数据结构基本点
逻辑性数据
比较运算的结果是逻辑值
>,<,<=,>=,==(相等吗?),!=(不相等吗?)

逻辑运算
与&、或|、非!
数据类型的判断和转换

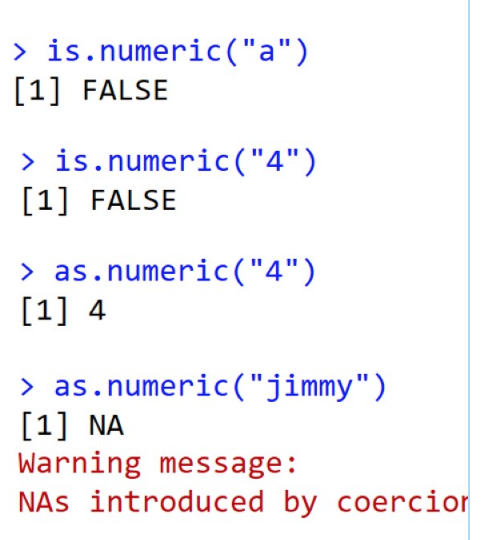
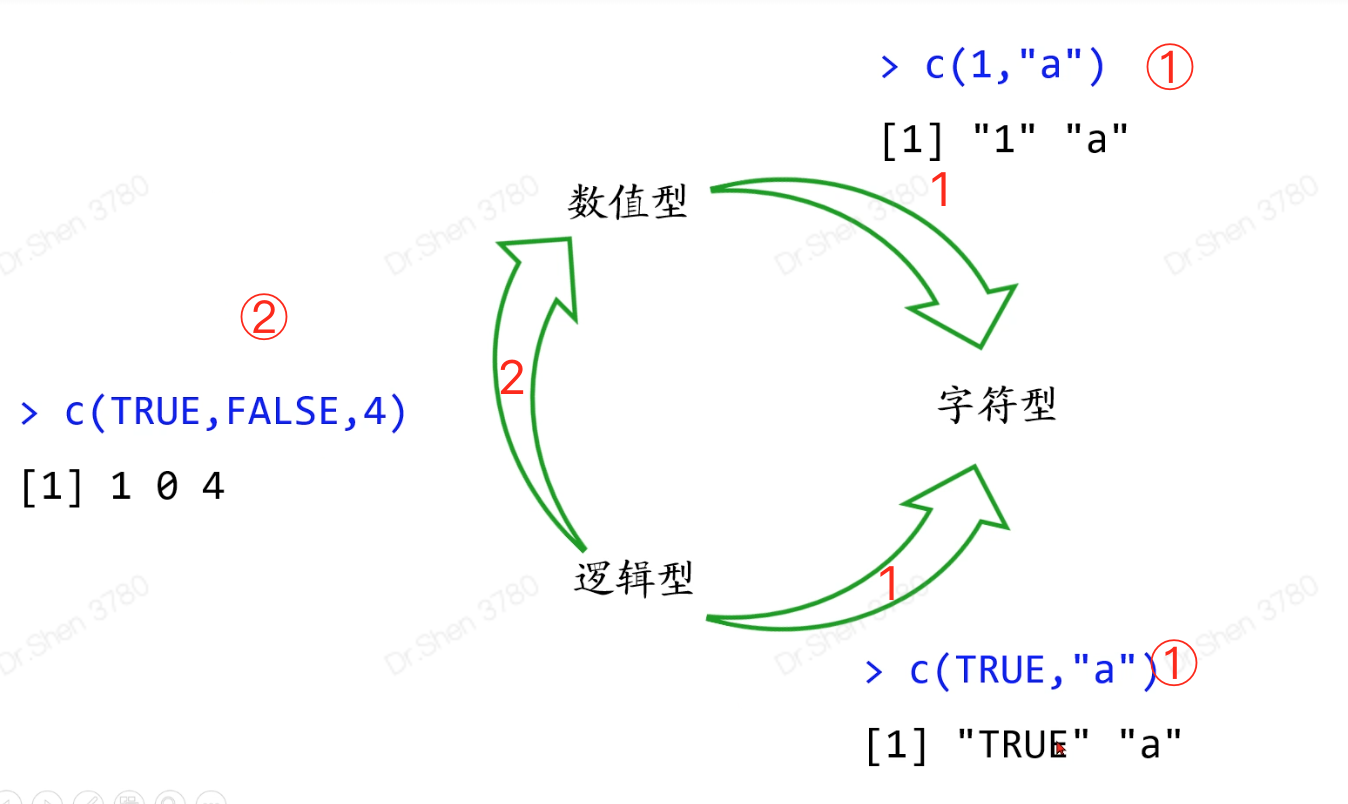
数据类型转换优先顺序
字符>数值>逻辑
实操
2.1向量生成
(1)用 c() 结合到一起【类似陈列】
(2)连续的数字用冒号“:”
(3)有重复的用rep(),有规律的序列用seq(),随机数用rnorm
(4)通过组合,产生更为复杂的向量
练习

如果数据值填错时,可能出现以下情况:
前面<具体数值时,会出现自动补齐;
前面>具体数值时,会出现重复等
2.2 单个向量
(1)赋值给一个变量名

(2)简单数学计算
(3)根据某条件进行判断,生成逻辑型向量
(4)初级统计
max(x) #最大值
min(x) #最小值
mean(x) #均值
median(x) #中位数
var(x) #方差
sd(x) #标准差
sum(x) #总和
‼️重要函数
length(x) #长度
unique(x) #去重复
duplicated(x) #对应元素是否重复
table(x) #重复值统计
sort(x)
sort(x,decreasing = F)
sort(x,decreasing = T)
2.3.两个向量
(1)比较运算,生成等长的逻辑向量
(2)数学计算
(3)连接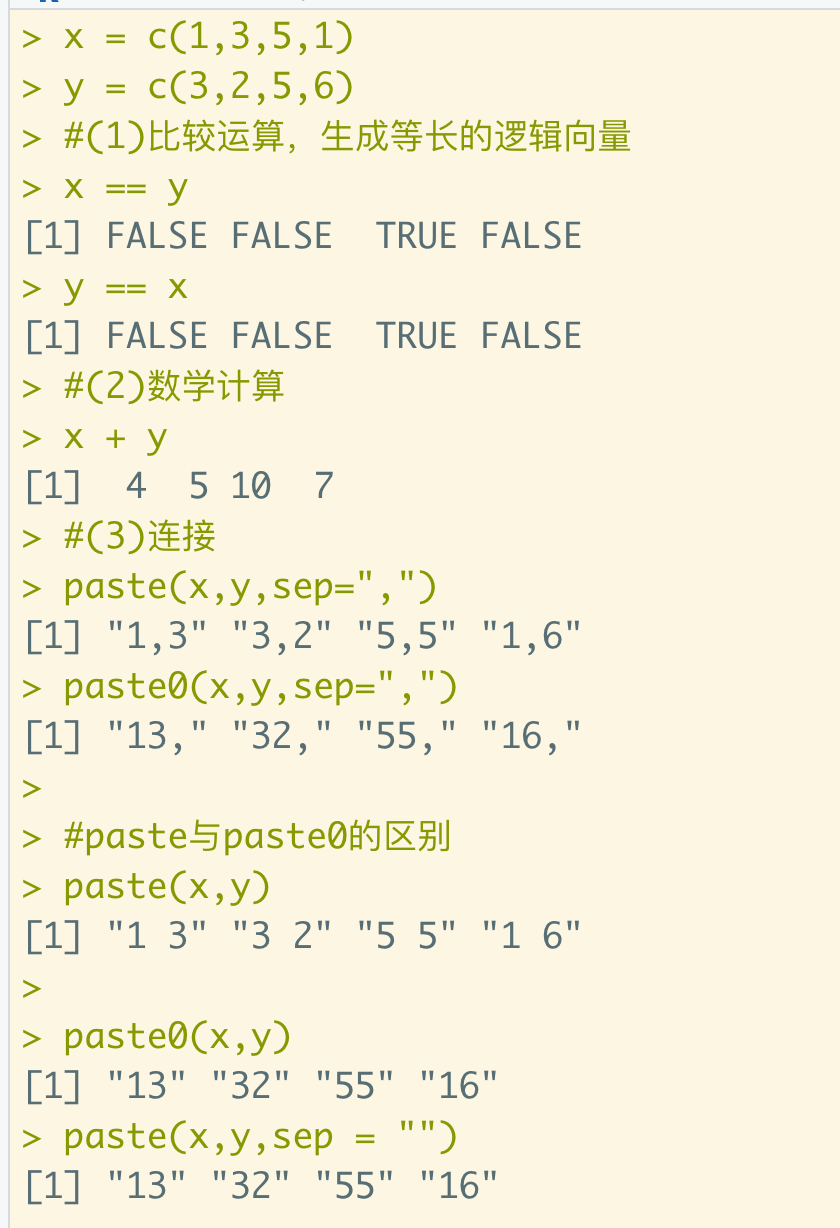
当两个向量长度不一致
解答:
x和y不等长时:发生循环补齐【短循环补齐长的】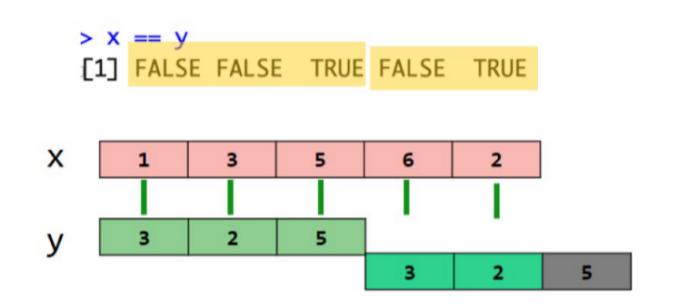
可利用循环补齐简化代码
(4)交集、并集、差集
intersect(x,y)
union(x,y)
setdiff(x,y)
setdiff(y,x)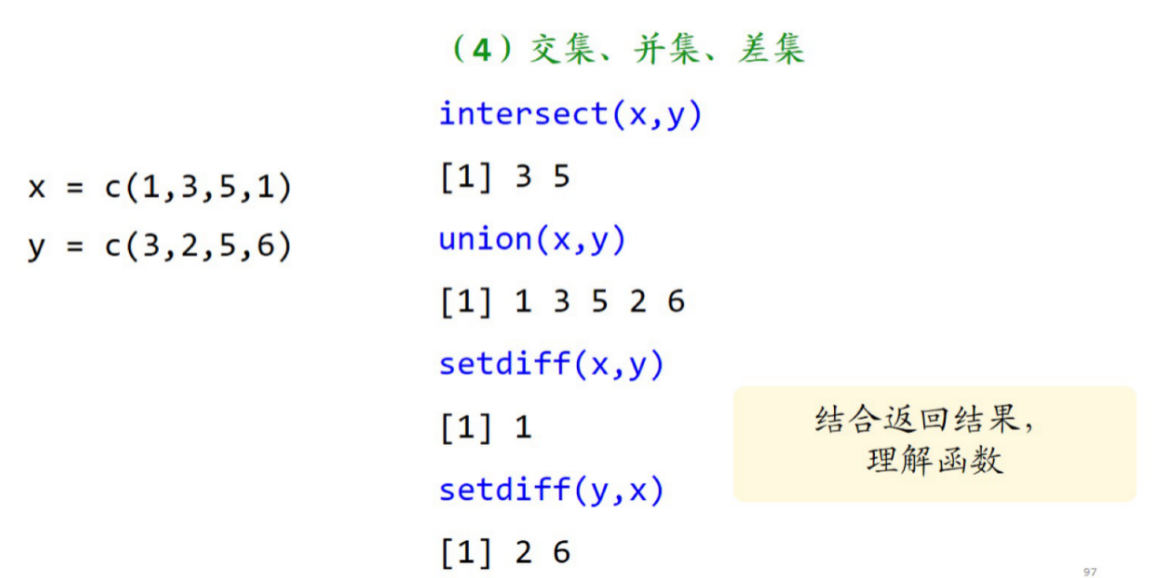
2.4.向量筛选(取子集): []

根据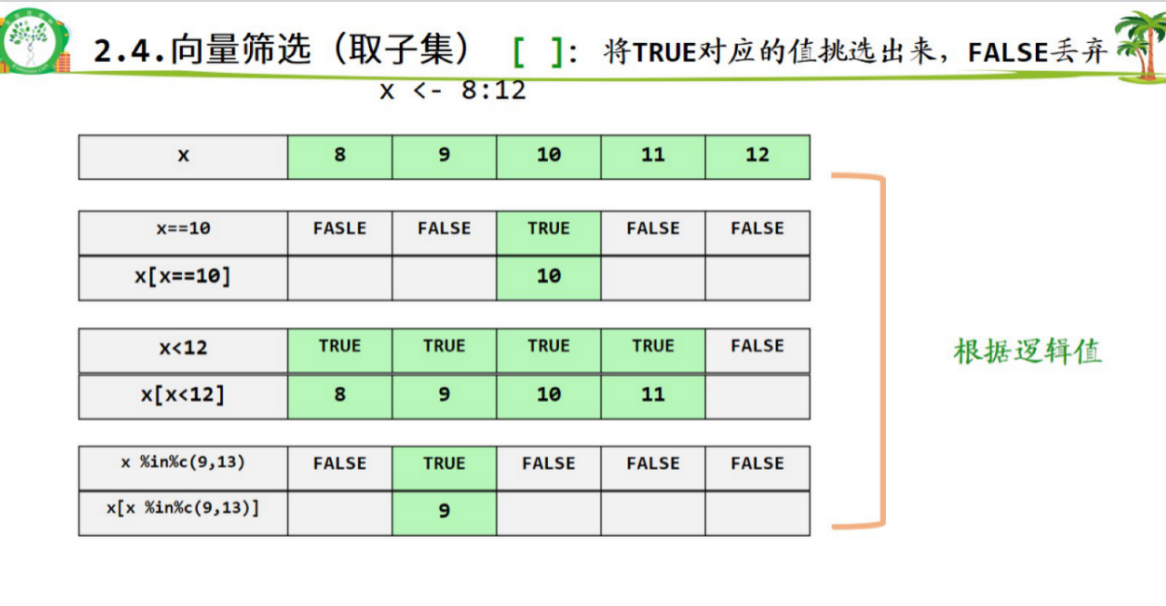
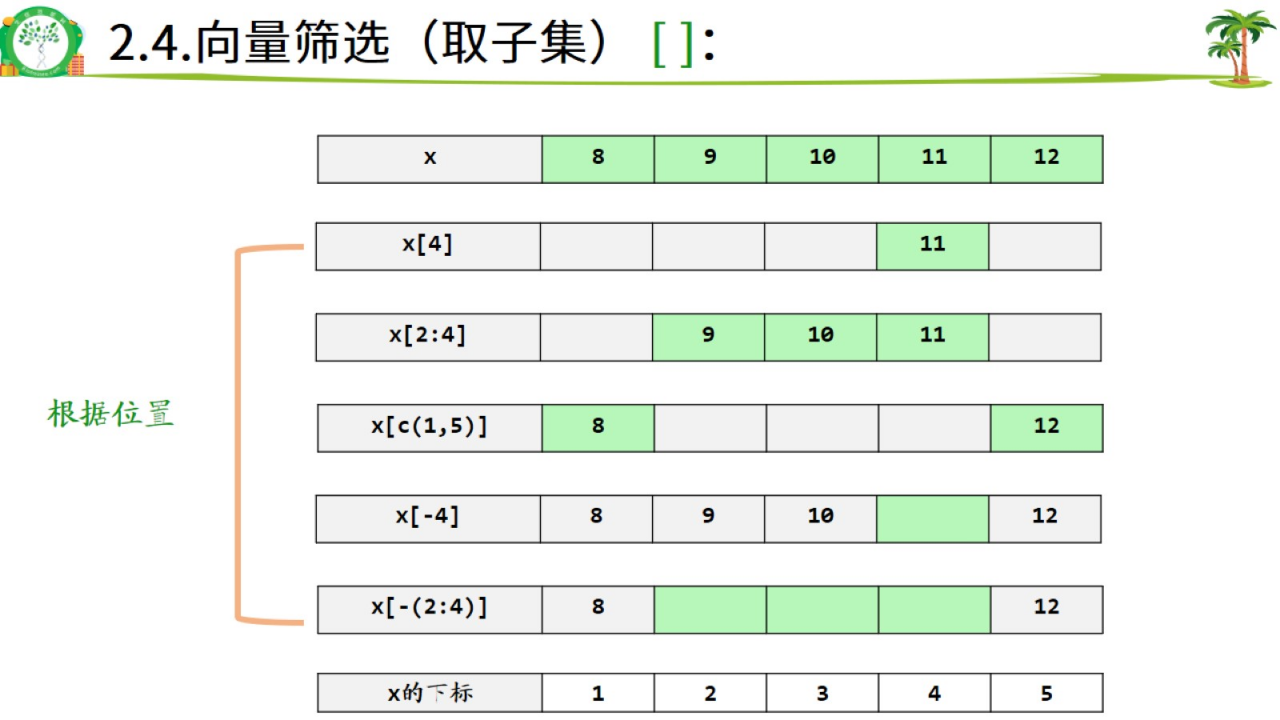

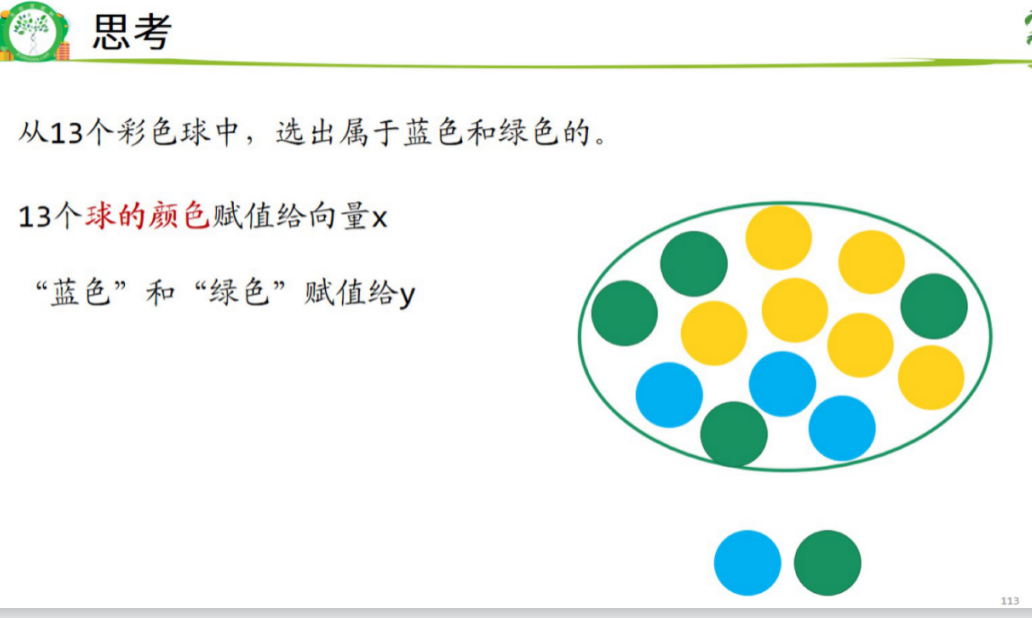
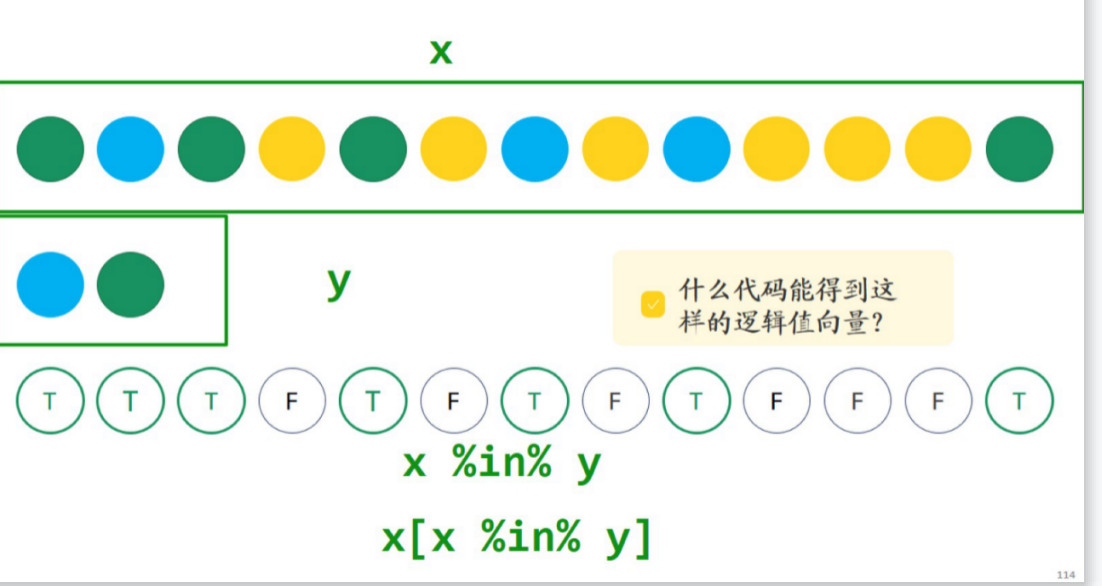
2.5.修改向量中的某个/某些元素:取子集+赋值

2.6 简单向量作图
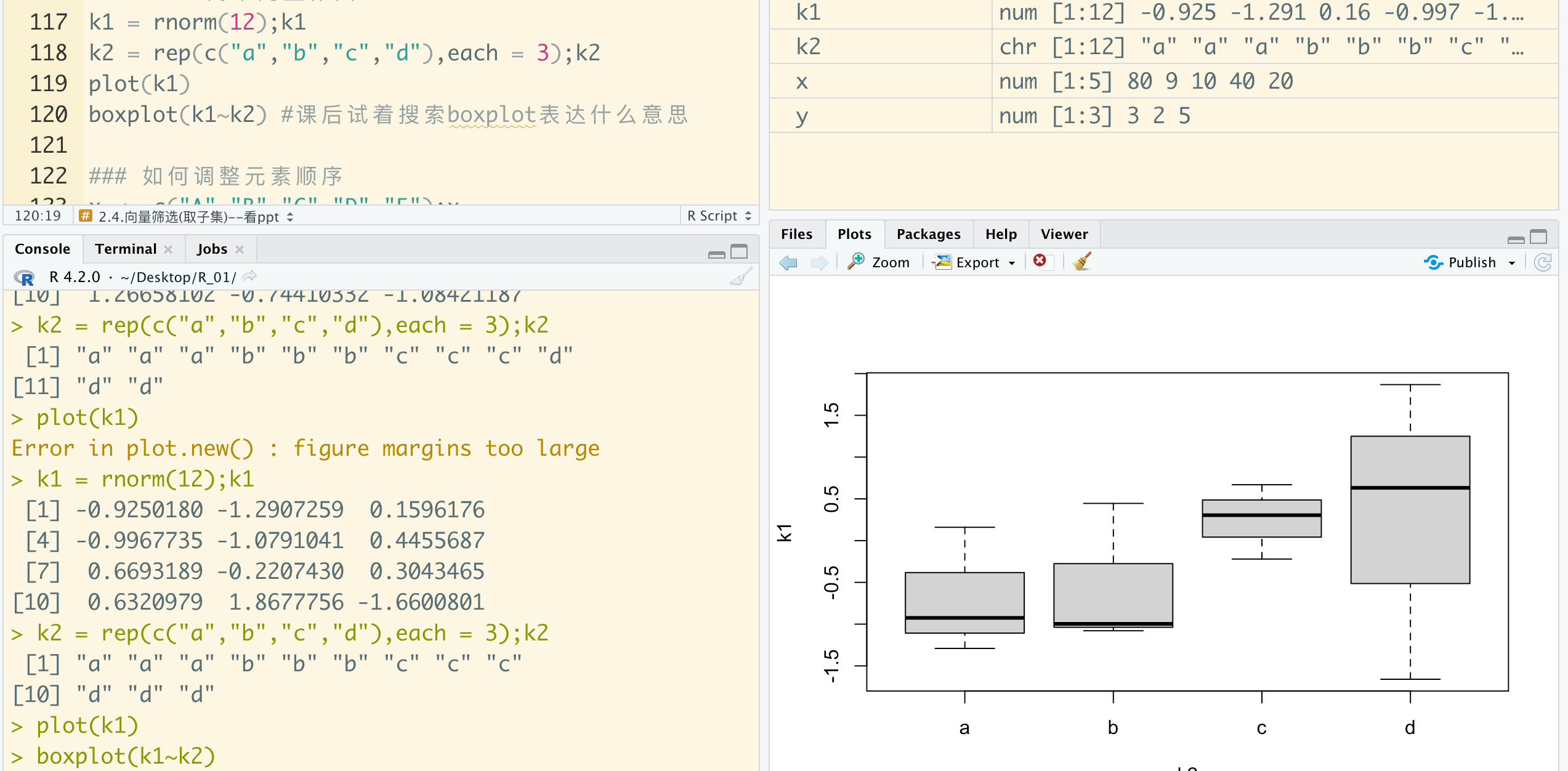
涉及代码部分
基本学习操作> #陈列数字或字符用c()> c(1,3,5)[1] 1 3 5> c("a","b","A")[1] "a" "b" "A"> #连续数字用:> 1:9[1] 1 2 3 4 5 6 7 8 9> #重复用rep()> rep("x",times=6)[1] "x" "x" "x" "x" "x" "x"> #有规律的数列用seq()> seq(from=3,to=11,by=2)[1] 3 5 7 9 11> #随机数用rnorm> rnorm(n=2)[1] -0.4587199 0.1827148> #组合用paste0> paste0(rep("x",times=3),1:2)[1] "x1" "x2" "x1"> paste0(rep("student",times=3),seq(from=2,to=10,by=2))[1] "student2" "student4"[3] "student6" "student8"[5] "student10"②> paste0(rep("student"),seq(2,10,2))[1] "student2" "student4"[3] "student6" "student8"[5] "student10"③> a = seq(from=2,to=14,by=2)> paste0(rep("student",length(a)),a)[1] "student2" "student4" "student6"[4] "student8" "student10" "student12"[7] "student14"数据类型转换> c(2,"a")#数值型自动被转换为字符型数据[1] "2" "a"> c(TRUE,"a")#逻辑型自动被转换为字符型数据[1] "TRUE" "a"> c(TRUE,FALSE,5)#逻辑型自动被转换为数值型数据[1] 1 0 5> #单个向量操作> #1、赋值,> #可用名称xyz、AB、_、.> #不可用空格、“”、c、-、中文> x <- c(2,4,7) #规范写法> x = c(2,4,7)#随意写法> x[1] 2 4 7> (x <- c(2,4,7)) #赋值+输出(专用代码)[1] 2 4 7> x <- c(2,4,7);x #两行代码并行实现,用分号隔开[1] 2 4 7> #2、简单运算> x <- c(3,4,8)> x+1[1] 4 5 9> log(x)# 取对数[1] 1.098612 1.386294 2.079442> sqrt(x)#开根号[1] 1.732051 2.000000 2.828427> #3、根据某条件进行判断,产生逻辑向量> x>4[1] FALSE FALSE TRUE> x==4[1] FALSE TRUE FALSE> #4、初级统计> x <- c(1,5,8,1)> #长度> length(x)[1] 4> #去重复,从左往右,若第一次出现则不重复,其余重复出现则为重复> unique(x)[1] 1 5 8> #判断是否重复,同unique的定义> duplicated(x)[1] FALSE FALSE FALSE TRUE> !duplicated(x)[1] TRUE TRUE TRUE FALSE> #重复值统计> table(x)x1 5 82 1 1> #排序> sort(x)#默认从小到大[1] 1 1 5 8> sort(x,decreasing = F)[1] 1 1 5 8> sort(x,decreasing = T)[1] 8 5 1 1> #对两个向量的操作> #1、比较运算,生成等长的逻辑向量> x <- c(1,3,6,1)> y <- c(3,2,1,6)> x == y[1] FALSE FALSE FALSE FALSE> y == x[1] FALSE FALSE FALSE FALSE> #2、数学运算> x+y[1] 4 5 7 7> #3、连接> paste(x,y,seq=",")[1] "1 3 ," "3 2 ," "6 1 ," "1 6 ,"> paste0(x,y)[1] "13" "32" "61" "16"> paste(x,y,seq="")[1] "1 3 " "3 2 " "6 1 " "1 6 "> paste(x,y)[1] "1 3" "3 2" "6 1" "1 6"> # 当两个向量不等长时,发生循环补齐,长的说了算> x <- c(1,3,6,1)> y <- c(3,2,6)> x == y[1] FALSE FALSE TRUE FALSEWarning message:In x == y : 长的对象长度不是短的对象长度的整倍数> y == x[1] FALSE FALSE TRUE FALSEWarning message:In y == x : 长的对象长度不是短的对象长度的整倍数> #利用循环补齐简化代码> paste(rep("x",3),1:3)[1] "x 1" "x 2" "x 3"> paste0("x",1:3)[1] "x1" "x2" "x3"> #4、交集、并集、交集> x <- c(1,5,8,1)> y <- c(3,1,8)> intersect(x,y)[1] 1 8> union(x,y)[1] 1 5 8 3> setdiff(x,y)[1] 5> x %in% y #x的每个元素在y中存在吗[1] TRUE FALSE TRUE TRUE> y %in% x #y的每个元素在x中存在吗[1] FALSE TRUE TRUE>> #注意xy的赋值形式> x <- c(1,1,3,5,7);y <- c(2,4,5,6,7)> x <- c(1,1,3,5,7)> y <- c(2,4,5,6,7)>> x>10 #可得到与x等长的逻辑向量[1] FALSE FALSE FALSE FALSE FALSE> x %in% y #可得到与x等长的逻辑向量[1] FALSE FALSE FALSE TRUE TRUE> duplicated(x) #可得到与x等长的逻辑向量[1] FALSE TRUE FALSE FALSE FALSE> unique(x) #不能可得到与x等长的逻辑向量[1] 1 3 5 7#循环补齐> x <- c(1,5,7);y <- c(2,4,5,6,7)> x==y #可发生循环补齐[1] FALSE FALSE FALSE FALSE FALSEWarning message:In x == y : 长的对象长度不是短的对象长度的整倍数> unique(x) #不发生循环补齐[1] 1 5 7> x %in% y #不发生循环补齐[1] FALSE TRUE TRUE> paste(x,y) #可发生循环补齐[1] "1 2" "5 4" "7 5" "1 6" "5 7"> x+y #可发生循环补齐[1] 3 9 12 7 12Warning message:In x + y : 长的对象长度不是短的对象长度的整倍数> #向量筛选(取子集)[],即将TRUE对应的值挑选出来> x <- 8:15> x==10[1] FALSE FALSE TRUE FALSE FALSE FALSE FALSE[8] FALSE> x[x==10][1] 10> x<12[1] TRUE TRUE TRUE TRUE FALSE FALSE FALSE[8] FALSE> x[x<12][1] 8 9 10 11>> x %in% c(9,14)[1] FALSE TRUE FALSE FALSE FALSE FALSE TRUE[8] FALSE> x[x%in%c(9,14)][1] 9 14> #[]在没有遇到TRUE或FALSE时,可表示下标/位置(即第几个时对应的值)> x[2][1] 9> x[2:5][1] 9 10 11 12> x[c(1,5)][1] 8 12> x[-3]# -代表的是反选[1] 8 9 11 12 13 14 15> x[-(2:4)][1] 8 12 13 14 15> #简单向量作图> k1=rnorm(6);k1[1] -0.4591089 0.1028639 -0.1179319 -0.5134955 0.2737513 1.1585768> k2=rep(c("a","b"),each=3);k2[1] "a" "a" "a" "b" "b" "b"> boxplot(k1~k2)作业> load("gands.Rdata")> length(g)#计算长度[1] 100> length(unique(g))#去重后的个数[1] 55> g[g=seq(from=2,to=50,by=2)]#筛选下标为偶数的基因名[1] "CRAMP1L" "PRSS8" "CRAMP1L" "SLCO1C1"[5] "COMMD1" "CCT4" "RAB7A" "ZDHHC16"[9] "MYL12B" "SNRPE" "ZNF586" "GGT7"[13] "RAB7A" "AFG3L2" "AC104581.1" "MPP2"[17] "ATP2A2" "SNRPE" "PRSS8" "ZNF461"[21] "CECR5" "CLEC17A" "ATG10" "ATG10"[25] "SLC25A25"其他方式g[c(T,F)]> table(g %in% s)FALSE TRUE37 63> g[g %in% s] #g中有多少元素在s中存在[1] "GFM2" "SLCO1C1" "NYNRIN"[4] "COMMD1" "COMMD1" "AC017081.1"[7] "RAB7A" "CASKIN2" "GGT7"[10] "SNRPE" "RGPD3" "ZNF586"[13] "COMMD1" "GGT7" "URB1"[16] "RAB7A" "MPP2" "AFG3L2"[19] "URB1" "AC104581.1" "MPP2"[22] "SNRPE" "ARHGAP1" "ZNF461"[25] "OR2D3" "CECR5" "SPDL1"[28] "CLEC17A" "ZNF461" "ATG10"[31] "ATG10" "ATG10" "SLC25A25"[34] "SLC30A9" "SLCO1C1" "GGT7"[37] "CASKIN2" "GSTP1" "MPP2"[40] "NYNRIN" "INTS12" "MPP2"[43] "RGPD3" "RGPD3" "SLC30A9"[46] "C10orf128" "HBD" "SLC30A9"[49] "GGT7" "HEPH" "RP5-1021I20.4"[52] "KLHDC8A" "HBD" "ZNF586"[55] "CECR5" "OR2D3" "LIPE"[58] "INTS12" "LIPE" "SPDL1"[61] "SLCO1C1" "GGT7" "CECR5"> duplicated(g)#有多少哥基因在g中出现不止一次[1] FALSE FALSE FALSE FALSE FALSE TRUE FALSE FALSE FALSE FALSE[11] TRUE FALSE FALSE FALSE TRUE FALSE FALSE TRUE FALSE FALSE[21] FALSE FALSE TRUE TRUE FALSE TRUE FALSE FALSE TRUE FALSE[31] FALSE TRUE FALSE FALSE TRUE TRUE FALSE TRUE FALSE FALSE[41] FALSE FALSE FALSE FALSE TRUE FALSE TRUE TRUE TRUE FALSE[51] FALSE FALSE FALSE TRUE FALSE TRUE TRUE FALSE FALSE TRUE[61] TRUE TRUE FALSE TRUE TRUE FALSE TRUE TRUE TRUE FALSE[71] FALSE TRUE TRUE TRUE FALSE TRUE FALSE FALSE TRUE FALSE[81] TRUE FALSE TRUE FALSE TRUE TRUE TRUE FALSE TRUE TRUE[91] FALSE FALSE TRUE FALSE TRUE TRUE TRUE TRUE TRUE FALSE> g[duplicated(g)][1] "CRAMP1L" "COMMD1" "CCT4" "MYL12B" "COMMD1" "GGT7"[7] "RAB7A" "URB1" "MPP2" "IL19" "SNRPE" "PRSS8"[13] "ZNF461" "ATG10" "ATG10" "ZDHHC16" "SLCO1C1" "GGT7"[19] "CASKIN2" "UBAC1" "MPP2" "NYNRIN" "MYL12B" "MPP2"[25] "RGPD3" "RGPD3" "SLC30A9" "SLC30A9" "MYL12B" "GGT7"[31] "TUBA4A" "HBD" "CCT4" "ZNF586" "CECR5" "OR2D3"[37] "CRAMP1L" "INTS12" "LIPE" "SPDL1" "SLCO1C1" "MARC2"[43] "GGT7" "LCP1" "CECR5"> unique(g[duplicated(g)])[1] "CRAMP1L" "COMMD1" "CCT4" "MYL12B" "GGT7" "RAB7A"[7] "URB1" "MPP2" "IL19" "SNRPE" "PRSS8" "ZNF461"[13] "ATG10" "ZDHHC16" "SLCO1C1" "CASKIN2" "UBAC1" "NYNRIN"[19] "RGPD3" "SLC30A9" "TUBA4A" "HBD" "ZNF586" "CECR5"[25] "OR2D3" "INTS12" "LIPE" "SPDL1" "MARC2" "LCP1"> length(unique(g[duplicated(g)]))[1] 30> rnorm(n=10,mean = 0,sd=18)#列出<2的数值[1] 12.180906 -31.719927 -23.929819 1.933203 34.938306[6] 6.453842 13.887899 11.719862 5.991164 -25.730037> z <- rnorm(n=10,mean = 0,sd=18)> z[z < -2][1] -19.53764 -12.31483 -7.96186 -15.47074 -35.08725> z[z <(-2)][1] -19.53764 -12.31483 -7.96186 -15.47074 -35.08725

若有收获,就点个赞吧
0 人点赞
