参考:https://zhuanlan.zhihu.com/p/28054589
one-hot表示法:用一个位置是1,其余位置都是0的向量来表示一个单词,每个向量的维度都等于字典大小
语言模型——直接学习语料库,可用于ASR和机器翻译
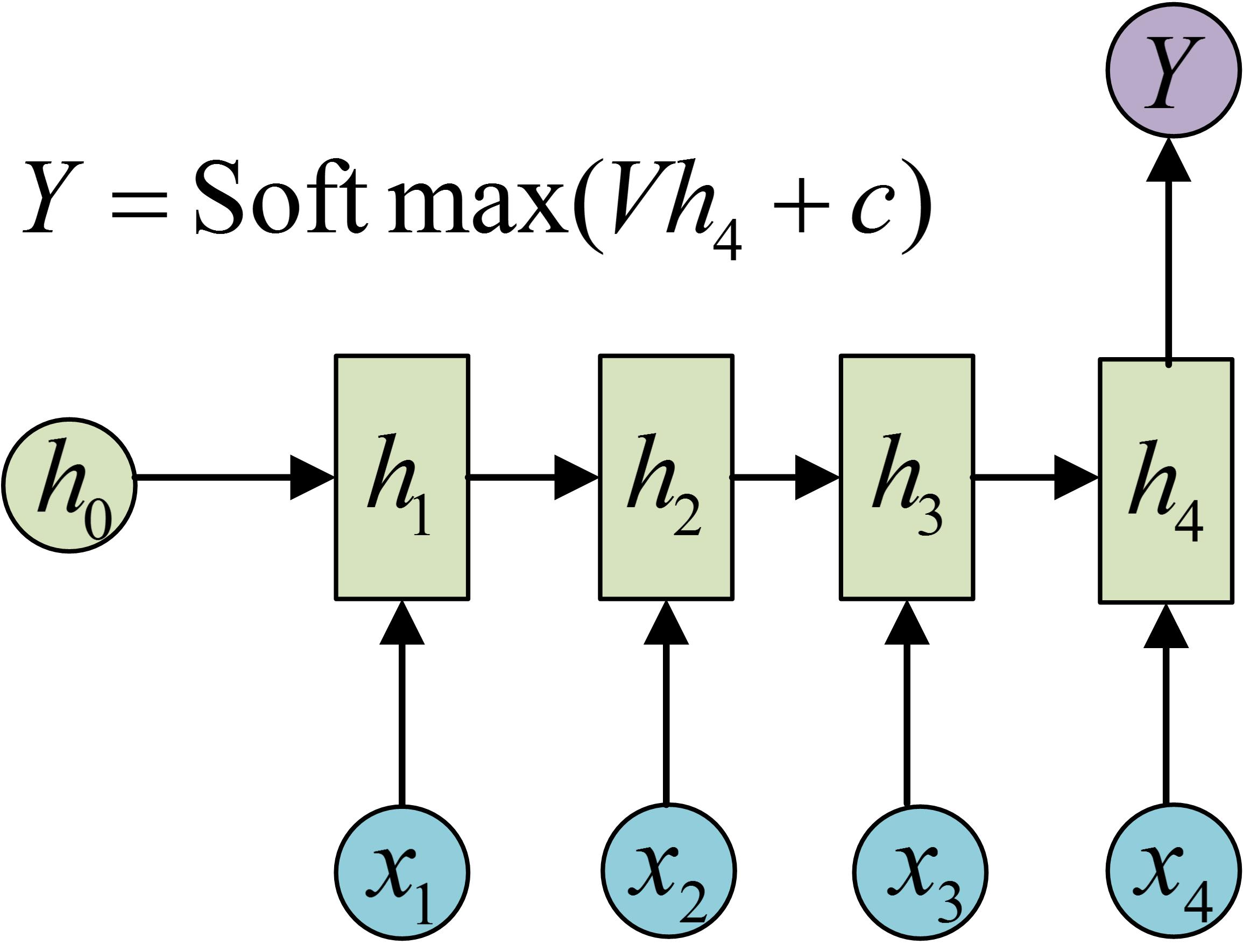
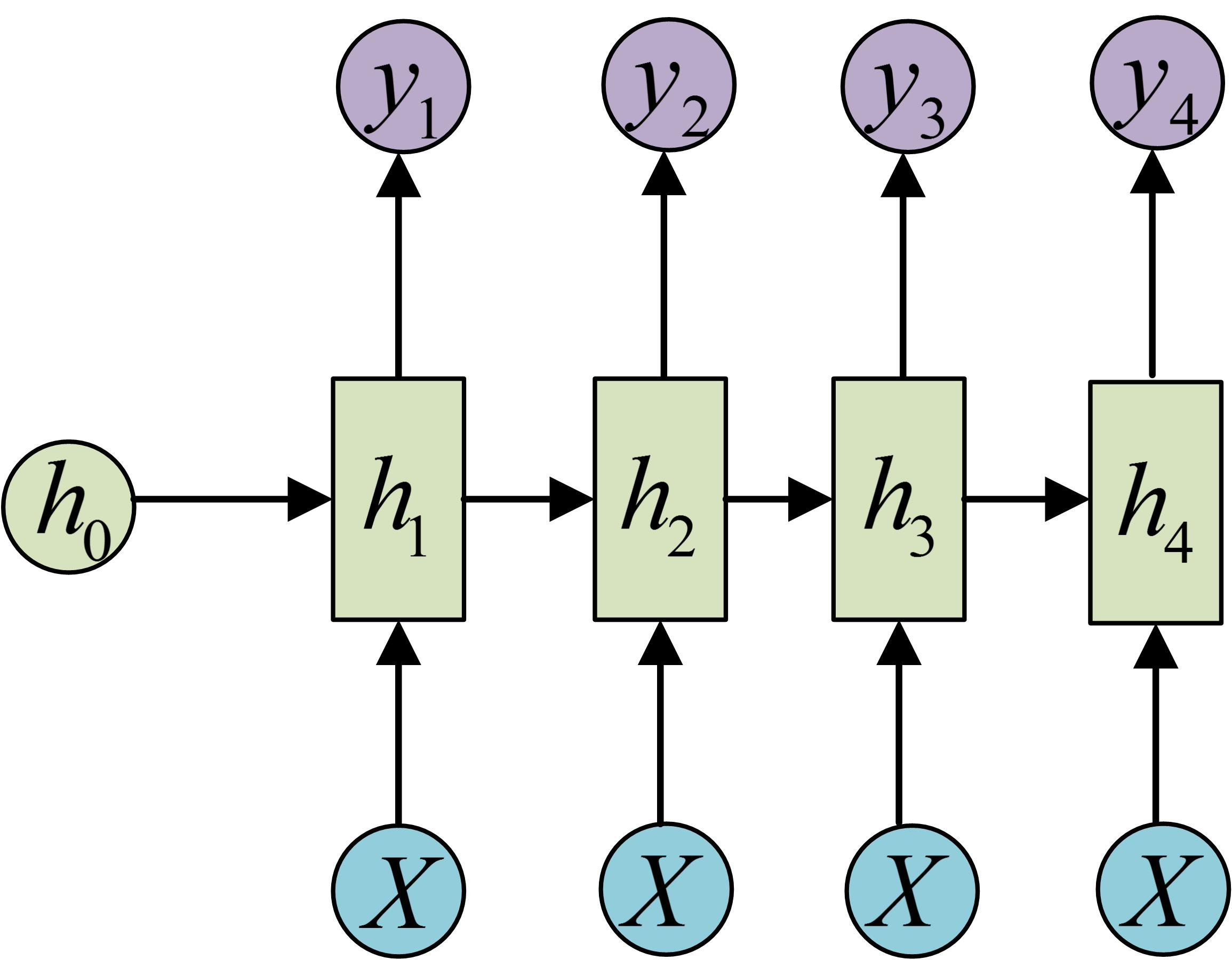
标准RNN(输出和输出一样长)

多对一RNN
一对多RNN
第一种方案,只在序列开始时输入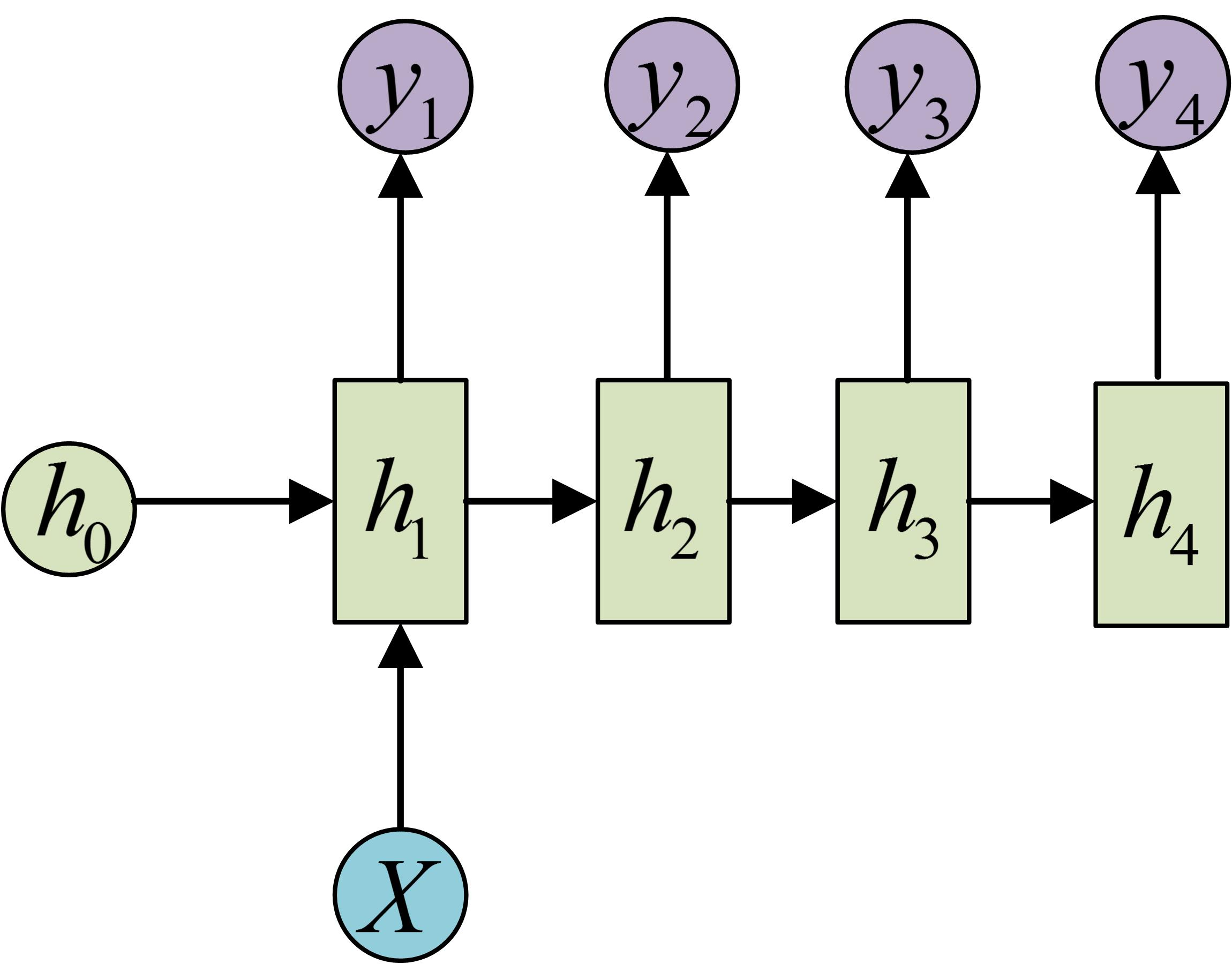
Encoder-Decoder (Seq2Seq,多对多RNN)

带有Attention的Encoder-Decoder
一个状态能存的信息有限,decoder训练一组混合参数,用这组参数混合encoder中的每一个隐藏状态
问题:输出序列的长度怎么决定,什么时候停?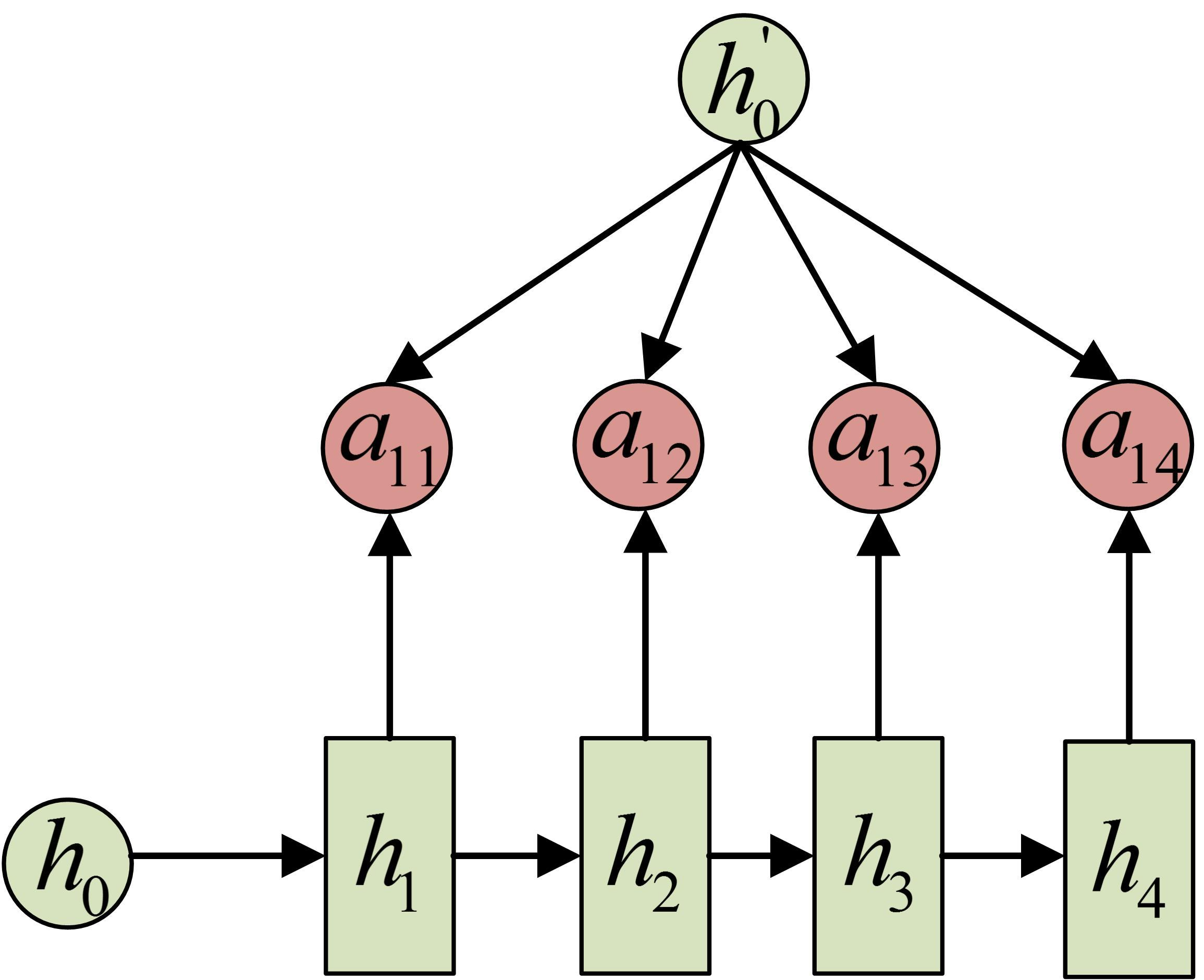
Decoding
Greedy
Beam Search
GRU
GRU单元(Gated Recurrent Unit),门循环控制单元,解决记忆时间太短问题(梯度消失问题)

LSTM,改成了三个门,更新门、遗忘门、输出门(GRU出现得更晚。GRU结构简单,更容易应用到大规模,LSTM更强大,但是更复杂)


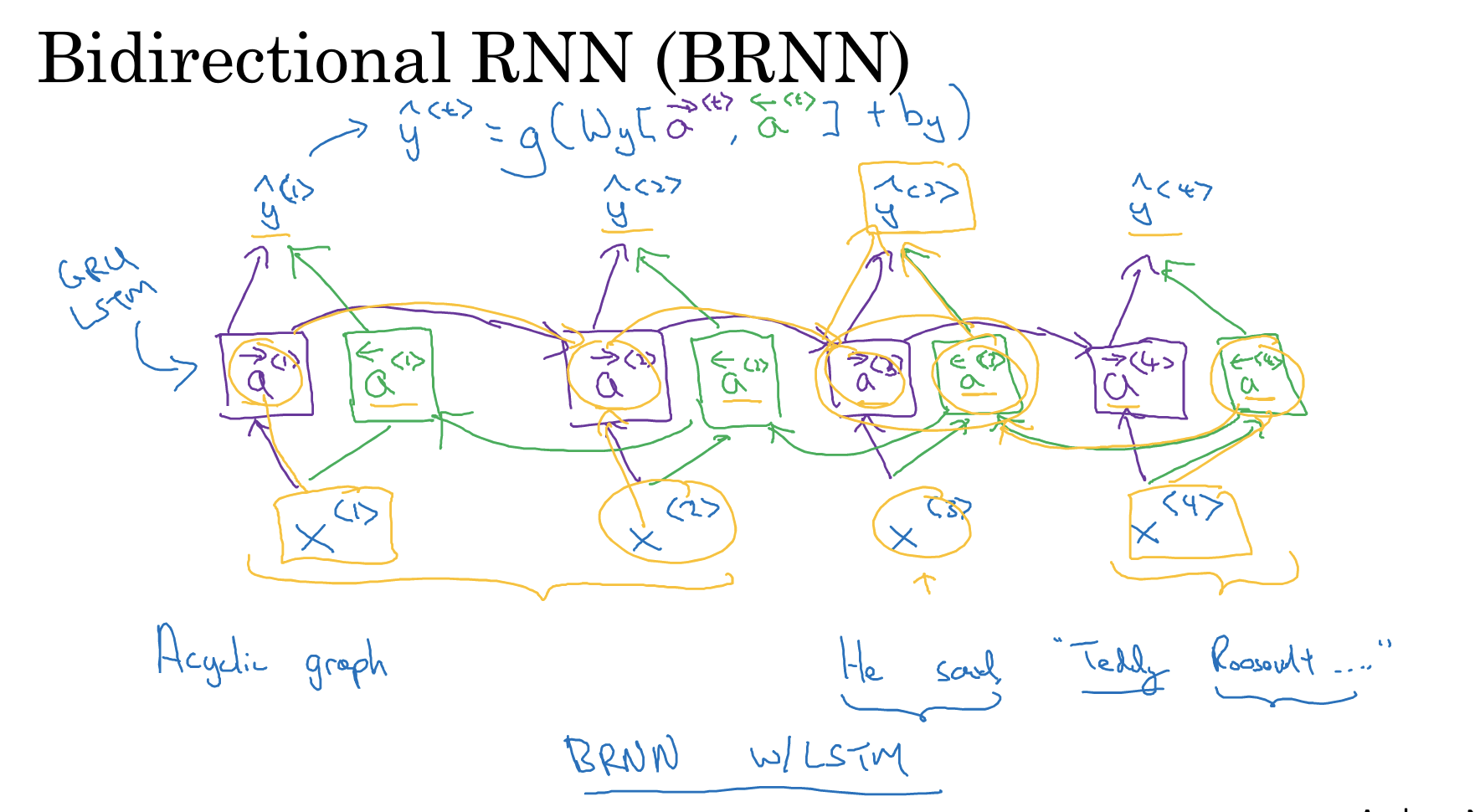
BRNN
深层RNN网络


若有收获,就点个赞吧
0 人点赞
