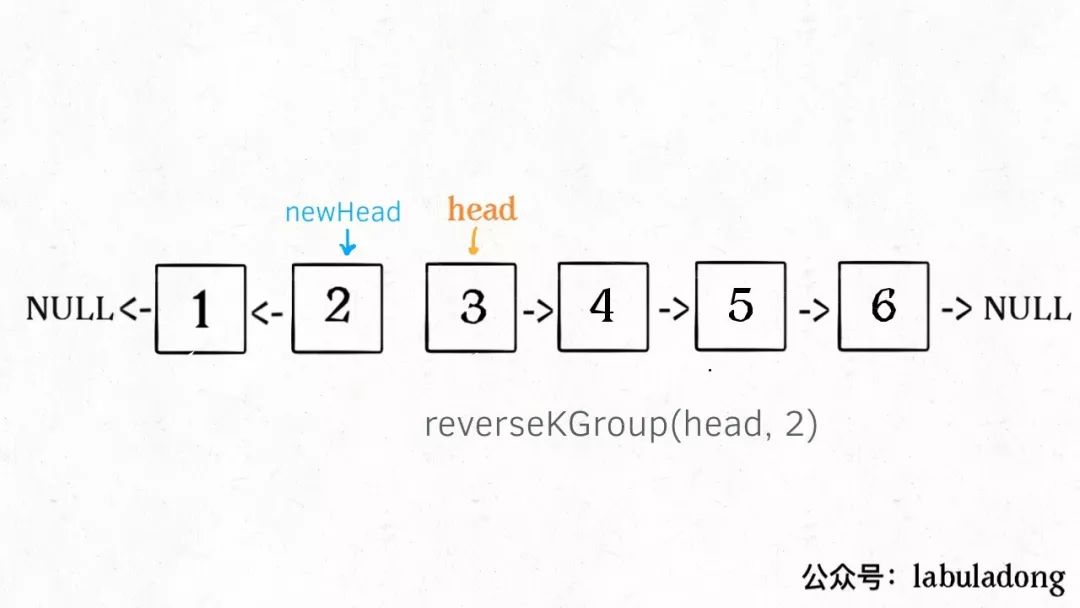
2、将第 **k + 1** 个元素作为 **head** 递归调用 **reverseKGroup** 函数。
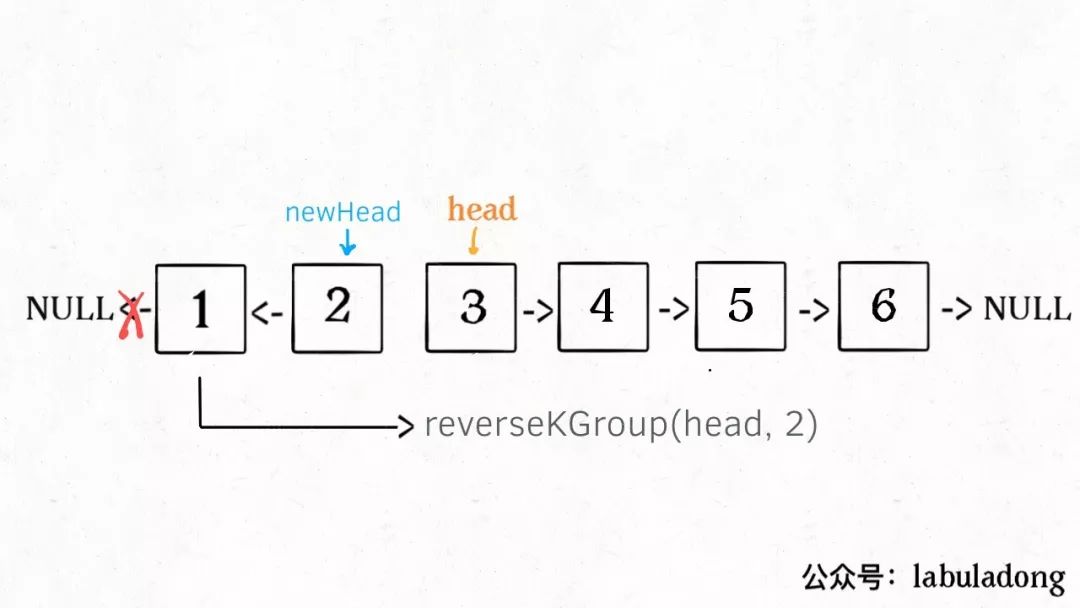
3、将上述两个过程的结果连接起来。
整体思路就是这样了,最后一点值得注意的是,递归函数都有个 base case,对于这个问题是什么呢?
题目说了,如果最后的元素不足 **k** 个,就保持不变。这就是 base case,待会会在代码里体现。
代码实现
首先,我们要实现一个 reverse 函数反转一个区间之内的元素。在此之前我们再简化一下,给定链表头结点,如何反转整个链表?
// 反转以 a 为头结点的链表
ListNode reverse(ListNode a) {
ListNode pre, cur, nxt;
pre = null; cur = a; nxt = a;
while (cur != null) {
nxt = cur.next;
// 逐个结点反转
cur.next = pre;
// 更新指针位置
pre = cur;
cur = nxt;
}
// 返回反转后的头结点
return pre;
}
这次使用迭代思路来实现的,借助动画理解应该很容易。

「反转以 a 为头结点的链表」其实就是「反转 a 到 null 之间的结点」,那么如果让你「反转 a 到 b 之间的结点」,你会不会?
只要更改函数签名,并把上面的代码中 null 改成 b 即可:
/** 反转区间 [a, b) 的元素,注意是左闭右开 */
ListNode reverse(ListNode a, ListNode b) {
ListNode pre, cur, nxt;
pre = null; cur = a; nxt = a;
// while 终止的条件改一下就行了
while (cur != b) {
nxt = cur.next;
cur.next = pre;
pre = cur;
cur = nxt;
}
// 返回反转后的头结点
return pre;
}
现在我们迭代实现了反转部分链表的功能,接下来就按照之前的逻辑编写 reverseKGroup 函数即可:
ListNode reverseKGroup(ListNode head, int k) {
if (head == null) return null;
// 区间 [a, b) 包含 k 个待反转元素
ListNode a, b;
a = b = head;
for (int i = 0; i < k; i++) {
// 不足 k 个,不需要反转,base case
if (b == null) return head;
b = b.next;
}
// 反转前 k 个元素
ListNode newHead = reverse(a, b);
// 递归反转后续链表并连接起来
a.next = reverseKGroup(b, k);
return newHead;
}
解释一下 for 循环之后的几句代码,注意 reverse 函数是反转区间 [a, b),所以情形是这样的:
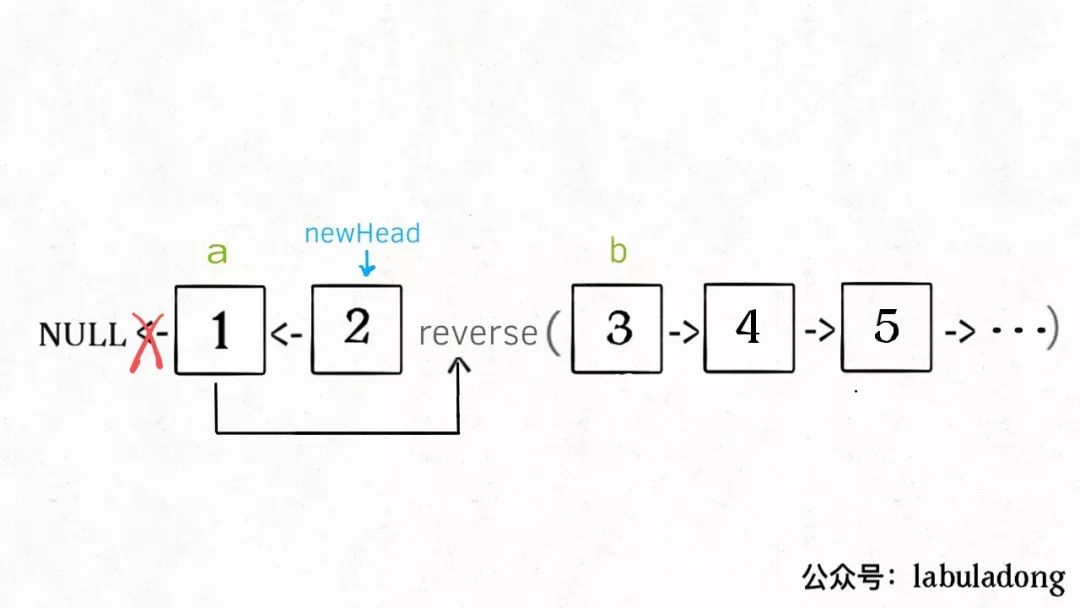
递归部分就不展开了,整个函数递归完成之后就是这个结果,完全符合题意:
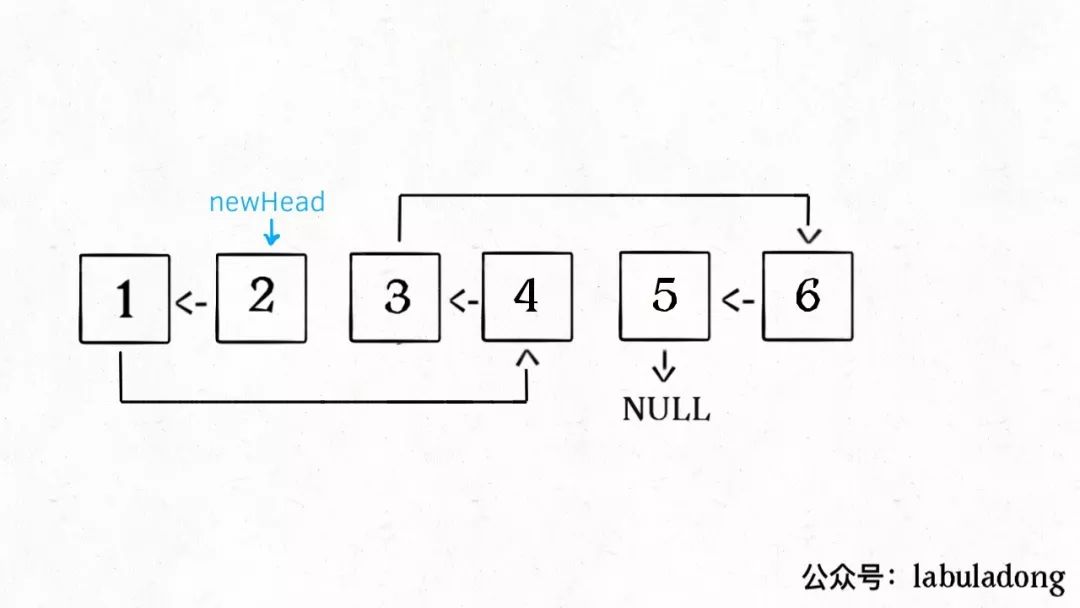
递归反向遍历链表
LeetCode 234. Palindrome Linked List
Given the head of a singly linked list, return true if it is a palindrome.
Example 1:
Input: head = [1,2,2,1]
Output: true
Example 2:
Input: head = [1,2]
Output: false
思路
为了想出使用空间复杂度为 #card=math&code=O%281%29&id=o0XS8) 的算法,你可能想过使用递归来解决,但是这仍然需要
#card=math&code=O%28n%29&id=kFgDy)的空间复杂度。
递归为我们提供了一种优雅的方式来方向遍历节点。
function print_values_in_reverse(ListNode head)
if head is NOT null
print_values_in_reverse(head.next)
print head.val
如果使用递归反向迭代节点,同时使用递归函数外的变量向前迭代,就可以判断链表是否为回文。
算法
currentNode 指针是先到尾节点,由于递归的特性再从后往前进行比较。frontPointer 是递归函数外的指针。若 currentNode.val != frontPointer.val 则返回 false。反之,frontPointer 向前移动并返回 true。
算法的正确性在于递归处理节点的顺序是相反的(回顾上面打印的算法),而我们在函数外又记录了一个变量,因此从本质上,我们同时在正向和逆向迭代匹配。
代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
ListNode* frontNode;
bool recursiveCheck(ListNode* head){
if(head==nullptr) return true;
if(!recursiveCheck(head->next)) return false;
if(head->val!=frontNode->val) return false;
frontNode = frontNode->next;
return true;
}
public:
bool isPalindrome(ListNode* head) {
frontNode = head;
return recursiveCheck(head);
}
};
最后总结
递归的思想相对迭代思想,稍微有点难以理解,处理的技巧是:不要跳进递归,而是利用明确的定义来实现算法逻辑。
处理看起来比较困难的问题,可以尝试化整为零,把一些简单的解法进行修改,解决困难的问题。
值得一提的是,递归操作链表并不高效。和迭代解法相比,虽然时间复杂度都是 O(N),但是迭代解法的空间复杂度是 O(1),而递归解法需要堆栈,空间复杂度是 O(N)。所以递归操作链表可以作为对递归算法的练习或者拿去和小伙伴装逼,但是考虑效率的话还是使用迭代算法更好。

若有收获,就点个赞吧
0 人点赞
