1. Harbor同步
1.1 Harbor生产线流程
harbor 官方默认提供主从复制的方案来解决镜像同步问题,通过复制的方式,我们可以实时将测试环境harbor仓库的镜像同步到生产环境harbor,类似于如下流程: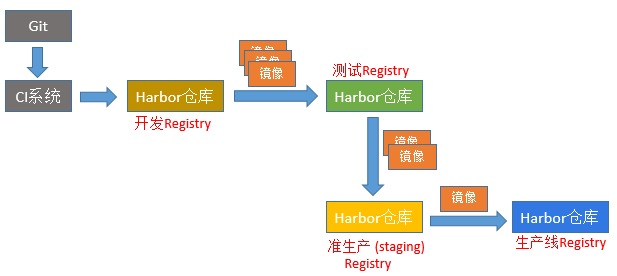
我们可以在 Harbor 库中自定义同步规则,手动将镜像同步到另一台 Harbor 库中,当然,也可以采用目前流行的两种主流的 Harbor高可用集群方案:
- 双主复制
- 多 harbor 实例共享后端存储
1.2 双主复制
所谓的双主复制其实就是复用主从同步实现两个 harbor 节点之间的双向同步,来保证数据的一致性,然后在两台 harbor 前端顶一个负载均衡器将进来的请求分流到不同的实例中去,只要有一个实例中有了新的镜像,就是自动的同步复制到另外的的实例中去,这样实现了负载均衡,也避免了单点故障,在一定程度上实现了 Harbor 的高可用性: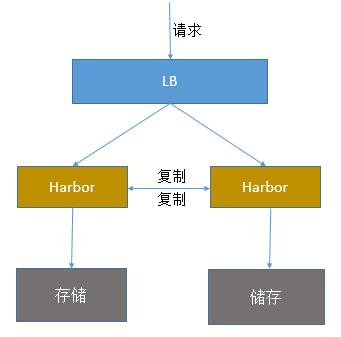
这个方案有一个问题就是有可能两个 Harbor 实例中的数据不一致。假设如果一个实例 A 挂掉了,这个时候有新的镜像进来,那么新的镜像就会在另外一个实例 B 中,后面即使恢复了挂掉的 A 实例,Harbor实例 B 也不会自动去同步镜像,这样只能手动的先关掉 Harbor实例B的复制策略,然后再开启复制策略,才能让实例B数据同步,让两个实例的数据一致。另外,这里还需要多吐槽一句:在实际生产使用中,主从复制十分的不靠谱!!所以这里推荐使用下面要说的这种方案:多 harbor 实例共享后端存储。1.3 多harbor实例共享后端存储
目前最常用的就是这种方案,下面也会以这种方案进行搭建。
共享后端存储算是一种比较标准的方案,就是多个 Harbor 实例共享同一个后端存储,任何一个实例持久化到存储的镜像,都可被其他实例中读取。通过前置 LB 进来的请求,可以分流到不同的实例中去处理,这样就实现了负载均衡,也避免了单点故障: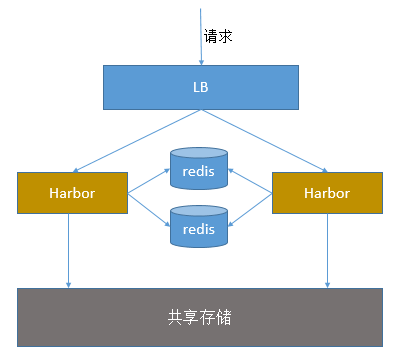
这个方案在实际生产环境中部署需要考虑三个问题:
- 共享存储的选取,Harbor 的后端存储目前支持 AWS S3、Openstack Swift, Ceph 等,在下面的实验环境里,暂且直接使用 nfs。
- Session 在不同的实例上共享,这个现在其实已经不是问题了,在最新的 harbor 中,默认 session 会存放在 redis 中,只需要将 redis 独立出来即可。可以通过 redis sentinel 或者 redis cluster 等方式来保证 redis 的可用性。在下面的实验环境里,暂且使用单台 redis。
- Harbor 多实例数据库问题,这个也只需要将 harbor 中的数据库拆出来独立部署即可。让多实例共用一个外部数据库,数据库的高可用也可以通过数据库的高可用方案保证。
2. 具体步骤
2.1 基本流程
1、准备一个 SpringBoot 项目,可以打包、也可以运行,有几个简单的页面。
2、将这个 SpringBoot 项目上传到 gitlab-ce,执行 ci pipline,实现编译、代码质量扫描、发送邮件、打包、构建镜像、发布到 harbor 测试库等功能。
3、将 harbor 测试库中的镜像同步到 k8s 中的 harbor 准生产库。(做的就是这一步)
4、k8s 拉取管理镜像。2.2 Harbor同步
2.2.1 同步过程
1、点击仓库管理—>新建目标,我这里没有配证书,就不勾选了。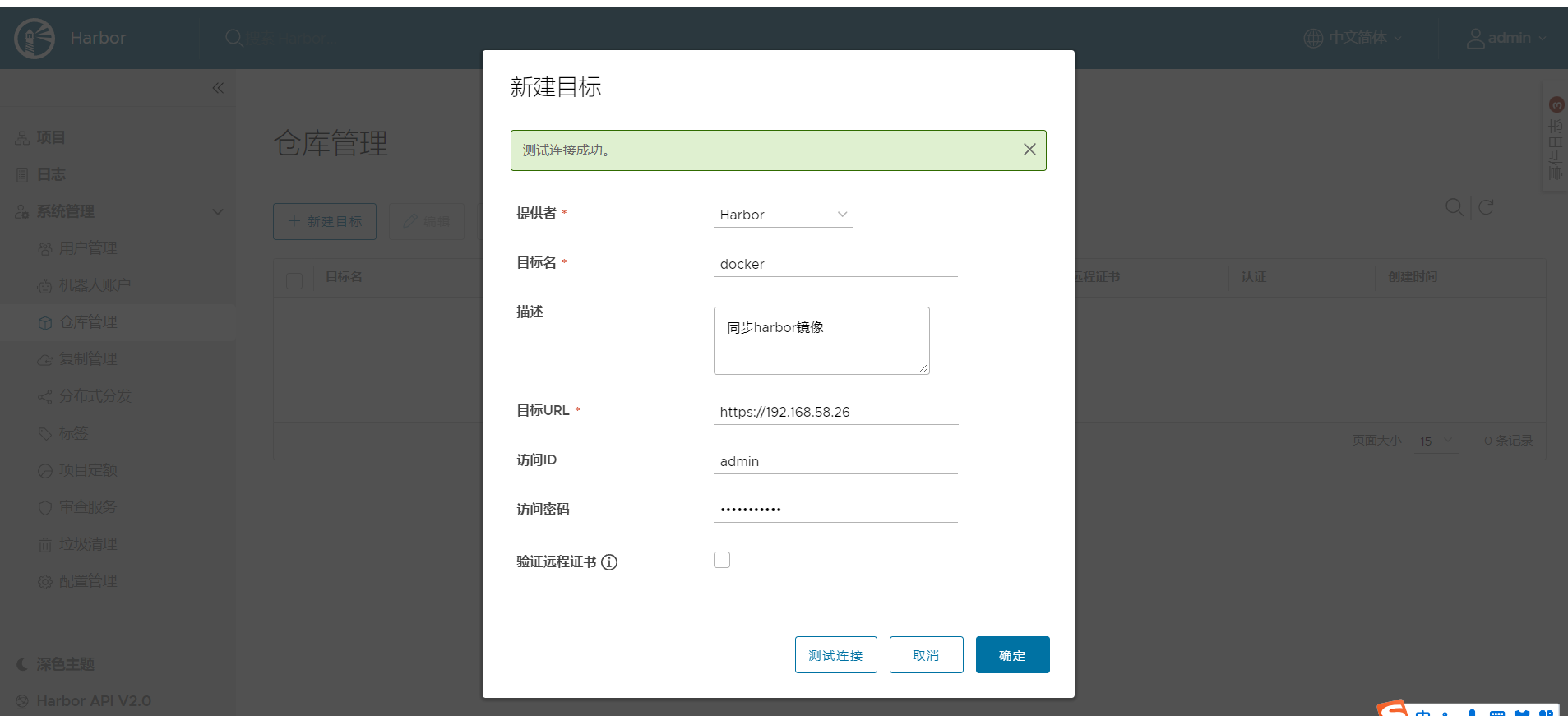
2、将远程仓库同步到本地,点击复制管理—>新建规则,选择 pull-based。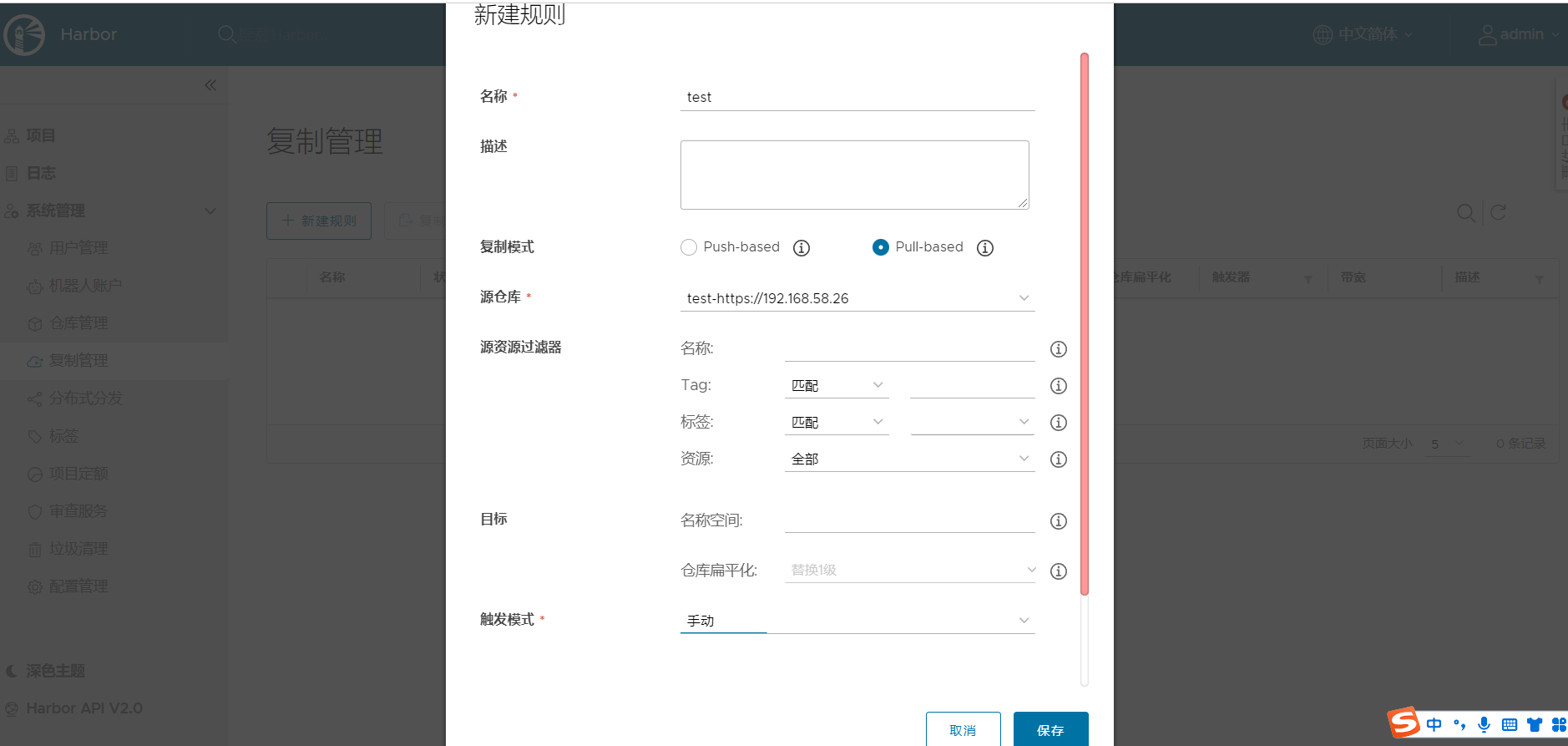
3、将本地库同步到远程仓库,点击复制管理—>新建规则,选择 push-based。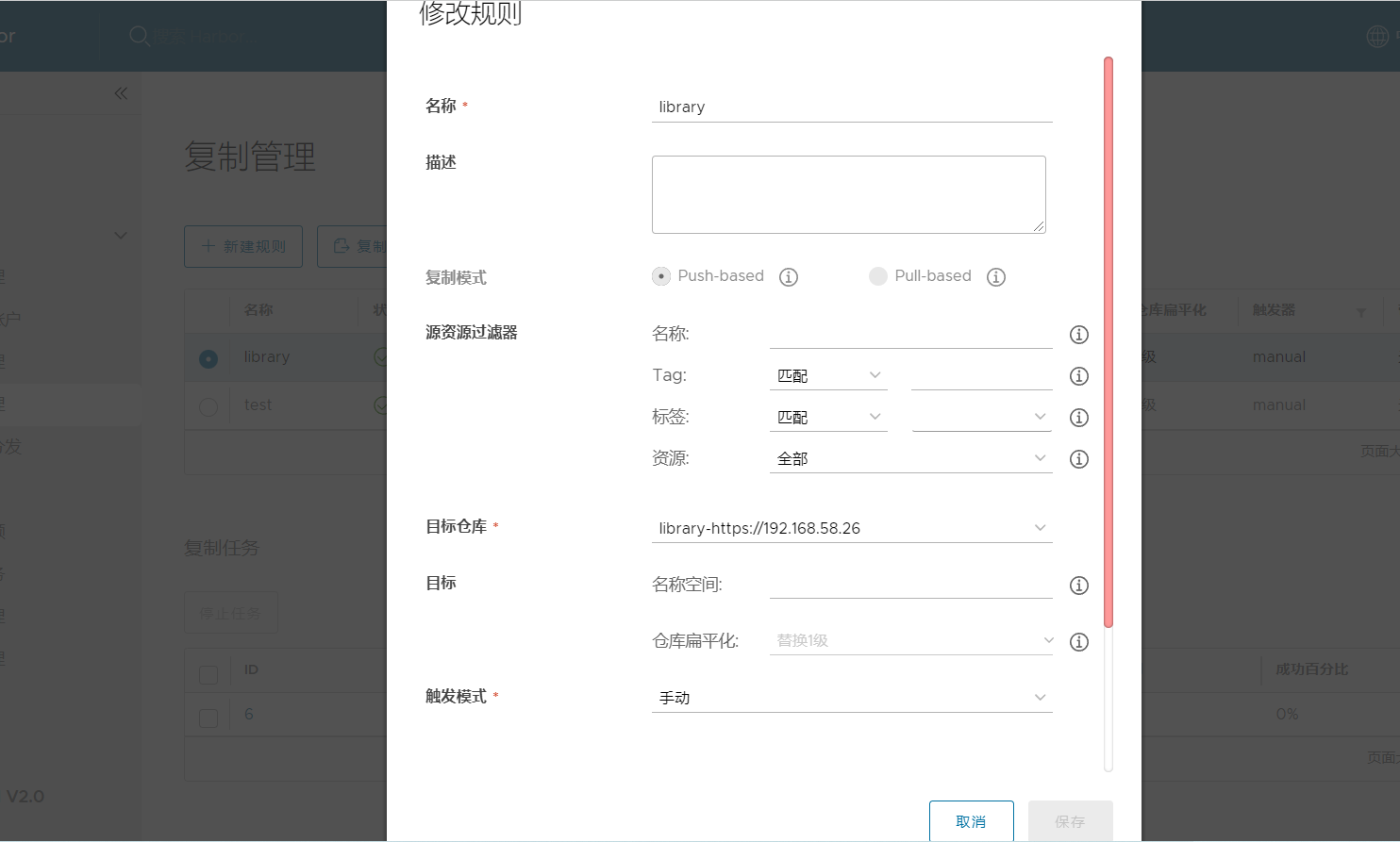
4、如果我们只想同步某一个仓库的话,还需要更进一步配置。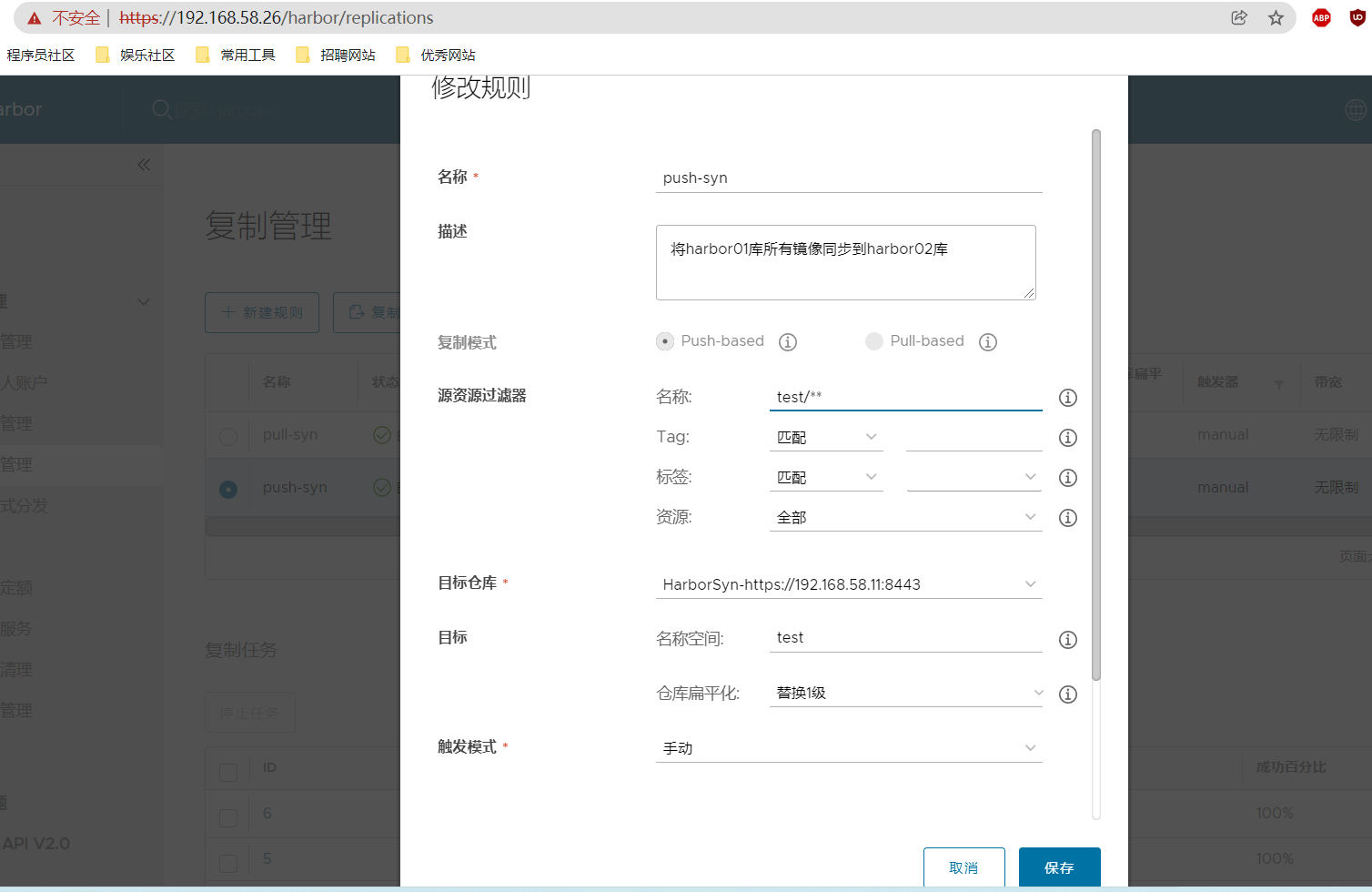
5、设置定时复制。30 ?:表示每半分钟触发一次任务。 0 0 /1 * ?:表示每隔1小时执行一次任务。 具体查看:https://www.jianshu.com/p/586fc47c6fd9?utm_campaign=maleskine&utm_content=note&utm_medium=seo_notes&utm_source=recommendation
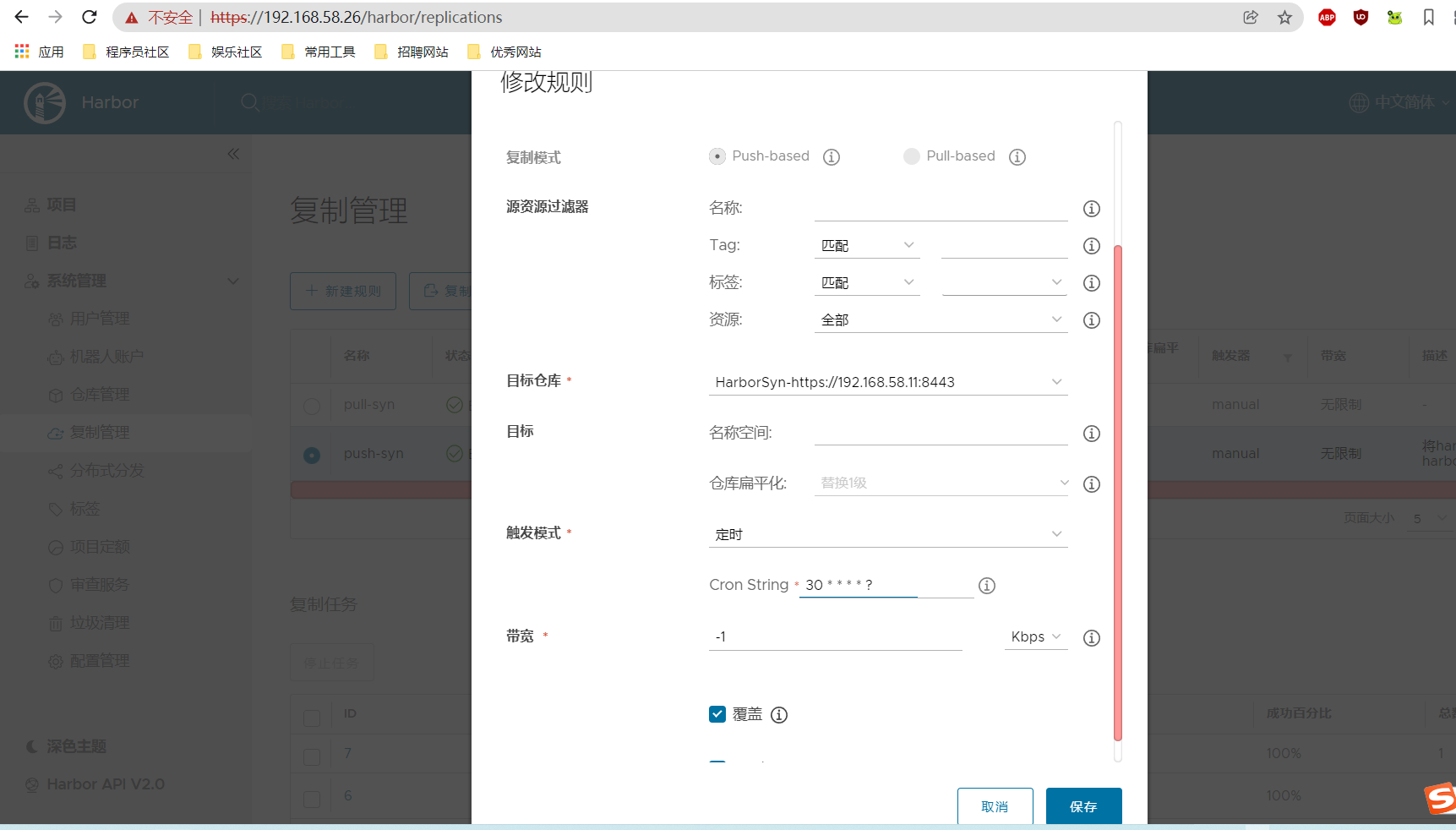
2.2.2 我的配置
只需要在 Harbor02.io 库里配置 push 定时任务即可。

若有收获,就点个赞吧
0 人点赞
