explain 执行计划详解

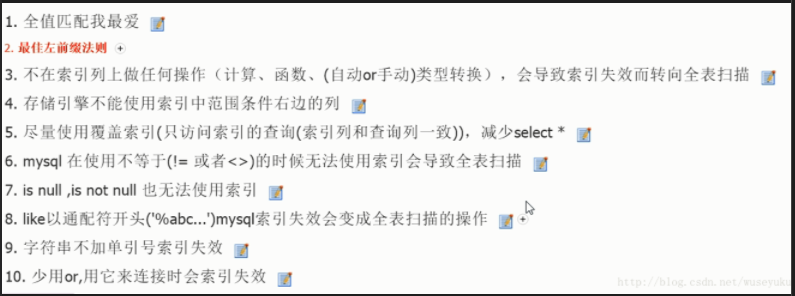
1.id
2.select_type
查询的类型,主要是区别普通查询和联合查询、子查询之类的复杂查询
[1]SIMPLE:查询中不包含子查询或者UNION[2]查询中若包含任何复杂的子部分,最外层查询则被标记为:PRIMARY[3]在SELECT或WHERE列表中包含了子查询,该子查询被标记为:SUBQUERY
3. table
4. type
访问类型
从左至右,性能由差到好;[1]ALL: 扫描全表[2]index: 扫描全部索引树[3]range: 扫描部分索引,索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行,常见于between、<、>等的查询[4]ref: 使用非唯一索引或非唯一索引前缀进行的查找(eq_ref和const的区别)[5]eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描[6]const, system: 单表中最多有一个匹配行,查询起来非常迅速,例如根据主键或唯一索引查询。system是const类型的特例,当查询的表只有一行的情况下, 使用system。[7]NULL: 不用访问表或者索引,直接就能得到结果;如select 1 from test where 1
5. possible_keys
possible_keys: 表示查询时可能使用的索引。如果是空的,没有相关的索引。这时要提高性能,可通过检验WHERE子句,看是否引用某些字段,或者检查字段不是适合索引
6.key:
显示MySQL实际决定使用的索引。如果没有索引被选择,是NULL
7.key_len
使用到索引字段的长度
注:key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
8. ref:
9.rows
这个数表示mysql要遍历多少数据才能找到,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数,在innodb上可能是不准确的
10. Extra
执行情况的说明和描述。包含不适合在其他列中显示但十分重要的额外信息。
| Using where | 表示优化器需要通过索引回表查询数据 |
|---|---|
| Using index | 表示直接访问索引就足够获取到所需要的数据,不需要通过索引回表; |
| Using index condition |
create table student(id bigint auto_incrementprimary key,name varchar(256) not null,age int not null,type tinyint not null,vendor_id bigint not null,created datetime null);create index idx_type_date_vendoron student (vendor_id, type, created);
explain select * from student where vendor_id=1 and created>='2021-05-11';执行计划如下:

ICP 索引下推技术
简单地说:之前 需要在server 端进行where 最后的筛选。
ICP将这个部分放到了存储引擎中筛选,然后直接返回数据。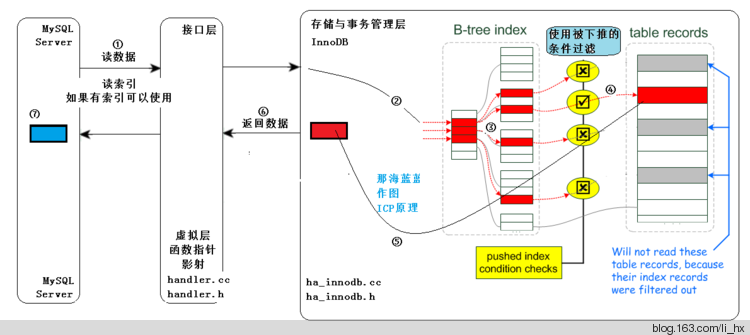
过程解释:
①:MySQL Server发出读取数据的命令,过程同图一。
②、③:进入存储引擎,读取索引树,在索引树上查找,把满足已经下推的条件的(经过查找,红色的满足)从表记录中读出(步骤④,通常有IO),从存储引擎返回⑤标识的结果。此处,不仅要在索引行进行索引读取(通常是内存中,速度快。步骤③),还要在③这个阶段依据下推的条件进行进行判断,不满足条件的,不去读取表中的数据,直接在索引树上进行下一个索引项的判断,直到有满足条件的,才进行步骤④,这样,较没有ICP的方式,IO量减少。
⑥:从存储引擎返回查找到的少量元组给MySQL Server,MySQL Server在⑦得到少量的元组。因此比较图一无ICP的方式,返回给MySQL Server层的即是少量的、符合条件的元组。
另外,图中的部件层次关系,不再进行解释。
引用

若有收获,就点个赞吧
0 人点赞
