传统ASR,声学模型包括高斯混合模型和隐马尔科夫模型
Gaussian Mixture Model (GMM) and Hidden Markov Model (HMM)
GMM用来找语音对应的模型(音素?),HMM用来求给定模型(音素?)之后语音的概率(声学模型)
使用EM训练算法
深度神经网络
直接代替GMM
·为什么一直留着HMM?
-神经网络只进行逐帧判别
-训练时,需要由HMM系统提供各音素起止
时间
–解码时,需要考虑状态转移概率
如果使用CTC,HMM也不需要了
因为HMM的两个作用,一个是在训练的时候提供对齐,现在我不要对齐了;另外一个是HMM本来是用来做帧之间的转移概率的,现在我说你这个建模很粗糙,我不要了。HMM就没用了。
传统asr的基本结构

声学模型P(X|W)是一个生成模型,实际是从音素序列映射到特征向量
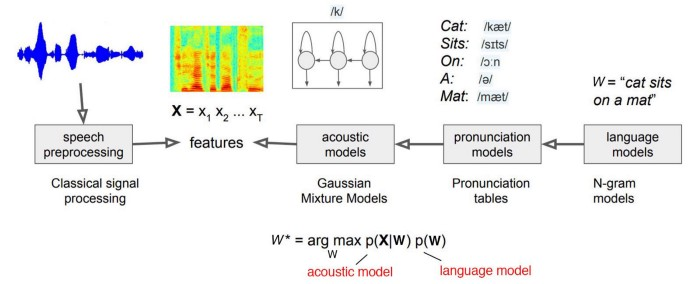
The distribution of features for a phone can be modeled with a Gaussian Mixture Model (GMM). We will learn it with training data. The transition between phones and the corresponding observable can be modeled with the Hidden Markov Model (HMM).
GMM对一个音素的特征分布进行建模,即P(Xt|音素t)
HMM对音素序列和特征序列进行建模,即P(X|音素序列),这里音素就是hidden state
HMM的解码过程由Viterbi algorithm或其他HMM的方法在多项式时间内完成
GMM+HMM+Lexicon = 声学模型
隐马尔科夫模型
Markov Assumption
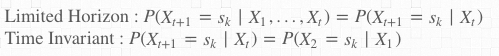
其中,
Limited Horizon 的意思是,
每个 Xt+1 是什么字 (si) 的概率, 只会受到上一个字 Xt 的影响
Time Invariant 的意思是,
每个 Xt+1 是什么字 (si) 的概率, 和前一个字 Xt 的机率关系, 不会因为在字串中的位置不同, 而有所改变
事实上, 这两种假设是为了简化计算, 在真实的自然语言中, 以上两种假设都不成立
建立转移矩阵得到马尔科夫模型,这样语料库中的任意一个序列都可以有概率连乘得到
马尔科夫模型中state就是字,而隐马尔科夫模型的state不能直接观测,相对而言observable就是字
隐状态映射到可观测状态的概率称为发射概率,隐状态之间的转换概率称为转移概率
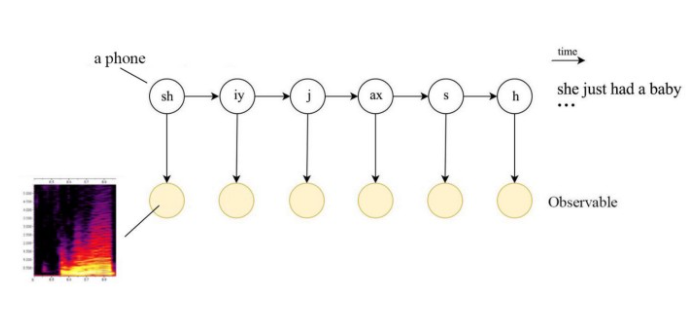
竖着的箭头是GMM,横着的箭头是HMM
Viterbi Decoder
解码器用Viterbi算法,动态规划的最短路径算法

若有收获,就点个赞吧
0 人点赞
