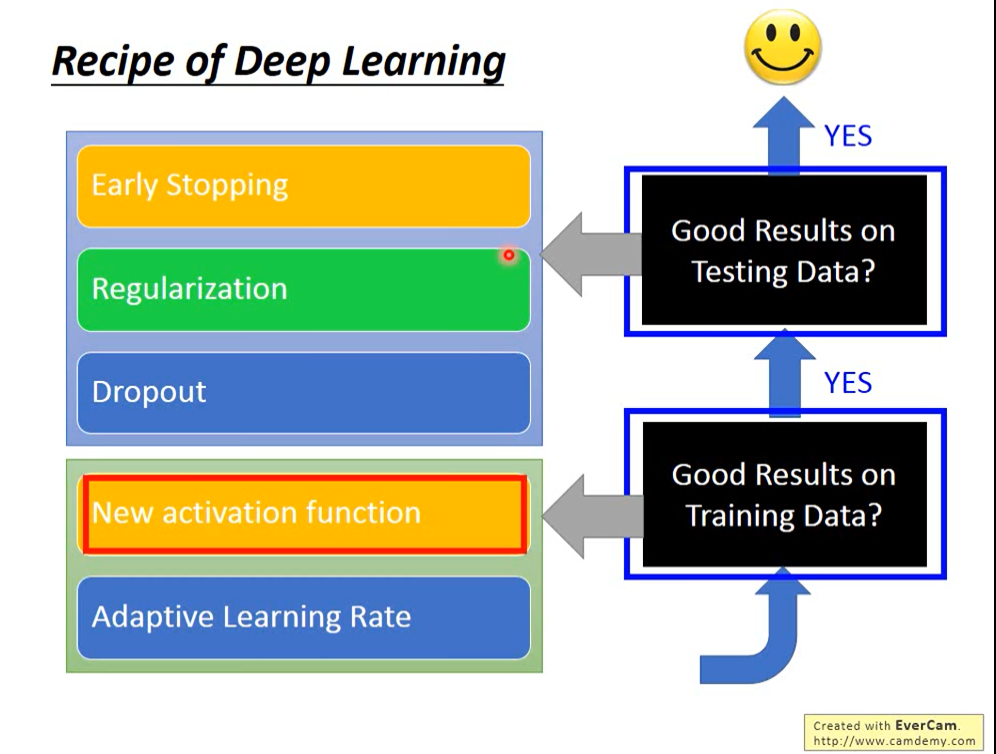
1.训练集效果差
梯度消失
前几层还是ramdon参数的时候后面几层就收敛了,在训练集上效果就会很差
解决方案:激活函数不使用sigmoid,使用ReLU、Maxout等
优化到局部最小值
动量、Adam
2 测试集效果差——过拟合
early stopping
用验证集确认没有过拟合,如果过拟合了就停下来
regularization
在优化函数里加上对参数的其他限制,比如限制参数的l2 norm
实际上是在做Weight Decay,每次更新权重时都让权重的绝对值变小一点(与人脑类似)
l2 regularization和l1 regularization的区别:
- 从极值导数是否为0判断
- 从先验概率看,l2约束对应高斯先验分布,l1约束对应laplace先验分布
laplace分布的概率密度函数:
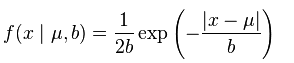
- 从优化过程看
l1 regularzation减小的值与w本身的大小无关,即使w很大或者很小,减小的速度也是固定的。

Dropout

如果网络是线性的,w乘以(1-p)后得到结果的期望与ensemble的期望是一样的,所以dropout在激活函数是relu时效果更好

若有收获,就点个赞吧
0 人点赞
