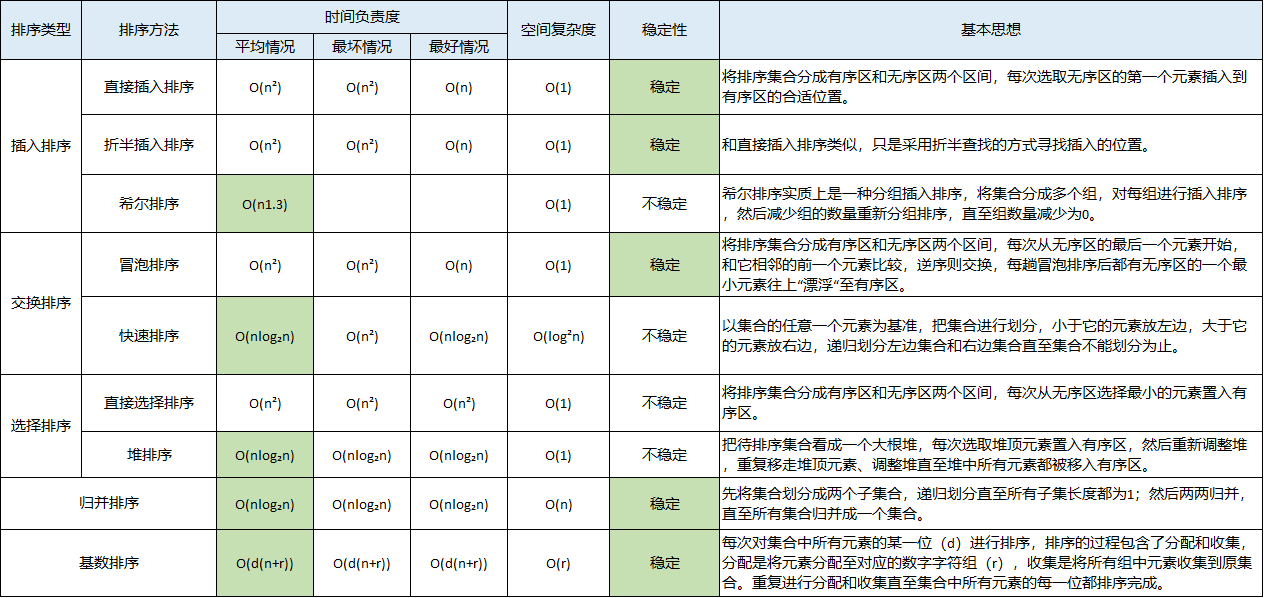
1. 时间复杂度
时间复杂度:通俗来说,算法中的基本操作次数,即为算法的时间复杂度(时间复杂度存在最好. 平均 . 和最坏情况,我们是以最坏情况为准),我们在计算时间复杂度的时候,并不一定要计算精确的执行次数,而只需要知道大概执行次数。
算法的速度指的并非时间,而是操作数的增速。谈论算法的速度时,说的是随着输入的增加,其运行时间将以什么样的速度增加,算法的运行时间用大O表示法表示。
| 简单查找 | 二分查找 | 元素个数 |
|---|---|---|
| 100 毫秒 | 7 毫秒 | 100 |
| 10 秒 | 14 毫秒 | 10 000 |
| 11 天 | 30 毫秒 | 1 000 000 000 |
2. 大O表示法
大O表示法指出了最糟糕情况下的运行时间。假设你使用简单查找在电话簿中找人。你知道,简单查找的运行时间为 O(n),这意味着在最糟情况下,必须查看电话簿中的每个条目。如果要查找的是 Chars ——电话簿中的第一个人,一次就能找到,无需查看每个条目。考虑到一次就找到了 Chars,请问这种算法的运行时间是 O(n)还是 O(1) 呢?简单查找的运行时间总是为 O(n)。查找 Chars 时,一次就找到了,这是最佳的情形,但大O表示法说的是最糟的情形。因此,你可以说,在最糟情况下,必须查看电话簿中的每个条目,对应的运行时间为 O(n)。这是一个保证——你知道简单查找的运行时间不可能超过 O(n)。
常见的大O运行时间
- O (log n ),也叫对数时间 ,这样的算法包括二分查找。
- O (n ),也叫线性时间 ,这样的算法包括简单查找。
- O (n * log n ),这样的算法包括快速排序——一种速度较快的排序算法。
- O (n 2 ),这样的算法包括选择排序——一种速度较慢的排序算法。
O (n !),这样的算法包括旅行商问题的解决方案——一种非常慢的算法。
3. 排序算法
3.1 算法简介
我们通常所说的排序算法往往指的是内部排序算法,即数据记录在内存中进行排序。排序算法大体可分为两种:
一种是比较排序,时间复杂度O(nlogn) ~ O(n^2),主要有:冒泡排序,选择排序,插入排序,归并排序,堆排序,快速排序等。
- 另一种是非比较排序,时间复杂度可以达到O(n),主要有:计数排序,基数排序,桶排序等。
3.2 插入排序
3.2.1 直接插入排序
基本思想:
数列前面部分看为有序,依次将后面的无序数列元素插入到前面的有序数列中,初始状态有序数列仅有一个元素,即首元素。遍历序列的关键字,将待排序的关键字字依次与其前一个关键字起逐个向前扫描比较,若是待排关键字小于扫描到的关键字,则将扫描到的关键字的向后移动一个位置,直到找到没有比待排关键字大的地方插入(待排序关键字前面的都是有序数列)。
直接插入排序最好的情况就是不需要移动,直接就是一个从小到大排好的顺序,那么就只需要比较一遍就可以了,不需要移动交换,时间复杂度为O(n),最坏的情况下需要全部移动一遍,就是按照从大到小的顺序排的,那么,时间复杂度为O(N²),空间复杂度为O(1),因为只需要一个数据存储要插入的数据即可,是一个稳定的排序算法,链式存储也可以用,比较适合基本有序的数据。
public static void directInsertSort(int[] arr) {//tmp表示当前数,j表示当前数前面数的下标int tmp;int j;for (int i = 1; i < arr.length; i++) {tmp = arr[i];j = i - 1; //从右向左在有序区找到插入位置//无序区中的数存在小于有序区中的数,则有序区中的数后移一位//举例:[45, 1, 87, 98, 40, 11, 73, 5, 63, 40]while (j >= 0 && tmp < arr[j]) {arr[j+1] = arr[j];j--;}arr[j+1] = tmp;}}
3.2.2 二分插入排序
二分插入排序算法实质上是对直接插入排序的一种优化,在排序数量大的情况下,速度远高于直接插入排序。
基本思想:
以待排关键字所在位置将序列分为有序数列和无序数列两部分,然后对有序数列进行折半查找,找出一个点,左边的序列都是小于待排序关键字,该点与其右边至待排关键字的序列都是大于待排关键字的,将右边序列右移然后插入空处。
最坏情况:时间复杂度为O(n ^ 2)。
最好情况:整个序列为正序的时候内层循环条件始终不成立,所以内层循环始终不执行,始终执行语句如果(NUMS [I]
public static void binaryInsertSort(int[] arr) {
int i,j,low,high,mid;
int tmp;
for (i = 1; i < arr.length; i++) {
tmp = arr[i];
low = 0;
high = i - 1;
//在a[low .. high ]中折半查找 有序插入位置
//举例:[24, 89, 72, 36, 36, 70, 24, 81, 43, 43]
while (low <= high) {
mid = (low + high) / 2;
if (tmp < arr[mid]) {
high = mid - 1;
} else {
low = mid + 1;
}
}
//后移,low指向的就是要插入的那个位置
for (j = i - 1; j >= low; j--) {
arr[j+1] = arr[j];
}
//后移
arr[low] = tmp;
}
}
3.2.3 希尔排序
其基本思想为:
该方法实质上是一种分组插入方法。先取一个小于Ñ的整数D1作为第一个增量,把文件的全部记录分组。所有距离为D1的倍数的记录放在同一个组中。先在各内组进行直接插入排序 ;然后,取第二个增量D2 <D1重复上述的分组和排序,直至所取的增量 即所有记录放在同一组中进行直接插入排序为止。
插入排序的改进版为了减少数据的移动次数,在初始序列较大时取较大的步长,通常取序列长度的一半,此时只有两个元素比较,交换一次。之后步长依次减半直至步长为1,即为插入排序,由于此时序列已接近有序,故插入元素时数据移动的次数会相对较少,效率得到了提高。时间复杂度:通常认为是O(N3 / 2),未验证稳定性:不稳定。
public static void shellInsertSort(int[] arr) {
//gap表示步长
int i,j;
int tmp;
int gap = arr.length / 2;
while (gap > 0) {
for (i = gap; i < arr.length; i++) {
tmp = arr[i];
j = i - gap;
while (j >= 0 && tmp < arr[j]) {
arr[j+gap] = arr[j];
j = j - gap;
}
arr[j+gap] = tmp;
}
gap = gap / 2;
}
}
3.3 交换排序
3.3.1 冒泡排序
它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。
冒泡排序算法的原理如下:
(1)比较相邻的元素。如果第一个比第二个大,就交换他们两个。
(2)对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
(3)针对所有的元素重复以上的步骤,除了最后一个。
(4)持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
public static void bubbleSort(int[] arr) {
int i,j;
int tmp;
//外层控制遍历次数
for (i = 1; i < arr.length; i++) {
for (j = i; j > 0; j--) {
if (arr[j] < arr[j-1]) {
tmp = arr[j];
arr[j] = arr[j-1];
arr[j-1] = tmp;
}
}
}
}
3.3.2 快速排序
其基本思想是通过⼀趟排序将要排序的数据分割成独⽴的两部分,其中⼀部分的所有数据都⽐另外⼀部分的所有数据都要⼩,然后再按此⽅法对这两部分数据分别进⾏快速排序,整个排序过程可以递归进⾏,以此达到整个数据变成有序序列。
复杂度分析
- 最好:O(nlogn)
- 最坏:O(n2)
稳定性:差
//快速排序 public class QuickSort { public static void main(String[] args) { //给80000个数据 int[] arr = new int[80000]; for (int i = 0; i < 80000; i++) { arr[i] = (int) (Math.random()*1000); } long start = System.currentTimeMillis(); //开始时间 System.out.println("排序前:" + Arrays.toString(arr)); // quickSort2(arr); quickSort(arr, 0, arr.length - 1); System.out.println("排序后:" + Arrays.toString(arr)); long end = System.currentTimeMillis(); //结束时间 System.out.println("快速排序共花时间:" + (end - start) + "毫秒"); //101毫秒 } /** * 递归方式 * @param arr * @param left * @param right */ public static void quickSort(int[] arr, int left, int right) { int l = left; int r = right; int pivot = arr[(left + right) / 2]; //中轴值 while (l < r) { //在 pivot 的左边一直找,找到大于等于 pivot 值,才退出 while (arr[l] < pivot) l++; while (arr[r] > pivot) r--; //此时已经分别找到了⽐中轴⼩的数(右边)、⽐⽀点⼤的数(左边),它们进⾏交换 if (l < r) { //交换完成之后继续往中间走,判断 int temp = arr[l]; arr[l++] = arr[r]; arr[r--] = temp; } } //左边再做排序,直到左边只剩一个 if (left < r) quickSort(arr, left, r); //右边再做排序 if (right > r) quickSort(arr, r+1, right); } /** * 基准值选取为第一个元素 * @param arr * @param left * @param right */ public static void quickSort2(int[] arr, int left, int right) { if (left >= right) { return; } int l = left; int r = right; int pivot = arr[l]; //基准值 while (l < r) { while (arr[r] >= pivot && l < r) r--; arr[l] = arr[r]; //找到一个值比基准值小的 while (arr[l] < pivot && l < r) l++; arr[r] = arr[l]; //找到一个值比基准值小的 } arr[l] = pivot; //此时l和r指向同一个位置,即为基准值的位置 quickSort2(arr, left, l); quickSort2(arr, r + 1, right); } //非递归方式 public static void quickSort2(int[] arr) { if (arr == null || arr.length == 1) return; //存放开始与结束索引 Stack<Integer> s = new Stack<>(); //压栈 s.push(0); s.push(arr.length - 1); while (!s.empty()) { int right = s.pop(); int left = s.pop(); //如果最大索引小于等于左边索引,说明结束了 if (right <= left) continue; int i = partition(arr, left, right); if (left < i - 1) { s.push(left); s.push(i - 1); } if (i + 1 < right) { s.push(i + 1); s.push(right); } } } //找到轴心,进行交换 public static int partition (int[] data, int first, int end) { int temp; int i=first,j=end; if(first<end) { temp=data[i]; //当i=j的时候,则说明扫描完成了 while(i<j) { //从右边向左边扫描找到一个小于temp的元素 while(j>i&&data[j]>temp)j--; if(i<j) { //将该元素赋值给temp data[i]=data[j]; //赋值后就应该将i+1指向下一个序号 i++; } //然后从左边向右边开始扫描,找到一个大于temp的元素 while(i<j&&temp>data[i])i++; if(i<j) { //将该元素赋值给temp data[j]=data[i]; //赋值后就应该将j-1指向前一个序号 j--; } } //将轴数据放在i位置中 data[i]=temp; } return i; } }3.4 选择排序
基本思想是:
第一次从R [0] ~R [n-1]中选取最小值,与R [0]交换,第二次从R [1]〜[R [N-1]中选取最小值,与R [1]交换,…,第I次从ř[I-1]〜[R [N-1] ]中选取最小值,与[R [I-1]交换,…,第n-1个次从ř[N-2]〜[R [N-1]中选取最小值,与[ R [N-2]交换,总共通过n-1个,得到一个按排序码从小到大排列的有序序列。
在直接选择排序中,共需要进行n-1次选择和交换,每次选择需要进行nitimes比较(1 <= i <= n-1),而每次交换最多需要3次移动,因此,总的比较次数C =(n * n - n)/ 2,总的移动次数3(n-1)。由此可知,直接选择排序的时间复杂度为O(n2),所以当记录占用字节数较多时,通常比直接插入排序的执行速度快些。由于在直接选择排序中存在着不相邻元素之间的互换,因此,直接选择排序是一种不稳定的排序方法。
public static void selectSort(int[] arr) {
int i,j,k;
int tmp;
//遍历次数
for (i = 0; i < arr.length-1; i++) {
k = i;
//选出一个比初始元素要小的
for (j = i+1; j < arr.length; j++) {
if (arr[j] < arr[k]) {
k = j;
}
}
//初始元素发生变化,两者交换位置
if (k != i) {
tmp = arr[i];
arr[i] = arr[k];
arr[k] = tmp;
}
}
}
3.5 堆排序
3.6 归并排序
归并排序(MERGE-SORT)采⽤的是分治法(Divide and Conquer)。其归并过程为:比较a[i]和b[j]的大小,若a[i]≤b[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1;否则将第二个有序表中的元素b[j]复制到r[k]中,并令j和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r中从下标k到下标t的单元。归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序,最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。
复杂度分析
- 最好:O(nlogn)
- 最坏:O(nlogn)
稳定性:好
/** * 归并排序 * 代码核心思路: * 分治:不断递归将原数组分,每次划半分 * 合并:比较左数组的元素和右数组的元素,把较小的元素添加到辅助数组中,最终需要将辅助数组的元素填充到原数组中 */ public class MergeSort { public static void main(String[] args) { //给80000个数据 int[] arr = new int[80000]; for (int i = 0; i < 80000; i++) { arr[i] = (int) (Math.random()*1000); } long start = System.currentTimeMillis(); //开始时间 System.out.println("排序前:" + Arrays.toString(arr)); mergeSort(arr, 0, arr.length - 1); System.out.println("排序后:" + Arrays.toString(arr)); long end = System.currentTimeMillis(); //结束时间 System.out.println("归并排序共花时间:" + (end - start) + "毫秒"); //154毫秒 } /** * 进行递归 * @param arr * @param left 指向数组的第一个元素 * @param right 指向最后一个元素 */ public static void mergeSort(int[] arr, int left, int right) { //终止条件 if (left == right || arr == null) { return; } int mid = (left + right) / 2; //左边的数不断的拆分 mergeSort(arr, left, mid); mergeSort(arr, mid + 1, right); //合并左右两部分,使整个数组有序 merge(arr, left, mid, right); } /** * 合并数组 * @param arr * @param left * @param mid * @param right */ public static void merge(int[] arr, int left, int mid, int right) { int[] helpArr = new int[right - left + 1]; //辅助数组 int lPoint = left; //左指针 int rPoint = mid + 1; //右指针 int i = 0; //辅助指针 while (lPoint <= mid && rPoint <= right) { //填充辅助数组中的值 if(arr[lPoint] <= arr[rPoint]) { helpArr[i++] = arr[lPoint++]; }else { helpArr[i++] = arr[rPoint++]; } } //把剩余的元素填充到辅助数组中 while (lPoint <= mid) { helpArr[i++] = arr[lPoint++]; } while (rPoint <= right) { helpArr[i++] = arr[rPoint++]; } //将辅助数组中的值填充到原数组中,注意原数组可能不是从头开始 for (int j = 0; j < helpArr.length; j++) { arr[left + j] = helpArr[j]; } } }3.7 基数排序(桶排序)
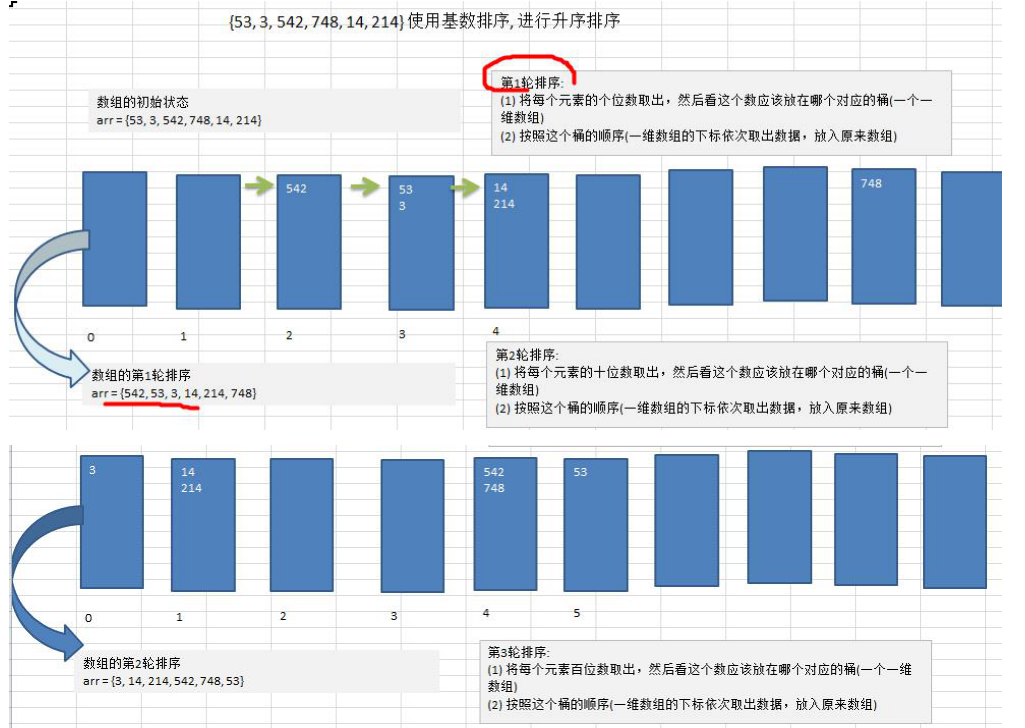
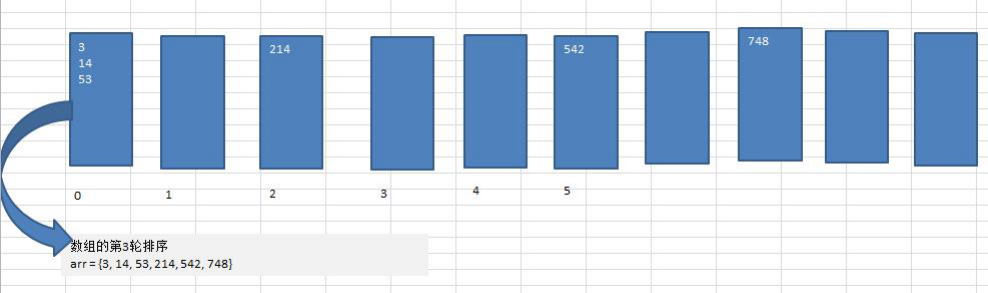
将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
基数排序是经典的空间换时间的方式,占用内存很大, 当对海量数据排序时,容易造成 OutOfMemoryError 。
- 基数排序时稳定的。[注:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且 r[i]在 r[j]之前,而在排序后的序列中,r[i]仍在 r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的]
/**
* 基数排序
*/
public class RadixSort {
public static void main(String[] args) {
int[] arr = new int[80000];
for (int i = 0; i < 80000; i++) {
arr[i] = (int) (Math.random() * 80000); // 生成一个[0, 80000) 数
}
System.out.println(Arrays.toString(arr));
Date data1 = new Date();
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String date1Str = simpleDateFormat.format(data1);
System.out.println("排序前的时间是=" + date1Str);
radixSort(arr);
Date data2 = new Date();
String date2Str = simpleDateFormat.format(data2);
System.out.println("排序后的时间是=" + date2Str);
System.out.println("基数排序后 " + Arrays.toString(arr));
}
public static void radixSort(int[] arr) {
//1.得到数组中最大的数的位数
int max = arr[0]; //假设第一数为最大数
for (int i = 1; i < arr.length; i++) {
if (arr[i] > max) max = arr[i];
}
//得到最大数是几位数
int maxLength = (max + "").length();
//定义一个二维数组,表示10个桶,每个桶就是一个一维数组
int[][] bucket = new int[10][arr.length];
//记录每个桶存储了多少个数据,bucketElementCounts[0] , 记录的就是 bucket[0] 桶的放入数据个数
int[] bucketElementCounts = new int[10];
for (int i = 0, n = 1; i < maxLength; i++, n*=10) {
//(针对每个元素的对应位进行排序处理), 第一次是个位,第二次是十位,第三次是百位
for (int j = 0; j < arr.length; j++) {
//取出每个元素的对应位的值
int digitOfElement = arr[j] / n % 10;
//放入对应的桶中
bucket[digitOfElement][bucketElementCounts[digitOfElement]] = arr[j];
bucketElementCounts[digitOfElement]++; //对应桶中多了一个元素
}
int index = 0;
//遍历每个桶,并将桶中的数据,放入到原数组
for (int k = 0; k < bucketElementCounts.length; k++) {
//如果桶中有数据,才放入
if (bucketElementCounts[k] != 0) {
for (int l = 0; l < bucketElementCounts[k]; l++) {
//取出元素放入到arr
arr[index++] = bucket[k][l];
}
}
//当前桶中元素出来完,需要将桶中元素个数清0
bucketElementCounts[k] = 0;
}
}
}
}

若有收获,就点个赞吧
0 人点赞
