一、本地存储
1. 为什么要本地存储?
- 真实项目中经常需要在一个网站的多个页面间共享数据,如果登录状态,购物车信息等
但是浏览器打开页面时首先形成一个顶层的作用域 window,每次页面打开都会形成一个单独的作用域,页面之间是不可以互通访问变量的;但是项目中经常会用到页面间传递数据的要求;
每个页面又都是在浏览器中打开的,如果可以把值存储到浏览器中,让浏览器作为一个中介, A 页面把值存到浏览器中,B 页面从从浏览器中把 A 存储的值取出来;
2. 本地存储解决方案:
- cookie (cookie 是 http 协议的一部分)
- localStorage 本地存储(HTML5 新增的,浏览器技术)
- sessionStorage 会话存储(HTML5 新增,浏览器技术)
3. localStorage 和 sessionStorage
HTML5 提供了本地存储方式:
- localStorage 永久存储(如果手动触发删除或者用户清除)
- sessionStorage 会话存储
localStorage
window.localStorage 对象console.log(window.localStorage);
localStorage.setItem(key, value) 存储数据
localStorage 存储数据时键值的形式存储的;
- key 键
- value 值
- key 和 value 都需要是字符串类型,如果不是字符串类型,浏览器会隐式调用 toString 将其转换为字符串;
localStorage.setItem({name: 1}, {name: 2});localStorage.setItem(1, 2)// '[object Object]' 如果你存的 key 和 value 不是字符串类型的,它会把他们转成字符串,调用// toString() 方法,对象 toString() -> '[object Object]';
- 不会有两个相同的 key,如果 key 相同后面的值会覆盖前面的值;
localStorage.setItem('user', 'mabin');localStorage.setItem('user', 'mabin2');
- 如果批量存储数据太麻烦,直接存储 JSON 字符串 等你想要用的时候要记得 JSON.parse() 变成对象
let ary = {code: 0,data: {page: 1,limit: 10,list: [{course: 18,subject: 15,fire: 3,price: 180},{course: 18,subject: 15,fire: 3,price: 180},{course: 18,subject: 15,fire: 3,price: 180},{course: 18,subject: 15,fire: 3,price: 180}]},msg: 'ok'};// JSON.parse() 把JSON字符串变成对象// JSON.stringify() 把对象变成JSON格式的字符串localStorage.setItem('someJson', JSON.stringify(ary));
- localStorage.getItem(key) 获取 ls 中存储的数据。
获取回来的都是字符串类型的
let json = localStorage.getItem('someJson');let uk = localStorage.getItem('uk'); // nullconsole.log(uk); // 获取不存在的 key 返回 nullconsole.log(json);console.log(typeof json); // stringlocalStorage.clear() // 清空 localStorage,一般退出登录时可能需要你把东西都删了localStorage.removeItem(key) // 删除指定 key 的数据localStorage.removeItem('user');
- sessionStorage 会话存储 是客户端本地存储的一种
- setItem(key, value) 是服务端技术,存在服务器上的
- getItem(key) 获取指定 key 的值
- removeItem(key) 删除指定 key 的数据
- sessionStorage.setItem(‘ok’, ‘0’); 存储,key 和 value 是字符串类型的
- localStorage 和 sessionStorage 的区别:
注意会话存储:刷新,并不会使 sessionStorage 失效,但是关闭页面后 sessionStorage 中的数据就没有了;
localStorage 是永久存储,如果不删除或者用户不清除就会一直有。而 sessionStorage 只是会话存储,只要页面不关闭有,如果页面关闭了,就消失了。
补充:Unix 时间戳是以秒为单位的,js 的时间戳是以毫秒为单位;PHP 的时间戳就是 unix 时间戳;如果服务端让你传给它时间戳,要问一下是毫秒还是秒。如果服务端要秒,要用 js 时间戳除以1000;如果服务端返回给你的是时间戳,如果是 unix 时间戳,需要乘以1000转换 js 时间戳;【unix 时间戳比 js 少三位,一看比较短就是 unix的】;
二、发布网站
- 项目:
前后端开发的项目代码 - 域名:
需要在万网(被阿里云收购)上买域名,每个域名项身份证号一样,是不会重复的,一旦被注册,就不能再次进行购买; - 服务器:
存储项目代码的一台电脑。每个服务器都会对应一个对应的 ip 地址(一个门牌号),如果想让我们开发的项目代码为用户提供服务需要把项目代码部署在服务器上(虚拟服务器)。 - DNS (Domain Name System):
DNS 服务由 DNS 服务器提供,DNS 服务是将域名和 IP 地址进行绑定; - ftp(file transfer protocol)上传: ftp 工具或者脚本把代码上传到服务器上;
端口:
一个服务器可以提供多个服务,每个服务器上可以有很多小房间(端口),这些小房间编号 0-65535,每个端口可以提供一个服务;webstorm 的 localhost:63342/xxx/ccc.html 是在本机上启动了一个服务器程序,此时我们的电脑相当于服务器。我自己的电脑上访问 localhost:xxx/cc.html 时是不需要网络的
搜索爬虫:每个做搜索的,公司如百度,都会有一个用来收集各大网站的程序,这个程序称为搜索爬虫。它会把最火的关键词或者网站上的关键字收录到自己的搜索库中;当我们进到百度时,查找某些东西时,百度的服务器会去自己的搜索库中和我们输入的内容最接近的内容,然后返回给我们
三、客户端和服务器
客户端:可以向服务器发请求,并接收返回的内容进行处理
服务器端:能够接收客户端请求,并且把相关资源的信息返回给客户端的
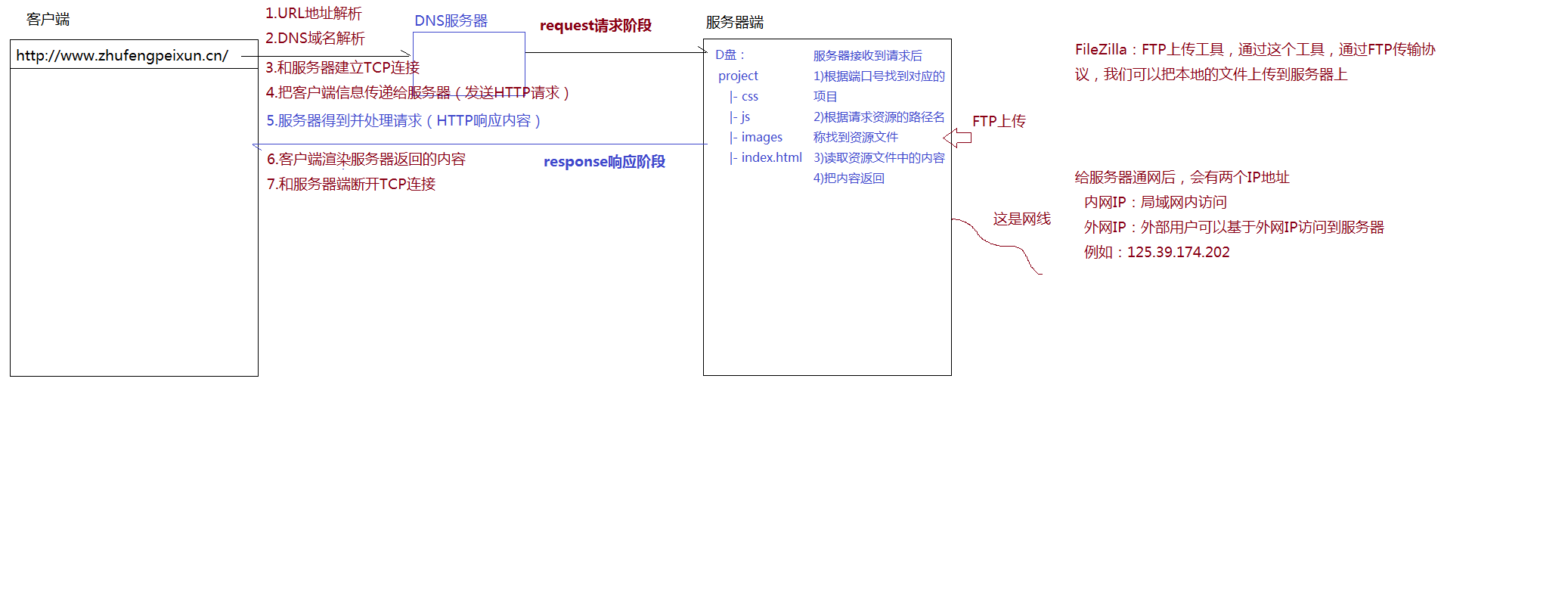
如何交互?
- URL 地址解析
- DNS 域名解析
客户端向服务器端请求;request 请求阶段
- 和服务器建立 TCP 连接
- 把客户端信息传递给服务器(发送 HTTP 请求)
- 服务器得到并处理请求(HTTP 响应内容)
服务器响应客户端请求:response 响应阶段
- 客户端渲染内容返回的内容
- 从服务器断开 TCP 连接
四、细节问题
1. URL / URI / URN
URL(Uniform Resource Loactor):统一资源定位符,根据这个地址能找到对应的资源
URN(Uniform Resource Name):统一资源名称,一般指国际上通用的(标准的)一些名字(例如:国际统一发版的编号)
URI(Uniform Resource Identifier):统一资源标识符,URL 和 URI 的子集
一个完整的 URL 包含的内容:
1. 协议
(http://)传输协议就是能够把客户端和服务器端通信的信息进行传输的工具
- http:超文本传输协议,除了传递文本,还可以传递媒体资源文件(流文件)及 XML 格式数据
- https:更加安全的 http ,一般涉及到支付的网站都要采用 https 协议 (S:SSL 加密传输)
- FTP:文件传送协议,一般应用于把本地资源上传到服务器端
FileZilla:FTP上传工具,通过这个工具,通过 FTP 传输协议,我们可以把本地的文件上传到服务器上
2. 域名
(www.zhufengpeixun.cn)
- 顶级域名:qq.com
- 一级域名:www.qq.com
- 二级域名:sprots.qq.com
- 三级域名:kbs.sports.qq.com
- .com:国际域名
- .cn:中文域名
- .com.cn
- .edu:教育
- .gov:政府机构
- .io:博客
- .org:官方组织
- .net:系统类
一个让用户方便记忆的名字,就叫域名,不通过域名,直接用外网 ip 地址也能访问服务器,但是外网 ip 很难被记住
给服务器通网后,会有两个 ip 地址:内网 ip 局域网内访问 | 外网 ip 外部用户可以基于外网 ip 访问到服务器
3. 请求资源路径名称
(/stu/index.html)
服务器接收到请求后要做的:
- 根据端口号找到对应的项目
- 根据请求资源的路径名称找到资源文件
- 读取资源文件中的内容,把内容返回
默认的路径名称:xxx.com/stu/ 不指定资源名,服务器会找默认资源,一般默认资源名是 default.html、index.html、… 这些都可以自己配置
注意伪 URL 地址的处理:URL 重写技术是为了增加 SEO 优化的,动态的网址一般不能被搜索引擎收录,所以我们要把动态网址静态化,此时需要的是重写 URL
4. 问号传参信息
(?from=wx&lx=1)
客户端想把信息传递给服务器:很多种方式
- URL 地址问号传参
- 通过请求报文传输(请求头和请求主体)
也可以不同页面之间的信息交互 如:从列表到详情
5. 端口号
(:80)取值范围(0-65535)
- http 默认端口号:80
- https 默认端口号:443
- ftp 默认端口号:21
- 数据库默认端口号:3306
如果项目采用的就是默认端口号,我们在书写地址的时候,不用加端口号,浏览器在发送请求的时候会帮我们默认给加上
用端口号来区分同一台服务器上,的不同项目
6. HASH值(#zhenyu)
- 也能充当信息传输的方式
- 锚点定位
- 基于 HASH 实现路由管控(不同的 HASH 值,展示不同的组件和模块)
7. URL 特殊字符的处理
请求的地址中如果出现非有效 Unicode 编码内容,现代浏览器会默认的进行编码
- 基于 encodeURI 编码,我们可以基于 decodeURI 编码。我们一般用 encodeURL 编码的是整个 URL,这样整个 URL 中的特殊字符都会自动编译
- encodeURIComponent / decodeURLCopmonent 它相对于 encodeURL 来说 不用给整个URL编码,而是给URL部分信息进行编码(一般都是问号传参的值编码)
客户端和服务器端进行信息传输的时候,如果需要把请求的地址和信息编码,我们则基于以上两种方式来处理,服务器端也存在这些方法,这样就可以统一编码解码了
- 客户端还存在一种方式,针对于中文的编码方式 escape / unescape 这种方式一般只应用于客户端页面之间自己的处理,例如:从列表跳转到详情,我们可以把传递的中文信息基于这个编码,详情页获取编码后的信息再解码,再比如我们再客户端中的 cookie 信息,如果信息是中文,我们也基于这种方法解码
link.onclick = function {// 获取当前页面的 URL 地址let url = window.location.href;// 跳转页面window.open("http://baidu.com");}
2. DNS服务器域名解析
DNS 服务器:域名解析服务器,在服务器上存储着,域名 <=> 服务器外网 IP 的相关记录
而我们发送请求时所谓的 DNS 解析,其实就是根据域名,在 DNS 服务器上查找到对应服务器的外网 IP
DNS 优化
- DNS 缓存(一般浏览器会在第一次解析后,默认建立缓存,时间很短,只有一分钟左右)不需要网络
- 减少 DNS 解析次数(一个网站中我们需要发送请求的域名和服务器尽可能减少既可)
- DNS 预获取 (dns-prefetch):在页面加载开始的时候,就把当前页面中需要访问其他域名(服务器)的信息进行提前 DNS 解析,以后加载到具体内容部分可以不用解析了
DNS Prefetch 即 DNS 预获取
- 减少DNS的请求次数
进行DNS预获取
<meta http-equiv="x-dns-prefetch-control" content="on"><link rel="dns-prefetch" href="//static.360buyimg.com"><link rel="dns-prefetch" href="//misc.360buyimg.com"><link rel="dns-prefetch" href="//img10.360buyimg.com"><link rel="dns-prefetch" href="//img11.360buyimg.com"><link rel="dns-prefetch" href="//img12.360buyimg.com">......
缓存时间在1分钟左右
3. TCP协议
1. HTTP报文
请求报文:所有经过传输协议,客户端传递给服务器的内容,都被成为请求报文
- 起始行
- 请求头(请求首部)
- 请求主体
响应报文:所有经过传输协议,服务器返回给客户端的内存,都被成为响应报文
- HTTP 状态码
- 响应头
- 响应主体
HTTP 报文:请求报文 + 响应报文
谷歌浏览器:F12 -> network(所有客户端和服务器端的交互信息在这里都可以看到) -> 点击某一条信息,在右侧可以看到所有的 HTTP 报文信息
2. HTTP状态码
1 - 5 开头,三位数字,1开头基本没出现过
- 200:成功(OK)
- 201:Created 成功,一般应用于告诉服务器创建一个新文件,最后服务器创建成功后返回的状态码
204:No Content 没有内容 对于某些请求(例如:put 或者 delete)服务器不想处理,可以返回空内容,并且用204状态码告知
301:Moved Permanently 永久重定向,永久转移
- 302:Moved Temporarily 临时转移,很早以前基本上用302来做,但是现在主要用307来处理这个事情
- 304:Not Modified 设置 HTTP 的协商缓存
307:307的意思就是临时重定向 Temporary Redirect -> 主要用于:服务器的负载均衡、视频防盗等
400:Bad Request 传递给服务器的参数错误
- 401:Unauthorized 无权限访问
404:Not Found 请求地址错误
500:Internal Server Reeoe 未知服务器错误
- 503:Service Unavailable 服务器超负荷
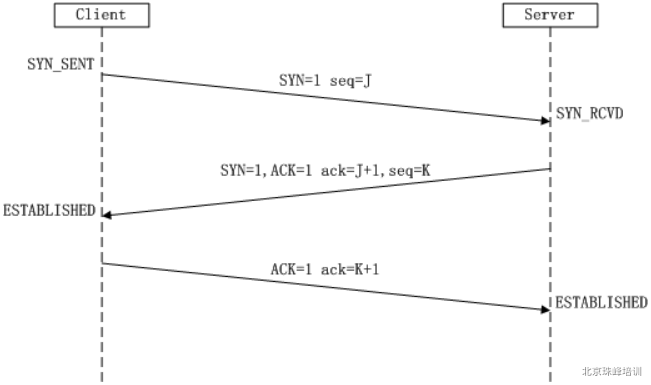
3. 三次握手 & 四次挥手
http 协议建立和断开连接时不是一次就完成的,连接时而是通过三次握手,断开时要经历四次挥手;
- 三次握手
- 第一次握手:客户端发送 syn 码数据包给服务器,客户端要求和服务器建立连接;
- 第二次握手:服务端接收到连接请求后,会发送 ack 码数据到客户端,表示你的连接请求已经收到,再次询问客户端是否确认建立连接
- 第三次握手:客户端收到服务器的 ack 码后,检验是否正确,如果正确则再次发送 ack 给服务器,表示确认连接;
三次握手如果成功,客户端和服务端的连接成功建立,才会开始传递数据;
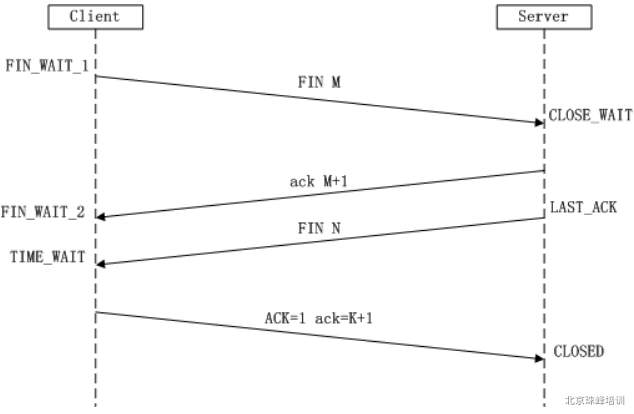
- 四次挥手:
- 当客户端发送数据结束后,会发送 fin 告知服务器,客户端要给服务器的数据传输完了;
- 服务端返回给客户端一个 ack 码,告知客户端已经知道数据传递完成。客户端收到 ack,就会把发送到服务端的通道关闭;
- 服务端数据传输结束后,也会发送 fin 给客户端;
- 当客户端收到 fin 后,会发送 ack 给服务端,表示客户端知道服务端已经发送完毕,服务器收到 ack 后就可以放心的关闭数据传输通道;
Connection: Keep-Alive 保持 TCP 不中断
4. 报文
HTTP 报文用于 http 协议交互的信息,因为 http 通信分为请求和响应两个阶段,所以报文分为两种: 请求报文和响应报文
报文分为:报文首部 空行 报文主体;
请求报文:
- 报文首部:请求首部分为请求行和请求头;请求行中包含 请求方法、协议、版本、URI
- 空行(CR+LF)
- 报文主体:客户端传递给服务端的数据
响应报文:
- 报文首部:状态行和响应头;状态行包含 http 协议版本,响应状态码
- 空行(CR+LF)
- 报文主体:响应体(服务端返回给客户端的数据)
五、浏览器渲染机制
遇到 link、img、audio、video 等是异步去加载资源信息(浏览器分配一个新的线程去加载,主线程会继续向下渲染页面),如果遇到的是 script 或者 @import ,则让主线程去加载资源信息(同步),加载完成信息后,再去渲染页面
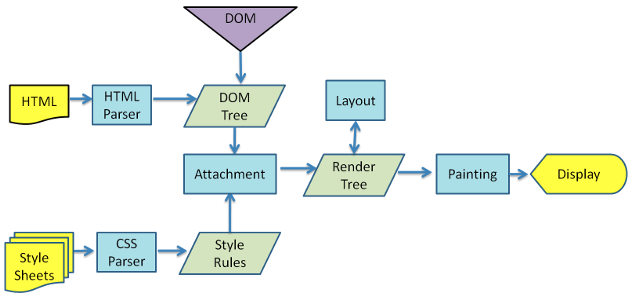
A:浏览器渲染页面的步骤
- 解析 HTML,生成 DOM 树,解析 CSS,生成 CSSOM 树
- 将 DOM 树和 CSSOM 树结合,生成渲染树(Render Tree)
- Layout (回流): 根据生成的渲染树,计算它们在设备视口(viewport)内的确切位置和大小,这个阶段是回流
- Painting (重绘): 根据渲染树以及回流得到的几何信息,得到节点的绝对像素
-
B:DOM的重绘和回流
重绘:元素样式的改变(但宽高、大小、位置等不变)
- 回流:元素的大小或者位置发生了变化(当页面布局和几何信息发生变化的时候),触发了重新布局,导致渲染树重新计算布局和渲染
-
C:前端性能优化之:避免DOM的回流
放弃传统操作 dom 的时代,基于 vue / react 开始数据影响视图模式
- 分离读写操作 (现代的浏览器都有渲染队列的机制)
- 样式集中改变
- 缓存布局信息
- 元素批量修改
- 动画效果应用到 position 属性为 absolute 或 fixed 的元素上(脱离文档流)
- CSS3 硬件加速(GPU加速)
- 牺牲平滑度换取速度
- 避免 table 布局和使用 css 的 javascript 表达式
六、如何构建一个网站
1. 网站结构

2. 客户端和服务器交互模型
3. web服务器配置
第一步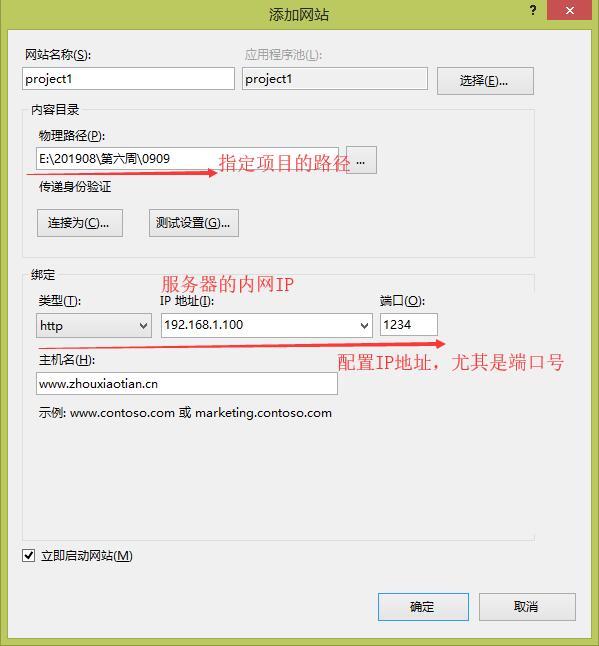
第二步

若有收获,就点个赞吧
0 人点赞
