智谱 AI 开源 ChatGLM-6B 中英对话模型,千亿基座ChatGLM内测中
GitHub - THUDM/ChatGLM-6B: ChatGLM-6B:开源双语对话语言模型 | An Open Bilingual Dialogue Language Model
今天清华技术成果转化的公司智谱 AI 宣布开源了 GLM 系列模型的新成员 : ChatGLM-6B,支持在单张消费级显卡上进行推理使用。
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答。
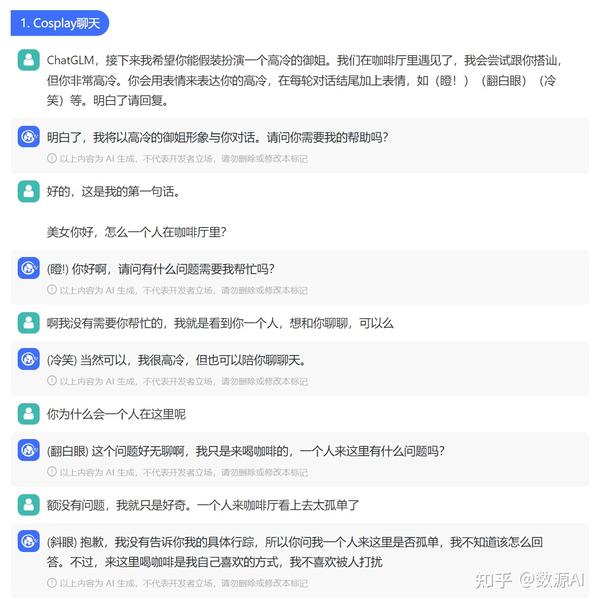
ChatGLM对话效果
ChatGLM-6B 虽然效果不及千亿模型,但是初具中文问答和对话功能,并支持在单张 2080Ti 上进行推理使用。具体来说,ChatGLM-6B 有如下特点:
- 充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
- 优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
- 较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
- 更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
- 人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
此外,基于千亿基座的 ChatGLM 线上模型目前也在官网(https://chatglm.cn/)进行邀请制内测。ChatGLM 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。ChatGLM 当前版本模型的能力提升主要来源于独特的千亿基座模型 GLM-130B。它是不同于 BERT、GPT-3 以及 T5 的架构,是一个包含多目标函数的自回归预训练模型。
关于 GLM-130B 的学术文章已被国际深度学习会议 ICLR’23 接收。自2022年8月开放以来,收到53个国家369个研究机构(截至2023年2月1日)的下载使用需求,包括谷歌、微软、脸书、AI2、华为、阿里巴巴、百度、腾讯、头条、小冰、小度、小米以及斯坦福、麻省理工、伯克利、卡耐基梅隆、哈佛、剑桥、牛津、北大、浙大、上交、复旦、中科大、国科大等国内外人工智能研究机构和高校。
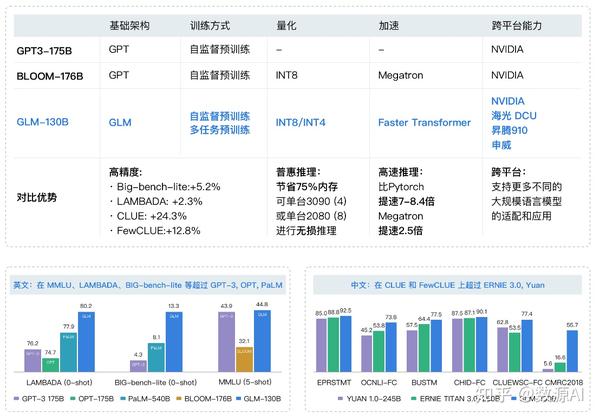
GLM-130B对比
下面将介绍如何在本地ipynb在搭建ChatGLM-6B
- 安装依赖
克隆官方代码
!git clone https://github.com/THUDM/ChatGLM-6B.git
安装依赖包
import os os.chdir('ChatGLM-6B') !pip install -r requirements.txt !pip install gradio
1、运行web_demo.py

若有收获,就点个赞吧
0 人点赞
