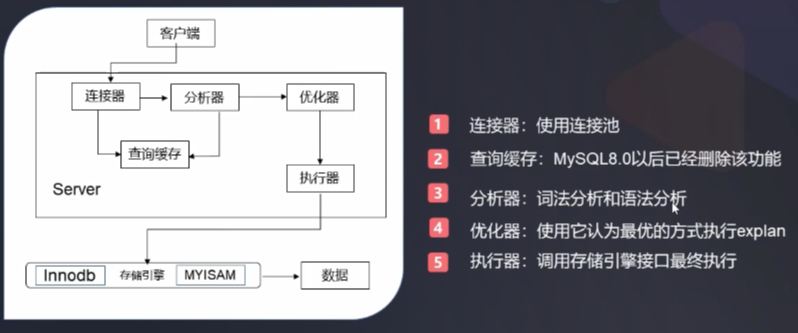
一、MySQL 的底层架构
二、MySQL 的存储引擎介绍
2.1 MyISAM 存储引擎
- 由 frm,myd,myi三个文件组成
- 不支持事务
- 提供表级锁
- 不支持外键
-
2.2 InnoDB 存储引擎
由 frm 、ibd 两个文件组成
- 支持事务
- 提供行级锁,可以通过行锁实现表锁的效果
-
2.3 Memory 存储引擎
定义在 frm 文件中
- 数据存放到内存中,访问效率高
- 提供表级锁
三、事务的 ACID 特性
3.1 描述一下你对事务隔离级别的理解
数据库的事务具有 ACID 特性,其中指的是隔离性;数据库存在 RU、RC、RR 和 S 四种隔离级别,设置不同的隔离级别可能产生脏读,不可重读,幻读等数据一致性的问题
深入:事务的隔离级别是使用 LBCC 机制 和 MVCC 机制来实现的,LBCC 和 MVCC
- ACID 特性
- 事务的隔离级别详解
- LBCC
-
3.2 ACID 特性
原子性(Atomicity)
- 整个事务中的所有操作,必须作为一个单元全部完成
- 借助 undolog 实现
- 一致性 (Consistency)
- 在事务开始之前与结束之后,数据库都保持一致状态
- 一般使用业务逻辑来保证
- 隔离性(Isolation)
- 一个事务不会影响其他事务的运行
- 使用锁机制和MVCC 机制来实现
- 持久性(Durability)
- 在事务完成以后,该事务对数据库所作的更改将持久的保存在数据库中,并不会回滚
3.3 隔离级别分类
- 读未提交:(READ UNCOMMITTED)
- 读已提交:(READ COMMITTED)
- 可重复读:(REPEATABLE READ)
- 串行化:(SERIALLZABLE)
3.4 数据一致性问题
- 脏读 (Dirty Read)
- 不可重复读(Non-repeatable Read)
- 幻读 (Phantorn Read)
3.5 不同隔离级别的数据一致性问题
| 事务隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 未提交读:(READ UNCOMMITTED) | 可能 | 可能 | 可能 |
| 读已提交:(READ COMMITTED) | 不可能 | 可能 | 可能 |
| 可重复读:(REPEATABLE READ) | 不可能 | 不可能 | 对 InnoDB 不可能 |
| 串行化:(SERIALLZABLE) | 不可能 | 不可能 | 不可能 |
四、MySQL LBCC 实现隔离性
4.1 数据库 ACID 特性中的隔离性是如何实现的?
隔离性实现之一是使用锁机制,即 LBCC (Lock Based Concurrency Control):读取数据之前,对其加锁,阻止其他事物进行修改
4.2 MySQL 数据库支持哪些种锁
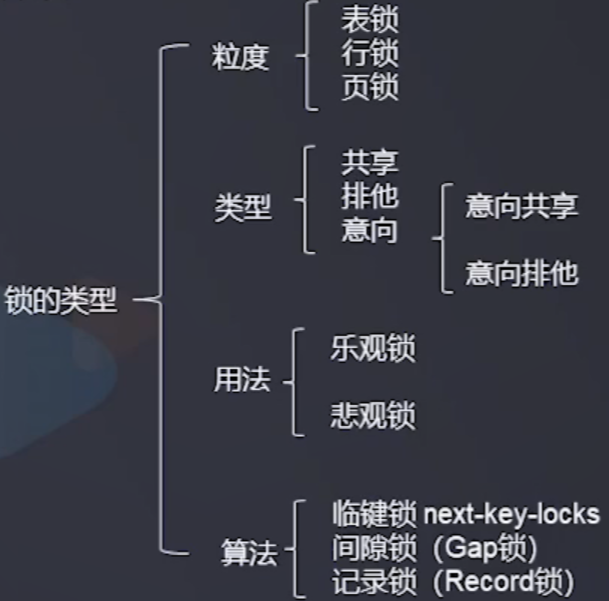
innoDB 行锁
MyISAM 表锁
4.3 共享锁 (S 锁)
多个事物对于同一数据可以共享一把锁,都可以访问到数据,但是只能读不能修改因此又叫读锁,s锁
加锁方式:查询语言后使用 lock in share mode
4.4 排他锁 (X锁)
排他锁不能与其他锁共存,又叫做写锁,x锁
加锁方式:更新自动加排他锁,查询语言使用 for update
4.4 锁的本质
4.4.1 InnoDB锁级别是行锁吗?有没有表级别的锁?
- InnoDB 的行锁是通过 给索引上的索引项 加锁来实现的
- 只有通过索引条件进行数据检索,InnoDB 才会使用行锁
- 否则将使用表锁—— 锁住了索引的所有行,类似于表锁
4.4.2 InnoDB 行锁使用什么算法实现的
因为 InnoDB 默认的行锁使用临键锁算法
当 InnoDB 使用临键锁时不把自己的区间锁住还把下一个临键区间锁住,就能够防止了幻读
4.4.3 还有哪些行锁算法
- Record 记录锁
- Gap 间隙锁
- Next-key 临键锁
4.4.4 间隙锁 和 记录锁
简述一下 Gap锁 和 Record锁
Gap锁
- 当 sql 执行按照索引进行数据的检索时
- 查询条件为范围查找(between and, <>) 或者等值查询并有数据命中
- Gap 锁只在 RR 这种事物隔离级别存在
Record 锁
- 当使用唯一性索引(包括主键索引 和唯一索引)
- 条件为精准匹配从表中检索数据时,那么可以命中唯一一条记录
五、MVCC 实现隔离性
一个事物加了排他锁,为什么其他事物还是能够读取到数据呢?
MVCC (Multi Version Concurrency Control):事物中第一次读取数据时,生成一个数据请求的时间点的一致性数据快照,并用这个快照提供语句级或事物的一致性读取
数据库中每一个表都存在三个隐藏字段,MVCC 是通过隐藏字段实现的
六、数据库优化
6.1 在查询中 exists 和 in 又是哪个效率高?
一直以来任务 exists 比 in 效率高的说法是不正确的
- in 是把外表和内表作 hash 连接,而 exists 是对外表作 loop 循环,每次 loop 循环再对内表进行查询。
- 如果查询的两个表大小相当,那么用 in 和 exists 差别不大
- 如果两个表中一个较小,一个是大表,则子查询表大用 exists,子查询表小的用 in
6.2 优化方式
- 数据库结构优化
- 调整数据库参数
- 通过优化 MySQL 的参数可以提高资源的利用率,从而达到提供 MySQL 服务器性能的目的
- MySQL 的配置参数都在 my.conf 或者 my.ini 文件中,可以使用 mysql -help 查看 mysql 数据库的配置文件的位置
- 设计数据库遵从哪些原则
- 三大范式
- 第一范式:有主键,原子性,字段不可分割
- 第二范式:完全依赖,表中非主键列不存在对主键的部分依赖,要求每张表只表述一件事情
- 第三范式:没有传递依赖,表中的列不存在对非主键列的传递依赖
- 列选择原则
- 字段类型优先级
- 整形 > date, time > char,varchar > blob
- 长度够用就行
- 尽量避免使用 Null
- 非负性的数据,优先使用无符号存储
- 财务数据必须使用 decimal
- 字段类型优先级
- 反范式设计
- 三大范式
- 调整数据库参数
- 数据库设计的优化
- Explan 的使用
- 可以模拟优化器执行 SQL 查询语句,从而知道 MySQL 是如何处理你的 SQL 语句的,分析你的查询语句或是表结构的性能瓶颈
- 可以分析出如下指标
- 表的读取顺序
- 数据读取操作的的操作类型
- 哪些索引可以使用
- 哪些索引被实际引用
- 表之间的引用
- 每张表有多少行被优化器查询
- 使用方式:explain sql
- eg explain select * from tb_item;
- select_type: select 查询的类别,区别是普通查询,联合查询,子查询等复杂查询
- type:表的连接类型,由最佳到最差 system > const > eq_ref > range > index > all
- key 相关:索引的使用情况
七、索引
7.1 in 和 or 哪个效率高
使用 in 或者 or 应该考虑一个前提条件:所在列是否有索引
- 如果有索引,性能没啥差别
- 如果没有索引,in 的效率会比 or 有明显的提高
7.2 高频问题
7.2.1 索引的本质和作用
数据库的索引本质时数据结构,这种数据结构能够帮助我们快速的获取数据库中的数据。有了索引相当于给我们的数据库加了目录一样,可以快速的找到数据,如果不使用索引就需要一点一点的去查找数据。作用是:提高了数据查询的效率
7.2.2 索引的优缺点
优点:
- 可以通过简历唯一索引 或者 主键索引,保证数据库中每一行数据的唯一性
- 建立索引可以大大提高检索数据的效率,以及减少表的索引行数
- 在分组和排序字句进行数据检索,可以减少查询中分组和排序时所耗的时间
缺点:
- 在创建索引和维护索引会消耗时间,随着数据量的增加而增加
- 索引文件会占用物理空间
- 当对表的数据进行更新操作时,索引也需要动态的维护,这降低了数据的维护速度
- 如果你在一个大表上创建了多种组合索引,会造成索引文件的膨胀
- 索引的原理
索引原理图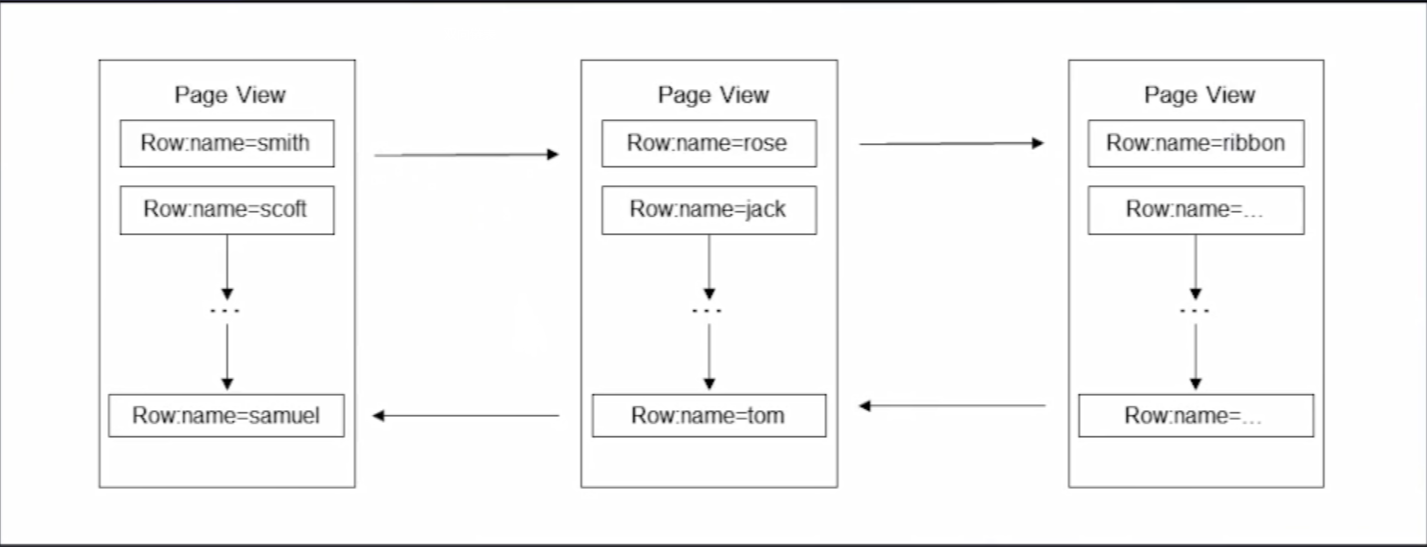
建立索引增加了检索速度,索引其实就是一棵 B+Tree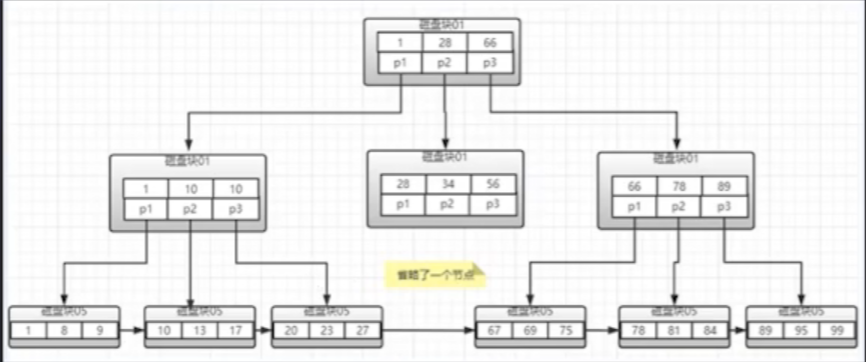
B+Tree 时 BTree 的一个变种,设 d 为树的度数(节点拥有子树的数量),树的度和关键字个数时相等的,h为树的高度,B+Tree 和 BTree 的不同主要在于:
- B+Tree 种的非叶子节点不存储数据,只存储键值
- B+Tree的叶子节点没有指针,所有键值都会出现在叶子节点上
- B+Tree 的每个非叶子节点由 n 个键值 key 和 n 个指针 point 组成,则和关键字是相等的
7.2.3 不同引擎的索引结构
一、InnoDB 的索引结构
- 什么是聚集索引?
- 聚集索引(clustered index):指数据库表行中数据的物理顺序与键值的索引顺序相同即决定了
数据的物理存储顺序的索引。一个表一定要有且仅有一个聚集索引
- 如果创建了主键索引,那么主键索引就是 聚集索引
- 如果没有主键索引,那么第一个是 uniquekey(唯一) 索引就是聚集索引
- 如果也没有唯一索引,那么表种将一个内置的隐藏 rowid 字段作为聚集索引
- 什么是二级索引?
- 所有的 非聚集索引都是二级索引
- 常见的索引优化技巧
二、MyISAM引擎 的索引结构
MyISAM引擎的表由三个文件组成,分别是frm、.myd。 其中myi文件存储的就是索引文件
MyISAM引擎的索弓结构主键索引和二级索引是一致的。
叶节点的data域存放的是数据记录的地址。
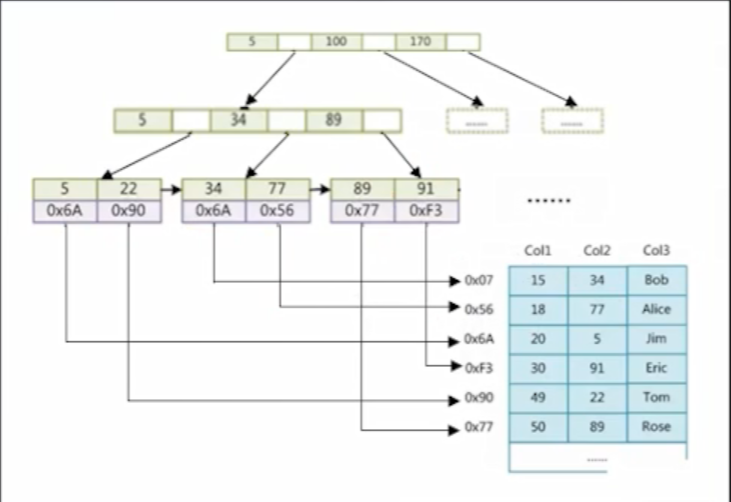
三、InnoDB 和 MyISAM 索引文件相同吗?
InnoDB 分为主键索引 和 二级索引,表数据文件本身就是按 B+Tree组织的一个索引结构,这棵树的叶节点 data 域保存了完整的数据记录
MyISAM 数据文件和索引文件时分开的,索引文件仅保存数据记录的地址
7.2.4 索引优化的技巧
- 离散度
离散度:count(distinct(clumn)); count(*),离散度在不超过全表 10% ~ 15%的前提下索引才可以显示其所具有的价值。当离散度超过该值的情况下全表扫描可能反倒比索引扫描更有效
- 最左前缀原则
主要体现在联合索引上,比如 user 表的 name 和 city 加联合索引就是 name,city,而最左前缀原则指的是,如果查询的时候查询条件可以从左到右精准匹配连续一列 或 几列,则就可以命中索引

若有收获,就点个赞吧
0 人点赞
