[toc]
卷积
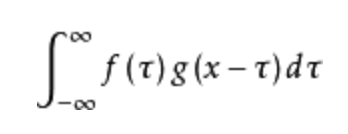
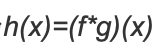
利用一点性质,即两函数的傅里叶变换的乘积等于它们卷积后的傅里叶变换,能使傅里叶分析中许多问题的处理得到简化。
卷积得到的函数f*g一般要比f和g都光滑
激活函数
https://blog.csdn.net/tyhj_sf/article/details/79932893
https://zhuanlan.zhihu.com/p/32610035
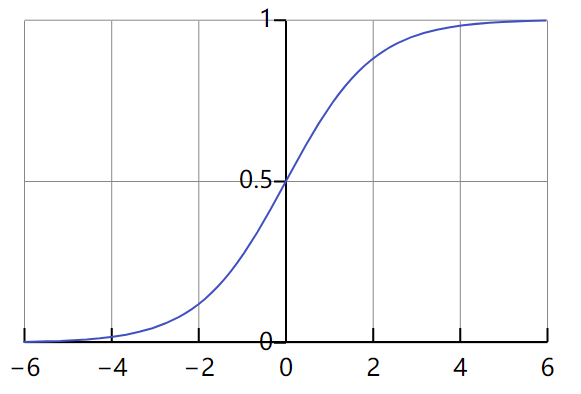
sigmoid
将实数压缩为[0,1]
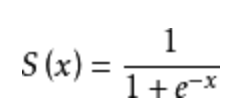
softmax:
将一个含任意实数的K维向量 “压缩”到另一个K维实向量 中,使得每一个元素的范围都在[0,1]之间,并且所有元素的和为1
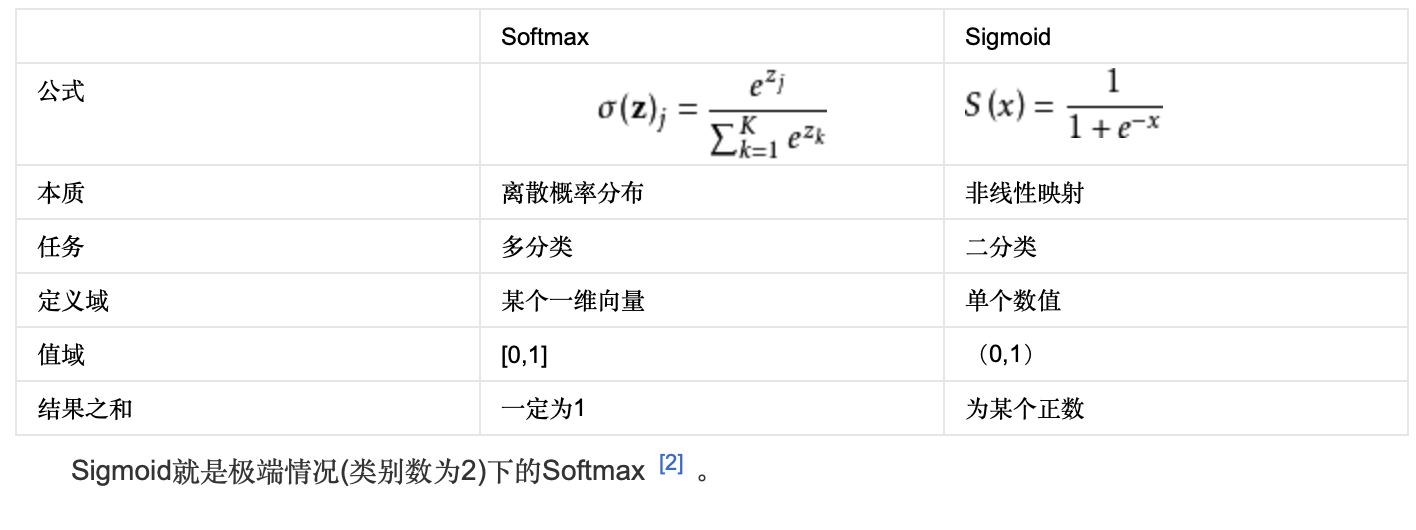
ReLU线性整流函数(Rectified Linear Unit)
f(x) = max(0, x)
f(x) = max(0, wx+b)
Maxout

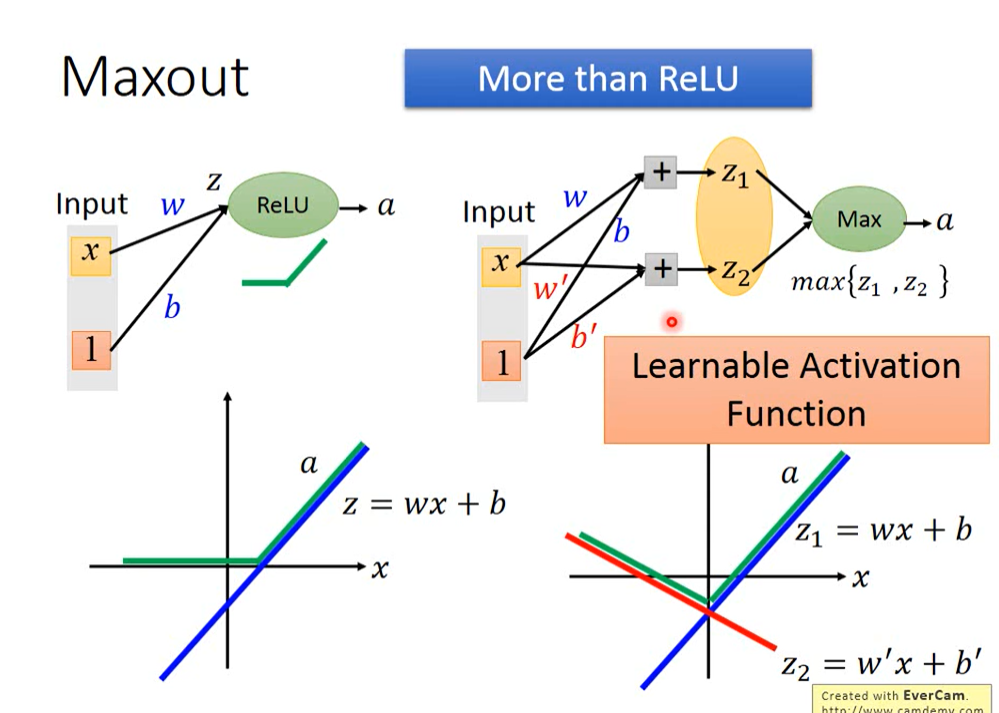
tan h 双曲正切
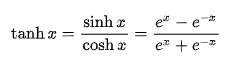
过原点,奇函数,定义域:R,值域:(-1,1)
范数(norm)

L1范数又称稀疏规则算子”(Lasso regularization)
L0范数是向量中非0的元素的个数
矩阵范数
https://zhuanlan.zhihu.com/p/35897775

常用损失函数
1. 0-1损失函数

2. 绝对值损失函数
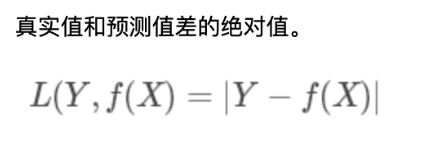
3. 平方损失函数 (MSE)
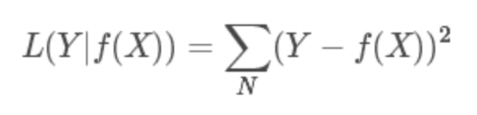
4. 指数损失函数
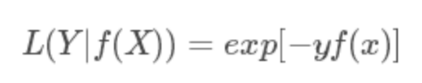
5. 对数损失函数
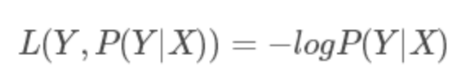
6. 合页损失函数

7. 交叉熵损失函数(cross_entropy)
参考:https://zhuanlan.zhihu.com/p/38241764
二分类
0-1分类的交叉熵损失函数
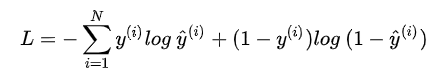
其中 是神经网络的输出(sigmoid的输出),是极大似然估计的参数Θ,代表模型当前样本的y为1的概率,具体值由输入x决定,每个样本都有自己的。
是神经网络的输出(sigmoid的输出),是极大似然估计的参数Θ,代表模型当前样本的y为1的概率,具体值由输入x决定,每个样本都有自己的。
y是观测值,样本的真实类。
多分类
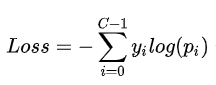

sigmoid(softmax)+cross-entropy loss 擅长于学习类间的信息,因为它采用了类间竞争机制,它只关心对于正确标签预测概率的准确性,忽略了其他非正确标签的差异,导致学习到的特征比较散。基于这个问题的优化有很多,比如对softmax进行改进,如L-Softmax、SM-Softmax、AM-Softmax等。

若有收获,就点个赞吧
0 人点赞
