背景
在信息学竞赛中,我们经常会碰到一些跟区间有关的问题,比如给一些区间线段求并区间的长度,或者并区间的个数等等。这些问题的描述都非常简单,但是通常情况下数据范围会非常大,而朴素方法的时间复杂度过高,导致不能在规定时间内得到问题的解。这时,我们需要一种高效的数据结构来处理这样的问题,在本文中,我们介绍一种基于分治思想的数据结构—-线段树(Interval Tree)。
简介
线段树(interval tree)是一种二叉树形结构,属于平衡树的一种。它将线段区间组织成树形的结构,并用每个节点来表示一条线段。一棵[1,10)的线段树的结构如图1.1所示: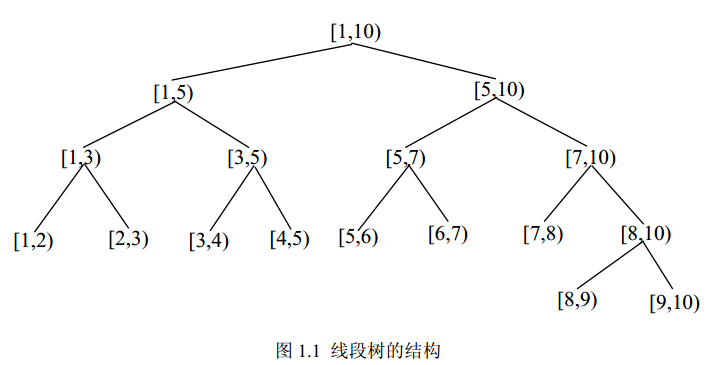
可以看到,线段树的每个节点表示了一条前闭后开,即[a,b)的线段,这样表示的好处在于,有时候处理的区间并不是连续区间,可能是离散的点,如数组等。这样就可以用**[a,a+1)**的节点来表示一个数组的元素a,做到连续与离散的统一。
由图1.1可见,线段树的根节点表示了所要处理的最大线段区间,而叶节点则表示了形如**[a,a+1)**的单位区间。对于每个非叶节点(包括根节点)所表示的区间[s,t),令**m = (s + t) / 2**,则其左儿子节点表示区间**[s,m)**,右儿子节点表示区间**[m,t)**。这样建树的好处在于,对于每条要处理的线段,可以类似“二分”的进入线段树中处理,使得时间复杂度在O(logN)量级,这也是线段树之所以高效的原因。
性质
线段树具有如下一些性质:
- 线段树是一个平衡树,树的高度为logN。
- 线段树把区间上的任意一条长度为L的线段都分成不超过2logL条线段的并。
- 线段树同一层的节点所代表的区间,相互不会重叠。
- 线段树任两个结点要么是包含关系要么没有公共部分, 不可能部分重叠
- 给定一个叶子p, 从根到p路径上所有结点代表的区间都包含点p, 且其他结点代表的区间都不包含点p
- 线段树叶子节点的区间是单位长度,不能再分了。
基本存储结构
// 线段树节点struct IntervalTreeNode{int left,right,mid;// 表示是否被覆盖bool cover;};
其中,left 和right分别代表该节点所表示线段的左右端点,即当前节点所表示的线段为[left, right)。而mid = (left + right) / 2,为当前线段的中点,储存这个点的好处是在每次在当前节点需要对线段分解的时候不需要再计算中点。
这只是线段树节点的基本结构,在实际解决问题时,我们需要对应各种题目,在节点中添加各种数据域来保存有用的信息,比如添加cover域来保存当前节点所表示的线段是否被覆盖等等。根据题目来添加适当的数据域以及对其进行维护是线段树解题的精髓所在,我们在平时的做题中需要注意积累用法,并进行推广扩展,做到举一反三。
基本操作
// 由线段树的性质可知,建树所需要的空间大概是所需处理// 最长线段长度的2倍多,所以需要开3倍大小的数组IntervalTreeNode intervalTree[3 * MAX];
线段树的建立操作
在对线段树进行操作前,我们需要建立起线段树的结构。我们使用结构体数组来保存线段树,这样对于非叶节点,若它在数组中编号为num,则其左右子节点的编号为**2*num** ,**2*num + 1**。由于线段树是二分的树型结构,我们可以用递归的方法,从根节点开始来建立一棵线段树。代码如下所示:
// left,right分别为当前节点的左右端点,num为节点在数组中的编号void Create(int left,int right,int num){intervalTree[num].left = left;intervalTree[num].right = right;intervalTree[num].mid = (left + right) / 2;intervalTree[num].cover = false;// 若不为叶子节点,则递归的建立左右子树if(left + 1 != right){Create(left,intervalTree[num].mid,2*num);Create(intervalTree[num].mid,right,2*num+1);}//if}
对应不同的题目,我们会在线段树节点中添加另外的数据域,并随着线段的插入或删除进行维护,要注意在建树过程中将这些数据域初始化。
线段树的插入(覆盖)操作
为了在插入线段后,我们能知道哪些节点上的线段被插入(覆盖)过。我们需要在节点中添加一个cover域,来记录当前节点所表示的线段是否被覆盖。这样,在建树过程中,我们需要把每个节点的cover域置0;
如图1.2所示,在线段的插入过程中,我们从根节点开始插入,同样采取递归的方法。如果插入的线段完全覆盖了当前节点所代表的线段,则将当前节点的cover 域置1并返回。否则,将线段递归进入当前节点的左右子节点进行插入。代码如下:
// 插入void Insert(int left,int right,int num){// 若插入的线段完全覆盖当前节点所表示的线段if(intervalTree[num].left == left && intervalTree[num].right == right){intervalTree[num].cover = 1;return;}//if// 当前节点的左子节点所代表的线段包含插入的线段if(right <= intervalTree[num].mid){Insert(left,right,2*num);}//if// 当前节点的右子节点所代表的线段包含插入的线段else if(left >= intervalTree[num].mid){Insert(left,right,2*num+1);}//if// 插入的线段跨越了当前节点所代表线段的中点else{Insert(left,intervalTree[num].mid,2*num);Insert(intervalTree[num].mid,right,2*num+1);}//else}
要注意,这样插入线段时,有可能出现以下这种情况,即先插入线段[1,3),再插入线段[1,5),如图1.3所示。这样,代表线段[1,3)的节点以及代表线段[1,5)的节点的cover值均为1,但是在统计时,遇到这种情况,我们可以只统计更靠近根节点的节点,因为这个节点所代表的线段包含了其子树上所有节点所代表的线段。
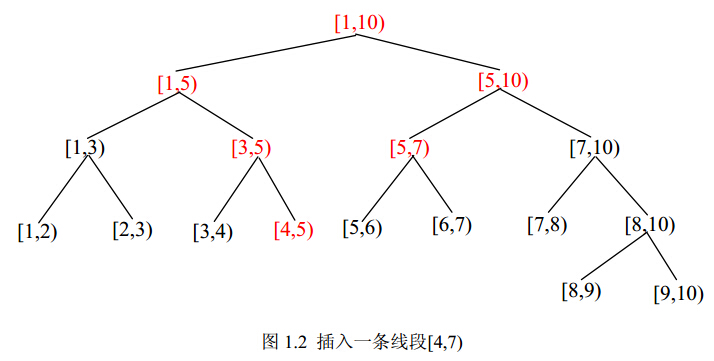
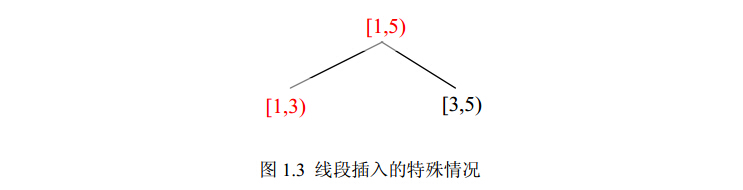
线段树的删除操作
线段树的删除操作跟插入操作不大相同,因为一条线段只有被插入过才能被删除。比如插入一条线段[3,10),则只能删除线段[4,6),不能删除线段[7,12)。当删除未插入的线段时,操作返回false值。
我们一样采用递归的方法对线段进行删除,如果当前节点所代表的线段未被覆盖,即cover值为0,则递归进入此节点的左右子节点进行删除。如果当前节点所代表的线段已被覆盖,即cover值为1,则要考虑两种情况。
一是删除的线段完全覆盖当前节点所代表的线段,则将当前节点的cover值置0。由于我们在插入线段的时候会出现图1.3所示的情况, 所以我们应该递归的在当前节点的子树上所有节点删除线段。
另一种情况是删除的线段未完全覆盖当前节点所代表的线段,比如当前节点代表的线段为[1,10),而要删除的线段为[4,7),则删除后剩下线段[1,4)和[7,10),我们采用的方法是,将当前节点的cover置0,并将其左右子节点的cover置1,然后递归的进入左右子节点进行删除。
// 删除bool Delete(int left,int right,int num){// 删除到叶节点的情况if(intervalTree[num].left + 1 == intervalTree[num].right){int cover = intervalTree[num].cover;intervalTree[num].cover = 0;return cover;}//if// 当前节点不为叶节点且被覆盖if(intervalTree[num].cover == 1){intervalTree[num].cover = 0;intervalTree[2*num].cover = 1;intervalTree[2*num+1].cover = 1;}//if// 左子节点if(right <= intervalTree[num].mid){return Delete(left,right, 2*num);}//if// 右子节点else if(left >= intervalTree[num].mid){return Delete(left,right,2*num+1);}//else// 跨越左右子节点else{return Delete(left,intervalTree[num].mid,2*num) &&Delete(intervalTree[num].mid,right,2*num+1);}//else}
相对插入操作,删除操作比较复杂,需要考虑的情况很多,稍有不慎就会出错,在比赛中写删除操作时务必联系插入操作的实现过程,仔细思考,才能避免错误。
线段树的统计操作
对应不同的问题,线段树会统计不同的数据,比如线段覆盖的长度,线段覆盖连续区间的个数等等。其实现思路不尽相同,我们以下以统计线段覆盖长度为例,简要介绍线段树统计信息的过程。文章之后的章节会讲解一些要用到线段树的题目,并会详细介绍线段树的用法,以及各种信息的统计过程。
对于统计线段覆盖长度的问题,可以采用以下的思路来统计信息,即从根节点开始搜索整棵线段树,如果当前节点所代表的线段已被覆盖,则将统计长度加上当前线段长度。否则,递归进入当前节点的左右子节点进行统计。实现代码如下:
// 覆盖长度
int CoverLen(int num){
IntervalTreeNode node = intervalTree[num];
// 如果当前节点所代表的线段已被覆盖,
// 则将统计长度加上当前线段长度。
if(node.cover){
return node.right - node.left;
}//if
// 当遍历到叶节点时返回
if(node.left + 1 == node.right){
return 0;
}//if
// 递归进入当前节点的左右子节点进行计算
return CoverLen(2*num) + CoverLen(2*num+1);
}
#include <iostream>
#include <algorithm>
using namespace std;
#define MAX 10
// 线段树节点
struct IntervalTreeNode{
int left,right,mid;
// 表示是否被覆盖
bool cover;
};
// 由线段树的性质可知,建树所需要的空间大概是所需处理
// 最长线段长度的2倍多,所以需要开3倍大小的数组
IntervalTreeNode intervalTree[3 * MAX];
// 创建线段树
// left,right分别为当前节点的左右端点,num为节点在数组中的编号
void Create(int left,int right,int num){
intervalTree[num].left = left;
intervalTree[num].right = right;
intervalTree[num].mid = (left + right) / 2;
intervalTree[num].cover = false;
// 若不为叶子节点,则递归的建立左右子树
if(left + 1 != right){
Create(left,intervalTree[num].mid,2*num);
Create(intervalTree[num].mid,right,2*num+1);
}//if
}
// 插入
void Insert(int left,int right,int num){
// 若插入的线段完全覆盖当前节点所表示的线段
if(intervalTree[num].left == left && intervalTree[num].right == right){
intervalTree[num].cover = 1;
return;
}//if
// 当前节点的左子节点所代表的线段包含插入的线段
if(right <= intervalTree[num].mid){
Insert(left,right,2*num);
}//if
// 当前节点的右子节点所代表的线段包含插入的线段
else if(left >= intervalTree[num].mid){
Insert(left,right,2*num+1);
}//if
// 插入的线段跨越了当前节点所代表线段的中点
else{
Insert(left,intervalTree[num].mid,2*num);
Insert(intervalTree[num].mid,right,2*num+1);
}//else
}
// 删除
bool Delete(int left,int right,int num){
// 删除到叶节点的情况
if(intervalTree[num].left + 1 == intervalTree[num].right){
int cover = intervalTree[num].cover;
intervalTree[num].cover = 0;
return cover;
}//if
// 当前节点不为叶节点且被覆盖
if(intervalTree[num].cover == 1){
intervalTree[num].cover = 0;
intervalTree[2*num].cover = 1;
intervalTree[2*num+1].cover = 1;
}//if
// 左子节点
if(right <= intervalTree[num].mid){
return Delete(left,right, 2*num);
}//if
// 右子节点
else if(left >= intervalTree[num].mid){
return Delete(left,right,2*num+1);
}//else
// 跨越左右子节点
else{
return Delete(left,intervalTree[num].mid,2*num) &&
Delete(intervalTree[num].mid,right,2*num+1);
}//else
}
// 覆盖长度
int CoverLen(int num){
IntervalTreeNode node = intervalTree[num];
// 如果当前节点所代表的线段已被覆盖,
// 则将统计长度加上当前线段长度。
if(node.cover){
return node.right - node.left;
}//if
// 当遍历到叶节点时返回
if(node.left + 1 == node.right){
return 0;
}//if
// 递归进入当前节点的左右子节点进行计算
return CoverLen(2*num) + CoverLen(2*num+1);
}
int main() {
int x[] = {1,2,5};
int y[] = {3,4,6};
// 创建[1,10]区间的线段树
Create(1,10,1);
// 插入
for(int i = 0;i < 3;++i){
Insert(x[i],y[i],1);
}//for
// 删除
Delete(2,3,1);
/*for(int i = 1;i < 3*MAX;++i){
cout<<"["<<intervalTree[i].left<<","<<intervalTree[i].right<<"]"<<"->"<<intervalTree[i].cover<<endl;
}//for*/
// 覆盖长度
int len = CoverLen(1);
cout<<len<<endl;
}
应用
单点更新
最基础的线段树,只更新叶子节点,然后回溯更新其父亲结点。
[HDU][线段树]1166.敌兵布阵
[HDU][线段树]1754.I Hate It
成段更新
需要用到延迟标记(或者说懒惰标记),简单来说就是每次更新的时候不要更新到底,用延迟标记使得更新延迟到下次需要更新or询问到的时候。
区间合并
这类题目会询问区间中满足条件的连续最长区间,所以回溯的时候需要对左右儿子的区间进行合并。
扫描线
这类题目需要将一些操作排序,然后从左到右用一根扫描线(当然是在我们脑子里)扫过去。
最典型的就是矩形面积并,周长并等题。
扫描线应用
例题:LeetCode 218 The Skyline Problem
A city’s skyline is the outer contour of the silhouette formed by all the buildings in that city when viewed from a distance. Given the locations and heights of all the buildings, return the skyline formed by these buildings collectively.
The geometric information of each building is given in the array buildings where buildings[i] = [lefti, righti, heighti]:
- $left_i $is the x coordinate of the left edge of the
building.
- $right_i $is the x coordinate of the right edge of the
building.
is the height of the$ i^{th} $building.
You may assume all buildings are perfect rectangles grounded on an absolutely flat surface at height 0.
The skyline should be represented as a list of “key points” sorted by their x-coordinate in the form [[x1,y1],[x2,y2],...]. Each key point is the left endpoint of some horizontal segment in the skyline except the last point in the list, which always has a y-coordinate 0 and is used to mark the skyline’s termination where the rightmost building ends. Any ground between the leftmost and rightmost buildings should be part of the skyline’s contour.
Note: There must be no consecutive horizontal lines of equal height in the output skyline. For instance,[...,[2 3],[4 5],[7 5],[11 5],[12 7],...]is not acceptable; the three lines of height 5 should be merged into one in the final output as such: [...,[2 3],[4 5],[12 7],...]
Example 1:
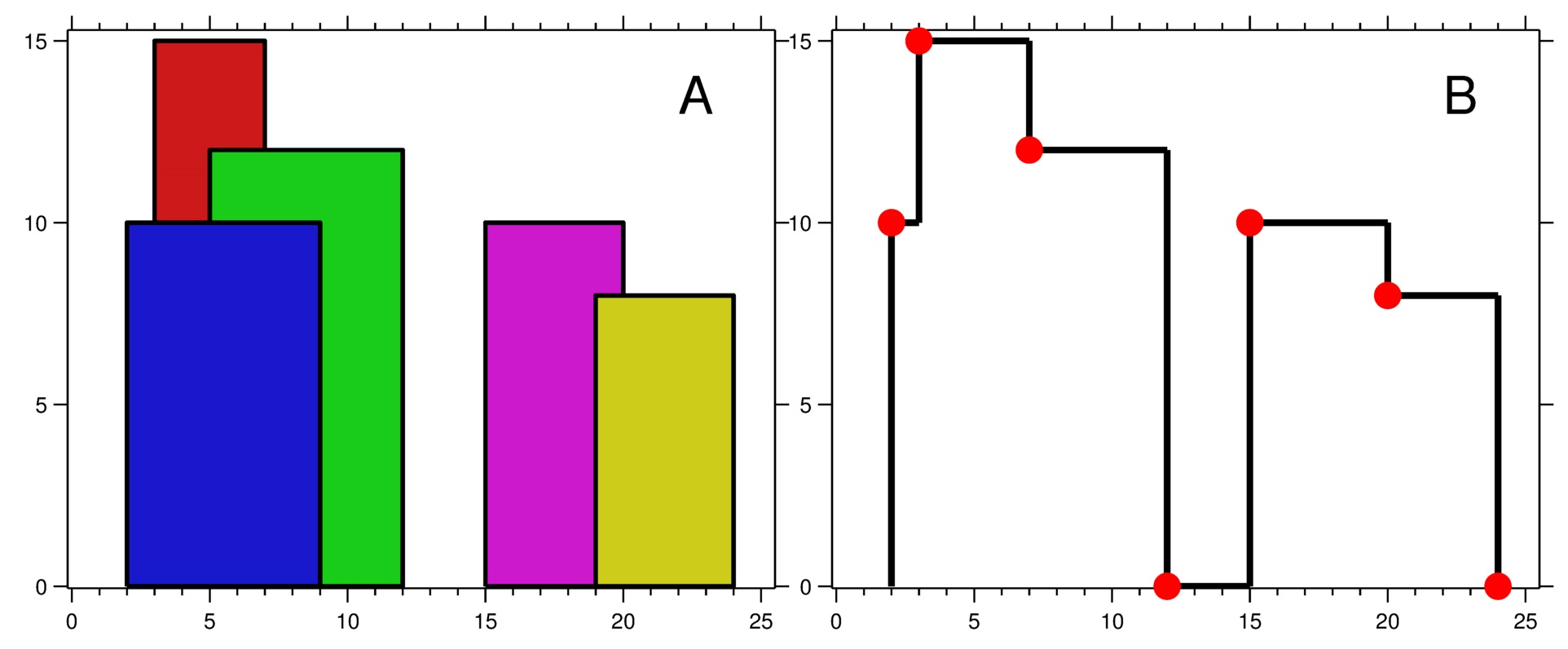
Input: buildings =
[[2,9,10],[3,7,15],[5,12,12],[15,20,10],[19,24,8]]Output:
[[2,10],[3,15],[7,12],[12,0],[15,10],[20,8],[24,0]]Explanation:
Figure A shows the buildings of the input.
Figure B shows the skyline formed by those buildings. The red points in figure B represent the key points in the output list.
Example 2:
Input: buildings =
[[0,2,3],[2,5,3]]
Output:[[0,3],[5,0]]
扫描线思路及算法
观察题目我们可以发现,关键点的横坐标总是落在建筑的左右边缘上。这样我们可以只考虑每一座建筑的边缘作为横坐标,这样其对应的纵坐标为「包含该横坐标」的所有建筑的最大高度。
观察示例一可以发现,当关键点为某建筑的右边缘时,该建筑的高度对关键点的纵坐标是没有贡献的。例如图中横坐标为 77 的关键点,虽然它落在红色建筑的右边缘,但红色建筑对其并纵坐标并没有贡献。因此我们给出「包含该横坐标」的定义:建筑的左边缘小于等于该横坐标,右边缘大于该横坐标(也就是我们不考虑建筑的右边缘)。即对于包含横坐标 x 的建筑 ,有
#card=math&code=x%E2%88%88%5Bleft_i%2Cright_i%29&id=KiWTN)。
特别地,在部分情况下,「包含该横坐标」的建筑并不存在。例如当图中只有一座建筑时,该建筑的左右边缘均对应一个关键点,当横坐标为其右边缘时,这唯一的建筑对其纵坐标没有贡献。因此该横坐标对应的纵坐标的大小为 0。
这样我们可以想到一个暴力的算法:#card=math&code=O%28n%29&id=ZRdCB)地枚举建筑的每一个边缘作为关键点的横坐标,过程中我们
#card=math&code=O%28n%29&id=rgTJz)地检查每一座建筑是否「包含该横坐标」,找到最大高度,即为该关键点的纵坐标。该算法的时间复杂度是
#card=math&code=O%28n%5E2%29&id=D4k3U),我们需要进行优化。
我们可以用优先队列来优化寻找最大高度的时间,在我们从左到右枚举横坐标的过程中,实时地更新该优先队列即可。这样无论何时,优先队列的队首元素即为最大高度。为了维护优先队列,我们需要使用「延迟删除」的技巧,即我们无需每次横坐标改变就立刻将优先队列中所有不符合条件的元素都删除,而只需要保证优先队列的队首元素「包含该横坐标」即可。
具体地,为了按顺序枚举横坐标,我们用数组 保存所有的边缘,排序后遍历该数组即可。过程中,我们首先将「包含该横坐标」的建筑加入到优先队列中,然后不断检查优先队列的队首元素是否「包含该横坐标」,如果不「包含该横坐标」,我们就将该队首元素弹出队列,直到队空或队首元素「包含该横坐标」即可。最后我们用变量
记录最大高度(即纵坐标的值),当优先队列为空时,
,否则
即为队首元素。最后我们还需要再做一步检查:如果当前关键点的纵坐标大小与前一个关键点的纵坐标大小相同,则说明当前关键点无效,我们跳过该关键点即可。
这里需要强调的是,如果紧接着的俩纵坐标一样的楼房的话,skyline 里算作一个,并没有被刷新!!!!所以要跳过当前关键点的值与前一个关键点的值
res.back()相同的元素。
在实际代码中,我们可以进行一个优化。因为每一座建筑的左边缘信息只被用作加入优先队列时的依据,当其加入优先队列后,我们只需要用到其高度信息(对最大高度有贡献)以及其右边缘信息(弹出优先队列的依据),因此只需要在优先队列中保存这两个元素即可。
class Solution {
public:
vector<vector<int>> getSkyline(vector<vector<int>>& buildings) {
auto cmp = [](pair<int,int> &a,pair<int,int> &b)->bool{return a.second<b.second;};
priority_queue<pair<int,int>,vector<pair<int,int>>, decltype(cmp)> queue(cmp);
vector<vector<int> > res;
vector<int> scan;
//store all scannning lines,sorted by their x-coordinate
for(vector<int> &building:buildings){
scan.emplace_back(building[0]);
scan.emplace_back(building[1]);
}
//all canning line should be in order
sort(scan.begin(),scan.end());
//scan
int b_index = 0, n = buildings.size();
for(int &line:scan){
//input by left edge
while(b_index<n&&buildings[b_index][0]<=line){
queue.emplace(buildings[b_index][1],buildings[b_index][2]);
b_index++;
}
//delay delete, delete onlny when use it
while(!queue.empty()&&queue.top().first<=line){
queue.pop();
}
int maxn = queue.empty() ? 0 : queue.top().second;
//current max number != the latest one, we should add it to results
if(res.size()==0||maxn!=res.back()[1]){
res.push_back({line,maxn});
}
}
return res;
}
};
线段树思路及算法
区间操作+单点查询+离散化,复杂度 O(nlogn)。
这个线段树的写法确实比较特殊,是由两个树状数组拼起来构成的。
class SegmentTree {
public:
struct node {
int tag;
int val;
};
private:
using node_ptr = node*;
node_ptr prefix, suffix; //左右子树指针
inline static int lowbit(int x) {//最低比特位
return x & -x;
}
public:
SegmentTree(size_t n) : prefix(new node[2 * n]), suffix(prefix + n) {}
inline size_t size() const {
return suffix - prefix;
}
inline void pushup(int p, int d, size_t s) {
const int n = size();
if (s == 0) return;
int i = p + lowbit(s);
int j = p - lowbit(s);
for (;i <= n;i += lowbit(i))
prefix[i].val = max(prefix[i].val, d);
for (i -= lowbit(i);j > i;j -= lowbit(j))
suffix[j].val = max(suffix[j].val, d);
}
inline void update(int l, int r, int d) {//左端点,右端点,数值
const int n = size();
int i = l, j = r;
if (l > 0)
for (;i + lowbit(i) <= r;i += lowbit(i)) {
suffix[i].val = max(suffix[i].val, d);
suffix[i].tag = max(suffix[i].tag, d);
}
for (;j > i;j -= lowbit(j)) {
prefix[j].val = max(prefix[j].val, d);
prefix[j].tag = max(prefix[j].tag, d);
}
pushup(l, d, i - l);
pushup(r, d, r - i);
}
inline int query(int p) const {
const int n = size();
int ans = 0;
for (int i = p + 1;i <= n;i += lowbit(i))
ans = max(ans, prefix[i].tag);
for (int i = p;i > 0;i -= lowbit(i))
ans = max(ans, suffix[i].tag);
return ans;
}
};
class Solution {
public:
vector<vector<int>> getSkyline(vector<vector<int>>& buildings) {
vector<int> order;
for (const auto& e : buildings) {
order.push_back(e[0]);
order.push_back(e[1]);
}
auto first = order.begin();
auto last = order.end();
sort(first, last);//
/*unique(C++)函数的功能是元素去重。即”删除”序列中所有相邻的重复元素(只保留一个)。
此处的删除,并不是真的删除,就是把重复元素的位置让不重复元素使用。返回值是去重之后的尾地址(是地址!!)
由于它”删除”的是相邻的重复元素,所以在使用unique函数之前,一般都会将目标序列进行排序。*/
/*erase(first,last);删除从first到last之间的字符,(first和last都是迭代器)*/
last = order.erase(unique(first, last), last);
const int n = order.size();
SegmentTree tree(n);
for (const auto& e : buildings) {
const int l = lower_bound(first, last, e[0]) - first;
const int r = lower_bound(first, last, e[1]) - first;
tree.update(l, r, e[2]);
}
int prev = 0;
vector<vector<int>> ans;
for (int i = 0;i < n;++i) {
const int cur = tree.query(i);
if (cur != prev) ans.push_back({order[i], prev = cur});
}
return ans;
}
};

若有收获,就点个赞吧
0 人点赞
