添加扩展模型
在 M.A.R.K 积木标签的底部,有一个“+扩展”的按钮。
点击可以打开“扩展中心”的弹窗,可以看到“扩展模型”的入口,用鼠标单击“+ 添加”。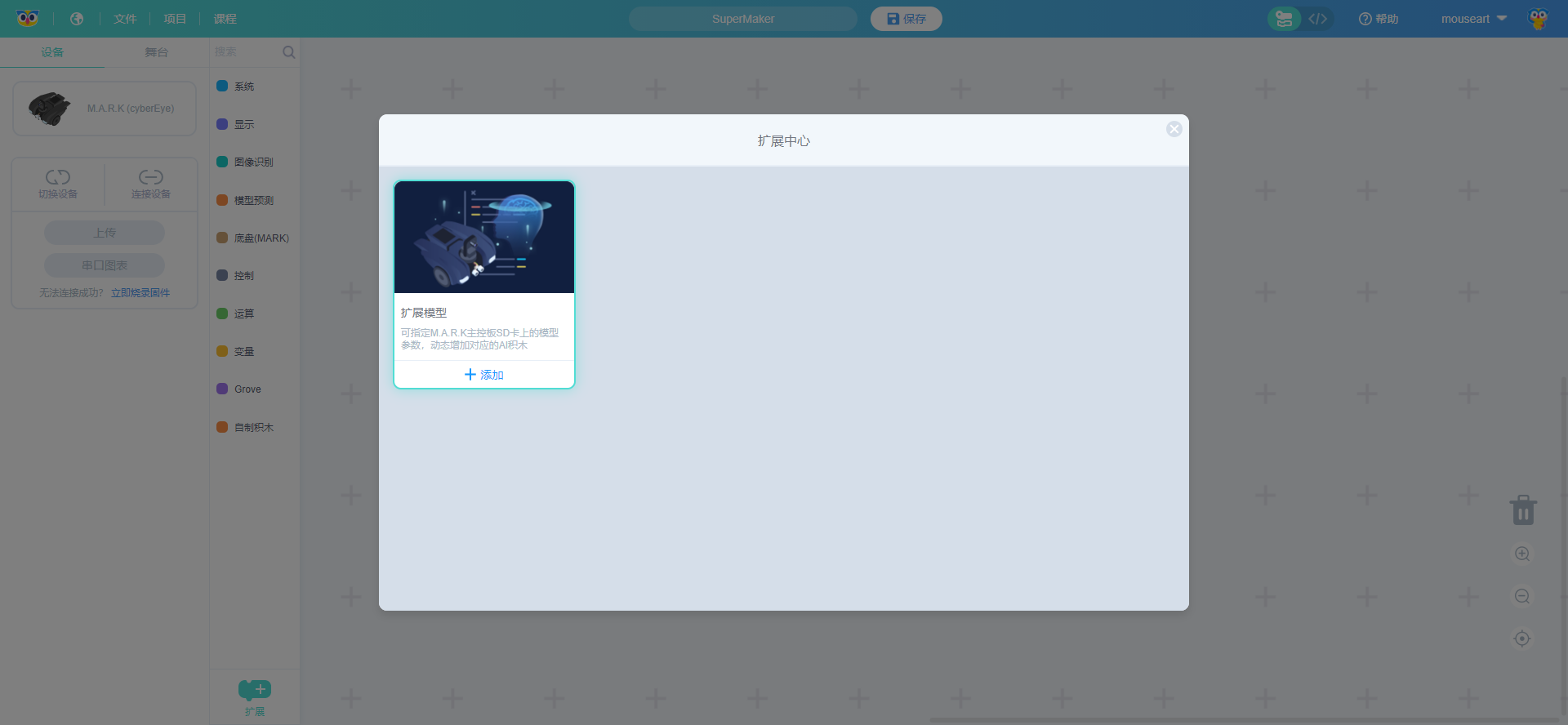
积木标签栏增加了“扩展模型”的分类,里面可以看到“图像分类模型”,“物体检测模型”和“本地训练”三个功能。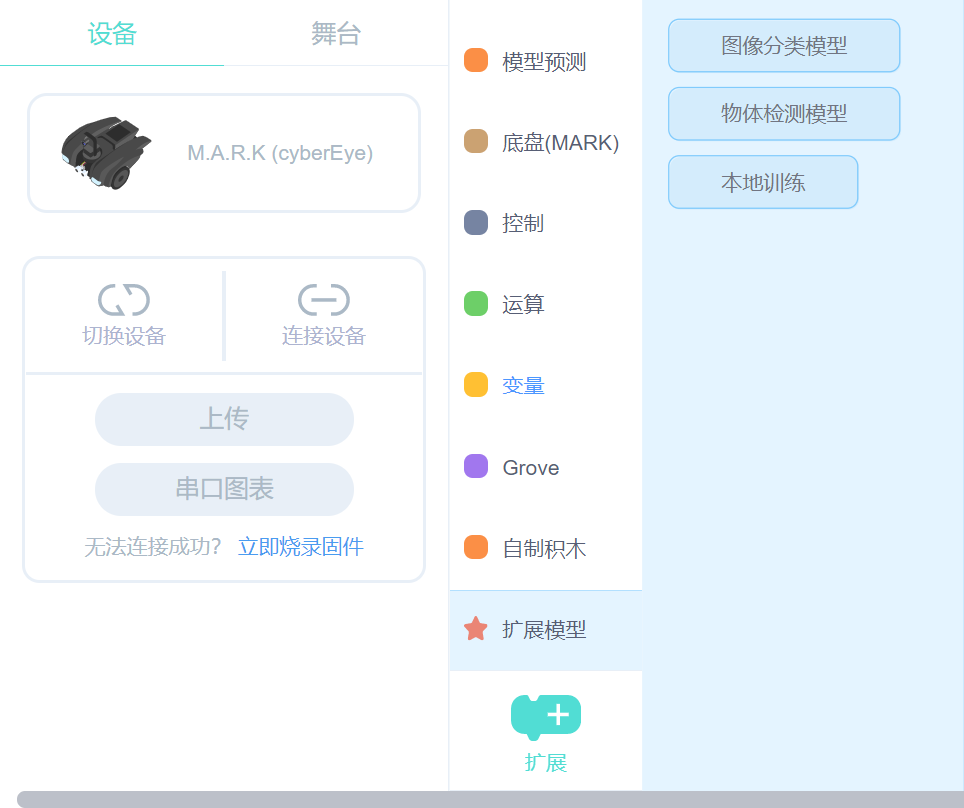
这3个扩展模块可以帮助用户扩展 M.A.R.K 图像识别和物体检测可支持的范围。
图像分类模型
图像分类模型将整个图像分为众类别中的一类——如果您的任务是想要确定 M.A.R.K 前面的物体是苹果还是香蕉,那么这就是您需要的模型。
- 图像分类模型也称为图像识别模型,只是名称不同。
- 由于图像分类模型对整个图像进行分类,因此模型仅在物体足够近且占据图像很大一部分时才能可靠地运行。当物体距离太远时则会无法运行。
- 用于训练图像分类模型的数据集由在各自文件夹中分类的不同图像类别的图片组成。
点击“扩展模型”标签里的 图像分类模型 按钮,可以进入“图像分类模型”的窗口,如下图所示。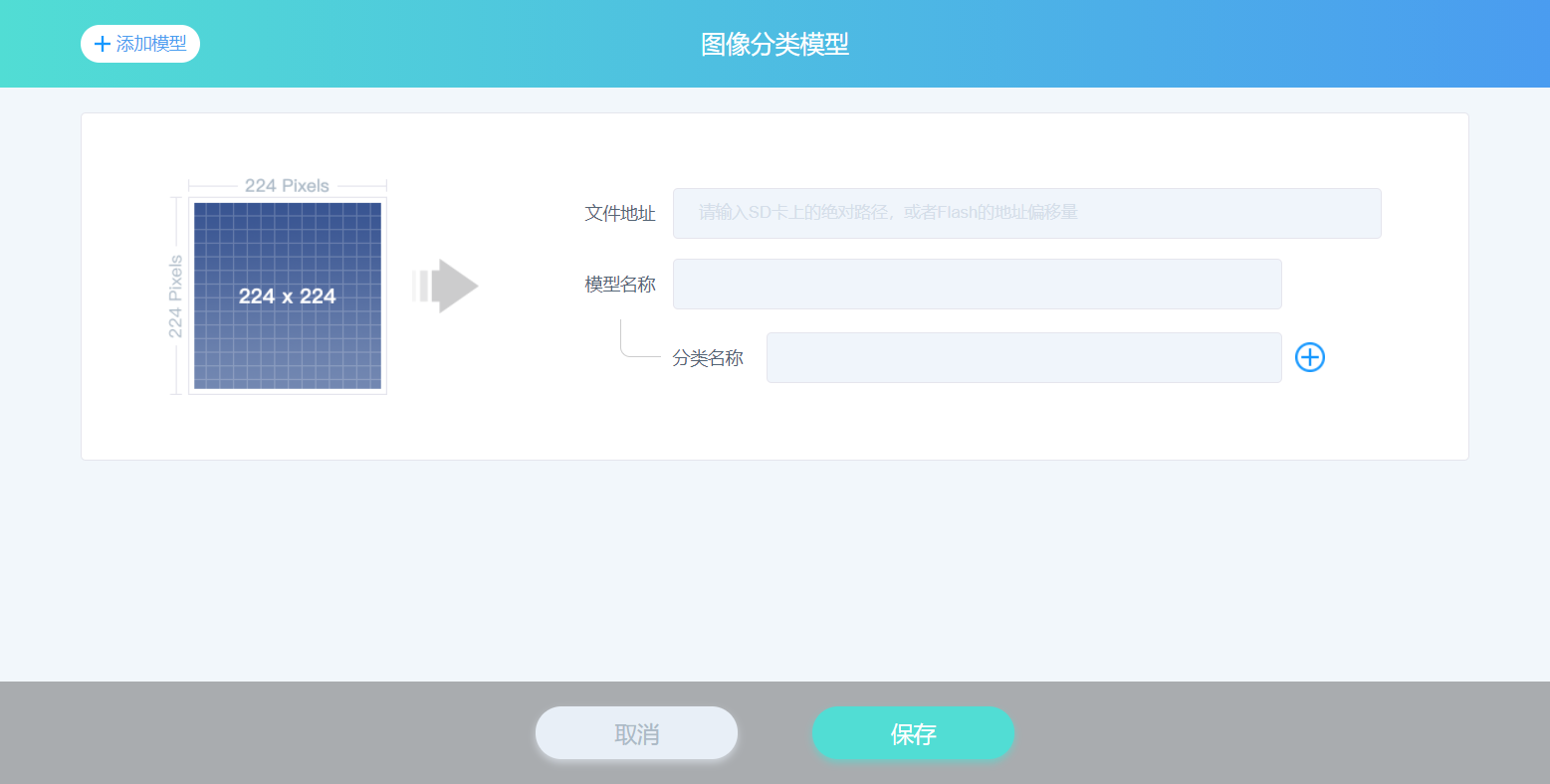
- 文件地址:是 SD 卡上文件的路径,例如,/sd/我的模型.kmodel 或是设备闪存中模型的地址,例如,0x800000
- 模型名称:是会出现在 Codecraft 界面的名称
- 分类名称:是分类的名称,必须在训练过程中顺序一样。例如,在训练过程中如果有【“狗” “猫” “苹果”】类别,那分类就需要是这种顺序!
例如添加识别几种花朵(玫瑰,百合,郁金香)的图像分类模型,相关信息填写如下图所示。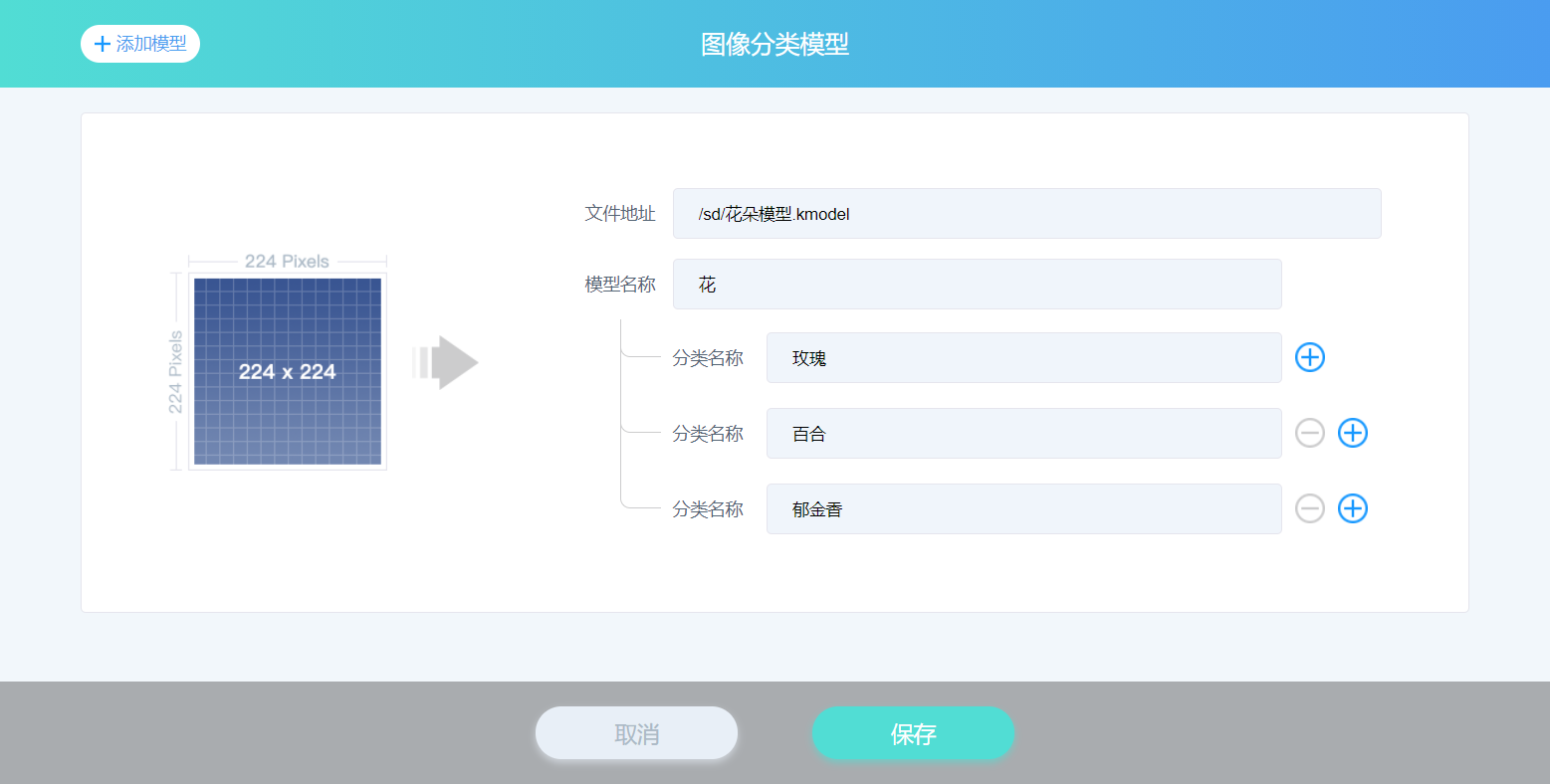
保存后,在“扩展模型”标签栏,多了两个新增的积木块,如下图所示。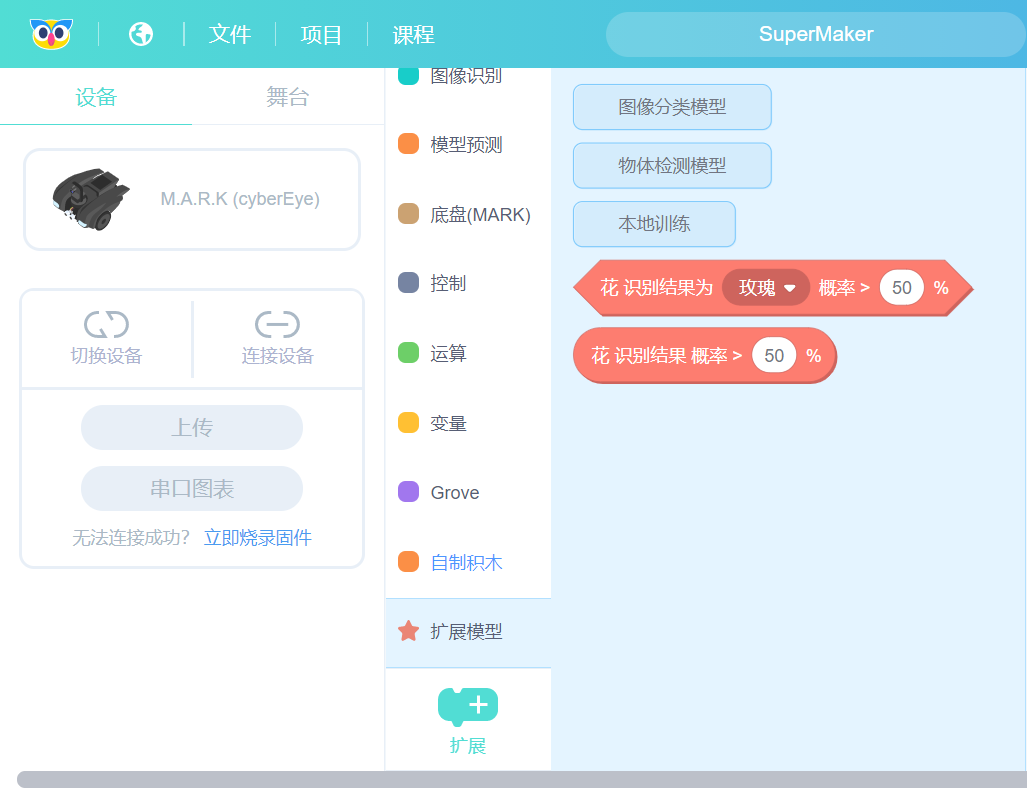
积木块:模型名称 识别结果为 (类别名称)概率 > 50%

含义: 如果图像中用户定义的类别的概率大于指定值,则返回TRUE(1)或FALSE(0)的值。
类型: 布尔
积木块:模型名称 识别结果为 概率 > 50%

含义: 如果该类别概率大于指定值,则返回带有用户定义分类名称的字符串。
类型: 数据
返回范围: [在分类名称中定义]
返回类型: 文本字符串
提示:
- 如果概率小于指定值,则返回值-1
有关使用自定义图像分类模型的更多示例,请参阅:
示例项目:Donkey MARK(自定义图像分类模型推断)
物体检测模型
物体检测模型分析整个图像,并为图像的每个网格单元输出一组预测。预测包括物体存在于该单元格中的概率、其坐标和类别。
- 如果您的任务是检测相对较远/较小的物体,则需要这种类型的模型
- 训练物体检测模型的数据集由图像文件和注释文件组成。注释文件包含有关在图像中找到的物体的信息:边界框坐标和分类名称。通常,用于物体检测的数据集是使用注释工具生成的,比如 LabelImg —— 制作用于物体检测的数据集比制作用于图像分类的数据集更耗时。
点击“扩展模型”标签里的 物体检测模型 按钮,可以进入“物体检测模型”的窗口,如下图所示。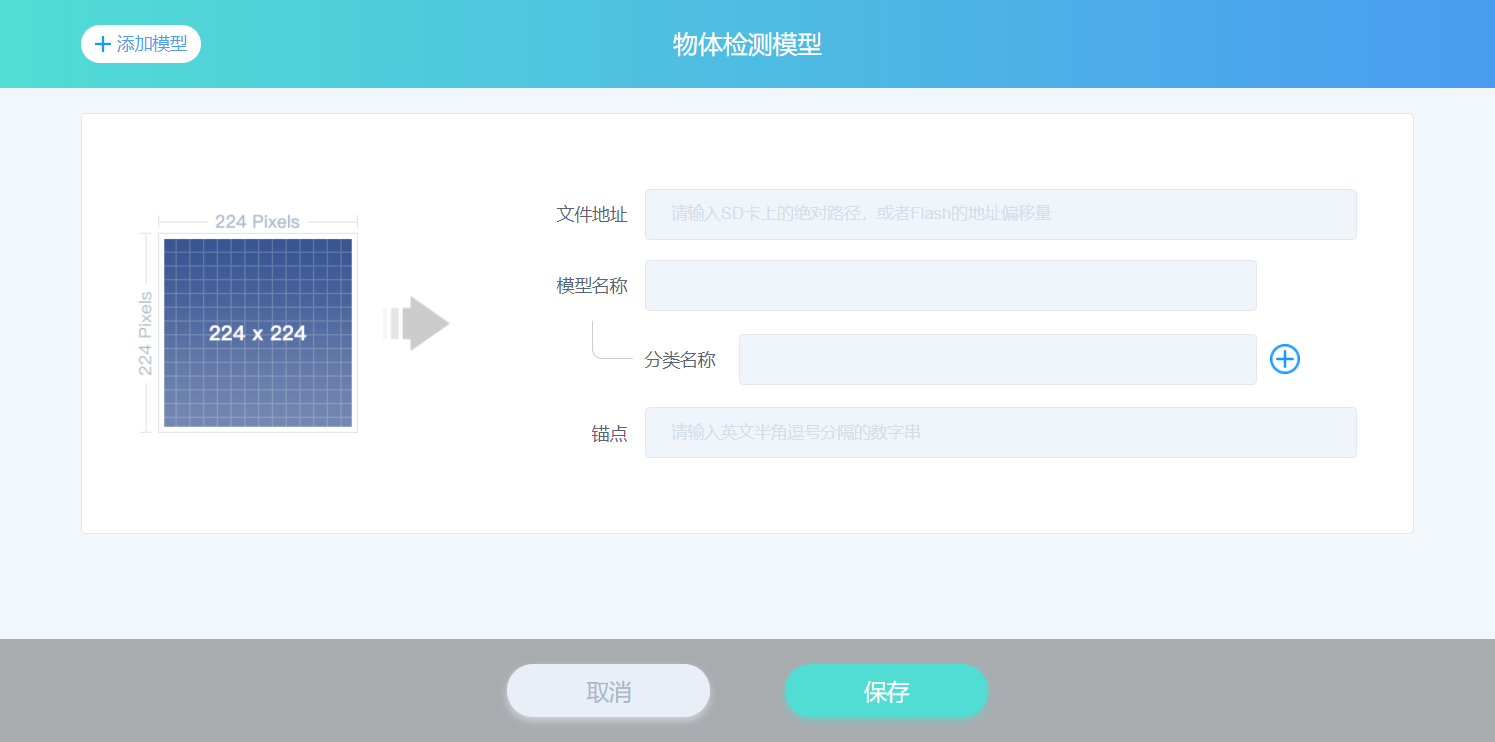
- 文件地址:是 SD 卡上文件的路径,例如,/sd/我的模型.kmodel 或是设备闪存中模型的地址,例如,0x800000
- 模型名称:是会出现在 Codecraft 界面的名称。
- 分类名称:是分类的名称, 必须 在训练过程中顺序一样。例如, 在训练过程中如果有【“狗” “猫” “苹果”】类别,那分类就需要是这种顺序!
- 锚点:是预设尺寸边框, 在模型训练中使用。使用锚点可以加快训练过程,因为模型不需要从随机猜测对象大小开始。通常,您不会更改此参数,因此,如果您没有在配置培训文件中更改了该参数,那么可以将该字段保留为空。
例如添加识别几种文具(笔,胶带,三角尺)的物体检测模型,相关信息填写如下图所示。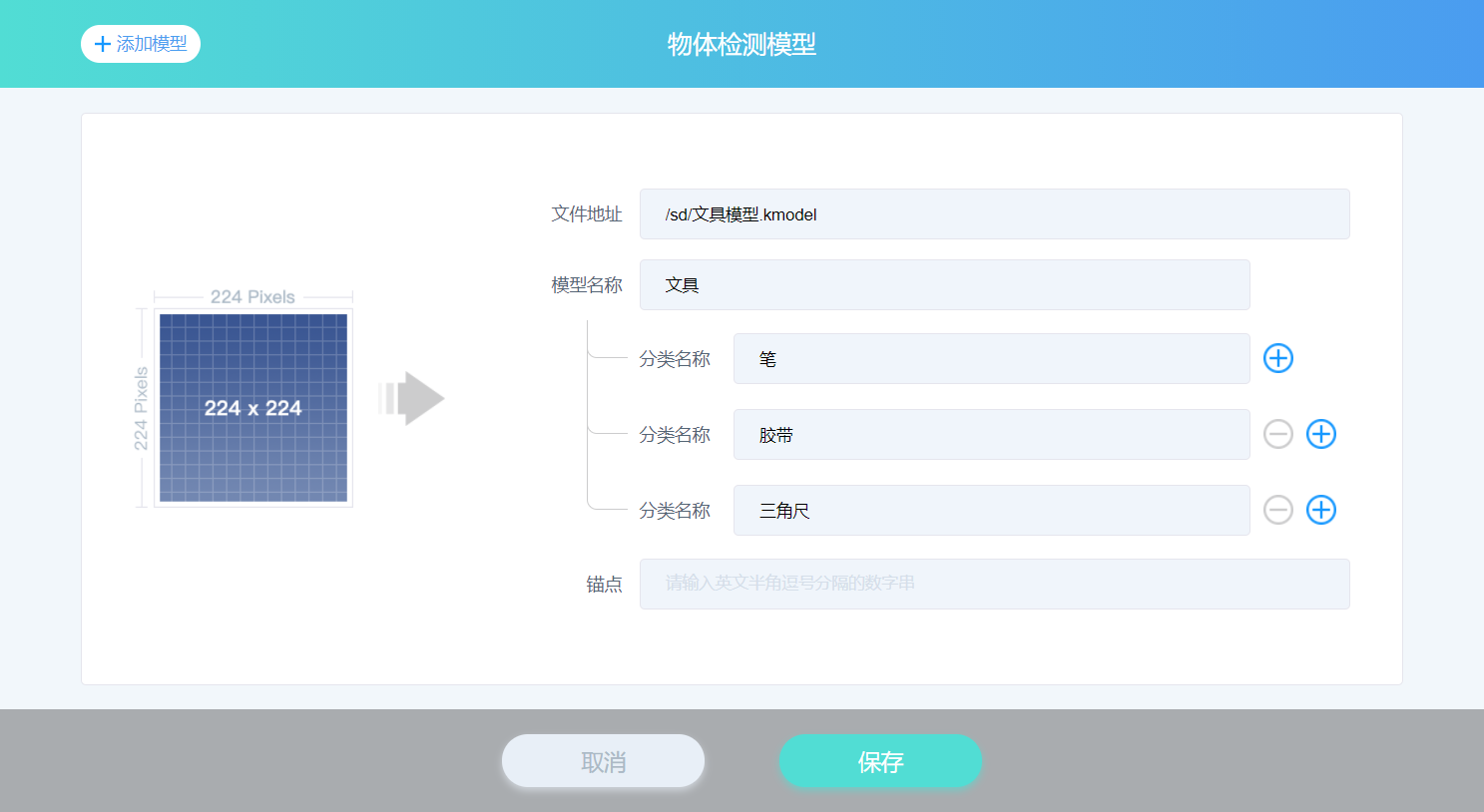
保存后,在“扩展模型”标签栏,多了3个新增的积木块,如下图所示。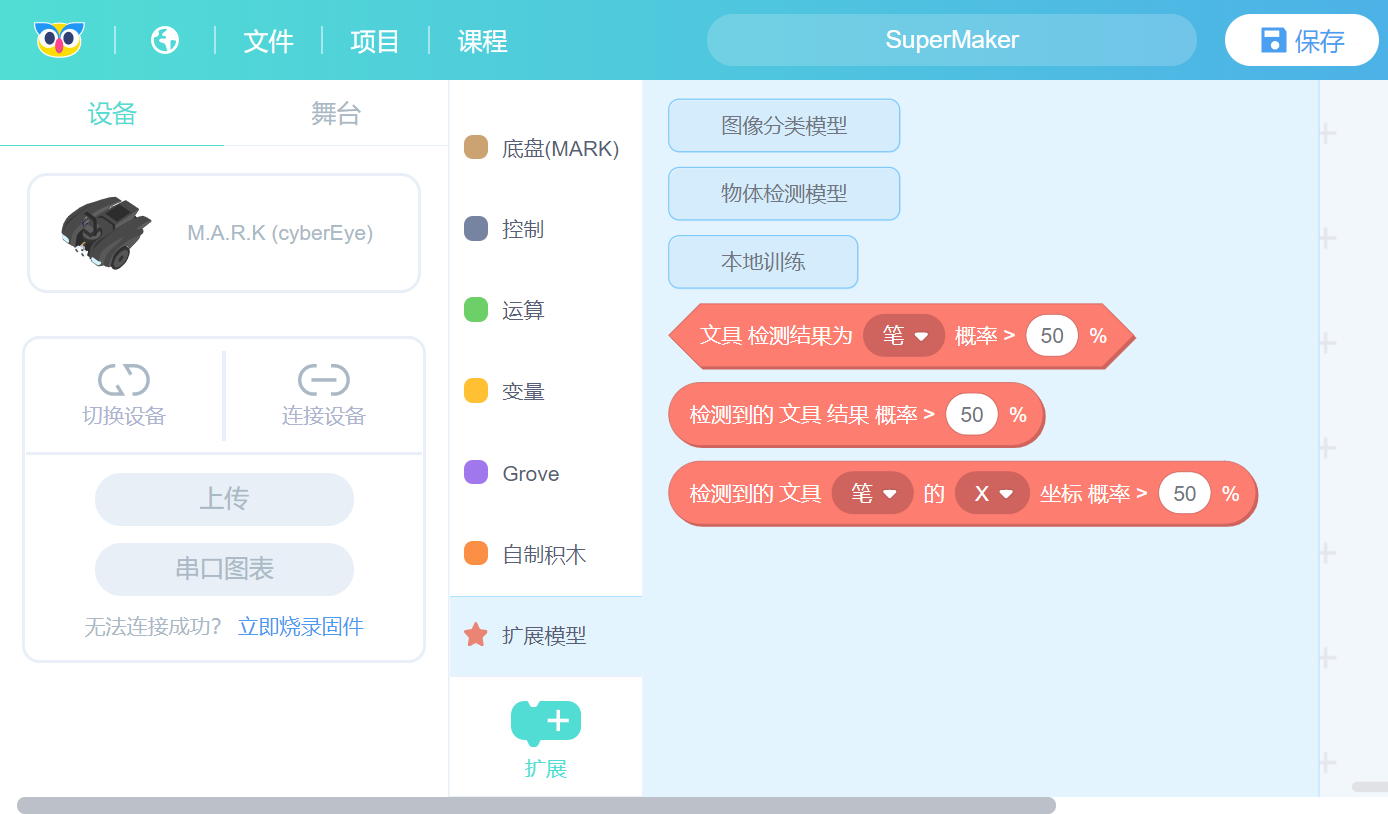
模型名称 识别结果为(分类名称) 概率 > (50) %

含义:如果检测到用户定义的物体的概率大于指定的值,则返回TRUE(1)或FALSE(0)的值。
类型: 布尔值
检测到的 模型名称 结果 概率 > 50%

含义: 返回检测到的用户定义物体的类型,如果该概率大于指定值,则返回字符串。
类型: 数据
返回范围: [在分类名称中定义]
返回类型: 文本字符串
提示:
- 如果未检测到受支持的物体,则返回值-1
- 如果检测到多个物体,则随机返回一个结果
示例:检测物体
在屏幕上显示检测到的物体名称
有关使用自定义物体检测模型的更多示例,请参阅:
项目示例:人物跟随(自定义物体检测模型推断)
检测到的 模型名称 分类名称 的 X 坐标 概率 > 50 %

含义: 返回用户定义物体的位置信息,例如x/y坐标
类型: 数据
提示:
- 如果未检测到指定的用户定义物体,则返回值-1。
- 如果检测到多个交通标志,则随机返回一个位置信息。
示例: MARK 小车相扑
MARK 小车会绕圈寻找另一个MARK 机器人,如果发现有,就会向前冲,将对手推出溜冰场。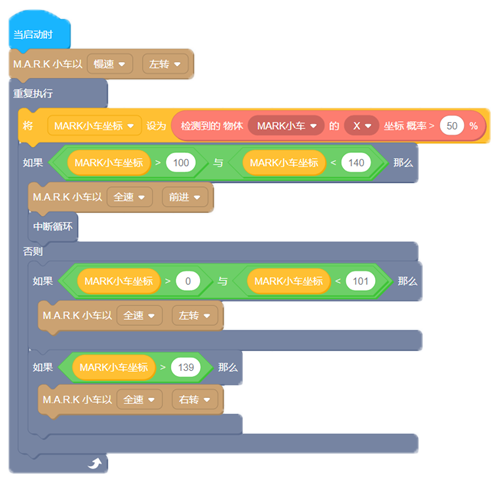
本地训练
在 MARK 固件更新 5011 中,我们新增了本地训练,以进一步简化用户定义的机器学习模型的训练和部署。
- 本地模型训练仅能用来训练图像分类模型,上面针对图像分类模型描述的限制也适用于本地训练模型
- 鉴于 MARK 小车的主板不具备训练反向传播训练神经网络模型所需的处理能力,因此我们在特征提取器的输出上使用 K-means 分类器 —— K-means分类器只需很少的数据即可进行训练,并且计算量也不大。但是,它不如在大数据集上训练的神经网络分类器稳健。也就意味着,你要选择各不相同的物体进行本地训练:苹果、橘子就可以,不过小狗和小猫可能会需要在云端/本地电脑上训练的模型(请参见以上示例)。
点击“扩展模型”标签里的 本地训练 按钮,可以进入“本地训练”的窗口,如下图所示。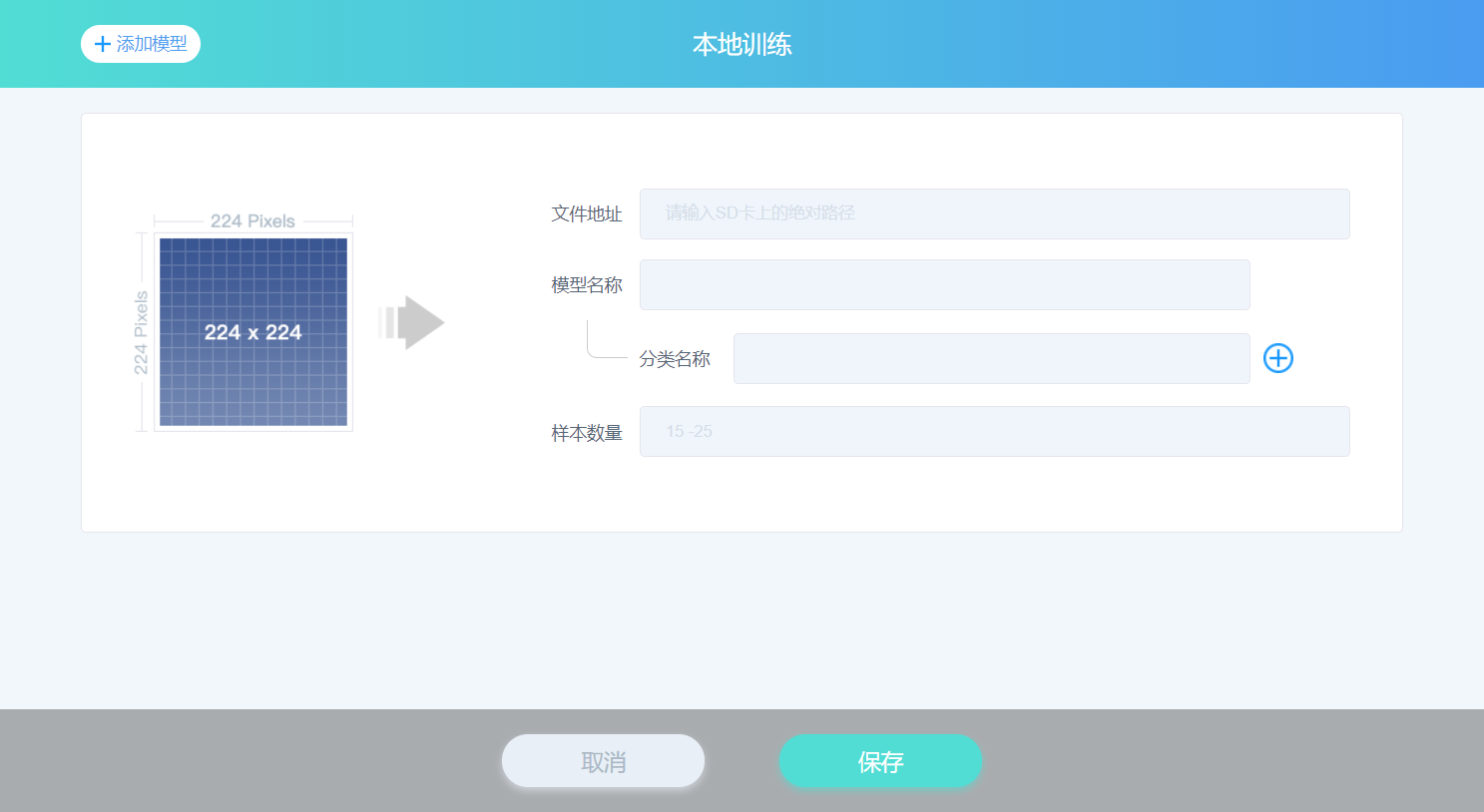
- 文件地址:是 SD 卡上文件的路径,例如,/sd/我的模型.tg,在该地址你可以加载训练后的模型或在训练后保存模型以供以后使用。
- 模型名称:是会出现在 Codecraft 界面的名称。
- 分类名称:是分类的名称, 必须 在训练过程中顺序一样。例如, 在训练过程中如果有【“狗” “猫” “苹果”】类别,那分类就需要是这种顺序!
- 样本数量:15 到 25 之间的一个数字,默认为 15。样本数量越多可能会产生精度更高的模型
例如想通过本地训练,添加识别几种花朵(玫瑰,百合,郁金香)的图像分类模型,相关信息填写如下图所示。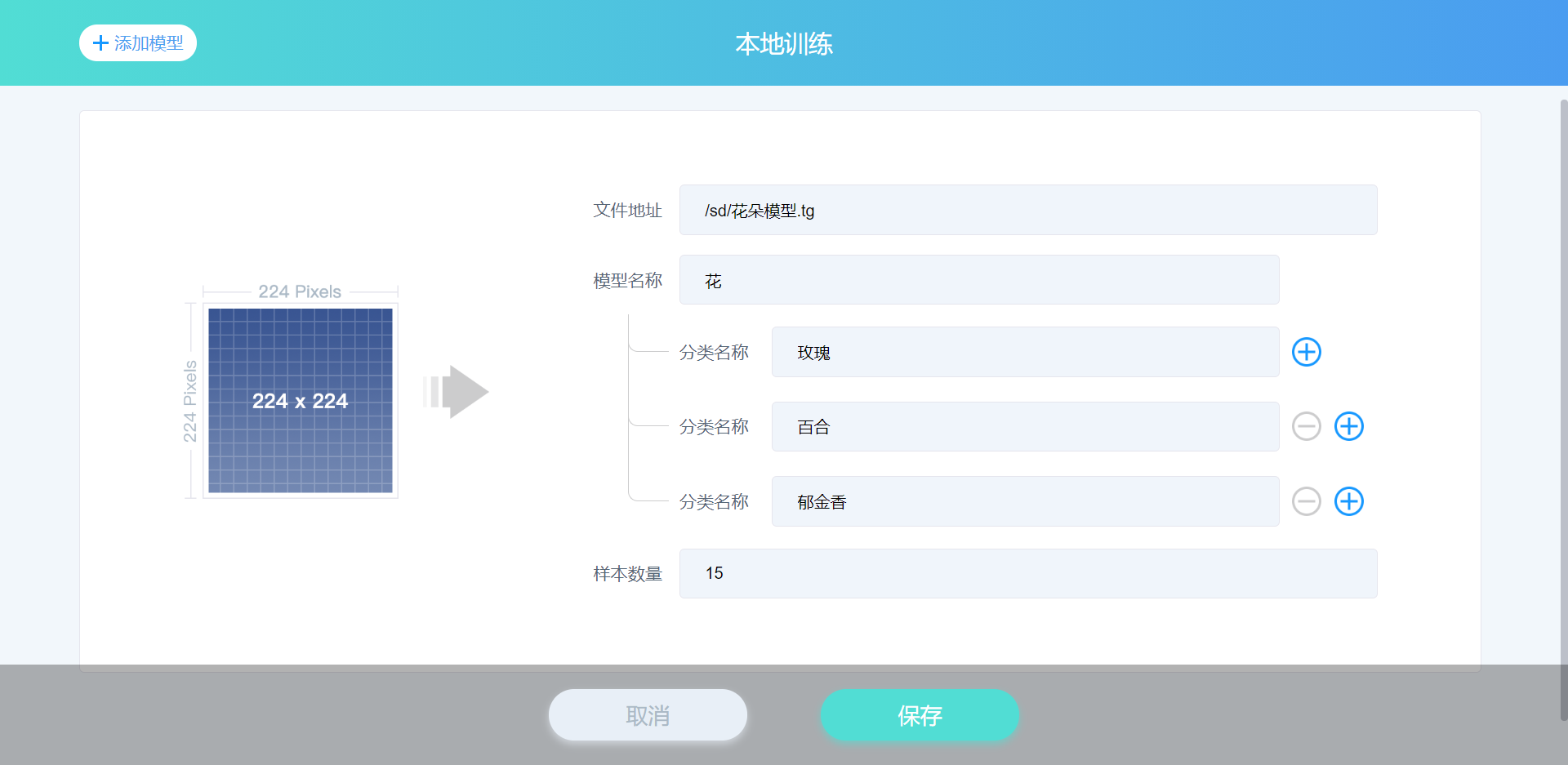
保存后,在“扩展模型”标签栏,多了6个新增的积木块,如下图所示。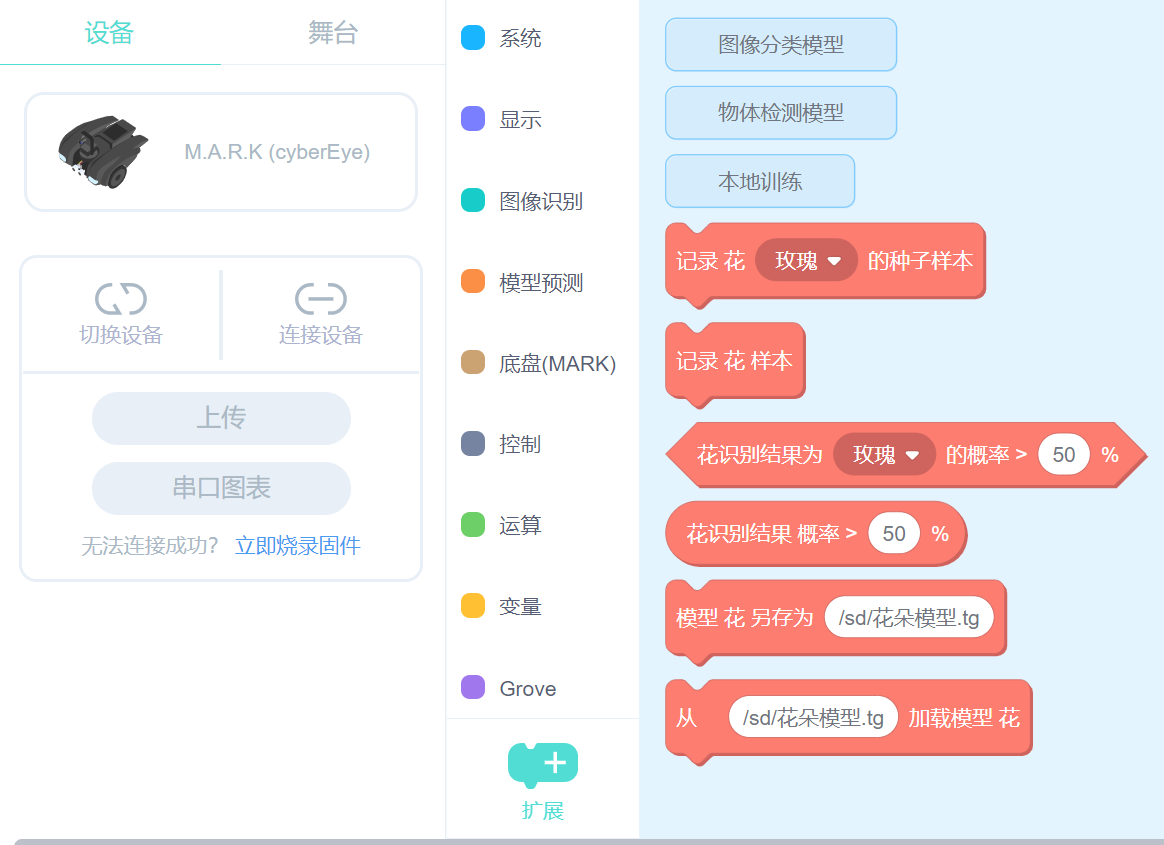
记录 模型名称 分类名称1 的种子样本

含义: 记录用户定义的分类的种子样本。
类型: 命令
提示: 每个分类只需要一个种子样本。
记录模型名称样本

含义: 记录样本供之后的训练。创建模型定义时,定义了所需的最大样本量,默认为 15。
类型: 命令
提示: 记录每个分类的种子样本之后,就可以开始记录样本了。记录样本的时候顺序不重要—因为我们用的是 K-means 分类器,一种无监督学习技术。
模型名称识别结果为 分类名称 的概率 > 50%

含义: 如果图像中用户定义类别的概率大于指定的值,则返回TRUE(1)或 FALSE(0)的值。
类型: 布尔值
提示:模型完成训练后或是加载完训练模型之后可以使用
模型名称识别结果 概率 > 50 %

含义: 如果分类概率大于指定值,则返回带有用户定义分类的名称的字符串。
类型: 数据
返回范围: [在分类名称中定义]
返回类型: 文本字符串
提示:
- 模型完成训练后或是加载完训练模型之后可以
- 使用如果该概率低于指定值,则返回值 -1
模型 模型名称 另存为 /sd/样本.tg

含义: 将训练后的模型在 SD 卡上保存两份文件:一个模型文件,一个名称文件。
类型:命令
提示:模型完成训练后或是加载完训练模型之后可以使用
从/sd/样本.tg 加载模型 模型名称

含义: 将训练后的模型在 SD 卡上保存两份文件:一个模型文件,一个名称文件。
类型: 命令
提示:
- 模型完成训练后或是加载完训练模型之后可以使用
- 这两个文件都必须存在于SD卡上,否则会无法加载。
有关使用本地模型训练的例子,请参阅:
示例项目:手势识别(本地训练和预测)

若有收获,就点个赞吧
0 人点赞
