
概念
分类(classification): 离散
回归(regression): 连续,输出是数值
生成(generation)
感知机(PLA)
二类分类 损失函数:误分点到超平面的距离 线性 学习算法:随机梯度下降
线性回归
y = wx + b
回归 损失函数:均方差MSE 线性 最小二乘法求损失函数,梯度下降法优化
广义线性回归
y = g(wx + b)
logistic回归(广义线性回归的特例)
y = sigmoid(wx + b)
多类分类 输出的对数几率是输入x的线性函数 极大似然法求损失函数,梯度下降法优化
logistic函数=sigmoid函数
logit函数(logit odds,对数几率):logit(p)=log p/(1-p)
吴恩达version,损失函数:
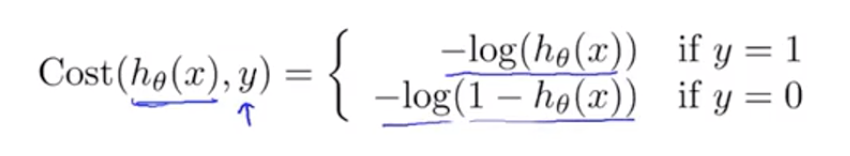
最大熵模型
多类分类
学习概率模型时,熵最大的模型是最好的模型,不确定的部分都是等可能的
k近邻法
多类分类、回归 无显式学习过程
朴素贝叶斯法
多类分类
支持向量机(SVM)
y = sign(wx + b)
选择距离正样本和负样本最远的超平面作为分类超平面
二类分类 损失函数:合页损失
决策树
算法流程:特征选择、决策树的生成、决策树的剪枝
常见算法:ID3、C4.5、CART
特征选择:根据信息增益(信息增益比)
决策树的生成
决策树的剪枝
信息熵:取值范围[0,1]
随机森林
Bootstrap抽样:有放回的均匀抽样
Bagging算法:
用Bootstrap抽样产生多个决策树
多个决策树投票决定最终结果
随机森林:
在Bagging算法的基础上随机选取分裂属性集
隐马尔科夫模型
标注
条件随机场
标注
神经网络

若有收获,就点个赞吧
0 人点赞
