1. 做算法题的⽅法
充分阅读题⽬,了解题⽬背后的关键意思
分析题⽬,涉及到哪些数据结构,对问题进⾏分类。到底属于链表问题、栈思想问题、字符串问题、⼆叉树问题、图相关问题、排序问题,与你之前所接触过的算法题有没有类似,找到问题的解题思路
实现算法:在算法的实现的过程,并不是⼀蹴⽽就,肯定是需要不断的调试、修改
验证算法正确性
找到题源,看其他的开发者提供的解决思路
找到题解建议之后,对于其他优秀思路,分析它的优势,学习它的思路,并且写成其他解法的代码(借⼒, 不要单纯的闭⻔造⻋)
算法题的解题能⼒来⾃于两点:对于数据结构与算法核⼼问题是否夯实 + 是否有⾜够多且⾜够耐⼼的积累
例如:如果你连基本的链表操作都不知道,如何去解决链表翻转问题?如果你连图的存储、遍历等都不清楚,如何去解决图的最⼩路径问题?如果你都不了解⼆叉树,如果去计算⼆叉树的深度问题?
2. 算法练习
2.1 括号匹配检验
假设表达式中允许包含两种括号:圆括号与⽅括号,其嵌套顺序随意,即([]())或者[([][])]都是正确的,⽽这[(]或者(()])或者([())都是不正确的格式。检验括号是否匹配的⽅法,可⽤“期待的急迫程度”这个概念来描述。例如:考虑以下括号的判断[([][])]
代码实现:
let str = "(()])";let dic = ["[" : "]", "(" : ")"];let stack = LinkedStack<String>();for c in str {let s = "\(c)";if(stack.isEmpty()){stack.push(element: s);continue;}let key = stack.getTop()!;let val = dic[key];if(val == nil || val != s){stack.push(element: s);continue;}stack.pop();}print(stack.isEmpty() ? "匹配" : "不匹配");
在字典中定义括号的匹配关系,然后利用栈的先进先出原则进行匹配
遍历字符串,如果当前栈空,压栈
获取栈顶元素作为字典的
key,如果取不到val或val与当前字符不等,压栈如果
val和当前字符相等,出栈遍历后如果栈为空,表示匹配成功,否则匹配失败
2.2 每⽇⽓温
根据每⽇⽓温列表,请重新⽣成⼀个列表,对应位置的输⼊是你需要再等待多久温度才会升⾼超过该⽇的天数。如果之后都不会升⾼,请在该位置0来代替
示例:
//给定气温列表temperatures = [73, 74, 75, 71, 69, 72, 76, 73]//输出结果[1, 1, 4, 2, 1, 1, 0, 0]
提示:⽓温列表⻓度的范围是[1, 30000]。每个⽓温的值的均为华⽒度,都是在[30, 100]范围内的整数
2.2.1 暴力破解法
let temperatures = [73, 74, 75, 71, 69, 72, 76, 73];var arrResult : [Int] = Array();for i in 0 ..< temperatures.count {let cur = temperatures[i];var jump = 0;if(i > 0 && cur == temperatures[i - 1]){let preResult = arrResult[i - 1];jump = preResult == 0 ? 0 : preResult - 1;arrResult.append(jump);continue;}for j in (i + 1) ..< temperatures.count {let next = temperatures[j];if(cur < next){jump = j - i;break;}}arrResult.append(jump);}print("\(arrResult)");
2.2.3 跳跃对比法
let temperatures = [73, 74, 75, 71, 69, 72, 76, 73];var arrResult : [Int] = Array.init(repeating: 0, count: temperatures.count);for i in (0 ..< temperatures.count - 1).reversed() {let cur = temperatures[i];var jump = 1;var next = temperatures[i + jump];if(cur < next){arrResult[i] = jump;continue;}var nextResult = arrResult[i + jump];if(nextResult == 0){continue;}while(nextResult > 0 && cur >= next){jump += nextResult;next = temperatures[i + jump];nextResult = arrResult[i + jump];}arrResult[i] = jump;}print("\(arrResult)");
2.2.4 栈思想解决
let temperatures = [73, 74, 75, 71, 69, 72, 76, 73];var arrResult : [Int] = Array.init(repeating: 0, count: temperatures.count);var stack = LinkedStack<[Int]>();for i in 0 ..< temperatures.count {let cur = temperatures[i];while(!stack.isEmpty()){let top = stack.getTop()!;if(top[1] > cur){break;}let index = top[0];arrResult[index] = i - index;stack.pop();}stack.push(element: [i, cur]);}stack.clear();print("\(arrResult)");
2.3 爬楼梯问题
假设你正在爬楼梯。需要n阶你才能到达楼顶。每次你可以爬1或2个台阶。你有多少种不同的⽅法可以爬到楼顶呢?注意:给定n是⼀个正整数å
示例1:
输⼊:2输出:2解释:有2种⽅法可以爬到楼顶1. 1阶 + 1阶2. 2阶
示例2:
输⼊:3输出:3解释:有3种⽅法可以爬到楼顶1. 1阶 + 1阶 + 1阶2. 1阶 + 2阶3. 2阶 + 1阶
2.3.1 递归法
func algorithm(n : Int) -> Int {if(n <= 2){return n;}return algorithm(n: n - 1) + algorithm(n: n - 2);}
公式可拆解为:
f(n) = f(n - 1) + f(n - 2)f(1) = 1f(2) = 2
2.3.2 动态规划法
动态规划(Dynamic programming,简称DP)是⼀种在数学、管理科学、计算机科学、经济学和⽣物信息学中使⽤的,通过把原问题分解为相对简单的⼦问题的⽅式求解复杂问题的⽅法
动态规划常常适⽤于有重叠⼦问题和最优⼦结构性质的问题,动态规划⽅法所耗时间往往远少于朴素解法
动态规划背后的基本思想⾮常简单。⼤致上,若要解⼀个给定问题,我们需要解其不同部分(即⼦问题),再根据⼦问题的解以得出原问题的解。动态规划往往⽤于优化递归问题,例如斐波那契数列,如果运⽤递归的⽅式来求解会重复计算很多相同的⼦问题,利⽤动态规划的思想可以减少计算量
通常许多⼦问题⾮常相似,为此动态规划法试图仅仅解决每个⼦问题⼀次,具有天然剪枝的功能,从⽽减少计算量
⼀旦某个给定⼦问题的解已经算出,则将其记忆化存储,以便下次需要同⼀个⼦问题解之时直接查表。这种做法在重复⼦问题的数⽬关于输⼊的规模呈指数增⻓时特别有⽤
动态规划法的三个核心要素:
找到最优子结构(可以将问题拆解,找到最优的拆解方式)
找到算法的边界(结束条件)
状态转移方程式
案例中f(n) = f(n - 1) + f(n - 2)公式,属于从上至下的拆解方式。这个问题也可以被分解为⼀些包含最优⼦结构的⼦问题,即它的最优解可以从其⼦问题的最优解来有效地构建,从而使⽤动态规划来解决这⼀问题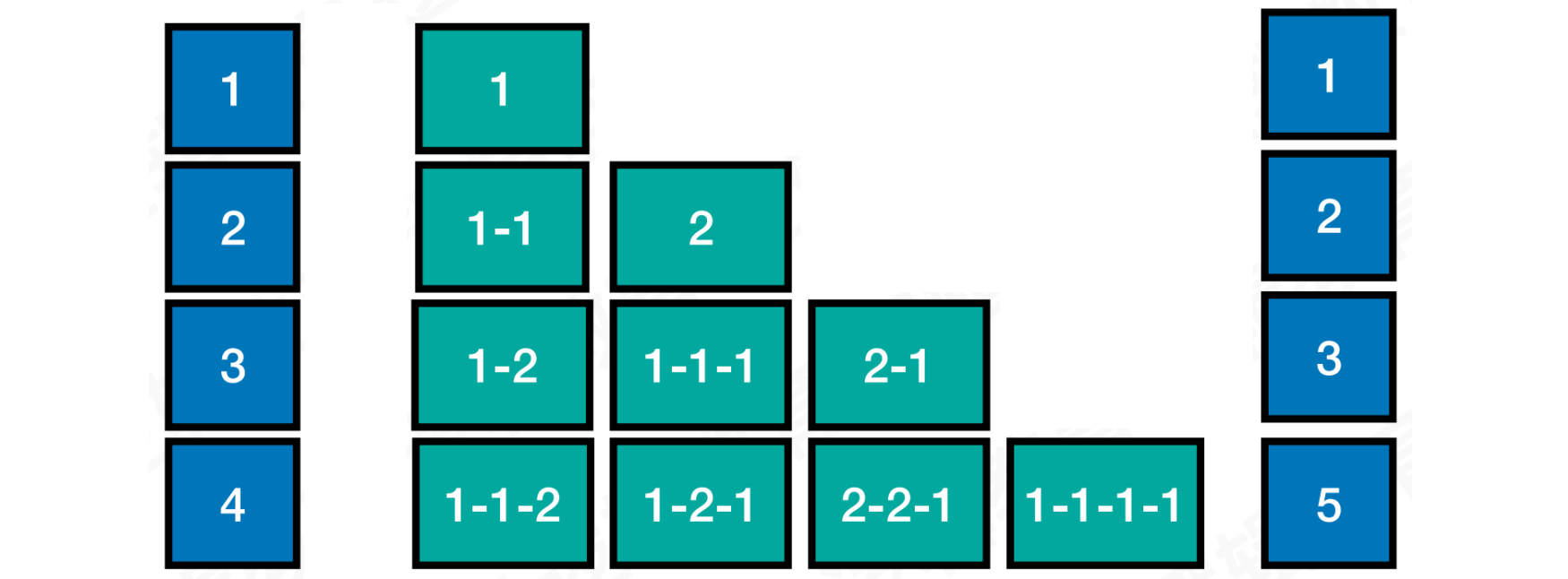
假设爬 n个台阶有f(n)个可能:
假设先爬
1阶, 剩下n-1阶有f(n-1)种可能假设先爬
2阶,剩下n-2阶有f(n-2)种可能
因此爬n阶可以转化成两种,爬n-1问题和n-2问题
代码实现:
func algorithm(n : Int) -> Int {var n1 = 1;var n2 = 2;if(n == 1){return n1;}for _ in 3 ... n {let tmp = n2;n2 += n1;n1 = tmp;}return n2;}
动态规划法中的n1、n2为已知结果,通过已知结果计算n阶结果,时间复杂度为O(n)。而递归法,相当于在下楼过程中层层拆解,时间复杂度为O(n ^ 2)
2.4 进制转换
将给定数字转为二进制
示例:
输⼊:17输出:10001
代码实现:
var n = 17;var stack = LinkedStack<Int>();while(n > 0){stack.push(element: n % 2);n = n / 2;}var result = "";while(!stack.isEmpty()){result += "\(stack.getTop()!)";stack.pop();}print(result);
2.5 杨辉三角
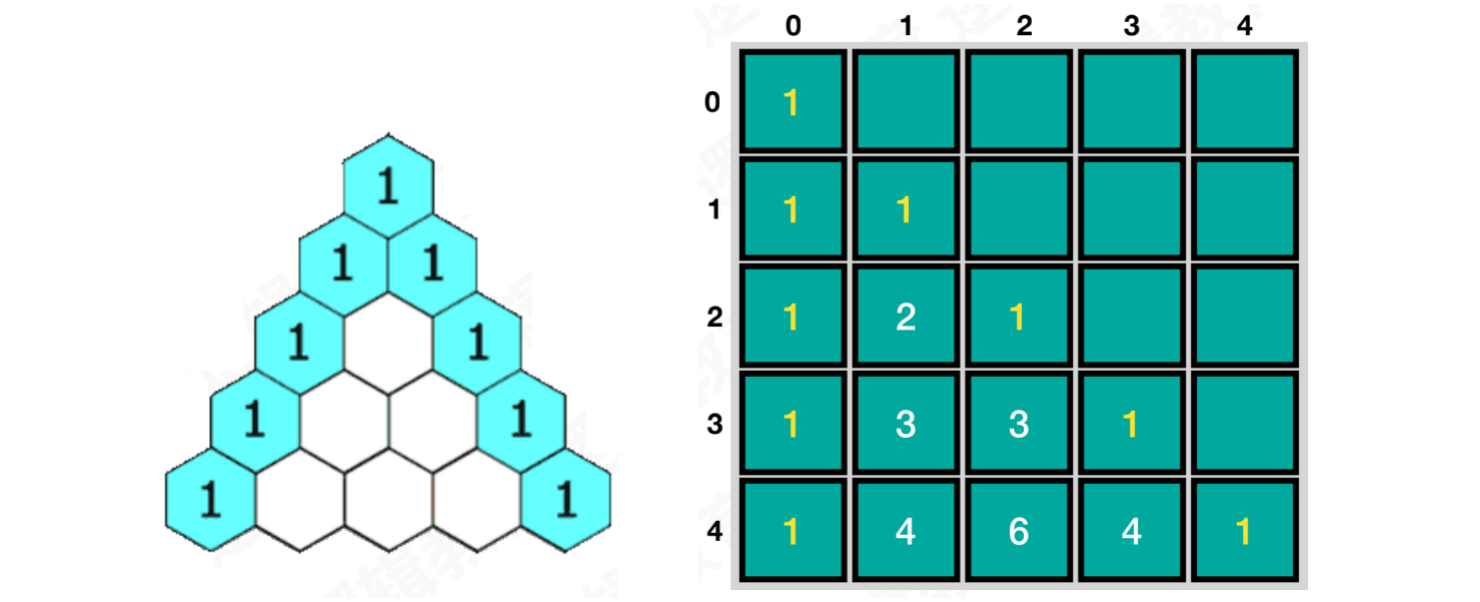
代码实现:
var n = 5;var arr = [[Int]](repeating: [Int](repeating: 0, count: n), count: n);for i in 0 ..< n {arr[i][0] = 1;if(i == 0){continue;}arr[i][i] = 1;for j in 1 ..< i {arr[i][j] = arr[i - 1][j - 1] + arr[i - 1][j];}}
2.6 字符串编码
给定⼀个经过编码的字符串,返回它解码后的字符串
编码规则为k[encoded_string],表示其中⽅括号内部的encoded_string正好重复k次。 注意:k保证为正整数
你可以认为输⼊字符串总是有效的,输⼊字符串中没有额外的空格, 且输⼊的⽅括号总是符合格式要求的。此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数k,不会出现像3a或2[4]的输⼊
示例:
s = "3[a]2[bc]"返回 "aaabcbc"s = "3[a2[c]]"返回 "accaccacc"s = "2[abc]3[cd]ef"返回 "abcabccdcdcdef"s = "a3[b]2[c1[d1[e]]f]10[g]x2[y]z"返回 "abbbcdefcdefggggggggggxyyz"
代码实现:
let str = "a3[b]2[c1[d1[e]]f]10[g]x2[y]z";var stack = LinkedStack<String>();var result = "";for c in str {if(c == "["){stack.push(element: result);result = "";continue;}if(c != "]"){result += "\(c)";continue;}let letter = result;result = "";let top = stack.pop()!;var number = "";for t in top.reversed() {if(t >= "0" && t <= "9"){number = "\(t)" + number;continue;}break;}if(top.count > number.count){result += top.prefix(top.count - number.count);}for _ in 0 ..< Int.init(number)! {result += letter;}}print(result);
2.7 去除重复字⺟
给你⼀个仅包含⼩写字⺟的字符串,请你去除字符串中重复的字⺟,使得每个字⺟只出现⼀次。需保证返回结果的字典序最⼩,要求不能打乱其他字符的相对位置
示例:
输⼊:"bcabc"
输出:"abc"
输⼊:"cbacdcbc"
输出:"acdb"
代码实现:
let str = "bcacdcbc";
var dic = [String : Int]();
for c in str {
if(dic["\(c)"] == nil){
dic["\(c)"] = 1;
continue;
}
let count = dic["\(c)"]!;
dic["\(c)"] = count + 1;
}
var result = "";
for i in 0 ..< str.count {
let c = str[i];
let count = dic[c]!;
if(count == 1){
dic.removeValue(forKey: c);
}
else{
dic[c] = count - 1;
}
if(result.isEmpty){
result += c;
continue;
}
var isExist = false;
for j in (0 ..< result.count).reversed() {
if(result[j] == c){
isExist = true;
break;
}
}
if(isExist){
continue;
}
var j = result.count - 1;
while(!result.isEmpty && result[j] > c && dic[result[j]] != nil){
result = String(result.prefix(j));
j = result.count - 1;
}
result += c;
}
print(result);
实现字符串扩展,支持使用下标截取字符串
extension String {
subscript (i:Int)->String{
let startIndex = self.index(self.startIndex, offsetBy: i)
let endIndex = self.index(startIndex, offsetBy: 1)
return String(self[startIndex..<endIndex])
}
subscript (r: Range<Int>) -> String {
get {
let startIndex = self.index(self.startIndex, offsetBy: r.lowerBound)
let endIndex = self.index(self.startIndex, offsetBy: r.upperBound)
return String(self[startIndex..<endIndex])
}
}
subscript (index:Int , length:Int) -> String {
get {
let startIndex = self.index(self.startIndex, offsetBy: index)
let endIndex = self.index(startIndex, offsetBy: length)
return String(self[startIndex..<endIndex])
}
}
func substring(to:Int) -> String{
return self[0..<to]
}
func substring(from:Int) -> String{
return self[from..<self.count]
}
}
2.8 字符串匹配
给你⼀个仅包含⼩写字⺟的字符串主串S = "abcacabdc",模式串T = "abd",请查找出模式串在主串第⼀次出现的位置
提示:主串和模式串均为⼩写字⺟且都是合法输⼊
示例:
S = "abcacabdc"
T = "abc"
返回 1
S = "abcacabdc"
T = "abd"
返回 6
2.8.1 BF算法
BF算法,即暴力(Brute Force)算法,是普通的模式匹配算法
BF算法的思想就是将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和T的第二个字符。若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果。BF算法是一种蛮力算法
代码实现:
let str = "abcacabdc";
let t = "abd";
var result = 0;
var i = 0;
var j = 0;
while(i < str.count && j < t.count){
if(str[i] == t[j]){
i += 1;
j += 1;
continue;
}
i = i - j + 1;
j = 0;
}
if(j == t.count){
result = i - j + 1;
}
print("\(result)");
2.8.2 RK算法
HASH:如果两个字符串HASH后的值不相同,则它们肯定不相同。如果它们HASH后的值相同,它们不一定相同
RK算法的基本思想就是:将模式串T的HASH值跟主串S中的每一个长度为T的子串的HASH值比较。如果不同,则它们肯定不相等。如果相同,则将原文逐位比较
不考虑溢出情况的简单实现:
let str = "abcacabdc";
let t = "abd";
let basics = Int(Character.init("a").asciiValue!);
let radix = 26;
let max = Int(pow(Double(radix), Double(t.count - 1)));
var hash = 0;
var result = 0;
var tmp = 0;
for i in 0 ..< t.count {
let o = Double(t.count - i - 1);
var c = Int(Character(str[i]).asciiValue!) - basics;
tmp += c * Int(pow(Double(radix), o));
c = Int(Character(t[i]).asciiValue!) - basics;
hash += c * Int(pow(Double(radix), o));
}
for i in 0 ... str.count - t.count {
if(i > 0){
let x = Int(Character(str[i - 1]).asciiValue!) - basics;
let c = Int(Character(str[i + t.count - 1]).asciiValue!) - basics;
tmp = (tmp - x * max) * radix + c;
}
if(tmp == hash){
result = i + 1;
break;
}
}
print("\(result)");
将主串按照模式串的长度进行拆分
使用以下公式得到
HASH值例如:主串为
abcd,模式串为bcd将当前字母的
ASCII码减去字母a的ASCII码,得到0 ~ 25的值将数字分别乘以
26的n次方,n为拆分后的字符串长度 - 当前字母所在位置 - 1计算
abc的HASH值:hash = 0 * (26 ^ 2) + 1 * (26 ^ 1) + 2 * (26 ^ 0)结果不匹配,进行
bcd的HASH值:hash = (hash - 0 * (26 ^ 2)) * 26 + 3
这种方式的好处是,以模式串的长度为基础拆分出的主串计算的HASH值不会出现冲突,缺陷是字符串过长计算出的HASH值会溢出
如果考虑溢出问题,我们需要缩短HASH计算后的数字大小,但会增加出现HASH冲突的情况
解决溢出情况的代码实现:
let str = "abcacabdc";
let t = "abd";
let basics = Int(Character.init("a").asciiValue!);
var hash = 0;
var result = 0;
var tmp = 0;
for i in 0 ..< t.count {
var c = Int(Character(str[i]).asciiValue!) - basics;
tmp += c;
c = Int(Character(t[i]).asciiValue!) - basics;
hash += c;
}
for i in 0 ... str.count - t.count {
if(i > 0){
let x = Int(Character(str[i - 1]).asciiValue!) - basics;
let c = Int(Character(str[i + t.count - 1]).asciiValue!) - basics;
tmp = (tmp - x) + c;
}
if(tmp != hash){
continue;
}
var isSucceed = true;
for j in 0 ..< t.count {
if(str[i + j] != t[j]){
isSucceed = false;
break;
}
}
if(isSucceed){
result = i + 1;
break;
}
}
print("\(result)");
将主串按照模式串的长度进行拆分
将当前字母的
ASCII码减去字母a的ASCII码,得到0 ~ 25的值将拆分后的字符串,直接按照
0 ~ 25的值进行累加得到HASH值当拆分后的主串和模式串的
HASH值相等,还要匹配两个字符串中的字符是否一致,避免HASH冲突的情况

若有收获,就点个赞吧
0 人点赞
