牛逼的Hinton大神不仅仅将反向传播引入了神经网络,使得大规模的训练神经网络成为可能,而现在他又提出了一个新的基础结构Capsule,听上去很厉害,但是我们坐以待毙,要站在科技的最前沿去掌握这些新的知识。今天我们就来理解一下这个Capsule到底是什么鬼,有和牛逼之处,以及它和CNN的关系,又该如何去实现它?论文地址传送门
Capsule基础
Hinton在他的论文里面,把论文的题目叫做 Dynamic Routing Between Capsules. 那么很显然,首先理解一下为毛叫Routing?这个题目总字面意思理解像是一种动态的算法,在Capsule中游离,具体是怎么一种方法我们继续看了。其实论文摘要的第一句话就说的是什么是Capsule:
A capsule is a group of neurons whose activity vector represents the instantiation parameters of a specific type of entity such as an object or object part.
一个胶囊,就是一组神经元,它的特征向量就是代表一个实体或者物体的实例化参数。简而言之,一个胶囊现在是一组神经元了,而不是一个或者一层神经元。一组这个概念非常重要,比如我们将好几层放到一组里面组成一个胶囊,Capsule也是顾名思义。那么这么一个胶囊,它的参数就是一个对象或者物体的实例化参数,比如就是一张图片中一个物体的特征。
用活动向量的长度来代表实例化物体存在的概率,用活动向量的方位来代表。较低层次的胶囊为较高抽象层次的胶囊做预测,当较低层次的多个胶囊对某个预测都表示同意时,高层次的抽象胶囊就将被激活。
Hinton在引入Capsule概念时提到,人类视觉使用了一种确定的固定点序列来忽略不相关的细节,以确保只有极少数部分的光学阵列以最高分辨率被处理。这什么意思呢?就是说,人类的视觉会忽略东西,比如你看远处的一座塔,那么它附近的树木,人就无法看清,人类只能同时聚焦于同一个物体,使得这个物体被以强所未有的分辨率被聚焦。这其实我们已经研究过了,CNN的基本不就是一个聚焦的卷积核对图片进行扫描吗?那么这个新的“CNN”又有何不同呢?接着,作者提出了一个非常犀利的观点,那就是Parse Tree,暂且把它叫做解析树。作者把人类的视觉比较是一个解析树。Parse Tree是一个由神经网络雕刻出来的雕刻品,就像是一个雕塑出自于石头一样,这么一说非常清晰,Parse Tree本质还是神经网络,但是他只是把神经网络当成是原料,而不是直接把神经网络拿来用。这个Parse Tree也是一层层的,而且每一层不再是单一的神经元,而是每一层有许多个胶囊组成,每个胶囊由若干个神经元组成。意思就是Parse Tree使得神经网络更加高级了,并产生了一个以胶囊为单位的层次结构。在解析树的每一层当中,每一个胶囊都会选择更上一层的胶囊作为它的父胶囊,此时父胶囊就会激活。
每个活动胶囊内部的神经网络参数表征了图片当中出现的物体的尺寸,形状,姿态等,甚至包括速度,文本信息都会包含,其中一个非常特别的信息是这个胶囊中是否包含该物体存在的信息,而一个表征是否存在的办法就是在这个胶囊后面接一个分类器输出0和1. 但是在这篇论文作者提出了一个更加牛逼的方式来表征胶囊里面是否存在一个物体的实例化信息,那就是通过胶囊的长度来判别,并且规定胶囊输出的特征长度不能超过1。一个胶囊输出是一个向量,这个天然特性非常好,他可以使得一个胶囊的输出可以被送到它更上层的胶囊中去。刚开始的时候, 一个胶囊的输出被送到所有可能的高层次胶囊中,但是由于总和限定在1,所以被逐渐递减,胶囊会有一个预测向量,乘上一个权重矩阵,如果预测向量与高层次的胶囊输出相乘得到的标量较大,那么就增加了这个胶囊将信息传递给这个高层次胶囊的概率。这种利用底层胶囊和高层胶囊协同合作的方式使得这种办法比简单的maxpooling要有效得多,Hinton等大神也说自己证明了这一点,这个机智在物体分割和检测重叠物体上具有效果。
说到了这里,是该对比一下基于胶囊机制的视觉系统和CNN的区别了。首先有:
| CNN | Capsule |
|---|---|
| scalar output of feature detector | vector ouput of Capsules |
| max pool | routing-by-agreement |
一眼就能看出,新的体系相对于CNN来说,CNN和Capsule的体系架构的区别就像小学数学和微积分,cnn中的max-pooling会很显然会丢失信息,而用routing-by-agreement的方式来处理,图像中物体的位置信息就被选择哪个高层次胶囊所取代了。其实说白了,Capsule架构是把神经网络和决策树结合起来,只不过和决策树决策的方式不一样。
那么问题来了,Capsule的输入和输出怎么计算呢?
论文中只是说明了一种非常简单的实现方法,那就是挤压函数,这个挤压函数的作用就是把一个低长度的向量的长度压缩到几乎为0,把一个很长长度的向量压缩到一个小于1的值(execuse me?长度还能小于1???这里说的length值得应该是二范数的长度),这个公式很显然就是将一个向量归一化了:
| vj = ||sj||^2 / (1 + ||sj||^2) * sj / ||sj|| |
|---|
这就是一个Capsule的公式,输入是sj,输出是vj,非常清晰简单明了。
除了第一层的Capsule之外,其他每一层的输入sj是下一层Capsule的输出乘以一个矩阵,在乘上一个耦合概率:
简单的Capsule算法如下:
| procedure ROUTING(uˆj|i, r, l) for all capsule i in layer l and capsule j in layer (l + 1): bij ← 0. for r iterations do for all capsule i in layer l: ci ← softmax(bi) for all capsule j in layer (l + 1): sj ← i cij uˆj|i for all capsule j in layer (l + 1): vj ← squash(sj ) for all capsule i in layer l and capsule j in layer (l + 1): bij ← bij + uˆj|i.vj return vj |
|---|
CapsNet的网络结构
Hinton在论文中也提出了CapsNet一个最简单的结构,我们直接看一下图形结构: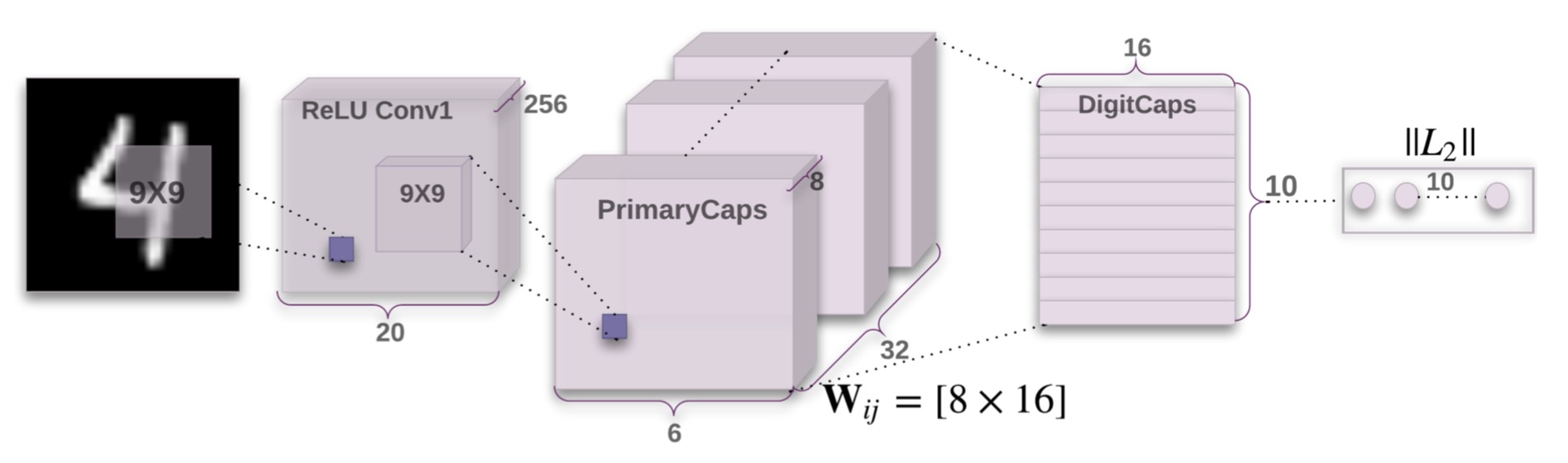
一看这个结构感觉跟想象的不太一样啊,说好的胶囊结构呢?这个primary caps就是一个胶囊了吧,那么这个就是3个层次的胶囊?还是说三个初级的胶囊?不是非常清晰啊。不过可以这么来理解,首先primary caps是首要的初级胶囊,这些胶囊就是最底层的胶囊了,每个初级胶囊里面都是一些卷积层组成的网络,比如每个caps里面都是一个lenet,然后每个primary capsules都与更高层次的抽象capsule组成一个激活与被激活的关系,最后抽象出来的capsule就是图中的DigitCaps。这些高层次的Caps不仅仅可以用来分类,直接计算输出的向量的二范数即可,而且还可以用来重构.
这是一个非常有趣的事情,也就是说这里的DigitsCaps已经足够高级了,高级到什么地步,我们可以直接用这个东西来做GAN生成!!!Hinton在论文里面也说了,直接一个decoder就可以用这个来生成相应的数字: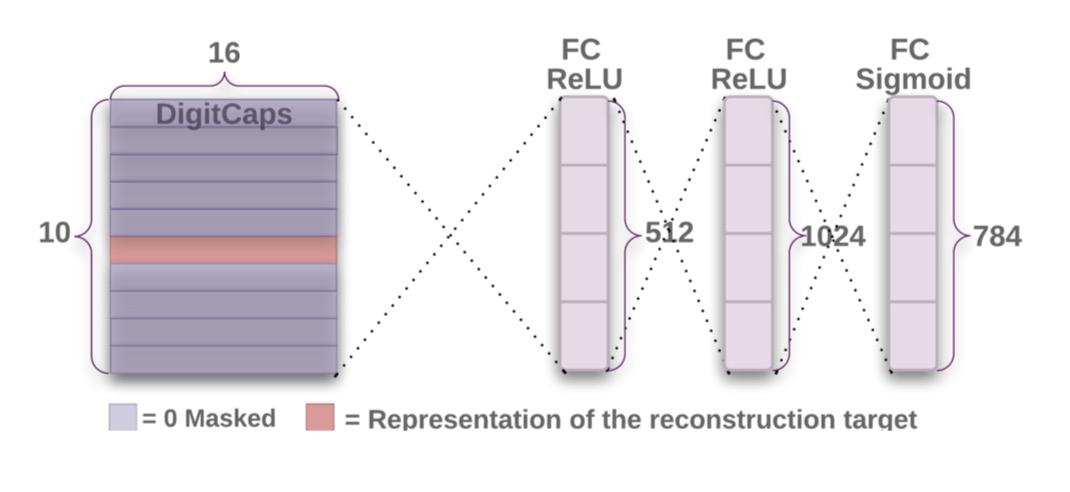
这是一个decoder,直接对DigitCaps进行重构,就得到了一个784维的原始mnist图片。
我们对CapsNet的原始论文的了解大概就是如此,但是我想现在你一定跟现在我一样懵逼。传说中非常牛逼吊炸天的CapsNet好像我依旧不知道它是什么来的,要实现什么功能?解决什么问题?怎么解决的?以及它计算的一些细节。别急,我们再来仔细分析一下。
CapsNet探究
简单来说,Hinton提出这个CapsNet是要解决这么一个问题:传统CNN在对图片信息提取的信息遗漏问题和深度学习模型对物体形状记忆的问题。为什么CNN会有这样的问题呢?有人仔细想过为什么我们要用maxpooling这么简单粗暴的东西吗?我们对特征进行一层层的抽象,有很多种办法,为什么一定要直接略过一些东西呢?我们在做检测和分割任务的时候,有人仔细想过为什么一个检测网络总是必须要借助人类的标签才能把物体框柱,而且框的还不准确吗(比如重叠物体)?这些都是目前CNN基石上所存在的问题。
而CapsNet的设计先天有着很好的优点:
通过一个个的胶囊来代替简单的一层CNN,这个非常好理解,现在要是提出一个胶囊网络,它的一层不是多少个神经元,而是多少个胶囊,每个胶囊可能有很多层CNN或者很多个神经元,毫无疑问,这个模型就要复杂很多了。
CapsNet不在使用拍脑袋决定的max-pooling这样的简单粗暴方式来处理特征的抽象或者说抽取,而是采用底层与高层之间的激活与被激活的关系来表征这一关系,比如我在底层有个胶囊A,它抽取了一个车的特征,它就激活它高层的一个胶囊,那么这个胶囊就在底层的基础上进行了一次抽象,至于这个抽象怎么去理解,就当时对图像进行了一次特征抽取吧。
由于CapsNet本身一个胶囊就被设计来发现一个物体,那么这个物体检测出来的特征自然就包含这个物体的类别,这个物体的形状等信息,这一想法在重构的实验中也得到了非常好的验证,底层识别1的胶囊,可以很好的复现1的图形。
正是基于此架构上的改进,未来,可能在做分割或者检测任务时,我们就不需要进行人工标注了,CapsNet可以通过简单的类别标注就可以知道什么地方有什么东西,而且这个检测可以做到非常准备。
从这个角度上来说,说大一些,CapsNet统一了CV里面的分类、检测、分割所有的任务,至于它是不是像设想的一样真的非常work,我想在未来的全球AI研究员的实现里面,肯定会很多人使用Caps对深度学习网络进行重构,无数实验结果或许会给我们带来非常惊喜的成果!

若有收获,就点个赞吧
0 人点赞
