Policy Gradient
术语和基本思想
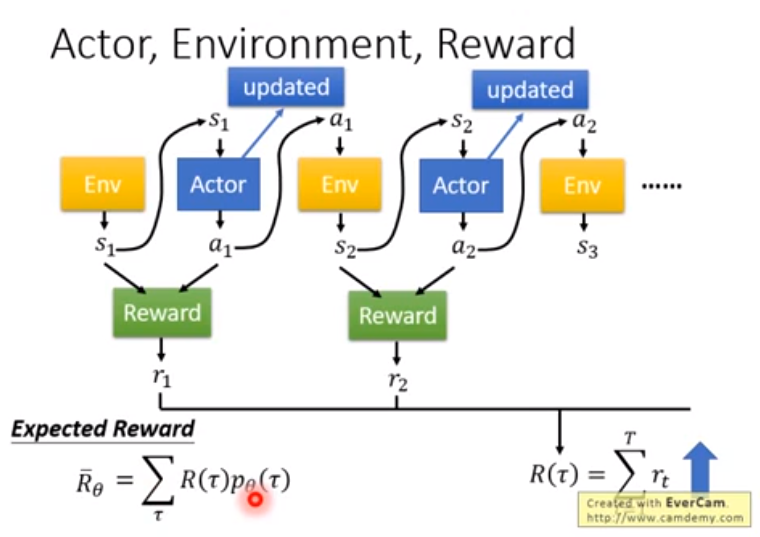
基本组成:
actor (即policy gradient要学习的对象, 是我们可以控制的部分)
环境 environment (给定的,无法控制)
回报函数 reward function (无法控制)
episode:游戏从开始到结束的一个完整的回合
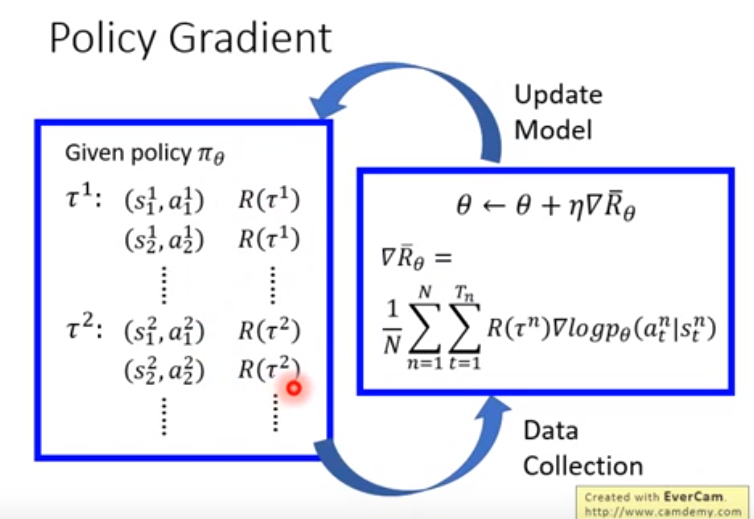
actor的目标:最大化总收益reward
π(θ):输入state,输出actor
Trajectory τ:行动action和状态state的序列
给定神经网络参数θ的情况下,出现行动状态序列τ的概率pθ(τ):
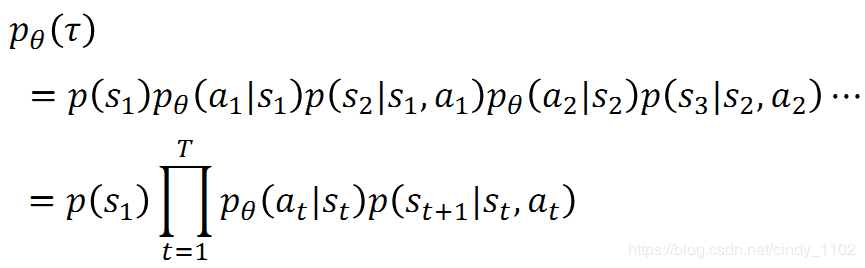
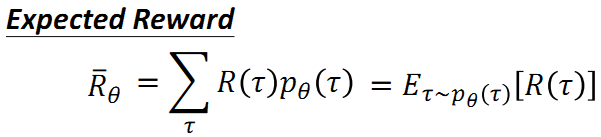
对θ梯度上升
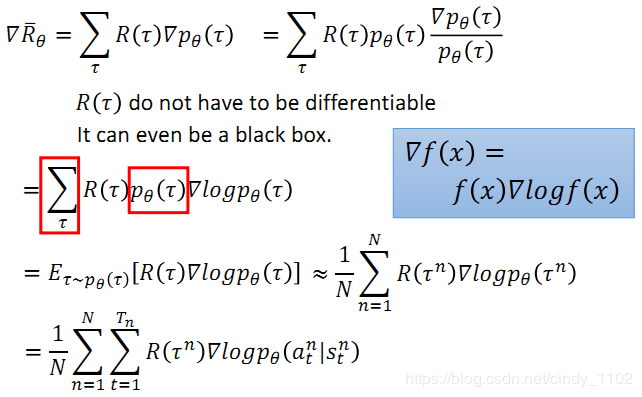
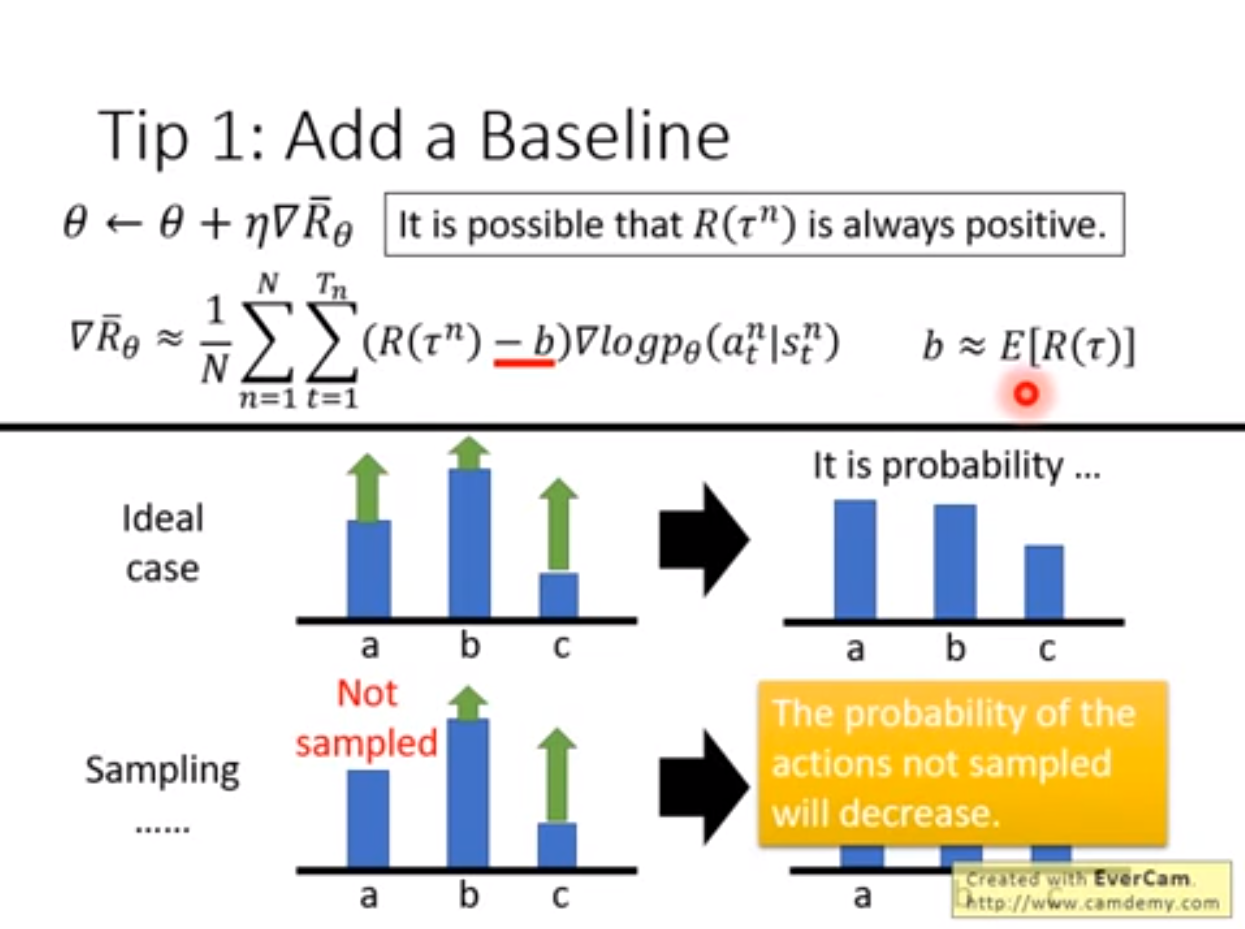
如果reward function本来只能取正值,增加baseline,让reward function的值可以为负
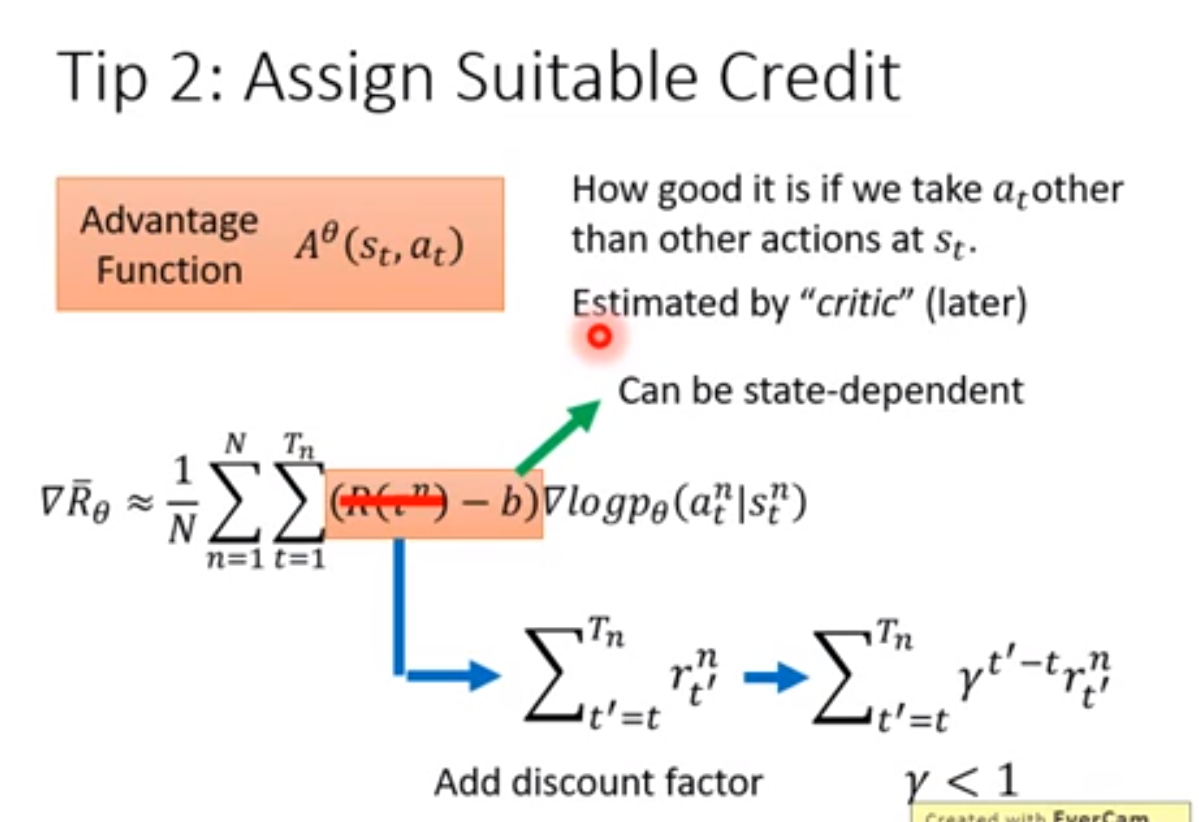
在sampling不够多的情况下,尽量要让reward funtion对每一步行为都做出评价,否则一场game结束后无法区分哪些actor是好的,哪些的坏的。
如果每一步结束后有一个总体的奖励,可以计算从这个动作开始到结束的奖励值之和作为权重。并且离得越远,贡献越小,增加一个衰减。
从on-policy到off-policy (反复多次使用经验)
术语和基本思想
On-policy: 学习的agent以及和环境进行互动的agent是同一个agent(一边玩一边学)
Off-policy: 学习的agent以及和环境进行互动的agent是不同的agent(看别人玩的时候学习)
Proximal Policy Gradient

若有收获,就点个赞吧
0 人点赞
