start-dfs.sh
start-yarn.sh

nohup hive —service metastore>metastore.log 2>&1 &
**启动hive
在test上启动Thrift服务器
服务模式
/opt/hive/bin/hiveserver2 start &
停止命令:
/opt/hive/bin/hiveserver2 stop &
====
命令行模式:
hive —service hiveserver2 —hiveconf hive.server2.thrift.port=10001
netstat -an |grep 9083
netstat -an |grep 10000

/opt/spark/sbin/start-all.sh
停止
/opt/spark/sbin/stop-all.sh
cat>people.json<
{“name”:”Andy”,”job number”:”002”,”age”:30,”gender”:”female”,”deptId”:2,”salary”:4000}
{“name”:”Justin”,”job number”:”003”,”age”:19,”gender”:”male”,”deptId”:3,”salary”:5000}
{“name”:”John”,”job number”:”004”,”age”:32,”gender”:”male”,”deptId”:1,”salary”:6000}
{“name”:”Herry”,”job number”:”005”,”age”:20,”gender”:”female”,”deptId”:2,”salary”:7000}
{“name”:”Jack”,”job number”:”006”,”age”:26,”gender”:”male”,”deptId”:3,”salary”:3000}
EOF
cat>newPeople.json<
{“name”:”Herry”,”job number”:”008”,”age”:20,”gender”:”female”,”deptId”:2,”salary”:5000}
{“name”:”Jack”,”job number”:”009”,”age”:26,”gender”:”male”,”deptId”:3,”salary”:6000}
EOF
cat>department.json<
{“name”:”Personnel dept”,”deptId”:2}
{“name”:”Testing dept”,”deptId”:3}
EOF
hdfs dfs -mkdir /user/hadoop
hdfs dfs -put people.json /user/hadoop
hdfs dfs -put newPeople.json /user/hadoop
hdfs dfs -put department.json /user/hadoop
hdfs dfs -ls /user/hadoop
http://192.168.100.21:50070
http://192.168.100.21:50070/explorer.html#/user/hadoop
spark-shell —master spark://test:7077 \
—executor-memory 1g \
—driver-class-path /opt/spark/lib/mysql-connector-java-5.1.48-bin.jar
import org.apache.log4j.{Level,Logger}
Logger.getLogger(“ora.apache.spark”).setLevel(Level.WARN)
Logger.getLogger(“ora.apache.spark.sql”).setLevel(Level.WARN)
===
import org.apache.log4j.{Level,Logger}
Logger.getLogger(“ora.apache.spark”).setLevel(Level.OFF)
Logger.getLogger(“ora.apache.spark.sql”).setLevel(Level.OFF)
修改文件 /opt/spark/conf/log4j.properties
log4j.rootCategory=INFO, console
改为
log4j.rootCategory=off, console
val people=spark.read.json(“hdfs://test:9000/user/hadoop/people.json”)
val dept= spark.read.json (“hdfs://test:9000/user/hadoop/department.json”)
====
val people=sqlContext.read.json(“hdfs://test:9000/user/hadoop/people.json”)
val dept=sqlContext.read.json (“hdfs://test:9000/user/hadoop/department.json”)
val people=sqlContext.jsonFile(“hdfs://test:9000/user/hadoop/people.json”)
val dept=sqlContext.jsonFile(“hdfs://test:9000/user/hadoop/department.json”)
(sqlContext.jsonFile()过时了!)
people.show
dept.show

people.columns
people.take(3)

people.toJSON.collect

people.filter(“gender=’male’”).count

people.filter($”gender”!==”female”).count

people.filter($”age”>25).show

people.where($”age”>25).show
people.where(‘age>25).show

(这两句有什么区别呢?):表示方法的区别:’age的表示方法是DSL(Domain Specific Language)的表示方法
people.filter($”age”>25 && $”gender”===”male”).show
people.where($”age”>25 && $”gender”===”male”).show

people.sort($”job number”.asc).show
people.sort($”job number”.desc).show

people.sort(“job number”).show
people.sort(“job number”).show(3)

people.sort(col(“salary”).desc).show

people.sort($”job number”.asc,col(“deptId”)).show

people.sort($”job number”.desc,col(“deptId”)).show

people.sort($”job number”.asc,col(“deptId”).desc).show

people.sort(col(“job number”).asc,col(“deptId”).asc).show
people.sort(col(“job number”).desc,col(“deptId”).asc).show

people.show
people.withColumn(“level”,people(“age”)/10).show
people.columns
列名写错(列名job number少写最后一个字母r),不会进行修改!
people.withColumnRenamed(“job numbe”,”jobId”).columns
列名正确的话,会进行列名修改
people.withColumnRenamed(“job number”,”jobId”).columns
:quit
spark-shell —master spark://test:7077 \
—executor-memory 1g \
—driver-class-path /opt/spark/lib/mysql-connector-java-5.1.48-bin.jar
val people=spark.read.json(“hdfs://test:9000/user/hadoop/people.json”)
val newPeople=spark.read.json(“hdfs://test:9000/user/hadoop/newPeople.json”)
people.columns
newPeople.columns
people.show

newPeople.show
people.unionAll(newPeople).show
people.union(newPeople).show
val groupName=people.unionAll(newPeople).groupBy(col(“name”)).count

groupName.show
groupName.filter($”count”>1).show
people.unionAll(newPeople).groupBy(col(“name”)).count.filter($”count”>1).show
people.union(newPeople).groupBy(col(“name”)).count.filter($”count”>1).show
val depAgg=people.groupBy(“deptId”).agg(Map(“age”->”max”,”gender”->”count”))
depAgg.show
先分组,在对分组求age的最大值,对gender进行计数
depAgg.toDF(“deptId”,”maxAge”,”countGender”).show

(重新命名列名,增加可读性)
val unionPeople=people.unionAll(newPeople).select(“name”).show
val unionPeople=people.unionAll(newPeople).select(“name”).distinct.show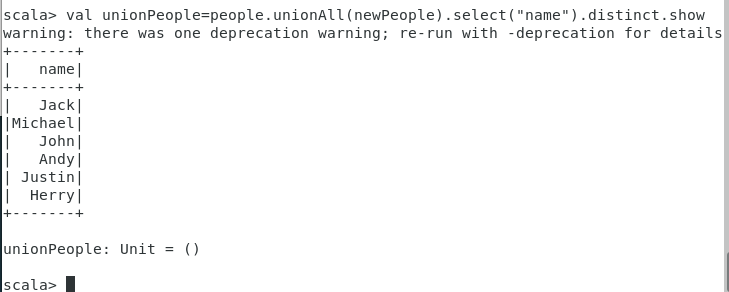
集合减
people.select(“name”).except(newPeople.select(“name”)).show
集合交
people.select(“name”).intersect(newPeople.select(“name”)).show
:quit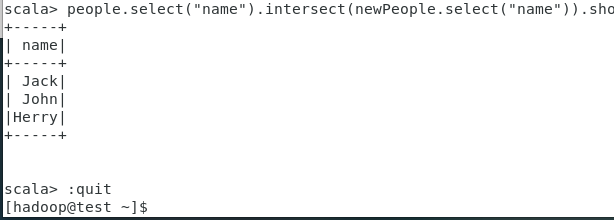
spark-shell —master spark://test:7077 \
—driver-class-path /opt/spark/lib/mysql-connector-java-5.1.48-bin.jar
读取json文件
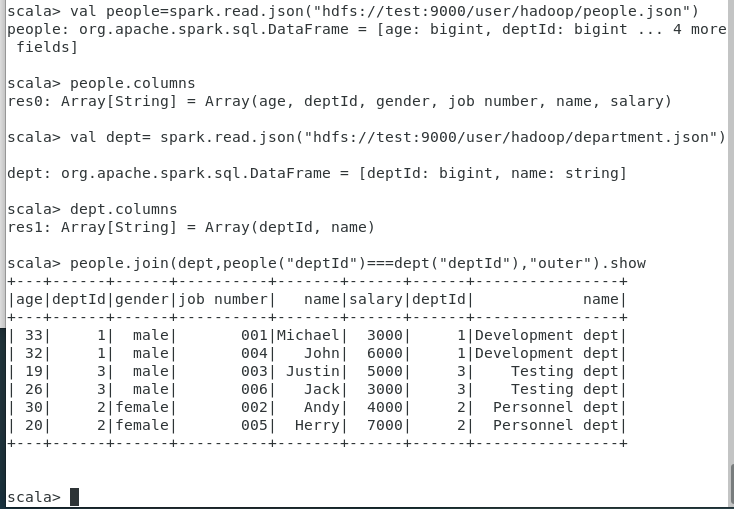
val people=spark.read.json(“hdfs://test:9000/user/hadoop/people.json”)
people.columns
val dept= spark.read.json(“hdfs://test:9000/user/hadoop/department.json”)
dept.columns
连接的两个表具有相同的列名deptId
people.join(dept,people(“deptId”)===dept(“deptId”),”outer”).show
生成一个具有不同列名的DataFrame
val rnDept=dept.withColumnRenamed(“deptId”,”id”).withColumnRenamed(“name”,”deptName”)
rnDept.columns
people.columns
val joinP=people.join(rnDept,$”deptId”===$”id”,”outer”)

joinP.show
val joinGp=joinP.groupBy(“deptName”).agg(Map(“age”->”max”,”gender”->”count”))
joinGp.show
val joinGpZQF=joinP.groupBy(“deptName”).agg(Map(“age”->”max”,”gender”->”count”))
joinGpZQF.show;
val joinGpZQF=joinP.groupBy(“deptName”).agg(Map(“age”->”max”,”gender”->”count”))
joinGpZQF.show;
joinGpZQF.registerTempTable(“peopleDeptGroupJoinTempTableOld”)
上面的提示表示registerTempTable方法已经过时!
registerTempTable已经被
joinGpZQF.createOrReplaceTempView(“peopleDeptGroupJoinTempTableNew”)
可以看出已经没有过时的提示了!
重新生成临时表
joinGpZQF.createOrReplaceTempView(“peopleDeptGroupJoinTempTable”)
spark.sql(“SELECT from peopleDeptGroupJoinTempTable”).show
改列名,并保存为表
val joinGpWithNewName=joinGp.withColumnRenamed(“max(age)”,”maxAge”).withColumnRenamed(“count(gender)”,”countGender”)
joinGpWithNewName.show()
joinGpWithNewName.write.saveAsTable(“peopleDeptGroupJoinSaved”)
在hive中可以查看到刚才保存的表
hive
show tables;
select from peopledeptgroupjoinsaved;
在Spark中查询
spark.sql(“SELECT * from peopleDeptGroupJoinSaved”).show
spark.catalog.listTables.show
**
val dfReadFromTable=spark.table(“peopleDeptGroupJoinSaved”)
dfReadFromTable.
joinGpWithNewName.write.format(“org.apache.spark.sql.json”).save(“hdfs://test:9000/user/hadoop/joinGpWithNewNameSaveJsonOnHDFS.json”)
在hdfs中检查:
hdfs dfs -ls /user/hadoop
hdfs dfs -ls /user/hadoop/joinGpWithNewNameSaveJsonOnHDFS.json
joinGpWithNewName.write.format(“org.apache.spark.sql.parquet”).save(“hdfs://test:9000/user/hadoop/joinGpWithNewNameSaveJsonOnHDFS.parquet”)
在hdfs中检查:
hdfs dfs -ls /user/hadoop
hdfs dfs -ls /user/hadoop/joinGpWithNewNameSaveJsonOnHDFS.parquet
将生成parquet文件保存留待以后的测试
hdfs dfs -get /user/hadoop/joinGpWithNewNameSaveJsonOnHDFS.parquet .
ls
tar cvf joinGpWithNewNameSaveJsonOnHDFS.parquet.tar joinGpWithNewNameSaveJsonOnHDFS.parquet/
[sparkSQL实战详解
https://www.cnblogs.com/hadoop-dev/p/6742677.html
SparkSession、SparkContext、SQLContext和HiveContext之间的区别
https://www.cnblogs.com/lillcol/p/11233456.html
**Hive on Spark安装详解(
https://www.cnblogs.com/linbingdong/p/5806329.html
Hive默认使用MapReduce作为执行引擎,即Hive on mr。
实际上,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark。
由于MapReduce中间计算均需要写入磁盘,而Spark是放在内存中,所以总体来讲Spark比MapReduce快很多。因此,Hive on Spark也会比Hive on mr快。
为了对比Hive on Spark和Hive on mr的速度,需要在已经安装了Hadoop集群的机器上安装Spark集群(Spark集群是建立在Hadoop集群之上的,也就是需要先装Hadoop集群,再装Spark集群,因为Spark用了Hadoop的HDFS、YARN等),然后把Hive的执行引擎设置为Spark。
Spark运行模式分为三种1、Spark on YARN 2、Standalone Mode 3、Spark on Mesos。
Hive on Spark默认支持Spark on YARN模式,因此我们选择Spark on YARN模式。Spark on YARN就是使用YARN作为Spark的资源管理器。分为Cluster和Client两种模式。
要使用Hive on Spark,所用的Spark版本必须不包含Hive的相关jar包,hive on spark 的官网上说“Note that you must have a version of Spark which does not include the Hive jars”。在spark官网下载的编译的Spark都是有集成Hive的,因此需要自己下载源码来编译,并且编译的时候不指定Hive。
https://blog.csdn.net/Dante_003/article/details/72867493
https://blog.csdn.net/yeruby/article/details/51448188
https://blog.csdn.net/MrLevo520/article/details/76696073
[spark 数据读取与保存
https://www.cnblogs.com/playforever/p/7737675.html
https://blog.csdn.net/xuejianbest/article/details/85775442
**
[hadoop@test conf]$ cd
[hadoop@test ~]$ cd /opt/hive/conf
[hadoop@test conf]$ cat hive-site.xml
<?xml version=”1.0”?>
<?xml-stylesheet type=”text/xsl” href=”configuration.xsl”?>

若有收获,就点个赞吧
0 人点赞
