1. 栈和队列
栈和队列都属于线性结构,它们的读取和操作方式与线性表有所区别
线性表可以不按照任何顺序,读取任意位置的元素,可以在指定位置插入元素。而栈和队列,需要按照它们特有的规则进行读取和插入
所以,栈和队都属于线性结构中特殊的限定性结构
栈的特点: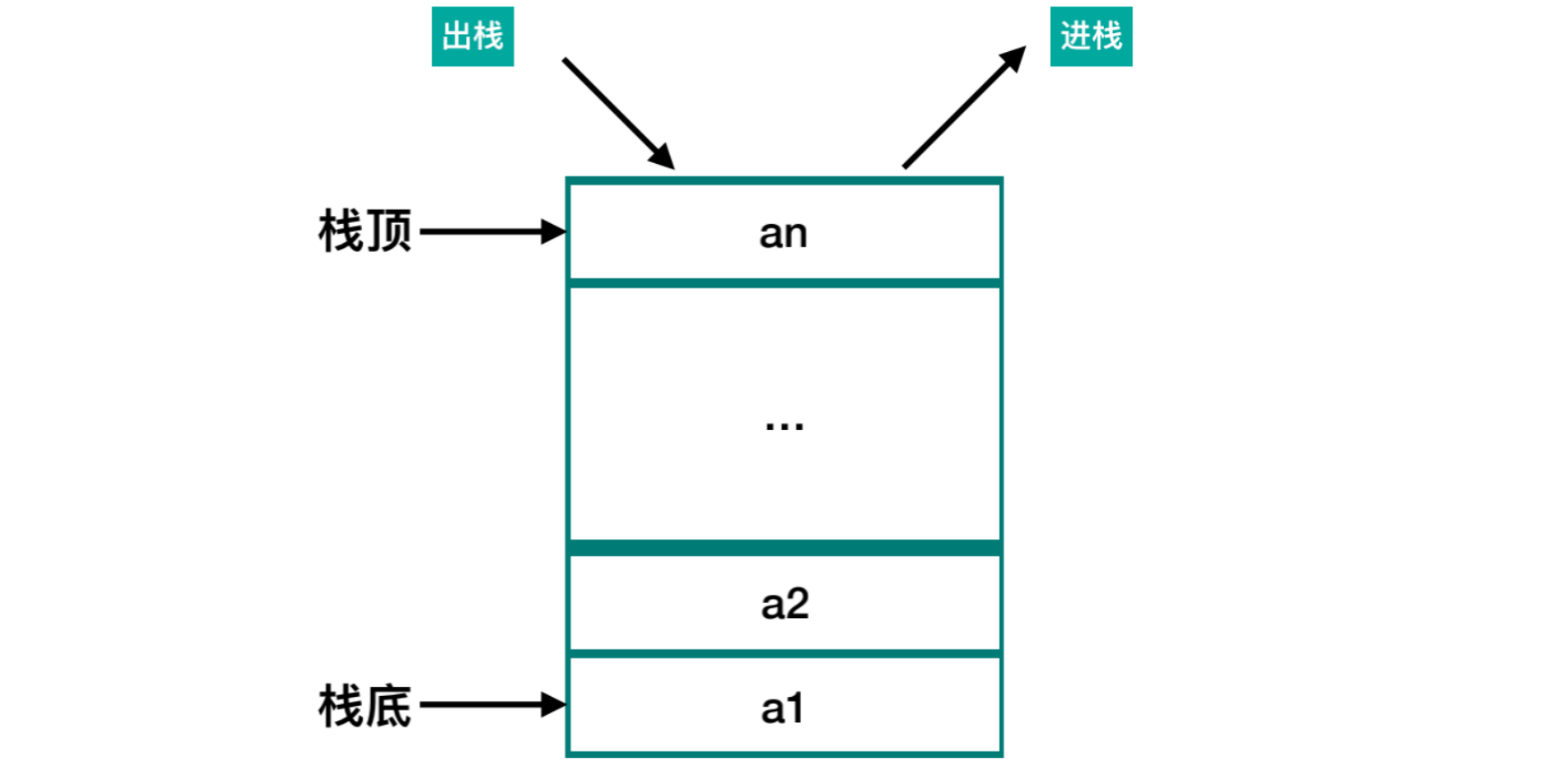
先进后出(
FILO)进栈与出栈只能针对栈顶进行操作
队列的特点: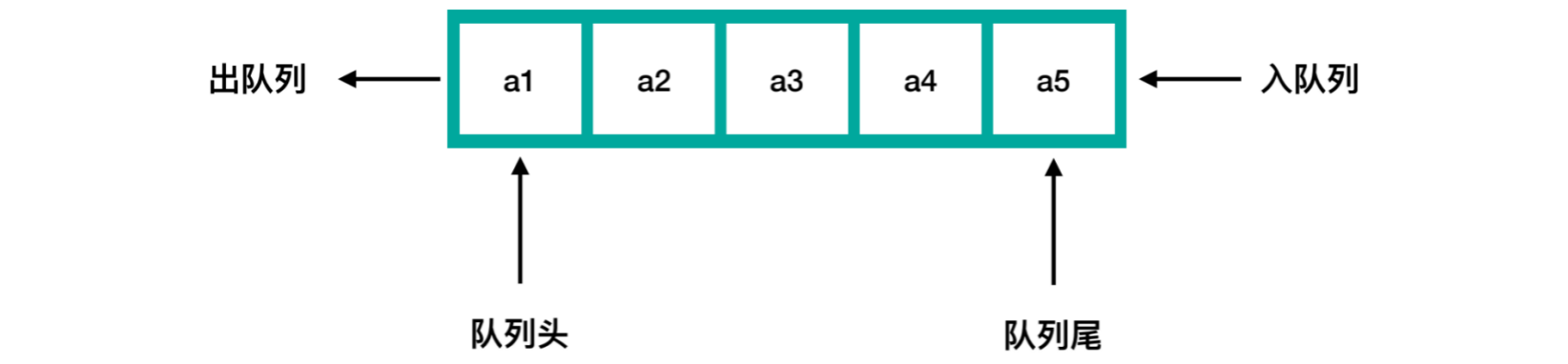
先进先出(
FIFO)只能操作队列头读取元素,不允许跳跃读取
插入元素必须追加到队列尾,不允许任意位置插入元素
2. 顺序栈
设计一个栈结构,可以采用顺序存储或链式存储,同时栈结构需要一个top指针
top指针可以是一个指针对象,也可以是一个标记top指针永远指向栈顶元素对于栈结构,不需要设置哨兵对象,因为它的唯一出口就是栈顶
栈结构的顺序存储: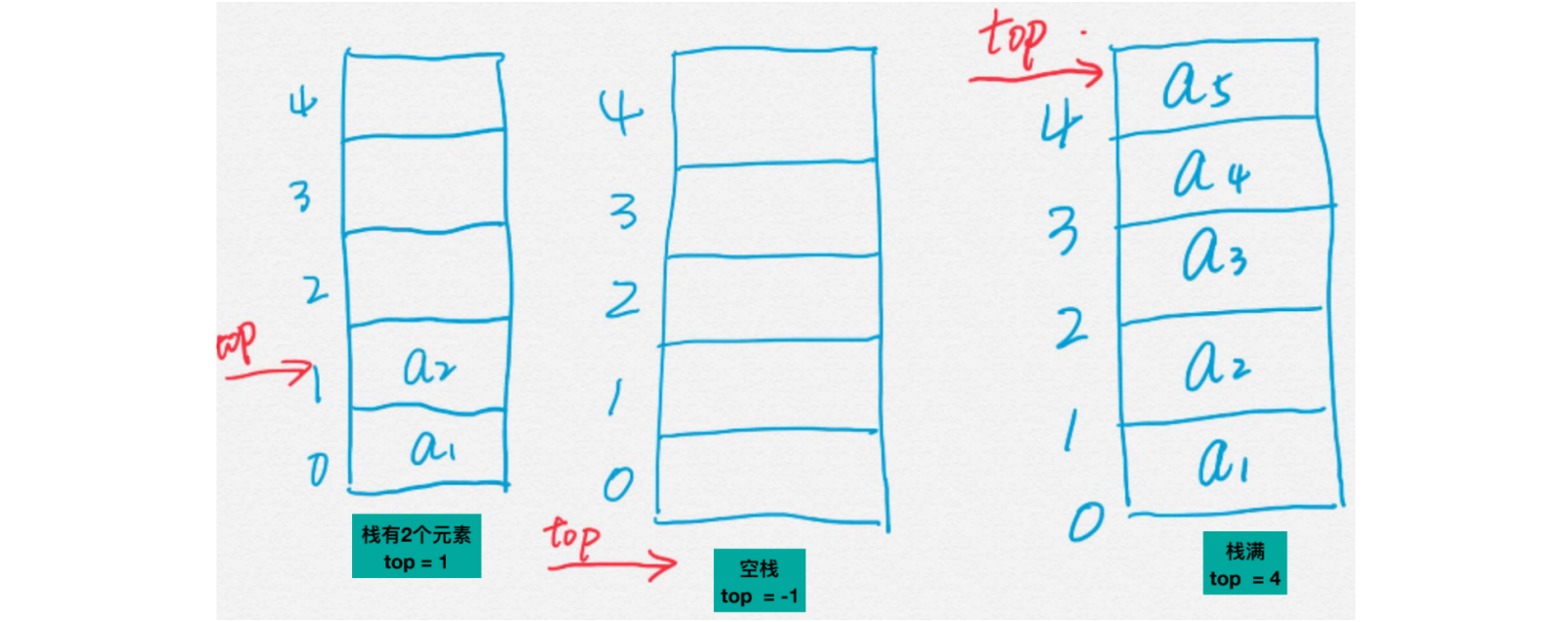
顺序栈需要开辟一段连续的内存空间
判断一个空栈,可以将
top设置一个标记,例如:-1当
top的位置等于连续空间的长度,表示栈满
2.1 创建
class Stack<Element> {fileprivate var _data : UnsafeMutablePointer<Element>;fileprivate var _capacity : Int;fileprivate var _top : Int;//获取栈的长度var length : Int {get{return _top + 1;}}//创建init(capacity : Int){_data = UnsafeMutablePointer<Element>.allocate(capacity: capacity);_capacity = capacity;_top = -1;}//是否为空栈func isEmpty() -> Bool {return _top == -1;}//是否栈满func isFull() -> Bool {return length == _capacity;}//清空栈func clear(){_top = -1;}}
2.2 获取栈顶元素
class Stack<Element> {
//获取栈顶元素
func getTop() -> Element? {
if(isEmpty()){
return nil;
}
return _data.advanced(by: _top).pointee;
}
}
2.3 压栈 & 出栈
class Stack<Element> {
//压栈
func push(element : Element) -> Int {
if(isFull()){
return ERROR;
}
_top += 1;
_data.advanced(by: _top).pointee = element;
return OK;
}
//出栈
func pop() -> Element? {
let data = getTop();
if(data == nil){
return data;
}
_top -= 1;
return data;
}
}
2.4 栈的遍历
class Stack<Element> {
//栈的遍历
func traverse() -> String {
var str : String = "";
if(isEmpty()){
return str;
}
for i in (0..<length).reversed() {
let val = _data.advanced(by: i).pointee;
str += "\(val),"
}
return str;
}
}
3. 链式栈
链式栈和顺序栈特性一致,结构也大致相同,只是存储方式不一样
设计一个链式栈,首先需要设计节点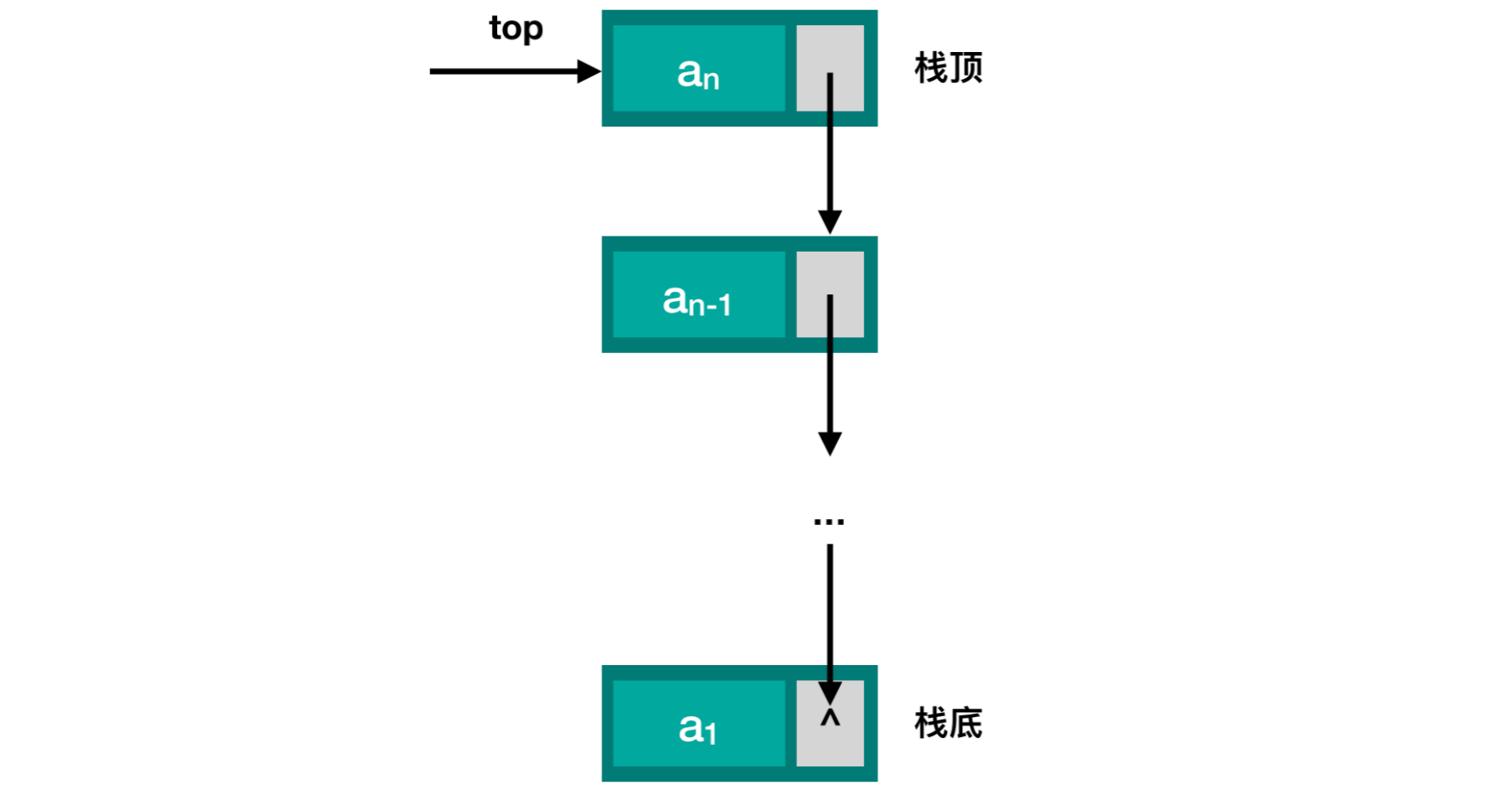
top指向栈顶,每个结点之间有next进行链接
3.1 创建
class LinkedStack<Element> {
fileprivate class Node<T> {
var next : Node<T>?;
var data : T;
init(data : T){
self.data = data;
self.next = nil;
}
deinit {
print("值为\(data)的Node释放");
}
}
fileprivate var _top : Node<Element>?;
fileprivate var _count : Int;
//获取栈的长度
var length : Int {
get{
return _count;
}
}
//创建
init() {
_count = 0;
}
//清空栈
func clear(){
_top = nil;
_count = 0;
}
//是否为空栈
func isEmpty() -> Bool {
return _count == 0;
}
}
3.2 获取栈顶元素
class LinkedStack<Element> {
//获取栈顶元素
func getTop() -> Element? {
if(isEmpty()){
return nil;
}
return _top?.data;
}
}
2.3 压栈 & 出栈
压栈操作: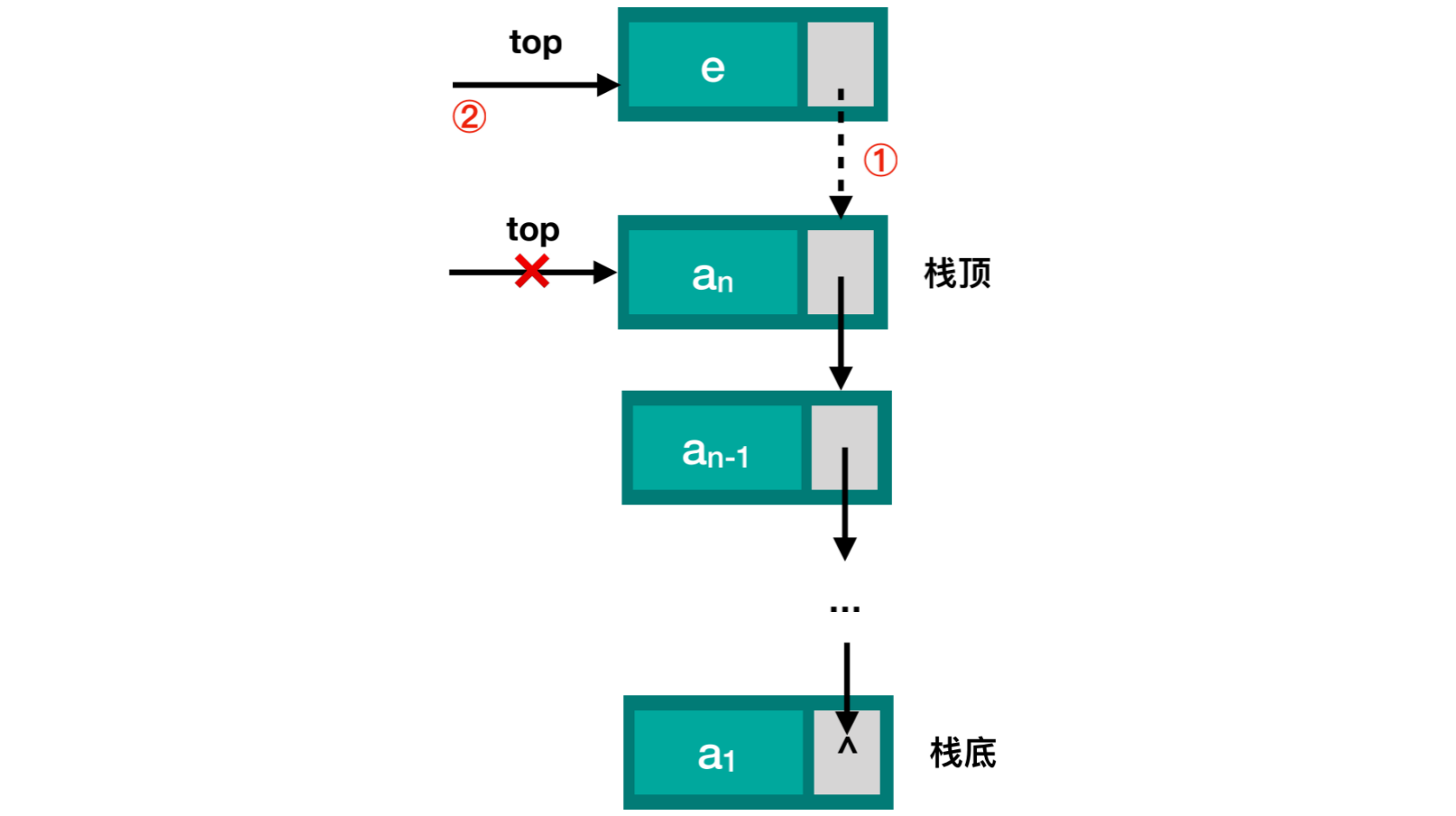
新结点的
next指向top栈顶将
top赋值为新结点
出栈操作: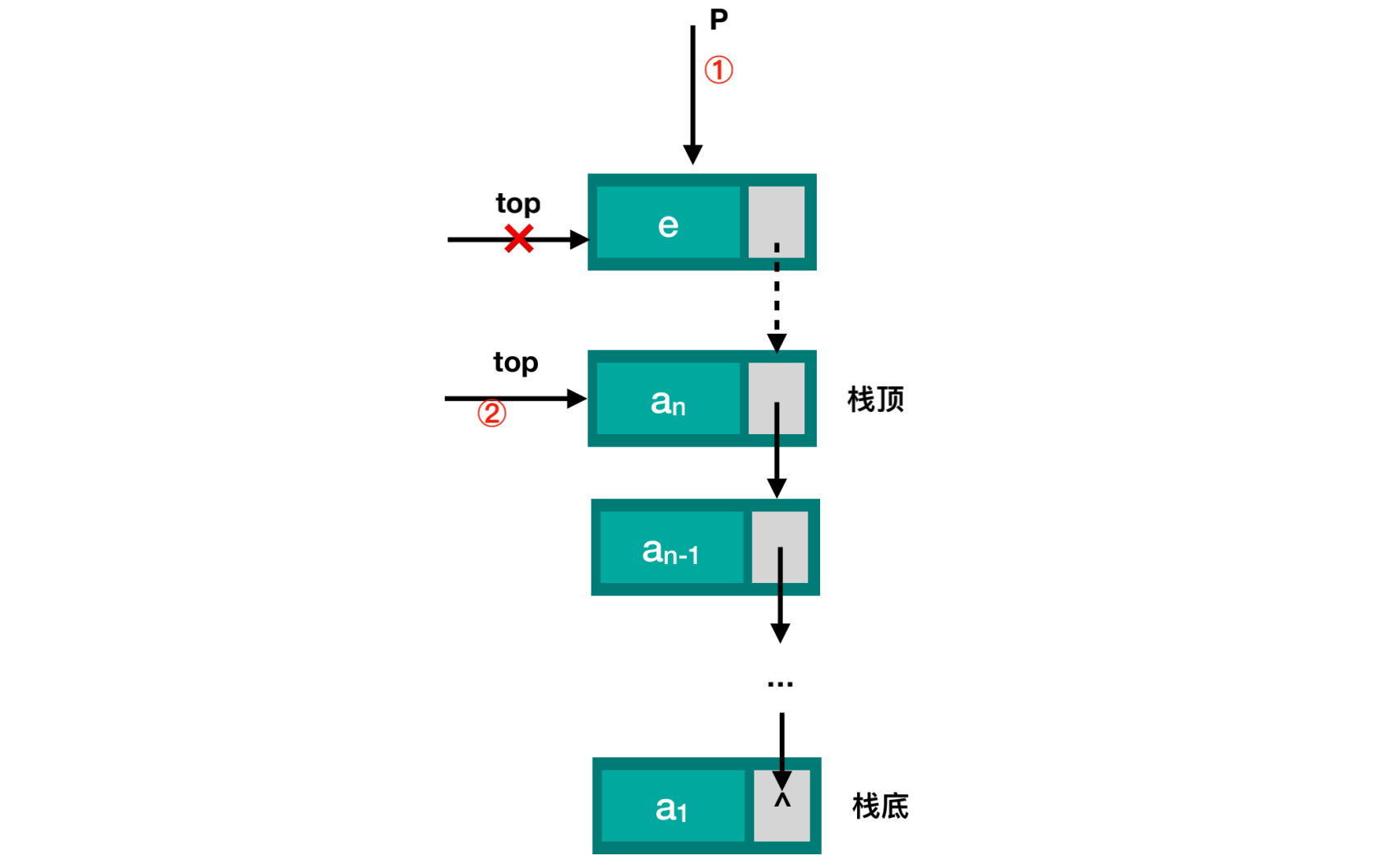
指针
p指向栈顶top指向栈顶的next结点释放
p指向的结点
代码实现:
class LinkedStack<Element> {
//压栈
func push(element : Element) -> Int {
let node = Node(data: element);
node.next = _top;
_top = node;
_count += 1;
return OK;
}
//出栈
func pop() -> Element? {
let data = getTop();
if(data == nil){
return data;
}
_top = _top?.next;
_count -= 1;
return data;
}
}
2.4 栈的遍历
class LinkedStack<Element> {
//栈的遍历
func traverse() -> String {
var str : String = "";
if(isEmpty()){
return str;
}
var node = _top;
while(node != nil){
str += "\(node!.data),"
node = node?.next;
}
return str;
}
}
4. 栈与递归
若在⼀个函数,过程或数据结构定义的内部⼜直接或间接出现定义本身的应⽤,则称之为递归或递归定义
理论上,任何递归代码都可以使用非递归的方式进行实现,那么使用递归的优势是什么?
递归求解本质上是使用系统提供的栈来实现的,由系统为我们自动递归求解。如果改成非递归的方式,那么我们其实就是在手动递归,本质上这两种方式没有任何区别。但是相同的逻辑,两份代码,递归实现明显更加地简洁,更加有利系统的维护
4.1 使用递归的场景
下⾯三种情况下,我们可以使⽤递归来解决问题:
定义是递归的。⽐如很多数学定义本身就是递归定义,例如:阶乘、斐波那契数列
数据结构是递归的。有些数据结构本身具有递归的特性,例如:链表、二叉树
问题是递归的。有⼀类问题,虽然问题本身并没有明显的递归结构,但是采样递归求解⽐迭代求解更简单。例如:汉诺塔问题、八皇后问题、迷宫问题
【示例1】阶乘:
long Fact(Long n){
if(n == 0) return 1;
else return n * Fact(n - 1);
}
若
n = 0,则返回1若
n > 1,则返回n * Fact(n - 1)
【示例2】⼆阶斐波那契数列:
long Fib(Long n){
if(n == 1 || n == 2) return 1;
else return Fib(n - 1) + Fib(n - 2);
}
若
n == 1或者n == 2,则返回1若
n > 2,则Fib(n - 1) + Fib(n - 2)
【示例3】链表其结点Node的定义:由数据域data和指针域next组成,⽽指针域next是⼀种指向Node类型的指针,即Node的定义中⼜⽤到了其⾃身,所以链表是⼀种递归的数据结构
void TraverseList(LinkList p){
//递归终⽌
if(p == NULL) return;
else{
//输出当前结点的数据域
printf("%d",p->data);
//p指向后继结点继续递归
TraverseList(p->next);
}
}
4.2 分治法
例如:在求解4时先求解3,然后再进⼀步分解进⾏求解,这种求解⽅式叫做”分治法”
算法中的分治法、动态规划法、蛮力法都是思想,使用代码实现时,分治法就会使用递归解决问题
使用分治法的满足条件:
一个问题可以分解为多个子问题,当前问题与其子问题除了数据规模不同外,求解思路完全一样
可以通过上述转换使问题变得简化
必须有⼀个明确的递归出⼝,或称为递归边界
示例:
void p(参数表){
if(递归结束条件成⽴) 可直接求解; //递归终⽌条件
else p(较⼩的参数); //递归步骤
}
在递归算法中,如果当递归结束条件成⽴,只执⾏return操作时,分治法求解递归问题算法⼀般形式可以简化为:
void p(参数表){
if(递归结束条件不成⽴)
p(较⼩参数);
}
例如:使用递归遍历链表:
void TraverseList(LinkList p){
if(p){
printf("%d",p->data);
TraverseList(p->next);
}
}
4.3 递归过程与递归工作站
一个递归函数,在函数的执行过程中,徐亚多次进行自我调用,此时递归函数是如何执行的?
了解递归函数的执行,先来了解一下任意两个函数之间的调用
通常,当一个函数的运行期间调用另一个函数时,在运行被调用函数之间,系统需要完成三件事情:
将所有的实参、返回地址等信息,传递给被调用函数并保存到栈空间
为被调用函数的局部变量分配存储空间
将控制转移到被调函数入口
从被调函数返回调用函数之前,系统同样需要完成三件事:
保存被调用函数的计算结果
释放被调用函数的数据区
依照被调用函数保存的返回地址,将控制移动到调用函数
当多个函数构成嵌套调⽤时,按照“先调⽤后返回”的原则,函数之间的信息传递和控制转移必须通过“栈”来实现。即系统将整个程序运⾏时的所需要的数据空间都安排在⼀个栈中
每当调⽤⼀个函数时,就在它的栈顶分配⼀个存储区。每当这个函数退出时,就释放它的存储区。则当前运⾏时的函数的数据区必在栈顶
【示例1】兔⼦繁衍问题(斐波那契数列)
如果兔⼦两个⽉之后就会有繁衍能⼒,那么⼀对兔⼦每个⽉能⽣出⼀对兔⼦。假设所有的兔⼦都不死,那么n个⽉后能⽣成多少只兔⼦?
代码实现:
#include <stdio.h>
int Fbi(int i){
if(i < 2)
return i == 0 ? 0 : 1;
return Fbi(i - 1) + Fbi(i - 2);
}
int main(int argc, const char * argv[]) {
printf("斐波那契数列!\n");
for (int i = 0; i < 10; i++) {
printf("%d,",Fbi(i));
}
printf("\n");
return 0;
}
调⽤分析: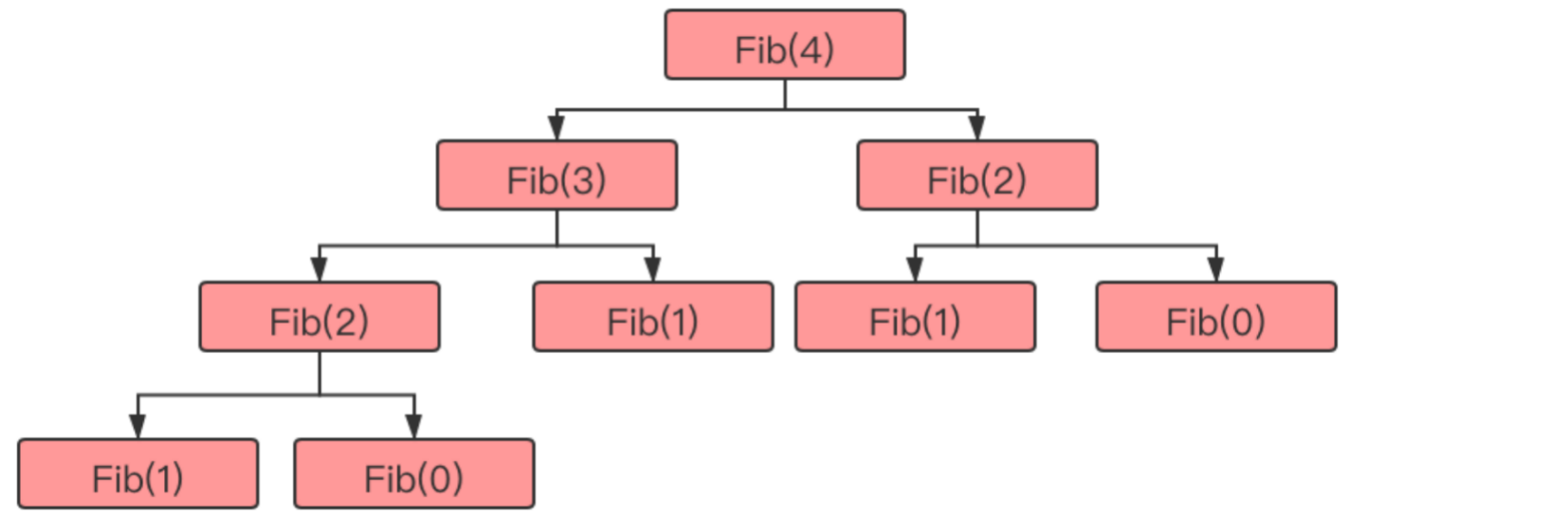
当调用
Fib(4)的时候,将其拆分成Fib(3)和Fib(2),依次向下拆分当拆分到
Fib(1)和Fib(0)的时候,才会一层一层的返回在系统中记录拆分后的结果,利用的就是栈结构。它可以帮助我们完成函数的调用和函数的嵌套,从而使函数调用之间不会发生错乱
【示例2】函数的嵌套调用
在主函数main中,调⽤函数first,⽽在函数first中⼜嵌套调⽤了second函数
int second(int d){
int x, y;
//...
}
int first(int s, int t){
int i;
//...
second(i);
//2.⼊栈
//...
}
void main(){
int m, n;
first(m, n);
//1.⼊栈
//...
}
当执⾏first函数时,保存了以下信息:
当执⾏second函数时,保存了以下信息: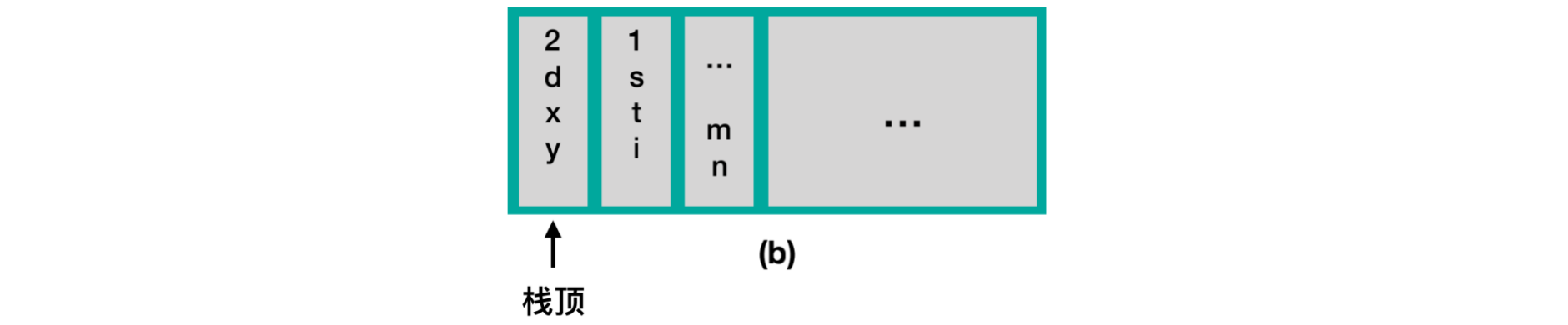
⼀个递归函数的运⾏过程,类似多个函数嵌套调⽤。只是调⽤函数和被调⽤函数是同⼀个函数。因此, 和每次调⽤相关的⼀个重要概念是递归函数运⾏的“层次”
假设调⽤该递归函数的主函数为第0层,则从主函数调⽤递归函数进⼊第1层,从第i层递归调⽤本函数为进⼊下⼀层,即第i + 1层。反之退出第i层递归应返回上⼀层,即第i - 1层
为了保证递归函数正确执⾏,系统需要设⽴⼀个“递归⼯作栈”,作为整个递归函数运⾏期间使⽤的数据存储区
每⼀层递归所需信息构成⼀个⼯作记录,其中包括所有的实参、所有的局部变量以及上⼀层的返回地址。每进⼊⼀层递归,就产⽣⼀个新的⼯作记录压⼊栈顶。每退出⼀个递归,就从栈顶弹出⼀个⼯作记录
则当前执⾏层的⼯作记录,必须是递归⼯作栈栈顶的⼯作记录,称为“活动记录”
5. 栈的思想应用
栈的思想应用:指的是利⽤栈先进后出的特性去解决问题,那么什么问题适合⽤栈思想解决了?
数据是线性的
问题中常常涉及到数据的来回⽐较、匹配问题。例如:每⽇温度、括号匹配、字符串解码、去掉重复字⺟等问题
问题中涉及到数据的转置,例如:进制问题、链表倒序打印问题等
注意:栈思想只是⼀个解决问题的参考思想,但它不是万能的。它适⽤于以上这样的情况下去解决问题
利⽤栈思想解决问题时,⾸先需要透彻的解析问题之后,找到问题解决的规律,才能使⽤它解决。思想只有指导作⽤,遇到不同的题⽬,需要个例分析,在基本思想上去找到具体问题具体的解决问题之道
总结
栈和队列:
- 栈和队都属于线性结构中特殊的限定性结构
栈的特点:
先进后出(
FILO)进栈与出栈只能针对栈顶进行操作
队列的特点:
先进先出(
FIFO)只能操作队列头读取元素,不允许跳跃读取
插入元素必须追加到队列尾,不允许任意位置插入元素
顺序栈:
top指针可以是一个指针对象,也可以是一个标记top指针永远指向栈顶元素对于栈结构,不需要设置哨兵对象,因为它的唯一出口就是栈顶
链式栈:
链式栈和顺序栈特性一致,结构也大致相同,只是存储方式不一样
top指向栈顶,每个结点之间有next进行链接
栈与递归:
- 若在⼀个函数,过程或数据结构定义的内部⼜直接或间接出现定义本身的应⽤,则称之为递归或递归定义
使用递归的场景:
定义是递归的。⽐如很多数学定义本身就是递归定义,例如:阶乘、斐波那契数列
数据结构是递归的。有些数据结构本身具有递归的特性,例如:链表、二叉树
问题是递归的。有⼀类问题,虽然问题本身并没有明显的递归结构,但是采样递归求解⽐迭代求解更简单。例如:汉诺塔问题、八皇后问题、迷宫问题
分治法:
例如:在求解4时先求解3,然后再进⼀步分解进⾏求解,这种求解⽅式叫做”分治法”
算法中的分治法、动态规划法、蛮力法都是思想,使用代码实现时,分治法就会使用递归解决问题
使用分治法的满足条件:
一个问题可以分解为多个子问题,当前问题与其子问题除了数据规模不同外,求解思路完全一样
可以通过上述转换使问题变得简化
必须有⼀个明确的递归出⼝,或称为递归边界
递归过程与递归工作站:
当一个函数的运行期间调用另一个函数时,在运行被调用函数之间,系统需要完成三件事情:
将所有的实参、返回地址等信息,传递给被调用函数并保存到栈空间
为被调用函数的局部变量分配存储空间
将控制转移到被调函数入口
从被调函数返回调用函数之前,系统同样需要完成三件事:
保存被调用函数的计算结果
释放被调用函数的数据区
依照被调用函数保存的返回地址,将控制移动到调用函数
当多个函数构成嵌套调⽤时,按照“先调⽤后返回”的原则,函数之间的信息传递和控制转移必须通过“栈”来实现。即系统将整个程序运⾏时的所需要的数据空间都安排在⼀个栈中
每当调⽤⼀个函数时,就在它的栈顶分配⼀个存储区。每当这个函数退出时,就释放它的存储区。则当前运⾏时的函数的数据区必在栈顶
⼀个递归函数的运⾏过程,类似多个函数嵌套调⽤。只是调⽤函数和被调⽤函数是同⼀个函数
为了保证递归函数正确执⾏,系统需要设⽴⼀个“递归⼯作栈”,作为整个递归函数运⾏期间使⽤的数据存储区
当前执⾏层的⼯作记录,必须是递归⼯作栈栈顶的⼯作记录,称为“活动记录”
栈的思想应用:
栈的思想应用:指的是利⽤栈先进后出的特性去解决问题
适⽤情况:
数据是线性的
问题中常常涉及到数据的来回⽐较,匹配问题。例如:每⽇温度、括号匹配、字符串解码、去掉重复字⺟等问题
问题中涉及到数据的转置,例如:进制问题、链表倒序打印问题等
栈思想只是⼀个解决问题的参考思想,但它不是万能的

若有收获,就点个赞吧
0 人点赞
