视频笔记
- 启发:
- 是一种机器学习方式,简单的可以先搞WordEmbedding,然后再搞GraphEmbeding。
- 用在源代码检测领域可以识别代码相似。
- 用在流量检测领域可以识别恶意行为。
- 用在风险控制领域,可以识别僵尸网络和机器行为(如暴力破解)。
- 重点依然看如何建模和使用数学公式表达。
- 是一种机器学习方式,简单的可以先搞WordEmbedding,然后再搞GraphEmbeding。
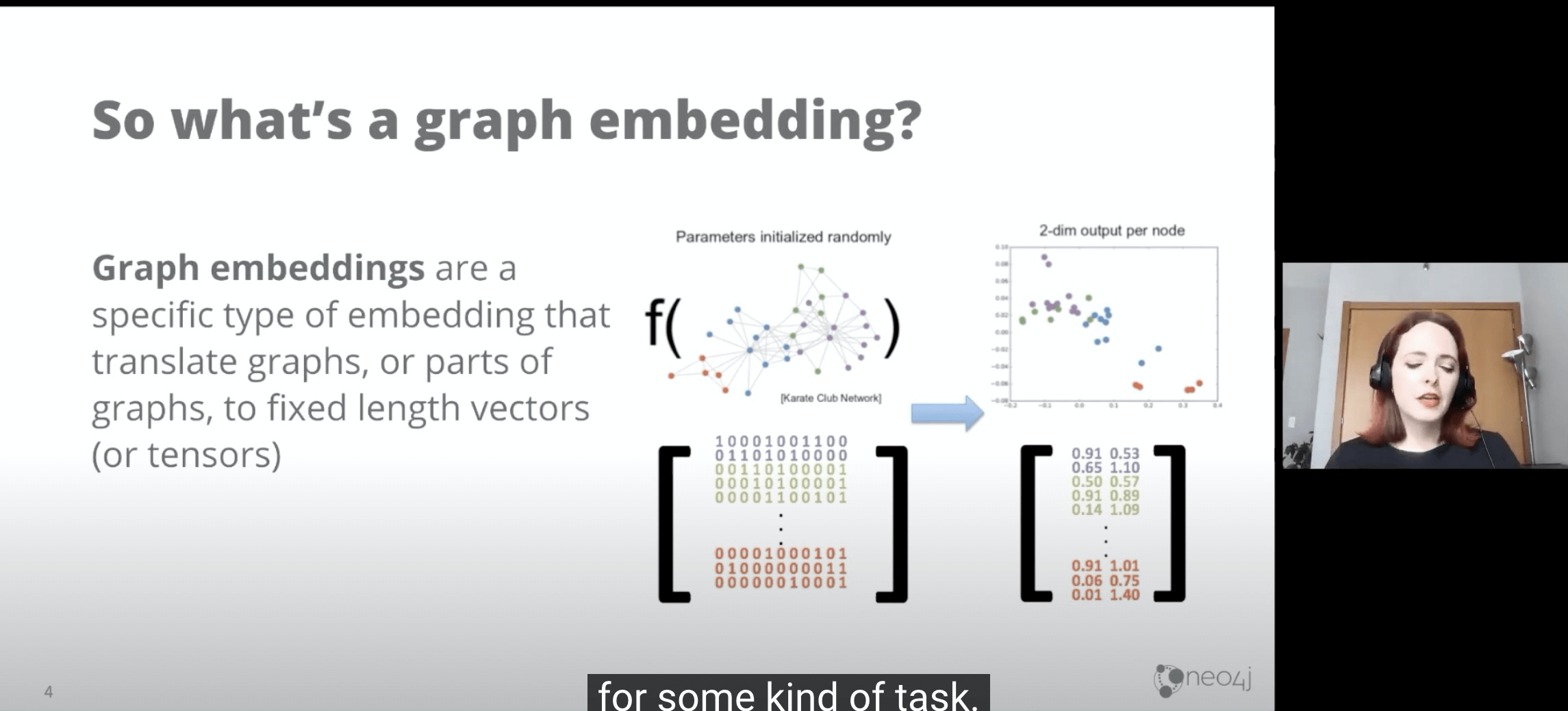
- Graph Embedding 是一种降低维度的方法,可以把一张图矩阵降成若干x元节点(如二元节点)

- GraphEmbedding可以用于:
- 表达图中复杂多维到低维表达。
- 降低后的低维表达可以用于机器学习或者深度学习,再进一步产出结果。
- GraphEmbedding,通常是非监督式的,通用方式.

- 应用例子:
- 2个单词有多相似?
- 我如何把一个单词表达到模型中?
- 简单的办法
- 2个字符串有多相似?
- 人工编码表达字符;
- 用2^x维度,表达<2^x个字符;
- 2个字符串有多相似?

- TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
- TF:词频矩阵(某个词在单篇文章中出现次数)
- IDF:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。

- 但是上面例子中忽略了单词出现的顺序,因此我们可以看单词和单词放一起时,他们可能表达一样信息。
- 用词袋方法(2个一组)

- 然后会得到一个稀疏矩阵.
- 因此我们需要给它降个维度.

- 需要拆分表格,降低维度,又要准确表达关系 ,准确,以及已知方法。

- 预测方法:源文件 + 训练样例
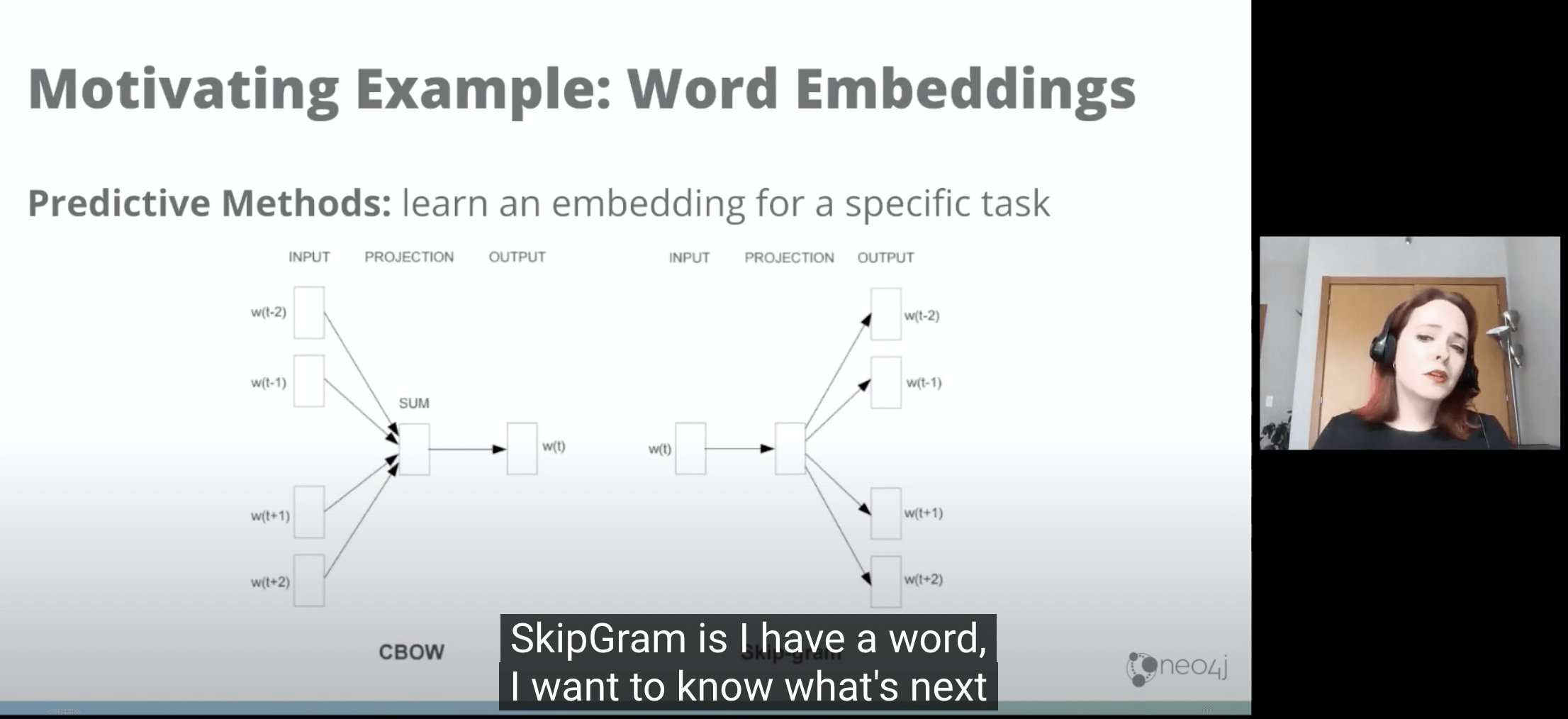
- 生成一个嵌入图(SkipGram方式:我有一个文字,我要猜测下一个很可能是啥)
- 很多Embedding都是用SkipGram的,因为它效果比较好。

- 继续延伸下去,我们就是讲的就是word2vec了,这个模型背后就是重点依赖SkipGram的。
- SKipGram可以用来表达每一个单词的特征,根据一个词预测下一个词。
- 以上图为例就构成了一个神经网络。你听起来以为这个很有用,但是实际上很可能很垃圾。

- 在这里Output Prediction其实没屌用的垃圾,我们想要的是训练用的Hidden Layer。

- 训练层用的Hidden Layer有很多中间结果。
- 就像上面,你可以用余弦相似度来计算距离。

- 上面讲的是Word Embedding的故事,下面继续讲GraphEmbedding,就很容易理解了。
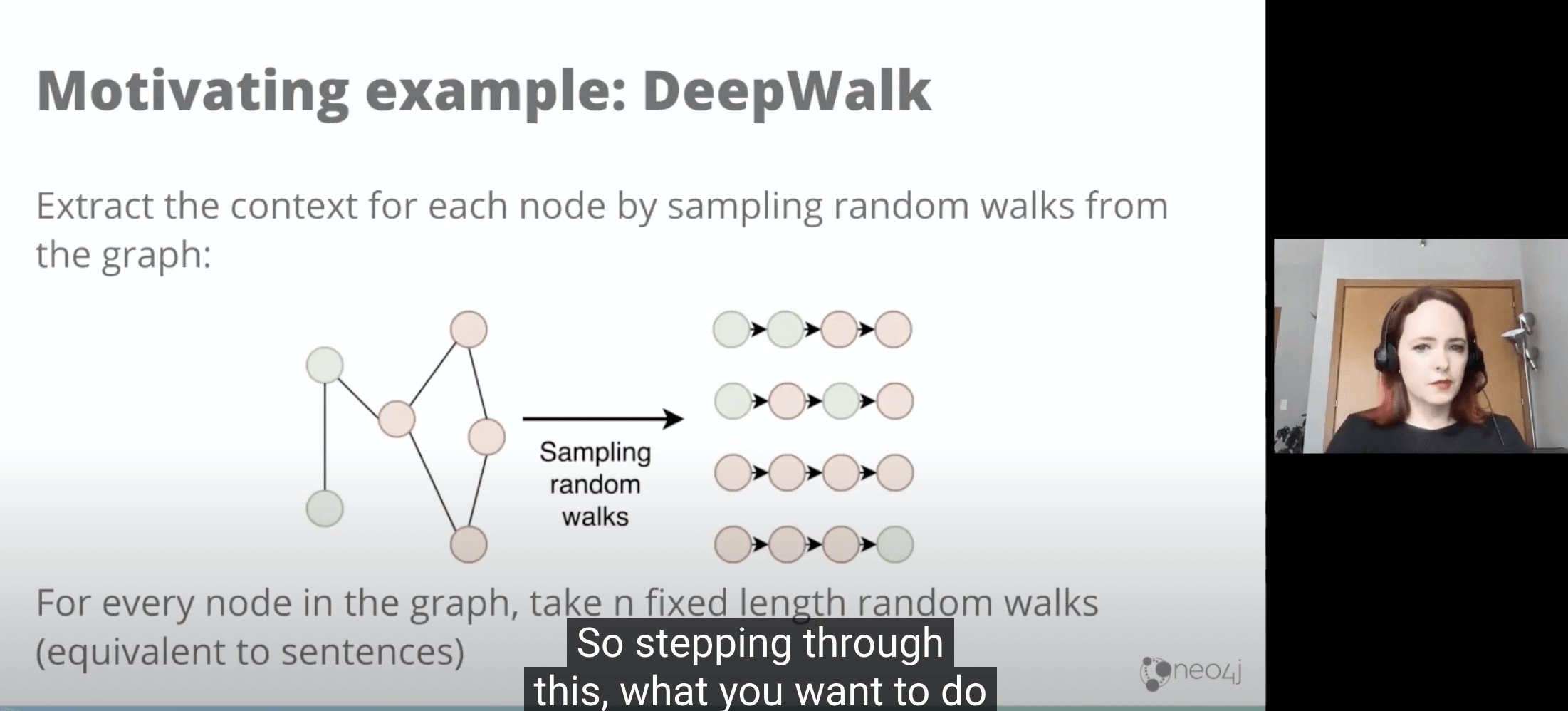
- DeepWalk用的技术其实就是类似WordEmbedding背后技术。我们假设每个节点都可以随机游走到下一个,那么游走X次,就可以变成X个行为序列,进而就变成了和wordEmbedding时很像的问题。
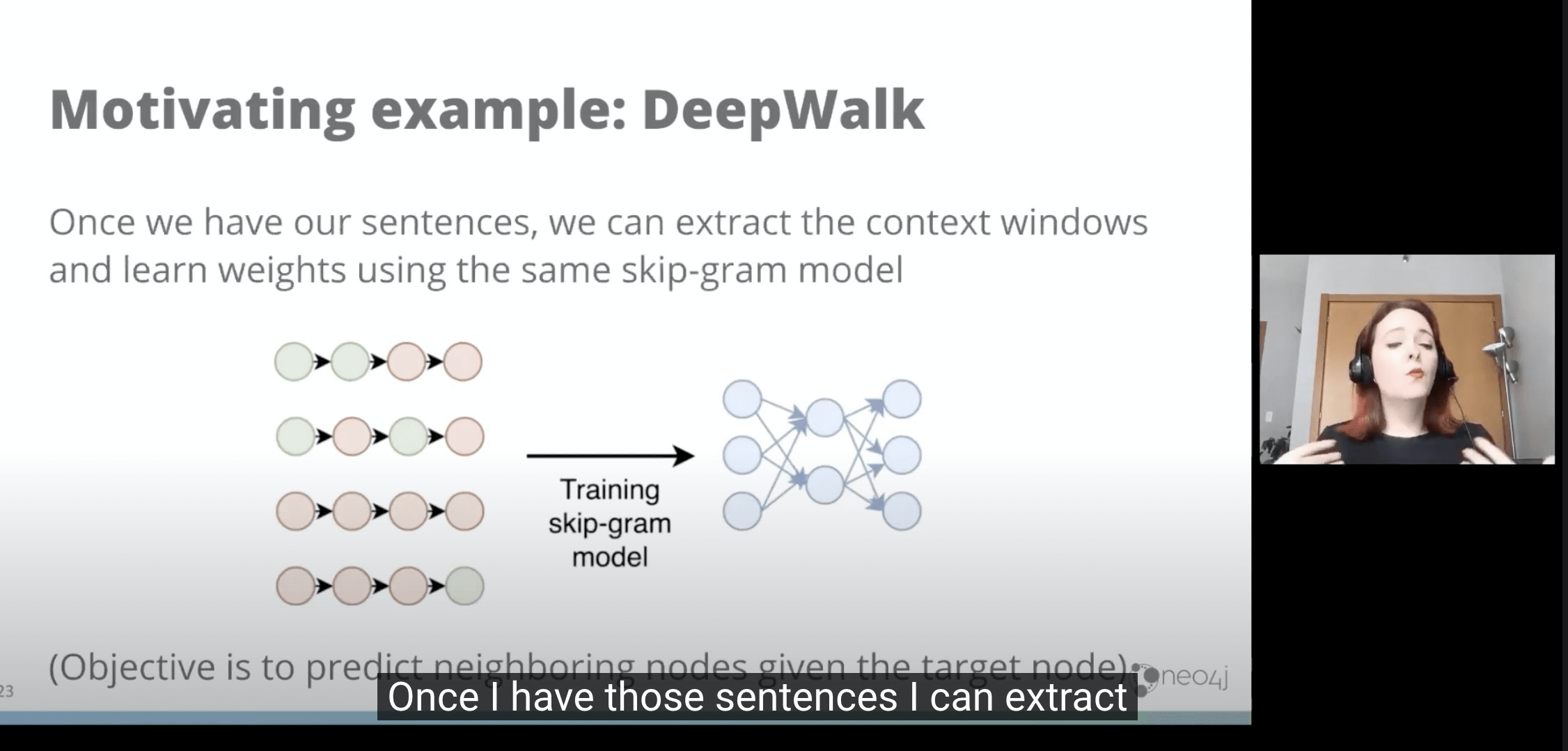
- 当我们有x个序列只哦呼,我们又可以用一样的skipGram来生成带weight的边
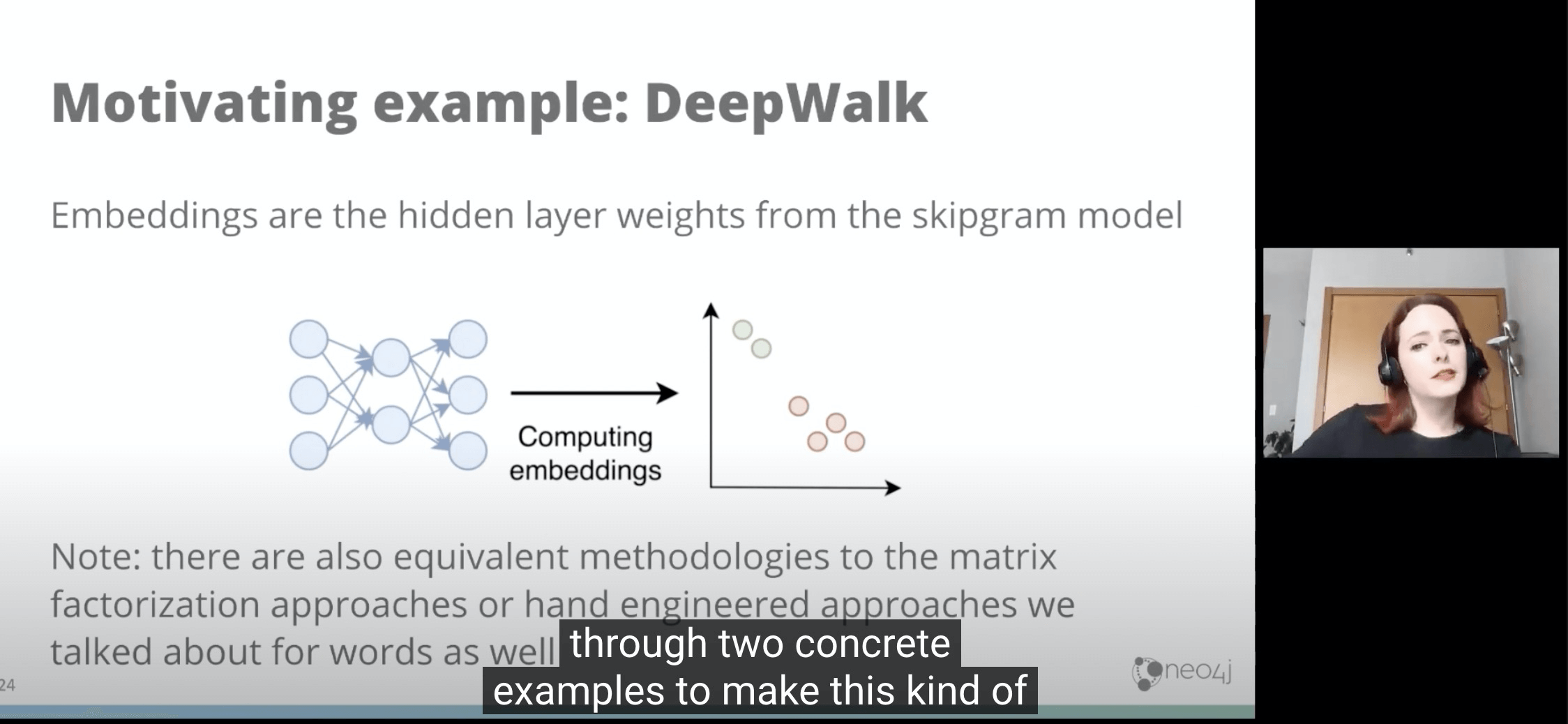
- 然后再用像上面wordEmbbedding的方法来生成多维矩阵和看相似度。

- 现在有很多GraphEmbedding的方法,前面WordEmbedding看的是以单词在句子(行为序列)里看相似;后面GraphEmbedding就以单词在图行为序列里看相似。
- 根据Graph Embedding重点研究主体不同,可以看节点相似,边相似,图相似,知识图谱相似。
- 在Ebay里用于商品相似度识别。
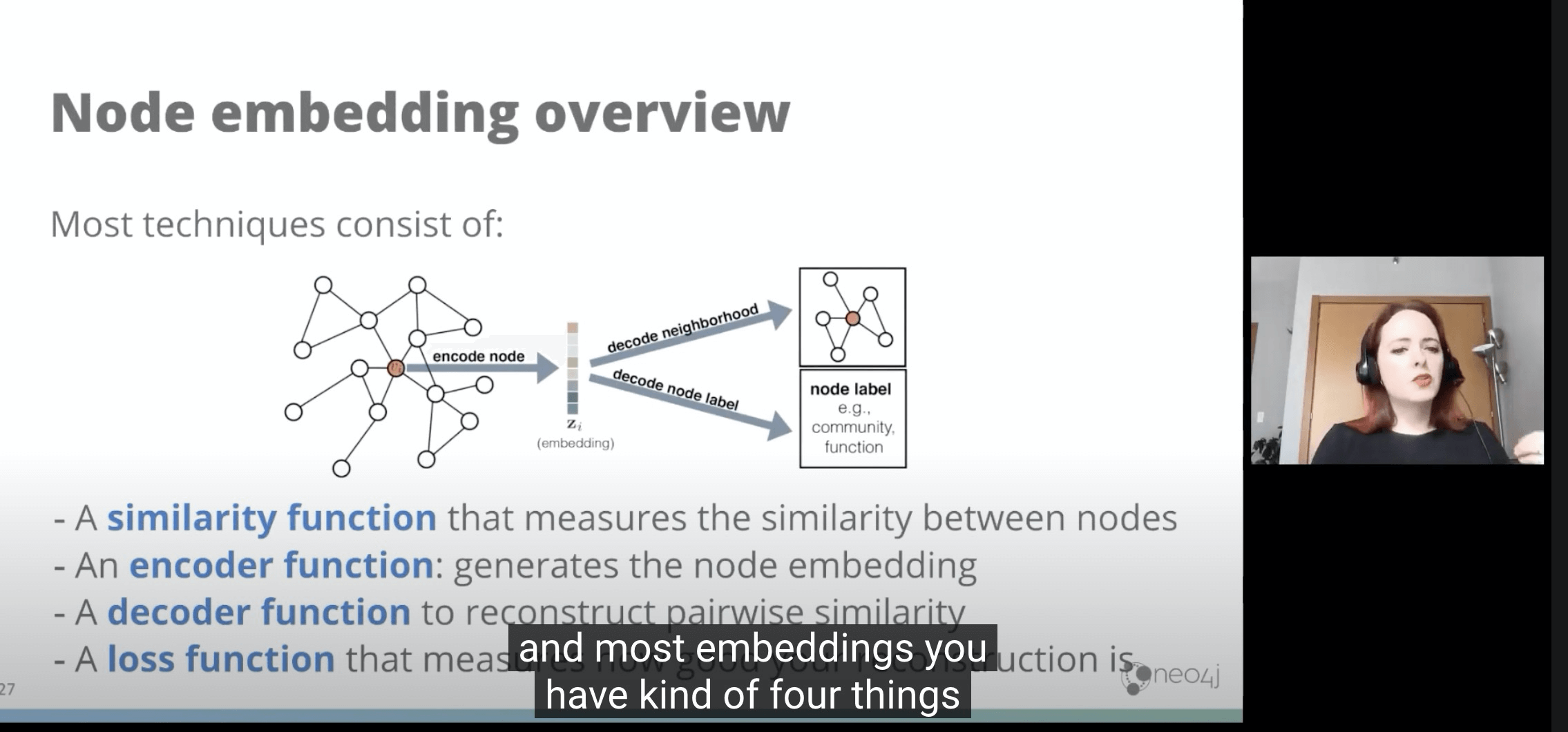
- 总体方法论必须:
- 一个相似度函数
- 一个编码函数
- 一个解码函数
- 一个损失函数:用来衡量重新生成的表达有多好。


- Shallow Embbedding 不是很有效率。
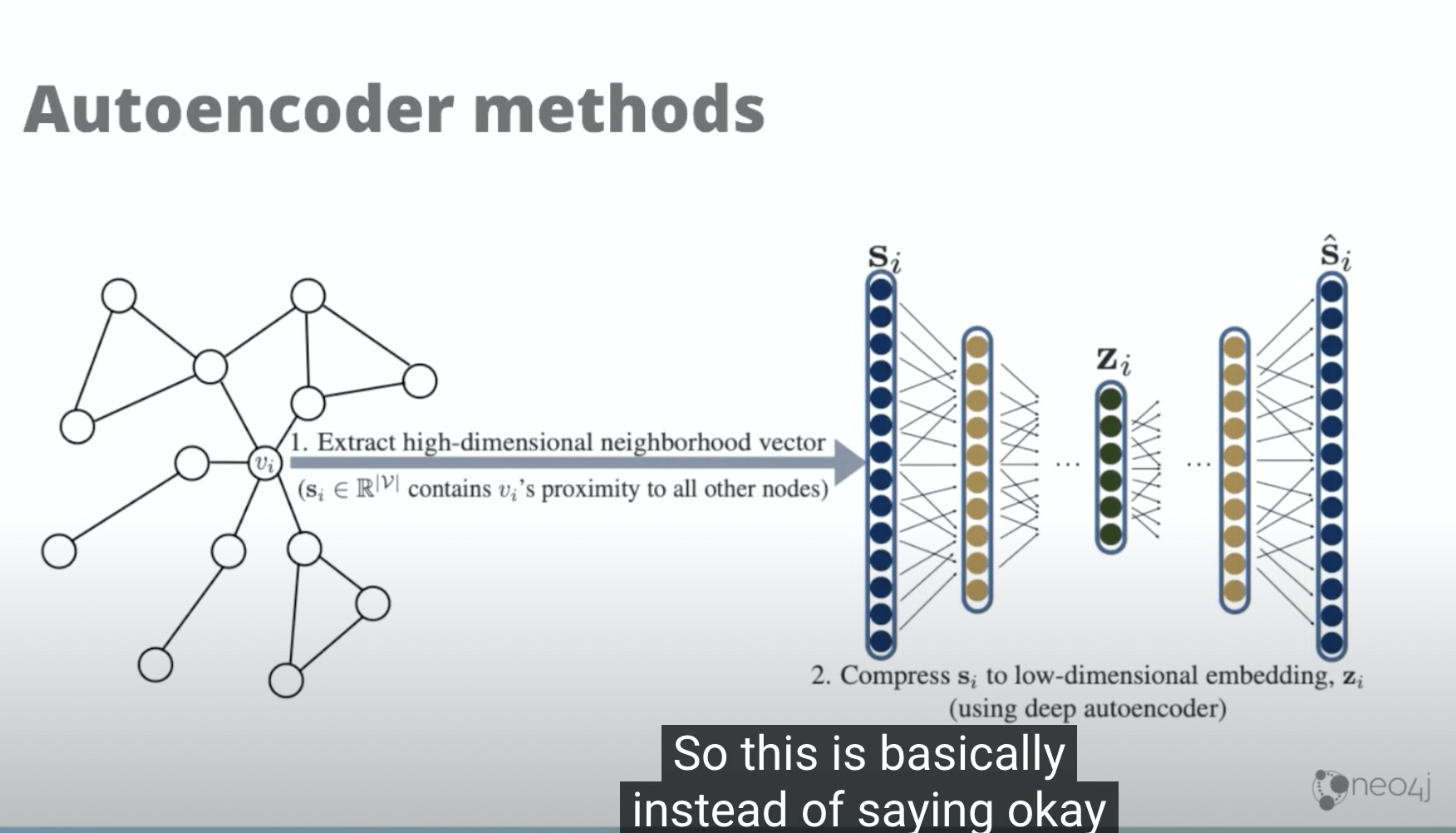
- 自动化编码模式

- 应用场景
- 可视化与模式识别
- 聚类与社区识别
- 协同推荐
- 定义识别同一属性东西


- 我们可以在Neo4J使用GraphEmbedding技术。

- 课后问答习题。

若有收获,就点个赞吧
0 人点赞
