深度强化学习DRL
缺点:
- 学习效率低,需要海量的Agent和环境的交互数据,样本利用率非常低
- 奖励函数设计困难,如果设置的奖励过度拟合你的目标,智能体会容易钻空子,产生预期外的结果
- 不稳定,收敛困难,调参困难,DRL不稳定,结果难以重现,超参数调节会对系统稳定性产生很大的影响,很难判断自己的代码到底有没有bug还是运气不好
- 最终表现很多时候不够好,很多应用,比较成熟的方法效果都不比DRL差
- 局部最优/探索和剥削(exploration vs. exploitation)的不当应用
- 对环境的过拟合
DRL成功的案例其实非常少,大体包括:
- 各类游戏:Atari Games, Alpha Go/Alpha Zero/Dota2 1v1/超级马里奥/日本将棋,其实还应该有DRL最早的成功案例,93年的西洋双陆棋(backgammon)。
- DeepMind的跑酷机器人。
- 为Google的能源中心节能。
- Google的AutoML。
作者认为从这些案例里获得的经验教训是DRL可能在有以下条件的情况下更可能有好的表现,条件越多越好:
- 数据获取非常容易,非常cheap。
- 不要急着一上来就攻坚克难,可以从简化的问题入手。
- 可以进行左右互搏。
- 奖励函数容易定义。
- 奖励信号非常多,反馈及时。
深度学习的特点:
- 推迟得到的回报: 有些action可能和reward的获得没有直接的关系,还有的action可能会在最初产生负的reward,后期生成较大的正的reward
- 采取的action会对后期接受的数据产生影响
强化学习方法
- model-based(Action based)关注每一步的最优行动
- model-free (policy-based 关注最优策略 and/or value-based 关注最优奖励总和)
(Alpha GO: policy-based+value-based+model-based)
Policy-based approach – learn an actor
step1: 将神经网络作为actor (模型的泛化能力较好)
step2: 衡量actor的好坏 (使用总回报reward的期望值来进行评估)
step3: 选择最好的actor
Value-based approach – learn a critic
Critic: 用来评估actor
State value function(V): 在看到某一个状态state的时候预期能够得到的累积收益Estimation of V:
- Monte-Carlo(MC): critic会观察actor π 玩游戏的整个过程, 具有不确定性,较大的方差,但结果无偏
- Temporal-difference(TD): 只计算状态与状态之间的收益reward,具有较小的方差,但是结果可能造成偏误
- State action value function: 基于状态state和行动action得到收益reward
- Q-learning: actor π和环境做互动,然后不断用一个更好的 π’来更新π
Actor-Critic
会在之后的笔记中进行详细介绍
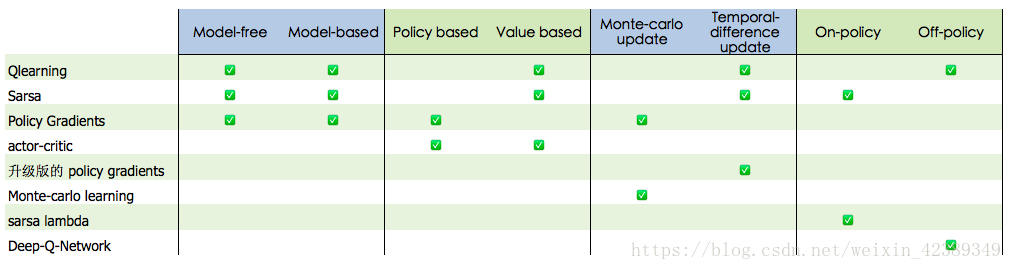
Q-learning(Value-Based, Off-Policy)

Saras是agent处于新状态s’,就知道要采取行动a’,并且执行了,行动的选择根据策略,Q值的计算是根据动作a’,而Qlearning是agent处于新状态s’,只能知道采取哪个行动可以得到maxQ,并没有采取对应行动,它是根据当前Q和策略来采取行动的
Saras

Actor-Critic
Sparce Reward
Imitation Learning
DQN(off-policy)
挑战
DL与RL结合存在以下问题 :
- DL是监督学习需要学习训练集,强化学习不需要训练集只通过环境进行返回奖励值reward,同时也存在着噪声和延迟的问题,所以存在很多状态state的reward值都是0也就是样本稀疏
- DL每个样本之间互相独立,而RL当前状态的状态值是依赖后面的状态返回值的。
- 当我们使用非线性网络来表示值函数的时候可能出现不稳定的问题
DQN中的两大利器解决了以上问题
- 通过Q-Learning使用reward来构造标签
- 通过experience replay(经验池)的方法来解决相关性及非静态分布问题
- 使用一个MainNet产生当前Q值,使用另外一个Target产生Target Q
DQN用到了两个关键技术涉及到了两个关键技术:
1、样本池(Experience Replay):将采集到的样本先放入样本池,然后从样本池中随机选出一条样本用于对网络的训练。这种处理打破了样本间的关联,使样本间相互独立。
2、固定目标值网络(Fixed Q-target):计算网络目标值需用到现有的Q值,现用一个更新较慢的网络专门提供此Q值。这提高了训练的稳定性和收敛性。
效果与不足
DQN在Atari games上用原始像素图片作为状态达到甚至超越人类专家的表现、通过左右互搏(self-play)等方式在围棋上碾压人类、大大降低了谷歌能源中心的能耗等等。当然DQN也有缺点,它是高维输入,低维输出的,当涉及到一次性输出连续动作时,即高维度输出,就束手无策了,DeepMind也在后续提出了DDPG。
Multi-Agent Learning(MAL)
挑战
agent不仅要跟环境互动,还要跟其他agent互动
任务类型
- 完全合作,每个agent的励函数相同,R1=R2=…=Rn,最大化共同回报即可
- 完全竞争,R1=-R2
- 混合型,指定良好的、通用的MARL目标是一个难题
稳定性和适应性。
稳定性指智能体的学习动力的稳定性以及策略会收敛至固定。
适应性确保智能体表现不会因为其他智能体改变策略而下降。收敛至均衡态是稳定性的基本要求,即所有智能 体的策略收敛至协调平衡状态,最常用的是纳什均衡。适应 性体现在理性或无悔两个准则上。理性是指当其他智能体稳定时,智能体会收敛于最优反馈;无悔是指最终收敛的策略的回报不能差于任何其他策略的回报。
完全合作
各智能体在做决策时是非独立的,即使它们平行地学习一个共同的目标,因此考虑智能体之间的协作问题变得很有必要。
Team-Q算法通过假设最优的联合行动是唯一的来避免协作问题。Distributed-Q算法在不假设协调的情况下以有限的计算量解决协作任务,其计算复杂度与单智能体Q-Learing的计算复杂度相似。然而,该算法只适用于具有非负报酬函数的确定性问题。上述算法存在一些局限,即它们都依赖于对状态的精确测量,一些还需要精确测量其他智能体的作用,并且还会受维数灾难的影响。
混合型任务
在混合随机博弈中,智能体的奖励函数不受约束,这种模式最适合自私的智能体。博弈论均衡概念在混合随机博弈中运用得最多,该类别中的大量算法仅针对静态任务。像Q学习这样的单智能体算法可以直接应用到混合型任务中。参数的更新需要使用所有智能体的Q表,因此每个智能体都要复制其他智能体的Q表,这要求所有的智能体使用相同的算法并且可以测量所有的动作和奖励。即使有了这些假设,当不同智能体求得的策略不唯一时,也会出现均衡选择问题。一种常用的方法是Nash Q-learning,此外还有相关平衡Q学习(CE-Q)[23]或不对称Q学习(Asymmetric Q-Learning)[4],它们可以分别通过使用相关或Stackelberg(前导-跟随)平衡来解决均衡问题。对于不对称Q学习,跟随者不需要对领导者的Q表进行建模,但是领导者必须知道追随者如何选择其行动。

然而,传统的MARL算法多适用于小规模的问题,很少有算法能应用于信息不完整或不确定的环境。提高MARL对实际问题的适应性是一个必不可少的研究步骤。

若有收获,就点个赞吧
0 人点赞
