1、Kafka 特性
高吞吐量、低延迟:Kafka每秒可以处理几十万条消息,延迟最低只有几毫秒;
可扩展性:kafka集群支持热扩展;
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失;
容错性:允许集群中节点失败(若副本数量为n, 允许n-1个节点失败);
高并发:支持数千个客户端同时读写 ;
1.1 高性能高吞吐原因
1.1.1 磁盘顺序读写
顺序读写
磁盘会预读,预读即在读取的起始地址连续读取多个页面。
随机读写
因为数据没有在一起,将预读浪费掉了。需要多次寻道和旋转延迟。
1.1.2 零拷贝
避免CPU将数据从一块存储拷贝到另外一块存储的技术
传统的数据复制
【1】读取磁盘文件数据到内核缓冲区<br /> 【2】将内核缓冲区的数据copy到用户缓冲区<br /> 【3】将用户缓冲区的数据copy到socket的发送缓冲区<br /> 【4】将socket发送缓冲区中的数据发送到网卡,进行传输。
2、Kafka 使用场景
- 日志收集:Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr 等。
- 消息系统:解耦和生产者和消费者、缓存消息等。
- 用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
- 运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
-
3、Kafka 基本概念与架构组成
3.1 Kafka中涉及的角色
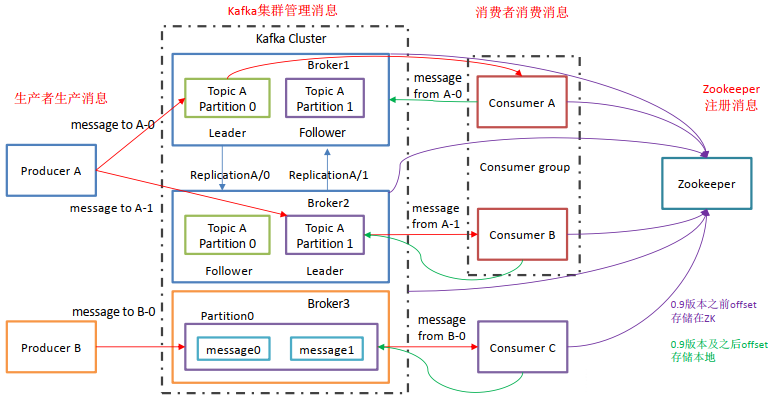
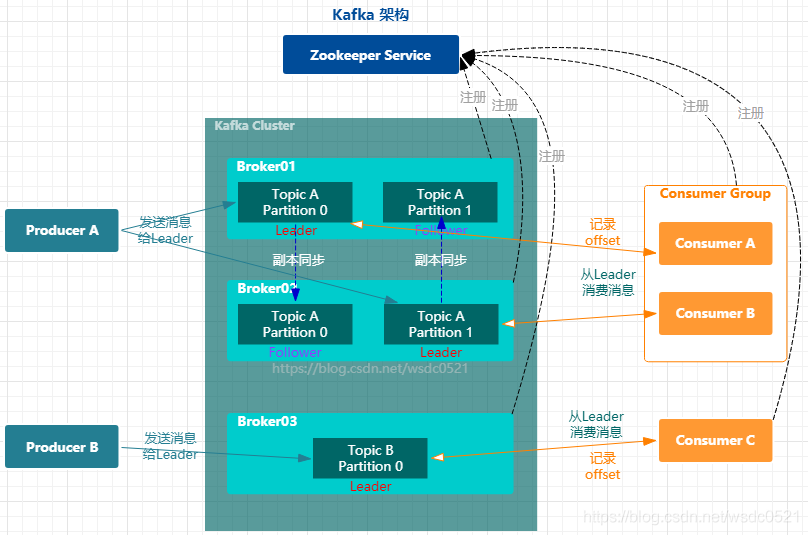
Broker:消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群,一个Broker可以容纳多个 topic;
Topic:逻辑概念。Kafka 对消息保存时根据 Topic 进行归类,一个Topic可以认为是一类消息。
可以理解为一个队列, 生产者和消费者面向的都是一个 topic。一个Topic可以横跨多个Broker ,以此来提供比单个Broker更强大的性能。
Partition:物理概念。每个topic将被分成一到多个partition(分区),每个partition在存储层面就是一个append log文件。一个topic可以分成多个partition,分布到多个broker上。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
- Offset:任何发布到Partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因此在kafka中几乎不允许对消息进行“随机读写”。
- Producer:生产者。Producer将消息发布到指定的Topic,也可以指定Partition。
- Consumer:消费者。Consumer采用pull的形式从Producer拉取消息
- Consumer Group:每个 consumer 属于一个特定的 consumer group(若不指定 group name 则属于默认的 group)。一个 topic可以有多个CG,topic的消息会分发到所有的CG,但每个CG只会把消息发给该CG中的一个consumer。如果所有的consumer都具有相同的group, 即单播,消息将会在consumers之间负载均衡;如果所有的consumer都具有不同的group,那这就是”发布-订阅”,每条消息将会广播给所有的consumer。
- Replication :分区副本,为了实现高可用,保证集群中的某个节点发生故障时,该节点上的partition 数据不丢失且kafka能正常提供服务,kafka提供副本机制,topic内的每个分区可以设置若干个副本(包含leader和follower);
- Leader : Topic 内分区副本的主副本,生产者的数据发送到Leader,消费者也是从Leader中消费数据;
- Follower :Topic 内分区副本的从副本,从主副本中同步数据,保证和主副本的数据一致性,当主副本出现故障时,某一个Follower 会成为新的Leader ,Follower副本不接收生产者消费者的读写请求。
ZooKeeper : 帮助 Kafka 维护Broker 的控制节点以及Topic 元数据信息,帮助控制器进行分区副本的选举。(高版本已移除ZK)
3.2 需要注意的点
Kafka 的副本数量(Replication)不能大于Broker 节点数量
Kafka的副本数量表示该Topic的副本数量,当副本数量大于Broker 节点数量时会报错,这是因为分区是以目录存储在各个Broker 节点的Data 目录下,命名为topicName-分区编号。当副本数量大于broker节点时表示在同一个Broker节点的data目录下有两个一样的文件夹,这是不允许的。
副本的目的 是为了保证集群中某一个节点发生故障时,该节点上的partition的数据不丢失。如果一个
broker上出现两个相同副本,不起任何作用。
- Kafka的分区数量可以大于Broker节点数量
当分区数量大于Broker节点数量时,在Broker节点的data目录下会有同一个Topic的两个分组的数据,比如:topicName-0,topicName-1
- 消费者组内的消费者的数量不要设置大于该消费者组订阅的所有topic的分区总数
这是由于该消费者组订阅的topic的每个分区只能被消费者组内的一个消费者所消费,当消费者组内的消费者数量大于订阅的topic的总分区数量时就会造成有消费者没有分区数据消费的情况,会造成资源的浪费。
- Kafka只保证分区内有序,不能保证全局有序。
4、Kafka工作流程及文件存储机制
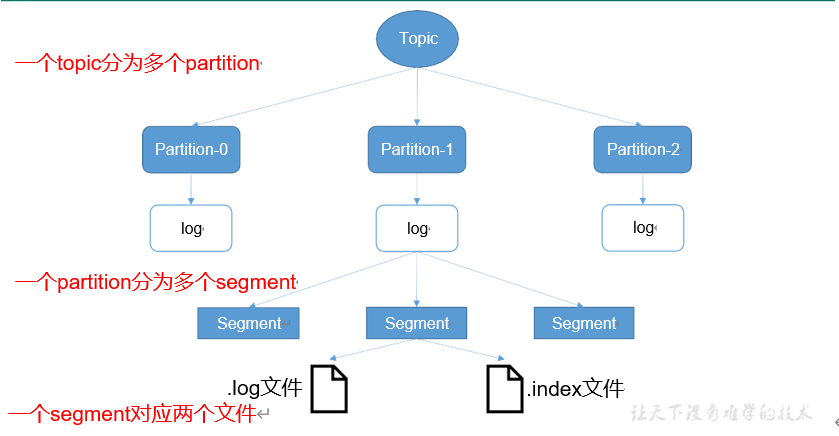
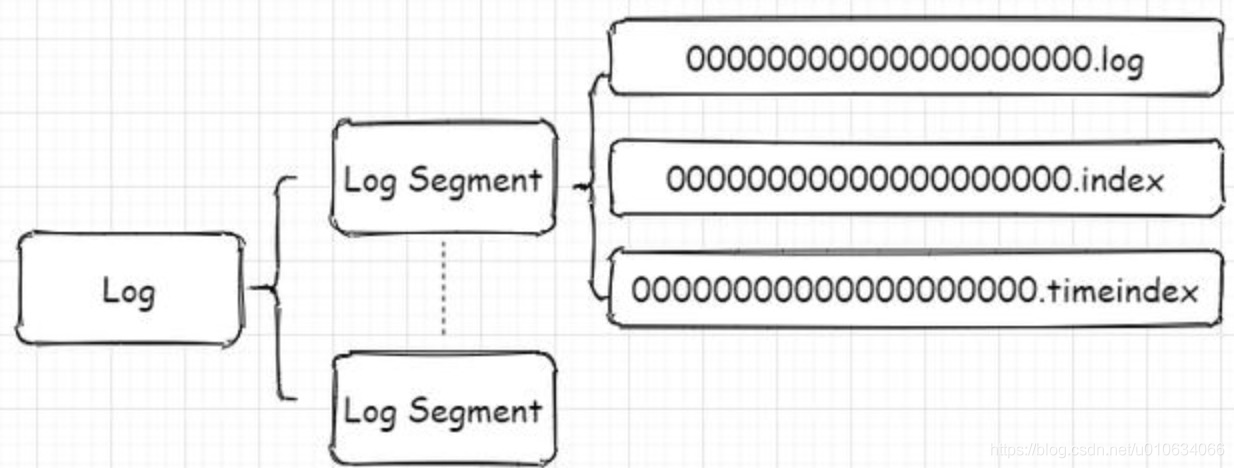
4.1 Kafka文件存储机制及索引机制
| 名称 | 描述 | 类型 | 默认 |
|---|---|---|---|
| log.segment.bytes | 单个日志文件的最大大小 | int | 1073741824 |
| log.index.interval.bytes | 添加一个条目到offset的间隔 | int | 4096 |
- .log 存储消息文件
- .index存储消息的索引
- .timeIndex,时间索引文件,通过时间戳做索引

从图中可以看到第一个segment文件00000000000000000000.log快要满log.segment.bytes的时候就开始创建了00000000000000005084.log了;
并且.log和.index、.timeindex文件是一起出现的; 并且名称是以文件第一个offset命名的
4.1.1 Kafka如何查找指定offset的Message
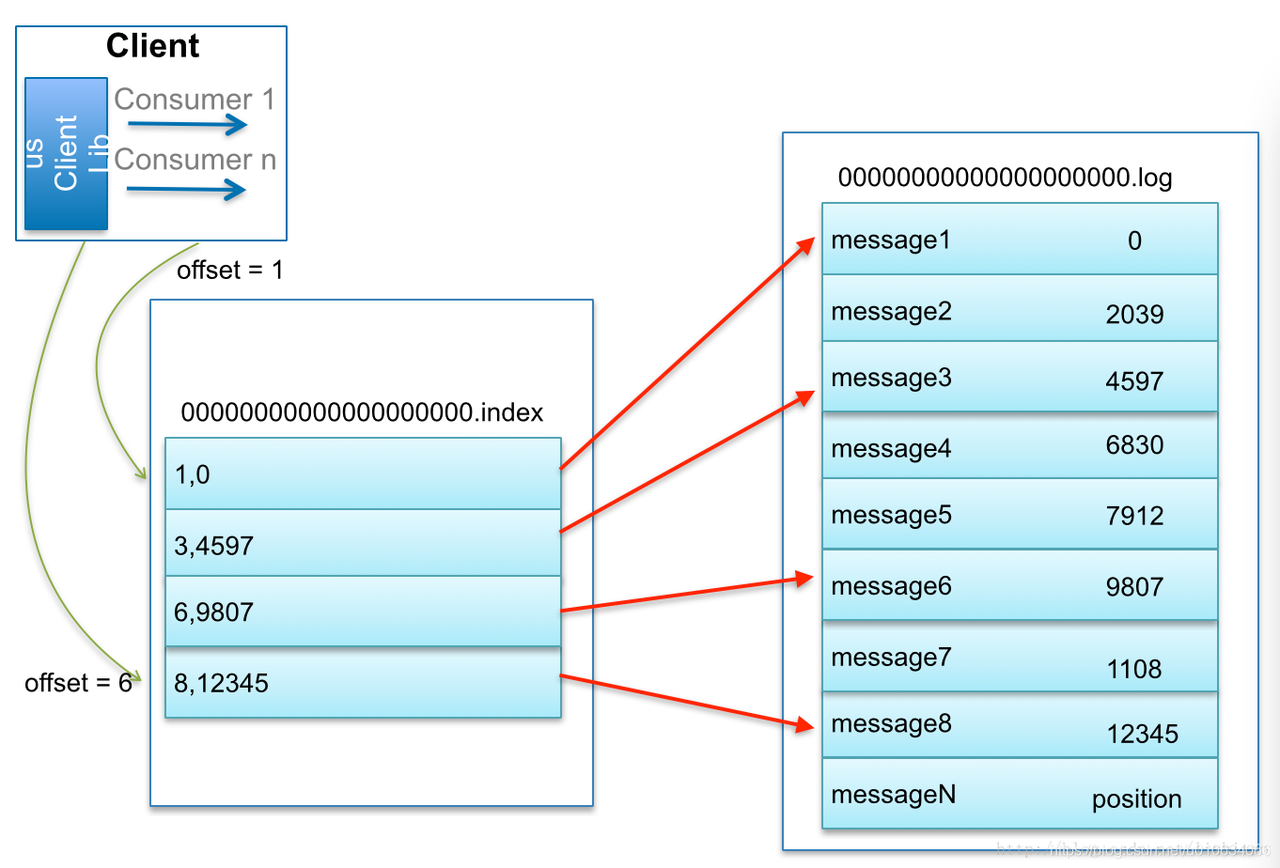
比如:要查找绝对offset为7的Message:
首先是用二分查找确定它是在哪个LogSegment中,自然是在第一个Segment中。
打开这个Segment的index文件,也是用二分查找找到offset小于或者等于指定offset的索引条目中最大的那个offset。自然offset为6的那个索引是我们要找的,通过索引文件我们知道offset为6的Message在数据文件中的位置为9807。
打开数据文件,从位置为9807的那个地方开始顺序扫描直到找到offset为7的那条Message。
Kafka 中的索引文件,以稀疏索引(sparse index)的方式构造消息的索引,它并不保证每个消息在索引文件中都有对应的索引项。每当写入一定量(由 broker 端参数 log.index.interval.bytes 指定,默认值为 4096,即 4KB)的消息时,偏移量索引文件 和 时间戳索引文件 分别增加一个偏移量索引项和时间戳索引项,增大或减小 log.index.interval.bytes 的值,对应地可以缩小或增加索引项的密度。
(4条消息) kafka数据可靠性深度解读_朱小厮的博客-CSDN博客
https://blog.csdn.net/lizhitao/article/details/39499283
5、Kafka选举机制
5.1 控制器(Broker)选举
1 第一个启动的broker在zookeeper中创建临时节点,成为控制器,其他broker在zookeeper中创建watch对象,接受通知。
所谓控制器就是一个Borker,在一个kafka集群中,有多个broker节点,但是它们之间需要选举出一个leader,其他的broker充当follower角色。集群中第一个启动的broker会通过在zookeeper中创建临时节点/controller来让自己成为控制器,其他broker启动时也会在zookeeper中创建临时节点,但是发现节点已经存在,所以它们会收到一个异常,意识到控制器已经存在,那么就会在zookeeper中创建watch对象,便于它们收到控制器变更的通知。
2.控制器异常,其他Broker竞争尝试创建临时节点,成功的将成为新的控制器。
如果控制器由于网络原因与zookeeper断开连接或者异常退出,那么其他broker通过watch收到控制器变更的通知,就会去尝试创建临时节点/controller,如果有一个broker创建成功,那么其他broker就会收到创建异常通知,也就意味着集群中已经有了控制器,其他broker只需创建watch对象即可。
broker异常退出后,该分区副本若存在leader,该分区需要一个新的leader。此时控制器就会去遍历其他副本,决定哪一个成为新的leader,同时更新分区的ISR集合。
broker加入集群,控制器就会通过Broker ID去判断新加入的broker中是否含有现有分区的副本,如果有,就会从分区副本中去同步数据。
5.2 分区副本选举机制
kafka集群,存在着多个topic,在每一个topic中,又被划分为多个partition,为了防止数据不丢失,每一个partition又有多个副本,在整个集群中,总共有两种副本角色:
1. 首领副本(leader):也就是leader主副本,每个分区都有一个首领副本,为了保证数据一致性,所有的生产者与消费者的请求都会经过该副本来处理。
创建分区时指定首选首领。如果不指定,则为分区的第一个副本。
2. 跟随者副本(follower):除了首领副本外的其他所有副本都是跟随者副本,跟随者副本不处理来自客户端的任何请求,只负责从首领副本同步数据,保证与首领保持一致。
如果首领副本发生崩溃,就会从这其中选举出一个leader。
Kafka 动态维护了一个同步状态的副本的集合(a set of in-sync replicas),简称ISR,在这个集合中的节点都是和leader保持高度一致的,任何一条消息必须被这个集合中的每个节点读取并追加到日志中了,才回通知外部这个消息已经被提交了。因此这个集合中的任何一个节点随时都可以被选为leader。ISR在 ZooKeeper 中维护。
如何选取出leader:谁写进去谁就是leader。
所有Follower都在Zookeeper上设置一个Watch,一旦Leader宕机,其对应的ephemeral znode会自动删除,此时所有Follower都尝试创建该节点,而创建成功者(Zookeeper保证只有一个能创建成功)即是新的Leader,其它Replica即为Follower。
6、Producer 生产者
生产者流程:消息的发送->序列化->分区器->生产者拦截器。
重点讲一下内容:
6.1 消息实体
ProducerRecord<K, V>private final String topic;//主题private final Integer partition;//分区号private final Headers headers;// 消息头部private final K key;//键private final V value;//值private final Long timestamp;
- Key 是用来指定消息的键,它不仅是消息的附加信息,还可以用来计算分区号进而可以让消息发往特定的分区。前面提及消息以主题为单位进行归类,而这个key 可以让消息再进行二次归类,同一个key 的消息会被划分到同一个分区中; 电商系统中 ,可以将订单号作为key ,根据相同的hash算法,将同一个订单号消息分到同一个分区内。
6.2 发送消息模式
| 发送即忘 | |
|---|---|
| 同步 | 结果future ,get()获取结果,阻塞线程直到拿到结果 |
| 异步 | 结果future |
public Future<RecordMetadata> send(ProducerRecord<K, V> record) {return this.send(record, (Callback) null);}RecordMetadata 中包含本次发送的消息 offset , 落与 哪个分区等信息;
6.3 发送消息分区逻辑
- 消息经过序列化之后就需要确定它发往的分区,如果消息ProducerRecord 中指定了 partition 字段, 那么就不需要分区器的作用,因为partition 代表的就是所要发往的分区号。如果消息ProducerRecord 中没有指定partition 字段,那么就需要依赖分区器, 根据key这个字段来计算partition 的值。
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {List<PartitionInfo> partitions = cluster.partitionsForTopic(topic);// 这个topic 所有的分区;int numPartitions = partitions.size();//所有分区的数量;// 如果ProducerRecord 中key 为null的话,则keyBytes 为null;if (keyBytes == null) {int nextValue = nextValue(topic);//选择所有可用的 分区;List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic);if (availablePartitions.size() > 0) {int part = Utils.toPositive(nextValue) % availablePartitions.size();return availablePartitions.get(part).partition();} else {// no partitions are available, give a non-available partitionreturn Utils.toPositive(nextValue) % numPartitions;// 在所有分区的范围内}} else {// hash the keyBytes to choose a partition// 电商业务中,相同的订单号 传 相同的 key 就可以做到 分到同一个分区内;return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; // 在所有分区的范围内}}// 对于每一个topic , 生产一个随机数, 然后放到map 中 之后都递增;private int nextValue(String topic) {AtomicInteger counter = topicCounterMap.get(topic);if (null == counter) {counter = new AtomicInteger(ThreadLocalRandom.current().nextInt());AtomicInteger currentCounter = topicCounterMap.putIfAbsent(topic, counter);if (currentCounter != null) {counter = currentCounter;}}return counter.getAndIncrement();}
6.4 ACK 参数
6.4.1 ack=1
leader 副本写入成功后给producer 返回响应;
默认为1
情景一:生产者可重新发送消息
如果消息无法写入leader副本中,比如在leader副本奔溃,重新选举新的leader副本的过程中。那么生产者就会收到一个错误的响应,为了避免消息丢失,生产者可以选择重新发送消息。
情景二:消费者没有同步,消息丢失
生产者发送消息之后,只要分区的leader 副本成功写入消息到本地log,那么服务端就会收到来自leader broker的成功响应。但是并没有等待所有follower是否成功写入。这种情况下,如果follower没有成功同步,那么就会出现消息丢失;
6.4.2 ack=0
追求吞吐量
生产者发送消息之后不需要等待任何broker的响应。如果在消息从发送到写入Kafka 的过程中出现某些异常,导致Kafka 并没有收到这条消息,那么生产者就无从得知,消息就丢失了。
6.4.3 ack=-1 或 ack=all
最稳妥:
生产者在消息发送之后,需要等待ISR中的所有副本都成功写入消息之后才能够收到来自broker的成功响应在其他配置环境相同的情况下,acks 的设置为-1 (all) 可以达到最强的可靠性。
存在的问题:
ack=all 并不意味着消息就一定可靠。因为ISR中可能只有leader副本,这样就退化成了ack = 1的情况。要获得更高的消息可靠性需要配合min.insync.replicas等参数的配合。
生产者线上配置
| 参数 | 配置内容 | 配置解释 |
|---|---|---|
| acks | all | |
| compression.type | none | 指定消息的压缩方式 |
| retries | 3 | leader 副本因选举,网络抖动等 临时性异常时 可重试解决。 |
| timeout.ms | 10000 | |
| reconnect.backoff.ms | 50 | |
| retry.backoff.ms | 200 | 设定2次重试之间的时间间隔。ms |
| batch.size | 10000 | 多个消息到同一个分区,生产者将消息打包处理。 |
| linger.ms | 1 | 指定生产者发送 ProducerBatch 之前等待更多消息(ProducerRecord)加入ProducerBatch 的时间,默认值为 0。 |
| max.request.size | 2097150 | 生产者客户端能发送的消息的最大值 ,2M |
batch.size 和 linger.ms 这两个条件 哪个先满足都会讲消息发送出去,基于高吞吐量和低延迟的平衡。
其他配置:
| max.in.flight.requests.per.connection(线上不会使用这个) | 该参数指定了生产者在收到服务器响应之前可以发送多少个消息。它的值越高,就会占用越多的内存,不过也会提升吞吐量。把它设为 1 可以保证消息是按照发送的顺序写入服务器的,即使发生了重试。 |
|---|---|
7、客户端
7.0 消费者和消费者组
每个消费者组之间相互隔离,每个消费者组下的所有消费者都可以消费 某topic 下全部消息。
7.1 Kafka 消费者分区分配策略
7.1.1 RangeAssignor 策略
对于每一个topic,RangeAssignor策略会将消费组内所有订阅这个topic的消费者按照名称的字典序排序,然后为每个消费者划分固定的分区范围,如果不够平均分配,那么字典序靠前的消费者会被多分配一个分区。
单个TOPIC维度:分区数 : partition消费者数:consumern=partition/consumer;m=partition % consumer;partition= consumer*n+m;m*(n+1) +(consumer-m)*n=m*n+m+consumer*n-m*n=m+consumer*n
7.1.2 RoundRobinAssignor
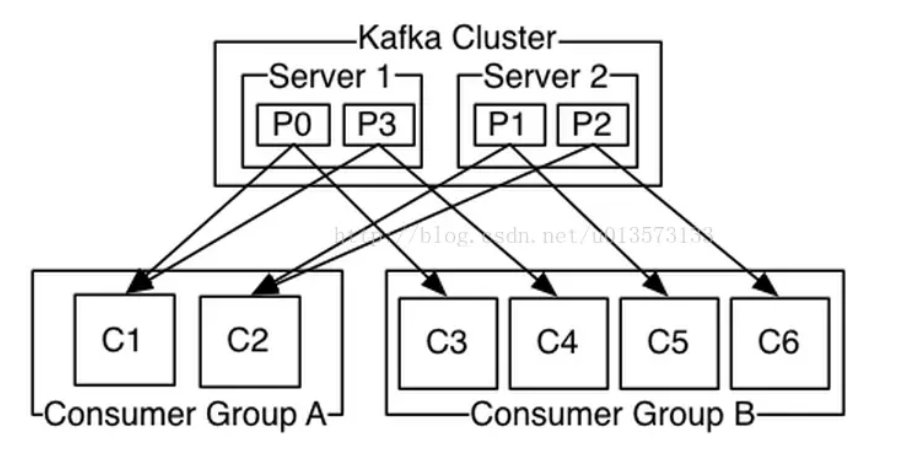
- partition中的每个message只能被组中的一个consumer消费;
- 发布-订阅模式可以使用不同的Consumer group来实现,新启动的consumer默认从partition队列最头端最新的地方开始读message。
- Consumer group去消费一个topic的时候,所有的consumer一定会消费全部的partition。
- Consumer Rebalance的触发条件:consumer增加或删除 ;订阅的 Topic 个数发生变化,订阅 Topic 的分区数发生变化。
Rebalance 发生时,Group下所有 consumer 实例都会协调在一起共同参与,kafka 能够保证尽量达到最公平的分配。但是 Rebalance 过程对 consumer group 会造成比较严重的影响。在 Rebalance 的过程中 consumer group 下的所有消费者实例都会停止工作,等待 Rebalance 过程完成。
5.consumer处理partition里面的message的时候是顺序读取的。通过offset维护处理消息的位置。
7.2 订阅主题
| 订阅方法 | 差异点 |
|---|---|
| subscribe(Collection |
订阅主题集合,维度:topic维度 |
| void assign(Collection |
订阅某些主题的特定分区 |
7.2 消费消息
ConsumerRecords<K, V> poll(final Duration timeout);ConsumerRecords<K, V> poll(final long timeoutMs);一个超时时间参数timeout,用来控制poll()方法的阻塞时间,在消费者的缓冲区里没有可用数据时会发生阻塞;这里不像producer 那样到一定时间或者存多少消息就会发送,消费者线程一单开启就会一直poll(),只是会判断对应分区内是否有待消费的消息,
7.3 位移提交
kafka offset:指的是 日志文件中消息的偏移量
consumer offset :记录的是最近拉取消息的位置,保证下次可以接着往下拉取新消息。
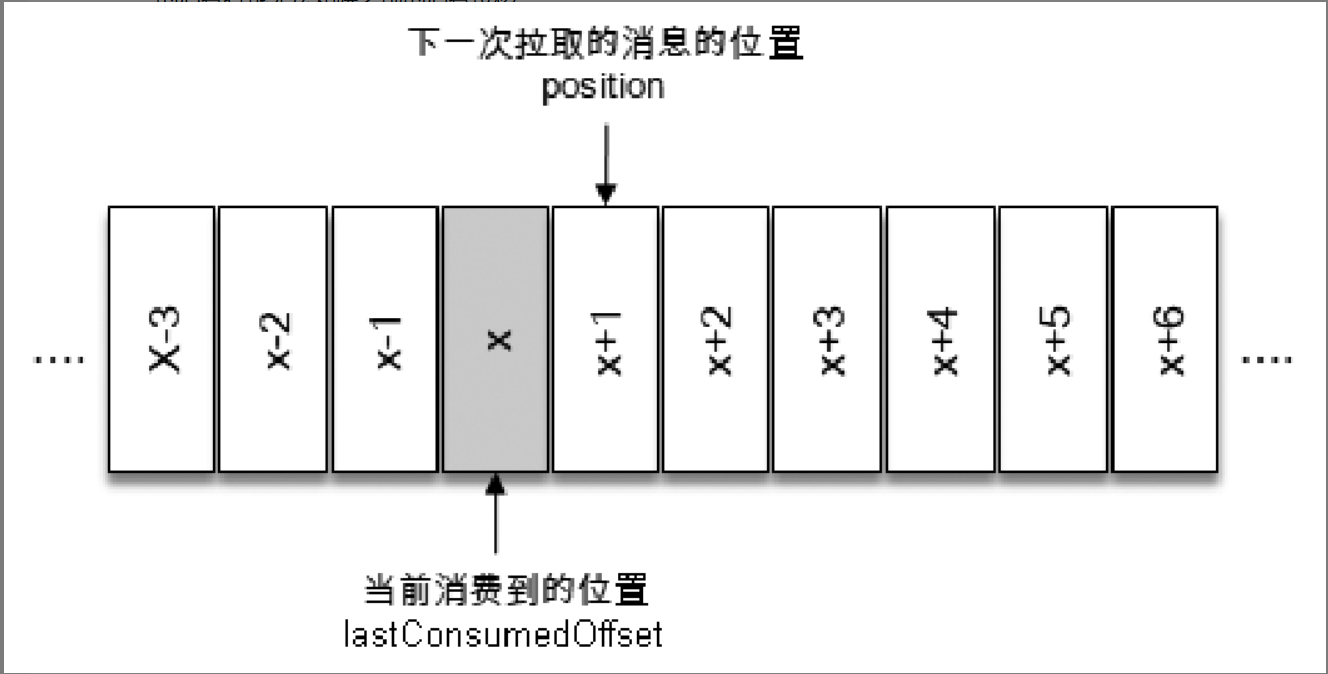
在旧消费者客户端中,消费位移是存储在ZooKeeper中的。而在新消费者客户端中,消费位移存储在Kafka内部的主题__consumer_offsets中。这里把将消费位移存储起来(持久化)的动作称为“提交”,消费者在消费完消息之后需要执行消费位移的提交。
可能出现的问题
1. 消息丢失:位移提交 先于 消费完成
拉取后 就提交,如果消费过程中出现异常,那么之前拉取的消息就会丢失,造成消息丢失。
2. 重复消费:先消费完成,后位移提交
本次poll 拉取到的是[X+2,X+7]区间的数据,如果在处理X+5的时候出现异常,故障恢复后,还是会从X+2的offset 拉取;此时就会出现[x+2,x+4] 之间的数据 重复消费。
7.4 再均衡
max.poll.interval.ms每次poll 间隔时间,每次poll()拉到的数据最好在这个间隔时间内处理完,原因如下:【1】broker 上的组管理GroupCoordinator 通过心跳检测 这个消费者是否还在线,而心跳信息只有在poll()被调用的时候发出,如果上次处理太慢,线程阻塞 导致超过阈值,组管理就会认为这个消费者已经消失并开始进行rebalance操作。合理设置2个参数:【1】max.poll.records:合理设置每次poll的消息消费数量,如果数量过多,导致一次poll操作返回的消息记录无法在指定时间内完成就会rebalance【2】max.poll.interval.ms:尽力保证一次poll的消息能够很快完成
8、Partition和消费者对应关系
- 消费者多于partition
同一个partition内的消息只能被同一个组中的一个consumer消费。当消费者数量多于partition的数量时,多余的消费者空闲。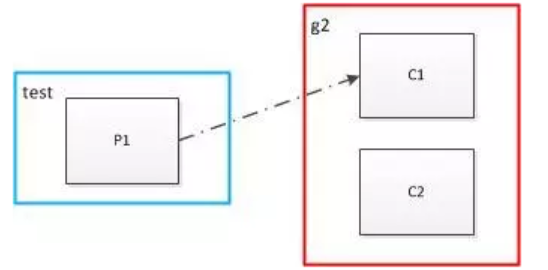
- 消费者少于和等于partition,消息在同一个组之间的消费者之间均分。
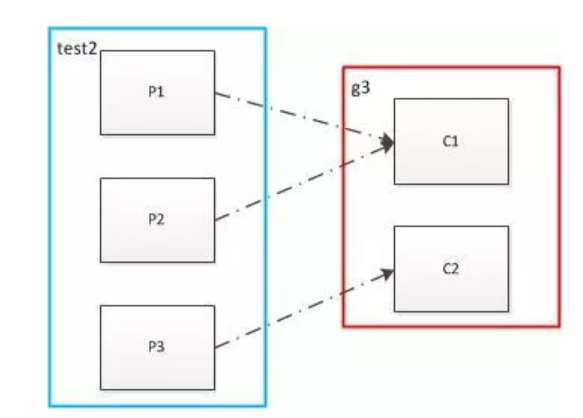
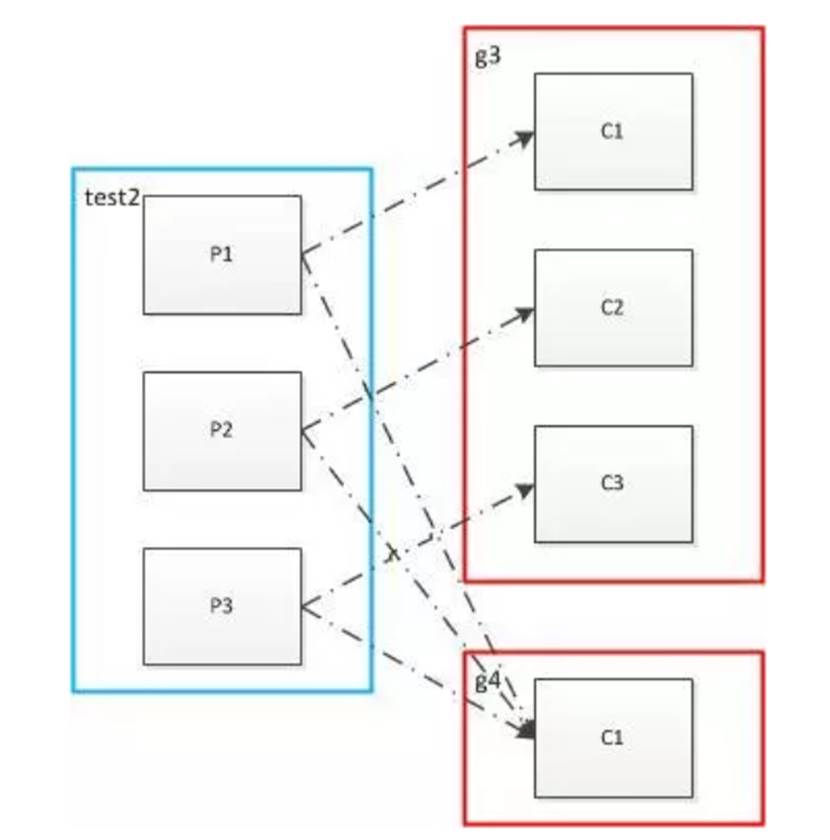
- 多个消费者组,每个消费者组会均分所有的partition,同一个消息被消费多次。
9、offset管理
offset记录着下一条将要发送给Consumer的消息的序号。
一个partition只能固定的交给一个消费者组中的一个消费者消费,因此Kafka保存offset时并不直接为每个消费者保存,而是以groupid-topic-partition -> offset的方式保存。如图所示: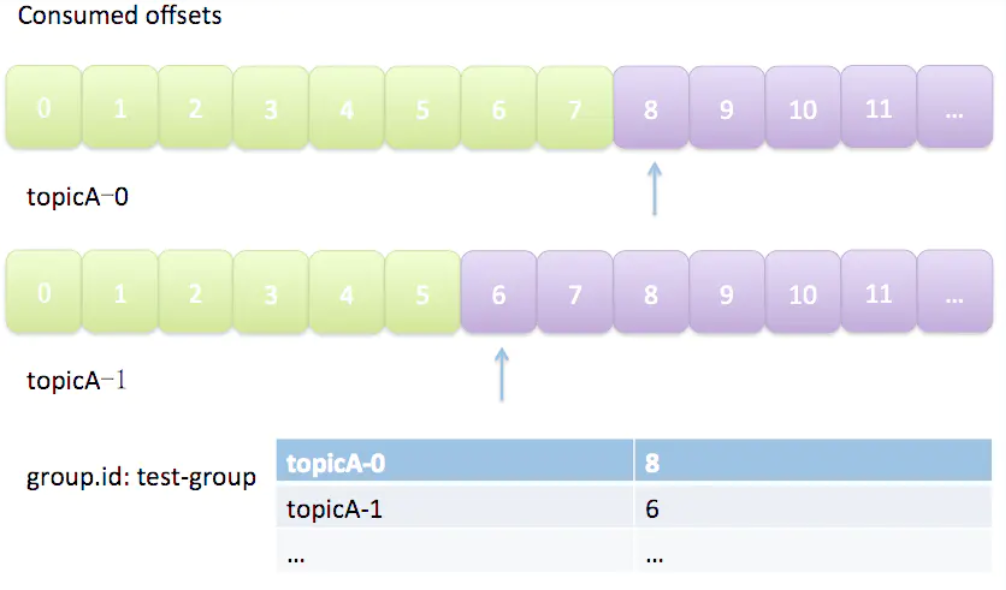
Kafka在保存Offset的时候,实际上是将Consumer Group和partition对应的offset以消息的方式保存在__consumers_offsets这个topic中。
auto.offset.reset参数
- earliest:
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费。
- latest:
当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据。
- none:
topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常。
https://blog.csdn.net/lizhitao/article/details/39499283
Producer和Consumer之间的消息传递保证三种语义:
- At most once:消息可能会丢,但绝不会重复传递;
- At least once:消息绝不会丢,但可能会重复传递;
-
Producer消息传递语义
At least once
当producer向broker发送消息时,一旦这条消息被commit,由于副本机制的存在,它就不会丢失。但是如果producer发送数据给broker后,遇到的网络问题而造成通信中断,那producer就无法判断该条消息是否已经提交。
如果一个Producer没有收到消息提交的响应,它只能重新发送消息,确保消息已经正确传输到broker中,这提供了at-least-once传递语义,因为如果原来的请求实际上成功了,则在重新发送时将再次把消息写入到日志中。
Exactly once
Producer支持幂等传递选项,保证重新发送不会导致在日志中出现重复项。为了实现这个目的,broker为每个Producer分配一个ID,并通过每个消息的序列号来进行去重。
启用幂等传递的方法是配置enable.idempotence=true。
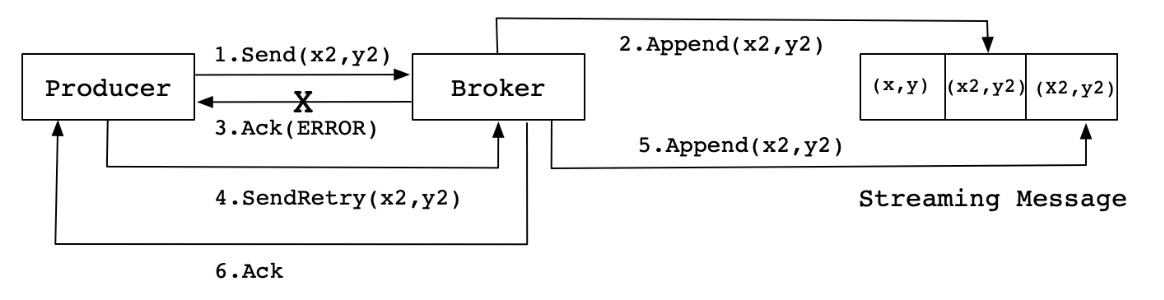
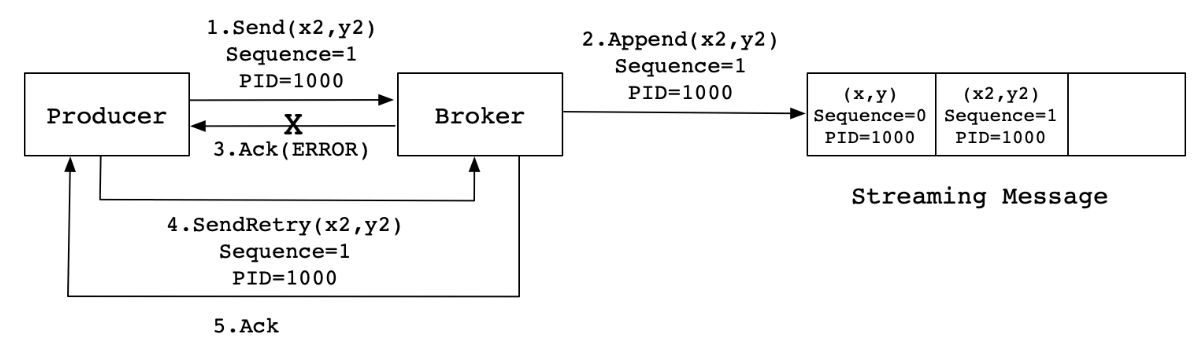
当Producer发送消息(x2,y2)给Broker时,Broker接收到消息并将其追加到消息流中。此时,Broker返回Ack信号给Producer时,发生异常导致Producer接收Ack信号失败。对于Producer来说,会触发重试机制,将消息(x2,y2)再次发送,但是,由于引入了幂等性,在每条消息中附带了PID(ProducerID)和SequenceNumber。相同的PID和SequenceNumber发送给Broker,而之前Broker缓存过之前发送的相同的消息,那么在消息流中的消息就只有一条(x2,y2),不会出现重复发送的情况。
并不是所有的场景都需要这么强的保证,对于延迟敏感的情况,Producer可以通过request.required.acks参数指定它期望的持久性级别。如Producer指定它想要等待消息的committed,则这可能需要10毫秒量级的延迟。然而,Producer也可以指定它想要完全异步地执行发送,或者它只等到leader(不需要副本的响应)的响应。Consumer的offset记录方式
At most once:消费者fetch消息,然后保存offset,然后处理消息。
当client保存offset之后,但是在消息处理过程中consumer进程失效(crash),导致部分消息未能继续处理。那么此后可能其他consumer会接管,但是因为offset已经提前保存,那么新的consumer将不能fetch到offset之前的消息(尽管它们尚没有被处理),这就是”at most once”。
At least once:消费者fetch消息,然后处理消息,然后保存offset。
如果消息处理成功之后,但是在保存offset阶段zookeeper异常或者consumer失效,导致保存offset操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是”at least once”。
如果一定要做到Exactly once,就需要协调offset和实际操作的输出。经典的做法是引入两阶段提交。也可以更简单一些,通过让Consumer将其offset存储在与其输出相同的位置。11、提交offset的方式
自动提交offset
enable.auto.commit设置为true,可以启用自动提交,auto.commit.interval.ms则设置了自动提交的时间间隔。自动提交是由轮询循环驱动的。当轮询时,Consumer检查是否提交,如果是的话,它将提交上次轮询中返回的偏移量。
- 手动提交offset
commitSync() 同步提交;commitAsync() 异步提交。
总之,kafka默认保证 At least once,并且允许通过设置producer异步提交来实现At most once。
12、 Kafka消费消息时的幂等性
幂等性:消费者对接口的多次调用所产生的结果和调用一次是是一致的,也就是说在kafka中有可能会消费到重复的数据,这个时候需要客户端去处理这种情况,使得消息消费一次和消费多次是一样的结果。
当消费者消费到了重复的数据的时候,消费者需要去过滤这部分的数据。主要有以下两种思路:
1.将消息的offset存在消费者应用中或者第三方存储的地方,可以将这个数据存放在redis或者是内存中,消费消息时,如果有这条数据的话,就不会去做后续操作。
2. 根据消费者处理的业务选择合适的规则:比如数据要写库,你先根据主键查一下,如果这数据都有了,选择更新。
引用
https://blog.csdn.net/lizhitao/article/details/39499283
https://honeypps.com/categories/%E6%B6%88%E6%81%AF%E9%98%9F%E5%88%97/Kafka/
https://mp.weixin.qq.com/s/gE54m3HxiWS3-mjNH8f8_w
源码分析:http://matt33.com/tags/kafka/
https://blog.csdn.net/wsdc0521/article/details/108604420
http://thesecretlivesofdata.com/raft/
动画演示: https://softwaremill.com/kafka-visualisation/
https://blog.csdn.net/a308601801/article/details/88642985
https://blog.csdn.net/u013256816/article/details/71091774
面试题:https://hiddenpps.blog.csdn.net/article/details/88550812
时间轮:http://www.codebaobao.cn/article/1602642269

若有收获,就点个赞吧
0 人点赞
