- 括号前面是函数;函数后面需要加括号
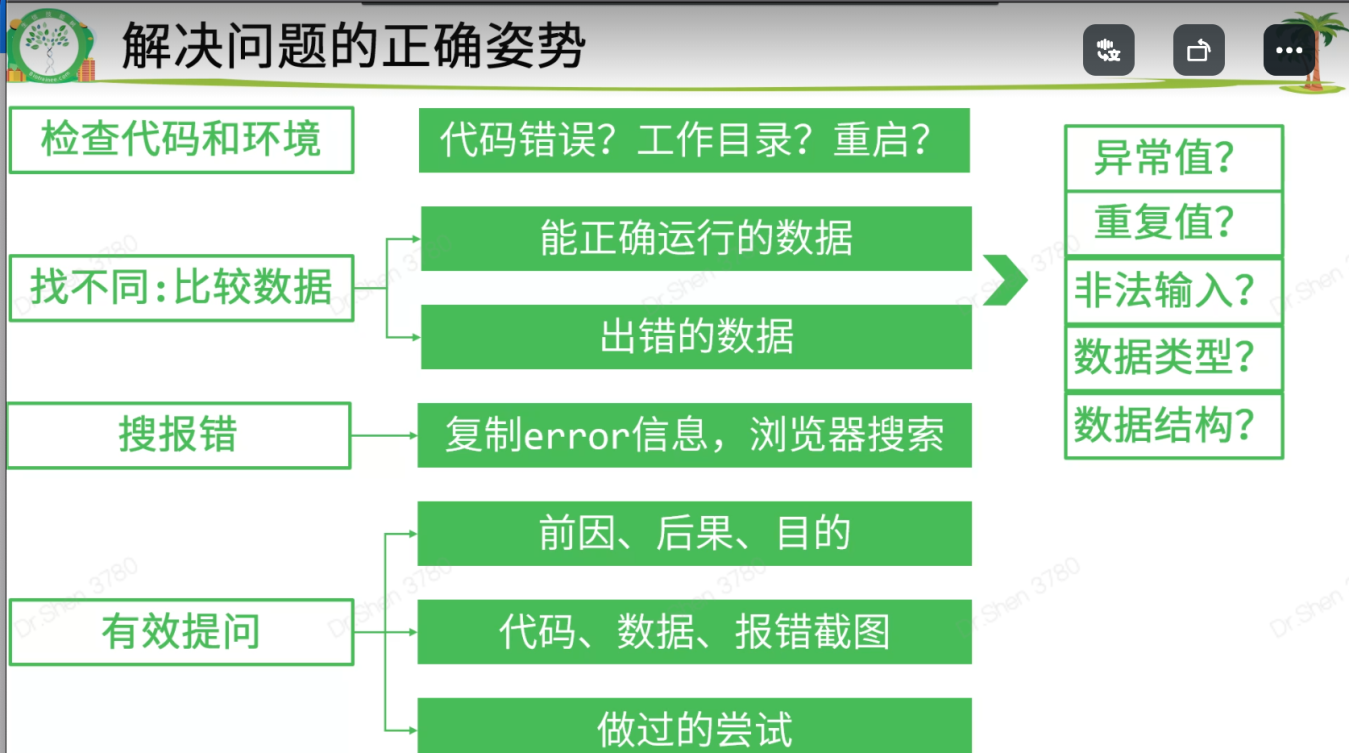
- 问号?在哪里意味着问题出在哪里
- 出现不管多少的提示信息时,检查是否有error,没有就不管
- 检查报错地方:引号、拼写、大小写、中英文【注意抓住error的地方】
- 操作期间解答后,包更新了就不能撤回,但赋值可重新赋值
- 默认存储位置为工作目录(working directory),即Rproj的文件夹;下次可直接双击Rproj文件夹,既可恢复之前已保存的种种设置
- R实践中遇到“要不要保存”时,一般选拒绝
- 能用函数尽量用
- 能转换的才能转换
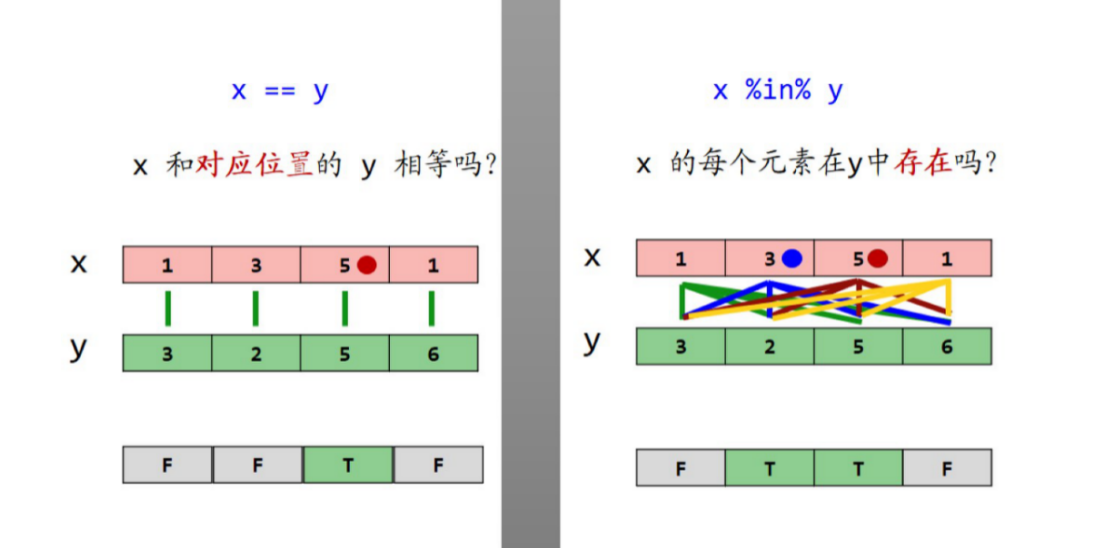
- 重点%in%
- x %in% y #x的每个元素在y中存在吗
- y %in% x #y的每个元素在x中存在吗

- “==”与“%in%”的区别
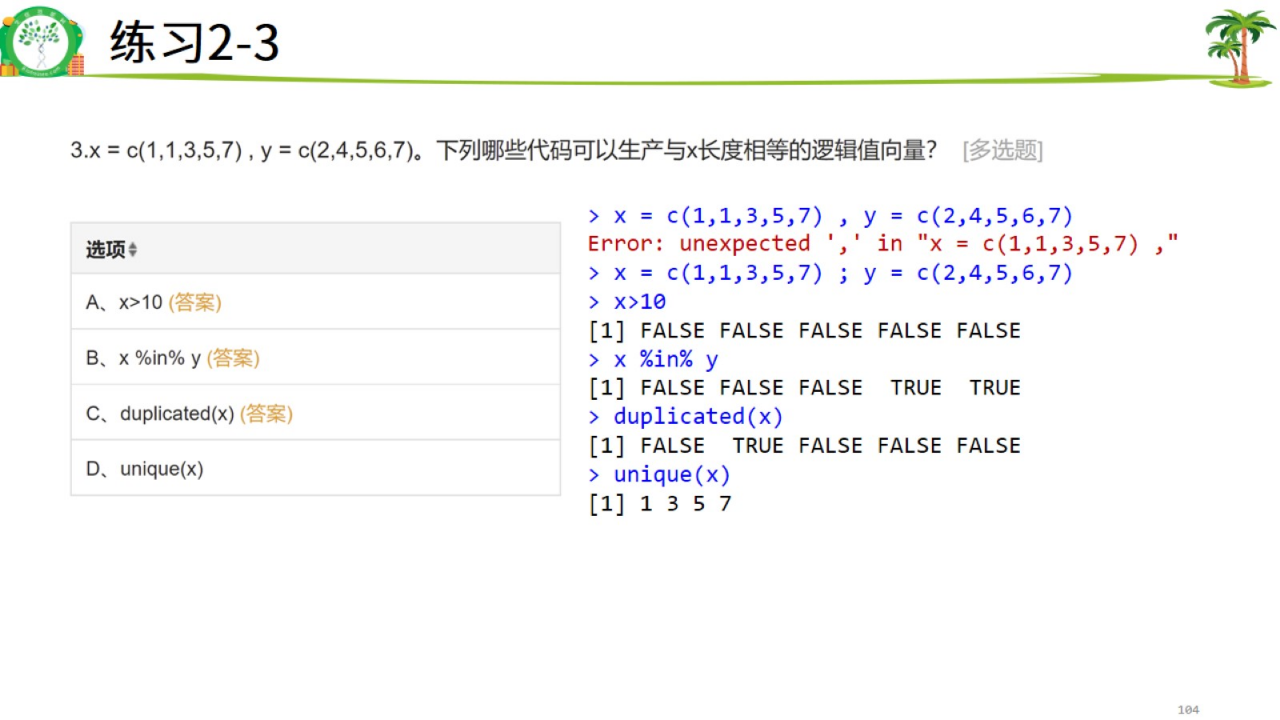
- 两个不同的代码,须用分号或分开多行填写
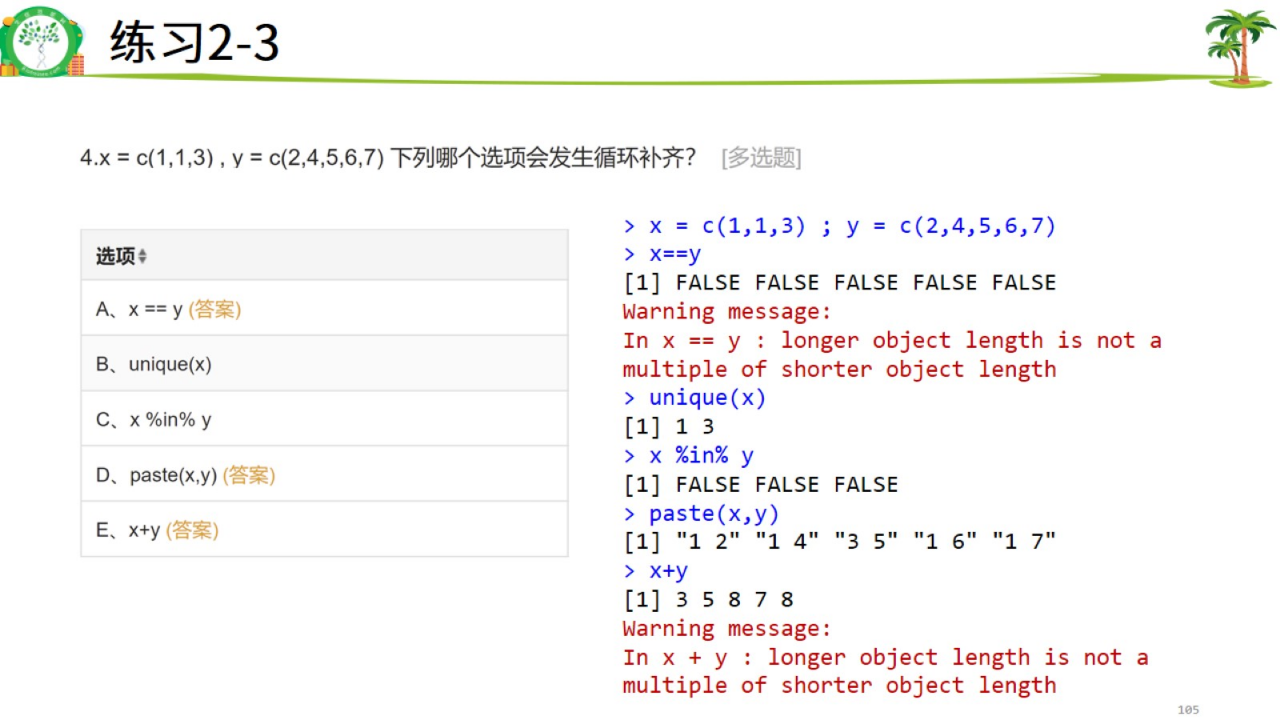
- 有嵌套时,先内后外;
- 没有嵌套的时候从左往右,和大括号小括号没有关系
- 没有赋值就没有发生过
- 问号+函数名可查看帮助文档
- 字符(如abc)输入时需要加“”
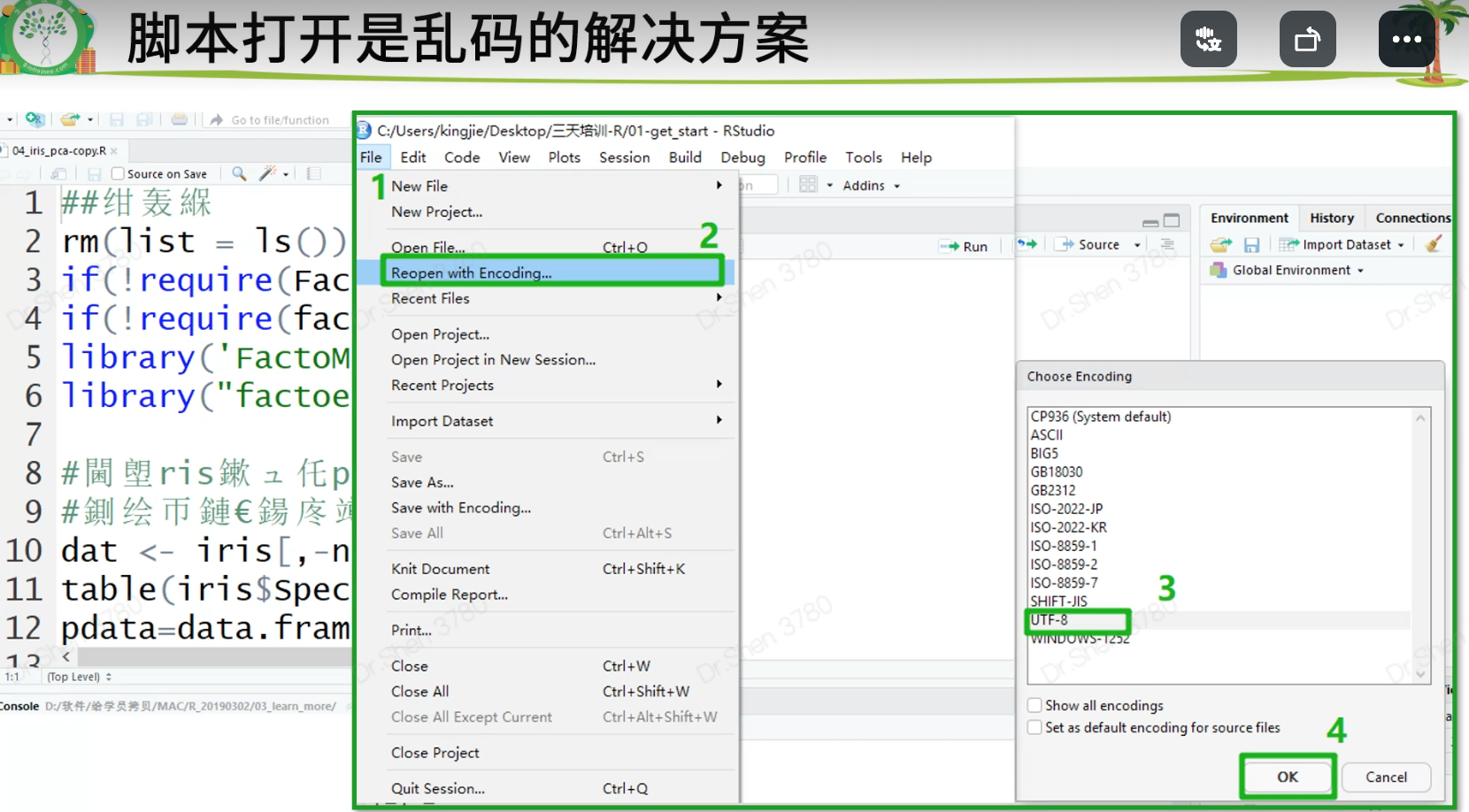
- 脚本打开的科学方式
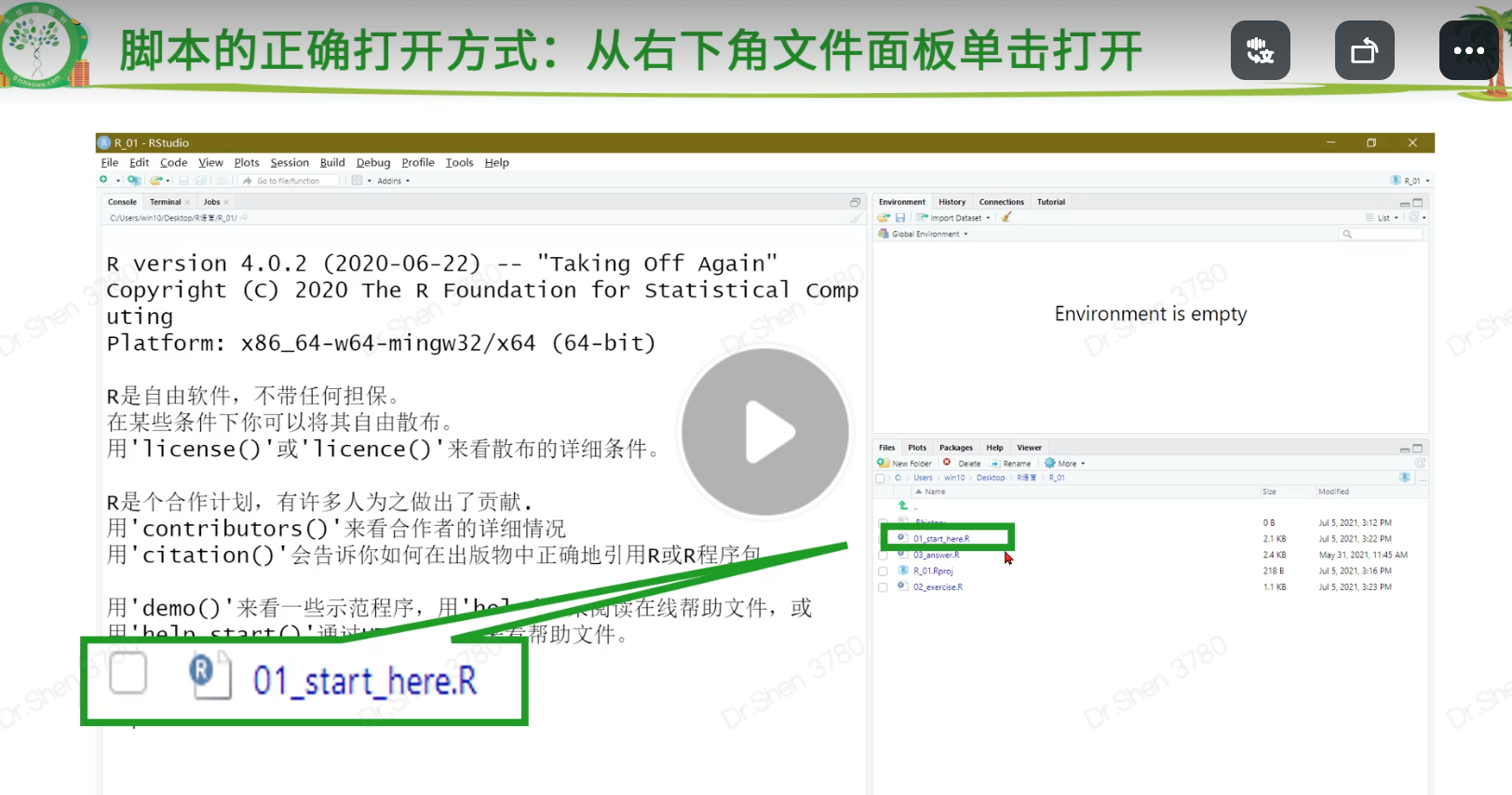
- 乱码时的处理方式,先试下以下的方式,不行时需要重新从源头打开
- 任何东西放入引号中均为字符
- 函数运行的返回结果是向量
- 不要想着手动省事,练就编程思维
- 向量是一种数据结构,字符是一种数据类型;向量包括字符/逻辑/字符型数据类型,一种向量只能有一种数据类型
- 赋值的快捷键alt+“-”
- sort(x)#默认从小到大排序
- 中括号[]外面的东西肯定是个数据,不是函数;是个被筛选的向量
- 中括号在没有遇到TRUE或FALSE时,可表示下标(即第几个的意思),
- 按照逻辑值:中括号里是与x等长的逻辑值
- 按照位置:中括号里是由x的下标组成的向量
- R语言的修改,均要赋值,没有赋值就没有发生过
- 取交集会去重复,而%in%取子集不会
- 代码不报错不代表就是对的,要检查目的是否达到
- 中括号的逗号表示维度的分割
- 数据框按照逻辑值取子集,TRUE读对应的行/列留下,FALSE对应的会丢掉
- 一个数据框有多少列,等同于最后一列的数目
- |用于连接逻辑值,不是字符
sort(x)等于x[order(x)]
x[match(y,x)]=y
match:谁在外面,谁就在后面只区分“是什么”(数据类型/数据结构),与“怎么得到”的无关
- 当一个代码需要复制粘贴三次,就应该写成函数或使用循环
形式参数:函数的括号里面,等号的前面
实际参数:等号的后面
函数书写时,内容不多时,大括号以及里面的内容可省略
- R语言版本一般没问题
- R包是否更新,大多选择不更新(懒惰策略);Linux碰到选择时多数选择服从
- 半年更一次包就很勤快了
- 文件名称带引号,且出现在某个函数的实际参数里
- 数据框约等于表格,不是文件
- 表格文件读入到r语言中,得到一个数据框;对数据框的修改不会同步到原有的表格文件
- 加参数都是需要达到某个目的
- 矩阵只允许一种数据类型,要改除非整个矩阵改
- 不要修改内置数据
学重点的字+查字典
重点
| max(x) #最大值 | | | —- | —- | | min(x) #最小值 | | | mean(x) #均值 | | | median(x) #中位数 | | | var(x) #方差 | | | sd(x) #标准差 | | | sum(x) #总和 | | | max(x) #最大值 | | | length(x) #长度 | | | unique(x) #去重复 | | | duplicated(x) #对应元素是否重复 | | | table(x) #重复值统计 | | | sort(x)#排序,默认从小到到 | | | sort(x,decreasing = T)#从大到小的排序 | | | intersect(x,y)#交集 | | | union(x,y)#并集 | | | setdiff(x,y)#差集 | | |
**重点掌握**| | | sort match | 向量数据框 列表取子集 | | names | 数据框新增列 | | ifelse str_detect | 文件读取 | | identical | Rdata的加载与读取 | | arrange | 作图保存 | | merge inner_join | R包的安装与加载 | | unique duplicated | 形式、实际、默认参数 |
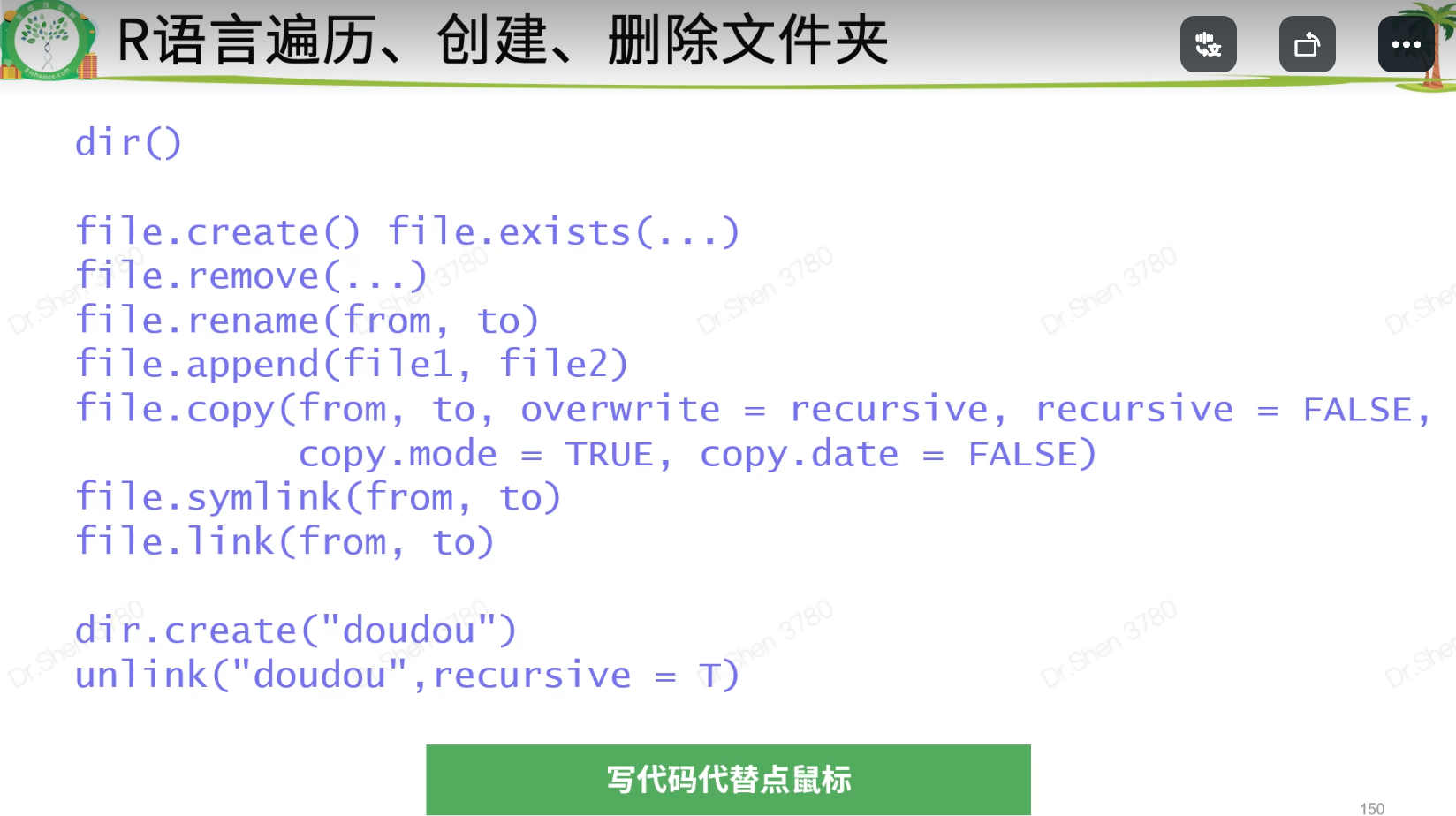
> x <- c(1,5,8,1)> length(x) #长度,向量中的元素数量[1] 4> unique(x) #去重复,从左往右,第一次出现为不重复,后续重复出现则为重复;呈现原有格式[1] 1 5 8> duplicated(x) #判断是否重复,同unique的定义;逻辑值[1] FALSE FALSE FALSE TRUE> !duplicated(x) #呈现反向结果[1] TRUE TRUE TRUE FALSE> table(x) #重复值统计x1 5 82 1 1> sort(x)#默认从小到大排序[1] 1 1 5 8> sort(x,decreasing = F)[1] 1 1 5 8> sort(x,decreasing = T)#从大到小排序[1] 8 5 1 1> x <- c(1,5,8,1)> y <- c(3,1,8)> intersect(x,y) #取交集[1] 1 8> union(x,y) #取并集[1] 1 5 8 3> setdiff(x,y) #取差集[1] 5> x %in% y #x的每个元素在y中存在吗[1] TRUE FALSE TRUE TRUE> y %in% x #y的每个元素在x中存在吗[1] FALSE TRUE TRUE>rm() #删除变量& #一次只提取1列[]#按坐标、名字、条件match(y,x)#以y为模版、目标、结果,以x为原料,去进行调整顺序所得到的下标向量 x[n] #修改元素数据框 df1[x,y],矩阵 df1[x,],df1[,y],$ #新增列,修改列表 m[x,y]dim()维度nrow()行数ncol()列数

若有收获,就点个赞吧
0 人点赞
