正则程序库(regex)
「正则表达式」就是一套表示规则的式子,专门用来处理各种复杂的操作。
std::regex是C用来表示「正则表达式」(regular expression)的库,于C11加入,它是class std::basic_regex<>针对char类型的一个特化,还有一个针对wchar_t类型的特化为std::wregex。
正则文法(regex syntaxes)
std::regex默认使用是ECMAScript文法,这种文法比较好用,且威力强大,常用符号的意义如下:
| 符号 | 意义 |
|---|---|
| ^ | 匹配行的开头 |
| $ | 匹配行的结尾 |
| . | 匹配任意单个字符 |
| […] | 匹配[]中的任意一个字符 |
| (…) | 设定分组 |
| \ | 转义字符 |
| \d | 匹配数字[0-9] |
| \D | \d 取反 |
| \w | 匹配字母[a-z],数字,下划线 |
| \W | \w 取反 |
| \s | 匹配空格 |
| \S | \s 取反 |
| + | 前面的元素重复1次或多次 |
| * | 前面的元素重复任意次 |
| ? | 前面的元素重复0次或1次 |
| {n} | 前面的元素重复n次 |
| {n,} | 前面的元素重复至少n次 |
| {n,m} | 前面的元素重复至少n次,至多m次 |
| | | 逻辑或 |
上面列出的这些都是非常常用的符号,靠这些便足以解决绝大多数问题了。
匹配(Match)
regex_match
字符串处理常用的一个操作是「匹配」,即字符串和规则恰好对应,而用于匹配的函数为std::regex_match(),它是个函数模板,我们直接来看例子:
std::regex reg("<.*>.*</.*>");bool ret = std::regex_match("<html>value</html>", reg);assert(ret);ret = std::regex_match("<xml>value<xml>", reg);assert(!ret);std::regex reg1("<(.*)>.*</\\1>");ret = std::regex_match("<xml>value</xml>", reg1);assert(ret);ret = std::regex_match("<header>value</header>", std::regex("<(.*)>value</\\1>"));assert(ret);// 使用basic文法std::regex reg2("<\\(.*\\)>.*</\\1>", std::regex_constants::basic);ret = std::regex_match("<title>value</title>", reg2);assert(ret);
这个小例子使用regex_match()来匹配xml格式(或是html格式)的字符串,匹配成功则会返回true,意思非常简单,若是不懂其中意思,可参照前面的文法部分。
对于语句中出现\,是因为\需要转义,C++11以后支持原生字符,所以也可以这样使用:
std::regex reg1(R"(<(.*)>.*</\1>)");auto ret = std::regex_match("<xml>value</xml>", reg1);assert(ret);
但C++03之前并不支持,所以使用时要需要留意。
获取匹配结果
若是想得到匹配的结果,可以使用regex_match()的另一个重载形式:
std::cmatch m;auto ret = std::regex_match("<xml>value</xml>", m, std::regex("<(.*)>(.*)</(\\1)>"));if (ret){std::cout << m.str() << std::endl;std::cout << m.length() << std::endl;std::cout << m.position() << std::endl;}std::cout << "----------------" << std::endl;// 遍历匹配内容for (auto i = 0; i < m.size(); ++i){// 两种方式都可以std::cout << m[i].str() << " " << m.str(i) << std::endl;}std::cout << "----------------" << std::endl;// 使用迭代器遍历for (auto pos = m.begin(); pos != m.end(); ++pos){std::cout << *pos << std::endl;}
输出结果为:
<xml>value</xml>160----------------<xml>value</xml> <xml>value</xml>xml xmlvalue valuexml xml----------------<xml>value</xml>xmlvaluexml
cmatch是class template std::match_result<>针对C字符的一个特化版本,若是string,便得用针对string的特化版本smatch。同时还支持其相应的宽字符版本wcmatch和wsmatch。
在regex_match()的第二个参数传入match_result便可获取匹配的结果,在例子中便将结果储存到了cmatch中,而cmatch又提供了许多函数可以对这些结果进行操作,大多方法都和string的方法类似,所以使用起来比较容易。
m[0]保存着匹配结果的所有字符,若想在匹配结果中保存所有子串,则得在「正则表达式」中用()标出子串,所以这里多加了几个括号:
std::regex("<(.*)>(.*)</(\\1)>")
这样这些子串就会依次保存在m[0]的后面,即可通过m[1],m[2],…依次访问到各个子串。
sregex_iterator。
regex iterator有助于迭代“匹配合格”之子序列,当你打算将string拆分为一个个语法单元(token)或以某种内容分割string,分隔符甚至可能被指定为一个正则表达式。
regex_token_iterator就提供了这样的功能。将它初始化,需要把字符序列的起点和终点,以及一个正则表达式传递给这个迭代器,同时还要指定整数表示语法化过程中的元素:
- -1 : 表示对分隔符之间的子序列感兴趣
- 0 : 表示你对每一个正则表达式或分隔符感兴趣
- 其他表示你对正则表达式中第n个匹配次表达式感兴趣。
| \w | 匹配字母、数字、下划线。等价于 [A-Za-z0-9_]
 |
| —- | —- |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。
|
| —- | —- |
| ( ) | 标记一个子表达式的开始和结束位置。子表达式可以获取供以后使用。
要匹配这些字符,请使用 \( 和 \)。
如:<(.)>(.)</(\\1)> 引用第一组的文本内容 |
* 和 +限定符都是贪婪的,因为它们会尽可能多的匹配文字,只有在它们的后面加上一个 ? 就可以实现非贪婪或最小匹配。
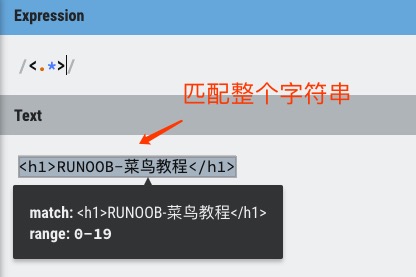
例如,您可能搜索 HTML 文档,以查找在 h1 标签内的内容。HTML 代码如下:
<h1>RUNOOB-菜鸟教程</h1>
贪婪:下面的表达式匹配从开始小于符号 (<) 到关闭 h1 标记的大于符号 (>) 之间的所有内容。
/<.*>/
非贪婪:如果您只需要匹配开始和结束 h1 标签,下面的非贪婪表达式只匹配
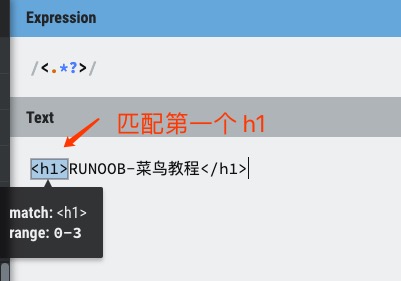
/<.*?>/
例子:
#include <iostream>#include <string>#include <regex>using namespace std;int main(int argc,char *argv[]){string data = "<person>\n""<first>Nano</first>\n""<second>Nike</second>\n""</person>\n";regex reg("<(.*)>(.*)</(\\1)>");sregex_token_iterator spos(data.begin(),data.end(),reg, // regex{0,2}); // 0: full match 2:second substringsregex_token_iterator end;for(;spos != end;++spos){cout << "match: " << spos->str() << endl;}string names = "nico,jim,helmut,paul,tim,john,paul,rita";regex sep("[ \t\n]*[,;:][ \t\n]*");sregex_token_iterator stpos(names.begin(),names.end(),sep,-1);sregex_token_iterator e;for(;stpos!=e;++stpos){cout << "names : " << stpos->str() << endl;}}
输出结果
match: <first>Nano</first>match: Nanomatch: <second>Nike</second>match: Nikenames : niconames : jimnames : helmutnames : paulnames : timnames : johnnames : paulnames : rita
如果语法元素只指定{0},那么输出结果:
match: <first>Nano</first>match: <second>Nike</second>names : niconames : jimnames : helmutnames : paulnames : timnames : johnnames : paulnames : rita
不区分大小写
对于两段文本
这句话里有two个word。这句话里有tWo个WoRd。
我希望用同一个正则表达式将其中的单词two、word、tWo、WoRd提取出来
这时候就须要用到不区分大小写的匹配模式。
#include <iostream>
#include <regex>
using namespace std;
int main()
{
string text = "这句话里有two个word。";
regex re("[a-z]+");
sregex_iterator itr1(text.begin(), text.end(), re);
sregex_iterator itr2;
for (sregex_iterator itr = itr1; itr != itr2; ++itr)
{
cout << itr->str() << endl;
}
string text2 = "这句话里有tWo个WoRd。";
regex re2("[a-z]+", regex_constants::icase); //不区分大小写的匹配
sregex_iterator beginIterator(text2.begin(), text2.end(), re2);
sregex_iterator endIterator;
for (sregex_iterator itr = beginIterator; itr != endIterator; ++itr)
{
cout << itr->str() << endl;
}
return 0;
}
搜索(Search)
「搜索」与「匹配」非常相像,其对应的函数为std::regex_search,也是个函数模板,用法和regex_match一样,不同之处在于「搜索」只要字符串中有目标出现就会返回,而非完全「匹配」。
还是以例子来看:
std::regex reg("<(.*)>(.*)</(\\1)>");
std::cmatch m;
auto ret = std::regex_search("123<xml>value</xml>456", m, reg);
if (ret)
{
for (auto& elem : m)
std::cout << elem << std::endl;
}
std::cout << "prefix:" << m.prefix() << std::endl;
std::cout << "suffix:" << m.suffix() << std::endl;
输出为:
<xml>value</xml>
xml
value
xml
prefix:123
suffix:456
这儿若换成regex_match匹配就会失败,因为regex_match是完全匹配的,而此处字符串前后却多加了几个字符。
对于「搜索」,在匹配结果中可以分别通过prefix和suffix来获取前缀和后缀,前缀即是匹配内容前面的内容,后缀则是匹配内容后面的内容。
那么若有多组符合条件的内容又如何得到其全部信息呢?这里依旧通过一个小例子来看:
std::regex reg("<(.*)>(.*)</(\\1)>");
std::string content("123<xml>value</xml>456<widget>center</widget>hahaha<vertical>window</vertical>the end");
std::smatch m;
auto pos = content.cbegin();
auto end = content.cend();
for (; std::regex_search(pos, end, m, reg); pos = m.suffix().first)
{
std::cout << "----------------" << std::endl;
std::cout << m.str() << std::endl;
std::cout << m.str(1) << std::endl;
std::cout << m.str(2) << std::endl;
std::cout << m.str(3) << std::endl;
}
输出结果为:
----------------
<xml>value</xml>
xml
value
xml
----------------
<widget>center</widget>
widget
center
widget
----------------
<vertical>window</vertical>
vertical
window
vertical
此处使用了regex_search函数的另一个重载形式(regex_match函数亦有同样的重载形式),实际上所有的子串对象都是从std::pair<>派生的,其first(即此处的prefix)即为第一个字符的位置,second(即此处的suffix)则为最末字符的下一个位置。
一组查找完成后,便可从suffix处接着查找,这样就能获取到所有符合内容的信息了。
分词(Tokenize)
还有一种操作叫做「切割」,例如有一组数据保存着许多邮箱账号,并以逗号分隔,那就可以指定以逗号为分割符来切割这些内容,从而得到每个账号。
而在C++的正则中,把这种操作称为Tokenize,用模板类regex_token_iterator<>提供分词迭代器,依旧通过例子来看:
std::string mail("123@qq.vip.com,456@gmail.com,789@163.com,abcd@my.com");
std::regex reg(",");
std::sregex_token_iterator pos(mail.begin(), mail.end(), reg, -1);
decltype(pos) end;
for (; pos != end; ++pos)
{
std::cout << pos->str() << std::endl;
}
这样,就能通过逗号分割得到所有的邮箱:
123@qq.vip.com
456@gmail.com
789@163.com
abcd@my.com
sregex_token_iterator是针对string类型的特化,需要注意的是最后一个参数,这个参数可以指定一系列整数值,用来表示你感兴趣的内容,此处的-1表示对于匹配的正则表达式之前的子序列感兴趣;而若指定0,则表示对于匹配的正则表达式感兴趣,这里就会得到“,”;还可对正则表达式进行分组,之后便能输入任意数字对应指定的分组,大家可以动手试试。
替换(Replace)
最后一种操作称为「替换」,即将正则表达式内容替换为指定内容,regex库用模板函数std::regex_replace提供「替换」操作。
现在,给定一个数据为”he…ll..o, worl..d!”, 思考一下,如何去掉其中误敲的“.”?
有思路了吗?来看看正则的解法:
char data[] = "he...ll..o, worl..d!";
std::regex reg("\\.");
// output: hello, world!
std::cout << std::regex_replace(data, reg, "");
我们还可以使用分组功能:
char data[] = "001-Neo,002-Lucia";
std::regex reg("(\\d+)-(\\w+)");
// output: 001 name=Neo,002 name=Lucia
std::cout << std::regex_replace(data, reg, "$1 name=$2");
当使用分组功能后,可以通过$N来得到分组内容,这个功能挺有用的。

若有收获,就点个赞吧
0 人点赞
