Spark核心测试
启动测试环境
启动Hadoop

启动Spark集群

启动spark-shell

单值型Transformation算子
map
map(func)
对RDD中的每一个元素,执行一个指定的函数func,输出一个新的元素,从而形成新的RDD。
RDD-1中的元素V1经过函数映射后,变为新的元素V’1,最终构成新的RDD-2。输入输出分区1对1型不会产生任何变化。注意,事实上,只有Action算子被触发后,这些操作才会被真正执行。
例子:
val a=sc.parallelize(List(“bit”,”linc”,”xwc”,”fjg”,”wc”,”spark”),3)
val b=a.map(word=>word.length)
val c=a.zip(b)
c.collect

flatMap
flatMap(func)
对RDD中的每一个元素,执行一个指定的函数func,输出一个或者多个新的元素,从而形成新的RDD。
比较map和flatMap:
map是输入一个RDD元素,执行func之后,输出一个RDD元素;
flatMap是输入一个RDD元素,执行func之后,输出一个或者多个RDD元素;
val a=sc.parallelize(1 to 10,5)
a.flatMap(num=>1 to num).collect
例子中func对于当个数字n,输出从1到n的数字系列。
因此:
对于元素1,flatMatp输出1这个元素;
对于元素2,flatMap输出1,2这两个元素;
对于元素3,flatMap输出1,2,3这三个元素;
其他的元素依次类推。
mapPartitions
mapPartitions(func)
以分区为粒度,将每个RDD分区,作为函数func的输入,执行函数func,产生新的RDD。
例子:
val a=sc.parallelize(1 to 9,3)
def myfuncT:Iterator[(T,T)]={
var res=List(T,T)
var pre=iter.next
while(iter.hasNext){
var cur=iter.next
res .::=(pre,cur)
pre=cur
}
res.iterator
}
a. mapPartitions(myfunc).collect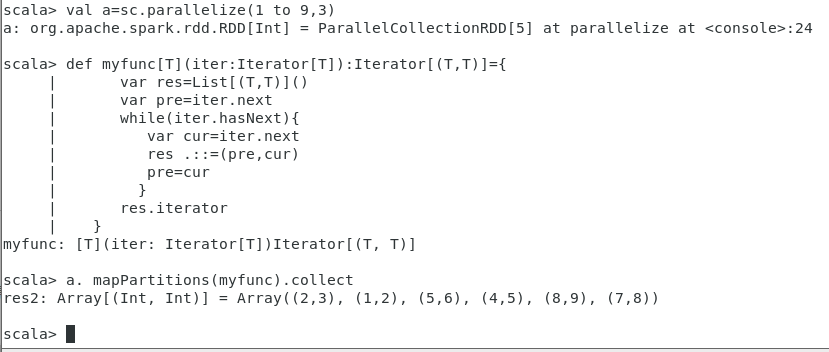
例子中,原始的RDD有3个分区,每个分区作为函数myfunc的输入。
myfunc函数,输入为一个列表(如a1,a2,a3),输出是列表的两个连续元素构成的元组(如(a1,a2)(a2,a3)),列表的最后一个元素(此处为a3),不能形成以最后一个元素为开头的元组。
例子中的输入RDD有3个分区:
1,2,3;
4,5,6;
7,8,9
以分区为输入单位,执行myfunc函数后,形成新的RDD的元素,如下图所示:
例子:
val a=sc.parallelize(List(-2,-1,1,6,7,8),2)
a.mapPartitions(iter=>iter.filter(_>0)).collect
mapPartitionsWithIndex
mapPartitionWithIndex(func)
每个RDD分区,作为函数func的输入,执行函数func,产生新的RDD(其中的元素会包含分区编号信息)。
val x=sc.parallelize(List(1,2,3,4,5,6,7,8,9,10),3)
def myfunc(index:Int,iter:Iterator[Int]):Iterator[String]={
iter.toList.map(x=>index+”,”+x).iterator
}
x.mapPartitionsWithIndex(myfunc).collect

例子中,原始的RDD有3个分区,每个分区作为函数myfunc的输入。
myfunc函数,输入的参数为一个整数(如RDD的分区编号0)、一个分区列表(分区0的元素1,2,3);输出为一个数字系列0,1,0,2,0,3
例子中的输入RDD有3个分区:
1,2,3;
4,5,6;
7,8,9,10
以分区为输入单位,执行myfunc函数后,形成新的RDD的元素:
0,1,0,2,0,3;
1,4,1,5,1,6;
2,7,2,8,2,9,2,10;
foreach
foreach(func)
对RDD中的每一个元素,执行一个函数func,函数func没有返回值。
val c=sc.parallelize(List(“xwc”,”fjg”,”wc”,”dcp”,”zq”,”snn”,”mk”,”zl”,”hk”,”lp”),3)
c.foreach(x=>println(x+”are from USTB”))
val c=sc.parallelize(List(“xwc”,”fjg”,”wc”,”dcp”,”zq”,”snn”,”mk”,”zl”,”hk”,”lp”),3)
c.map(x=>x+”are from USTB”).collect.foreach(println)
foreachPartition
foreachPartition(func)
对RDD的每一个分区,执行一个函数func,函数func没有返回值。
例子:打印每个分区的汇总值
val b=sc.parallelize(List(1,2,3,4,5,6,7,8,9),3)
b.foreachPartition(x=>println(x.reduce(+)))
初始化为3个分区(1,2,3)(4,5,6)(7,8,9)
分区和因此分别是6、15、24
例子:函数func计算每个分区的元素个数,并且把该分区的个数累加到一个累加器变量。
var allsize = sc.accumulator(0)
var rdd1 = sc.makeRDD(1 to 1000,100)
rdd1.foreachPartition { x => {
allsize += x.size
}}
println(allsize.value)
glom
将RDD的每个分区中的元素,组装成为一个数组,形成一个由这些数组作为元素构成的RDD。 
例子:
val a=sc.parallelize(List(-2,-1,1,6,7,8),2)
a.glom.collect
例子:
val a=sc.parallelize(1 to 12,3)
a.glom.collect
例子中原始的RDD有3个分区:
1,2,3,4
5,6,7,8
9,10,11,12
每个分区转化为一个数组:
Array(1, 2, 3, 4),
Array(5, 6, 7, 8),
Array(9, 10, 11, 12)
形成了一个新的RDD(由3个元素构成,每个元素是一个数组)
intersection
求两个RDD的交集(去重)
val a=sc.parallelize(1 to 4,2)
val b=sc.parallelize(2 to 4,1)
a.intersection(b).collect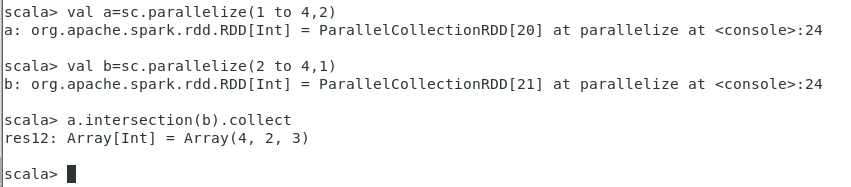
subtract
求两个RDD的差集
val a=sc.parallelize(1 to 4,2)
val b=sc.parallelize(2 to 4,1)
a.subtract(b).collect
val a=sc.parallelize(List(“Lion”,”Dolphin”,”Whale”,”Lion”))
val b=sc.parallelize(List(“Shark”,”Dolphin”,”Lion”))
a.subtract(b).collect
测试表明是先对RDD去重形成元素集合,然后再做两个RDD集合间的差集。
val a=sc.parallelize(1 to 9,3)
val b=sc.parallelize(1 to 3,1)
val c=a.subtract(b)
c.collect
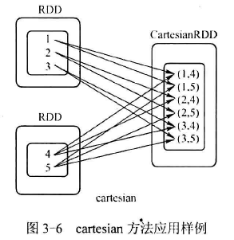
cartesian
求两个RDD的笛卡尔集
例子:
val x=sc.parallelize(List(1,2,3),1)
val y=sc.parallelize(List(4,5),1)
x.cartesian(y).collect

groupBy
groupBy(func)
对RDD中的每一个元素,执行函数func,根据函数func的返回值进行分组,也就是通过map转换形成一个新的由kv键值对组成的RDD(函数func的返回值为kv的键,元素本身是kv的值),再将键相同的键值对,分组在一起(值列表在一起)。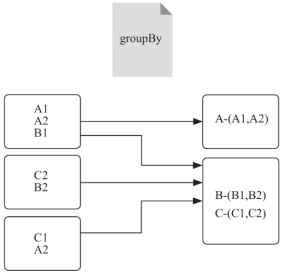
上图表明,groupBy先将元素通过函数生成Key,元素转为“Key-Value”类型之后,将Key相同的元素分为一组
例子:
val a=sc.parallelize(1 to 9,3)
a.groupBy(x=>{if(x%2==0) “even” else “odd”}).collect
例子:
val a=sc.parallelize(1 to 9,3)
def myfunc(a:Int):Int=
{
a%2
}
a.groupBy(myfunc).collect
例子:
val a=sc.parallelize(1 to 9,3)
def myfunc(a:Int):Int=
{
a%2
}
a.groupBy(myfunc(_),1).collect
filter
filer(func)
对RDD中的每一个元素,执行函数func,该函数返回true或者false,对于返回true的元素(满足条件的元素),放到新的RDD中
例子: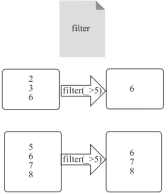
val a=sc.parallelize(List(2,3,6,5,6,7,8),2)
a.filter(>5) .collect
例子:
val a=sc.parallelize(1 to 10,3)
val b=a.filter(x=>x%3==0)
b.collect
例子:
val c=sc.parallelize(1 to 8)
val d=c.filter(x=>x<4).collect
例子:
val a=sc.parallelize(List(“cat”,”horse”,4.0,3.5,2,”dog”))
a.filter(<4).collect
列表中类型不同的话,不可以进行过滤。采用偏函数,可以解决这个问题。
distinct
去除原始RDD中的重复元素,形成一个新的RDD<br /> <br />val c=sc.parallelize(List("Gnu","cat","Rat","Dog","Gnu","Rat"))<br />c.distinct.collect<br /> <br /> <br />例子:distinct(n) 去除原始RDD中的重复元素,形成一个新的RDD,并进行重新分区,分区数为n<br />val a=sc.parallelize(List(1,2,3,4,5,6,7,8,9,9))<br />a.distinct.collect<br />a.distinct(2).partitions.length<br />a.distinct(3).partitions.length<br />
cache
将RDD缓存到内存中
val c=sc.parallelize(List(1,2,3,4,5,6,7,8,9,9))
c.cache
persist
根据不同级别,进行持久化
例子:默认持久化级别,保存到内存中,同cache
val a=sc.parallelize(1 to 9,3)
a.persist()
例子:持久化到内存中
import org.apache.spark.storage.StorageLevel
val b=sc.parallelize(1 to 9,3)
b.persist(StorageLevel.MEMORY_ONLY)

例子:持久化到内存和磁盘
import org.apache.spark.storage.StorageLevel
val c=sc.parallelize(1 to 9,3)
c.persist(StorageLevel.MEMORY_AND_DISK)
RDD转换为DataSet,缓存DataSet
val cDS=c.toDS
cDS.persist(StorageLevel.MEMORY_AND_DISK)
===
RDD、DataFrame、DataSet的区别
https://blog.csdn.net/weixin_43087634/article/details/84398036
sample
sample
第1个参数表示抽样方式
true放回抽样(泊松抽样)
false不放回抽样(伯努利抽样)
第2个参数是抽样比例
第3个参数是种子数
val a=sc.parallelize(1 to 1000,2)
a.sample(false,0.01,0).collect
val a=sc.parallelize(1 to 1000,2)
a.sample(true,0.01,0).collect
键值对型Transformation算子
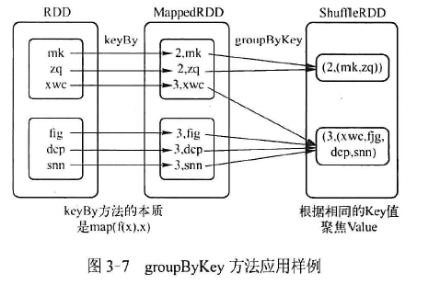
groupByKey
将键值对型RDD,键相同的元素,聚集在一起构成一个系列
//构建一个kv型RDD
val a=sc.parallelize(List(“mk”,”zq”,”xwc”,”fjg”,”dcp”,”snn”),2)
val b=a.keyBy(x=>x.length)
b.collect
b.groupByKey.collect
mapValues
mapValues(func)
键值对型RDD,原来的键保持不变,对值执行函数func,形成新的键值对型RDD
例子:
输入函数对Value分别进行加10操作,形成新的键值对型RDD。
val a=sc.parallelize(List((“A”,1),(“B”,2),(“C”,3),(“D”,4),(“E”,5)))
a.mapValues(y=>y+10).collect

例子:
val a = sc.parallelize(List(“dog”, “tiger”, “lion”, “cat”, “panther”, “eagle”), 2)
val b = a.map(x => (x.length, x))
b.mapValues(“x” + _ + “x”).collect
combineByKey
将键值对型RDD,聚合键相同的元素的值(Seq[V]),新生成的RDD形如(K,Seq[V])。
将RDD[K,V]转换为RDD[K,C]
V和C的类型可以相同也可以不同
例子:
例子1:
var rddl = sc.makeRDD(Array ((“A”,1),(“A”,2),(“B”,1),(“B”,2),(“C”,1)))
rddl.combineByKey(
(v:Int) => v + ““,
(c:String, v:Int) => c + “@” + v,
(c1:String,c2:String) => c1 + “$” + c2).collect

例子2:
//构建一个kv型RDD:RDD[K,V]
val a=sc.parallelize(List(“xwc”,”fjg”,”wc”,”dcp”,”zq”,”snn”,”mk”,”zl”,”hk”,”lp”),2)
val b=sc.parallelize(List(1,2,2,3,2,1,2,2,2,3),2)
val c=b.zip(a)
c.collect
val d=c.combineByKey(List(),(x:List[String],y:String)=>y::x, (x:List[String],y:List[String])=>x:::y)
d.collect
第1个参数createCombiner,List(_),将元素v转换为另外一个类型C
第2个参数mergeValue,(x:List[String],y:String)=>y::x,将元素V合并到元素C
第3个参数mergeCombiners,(x:List[String],y:List[String])=>x:::y,将两个元素C合并
union
相当于++,合并两个RDD(并集,不去重)

例子:
val a=sc.parallelize(1 to 4,2)
val b=sc.parallelize(2 to 4,1)
(a++b).collect
a.union(b).collect
例子中,第1个RDD有元素1,2,3,4(两个分区);第2个RDD有元素2,3,4(一个分区)
进行union运算后,形成新的RDD,有元素1,2,3,4,2,3,4
reduceByKey
对键值对型RDD中Key相同的元素的Value进行reduce操作,即两个值合并为一个值。因此,Key相同的多个元素的值被合并为一个值,然后与原RDD中的Key组成一个新的KV对。
例子:
val a=sc.parallelize(List((“A1”,2),(“A1”,1),(“A2”,2),(“A3”,1),(“B1”,1),(“B1”,2),(“B1”,3)),2)
a.reduceByKey(+).collect
例子:
//构建kv型RDD
val a=sc.parallelize(List(“dcp”,”fjg”,”snn”,”wc”,”zq”),2)
val b=a.map(x=>(x.length,x))
b.collect
b.reduceByKey((a,b)=>a+b).collect
例子:
//构建kv型RDD
val a=sc.parallelize(List(“xwc”,”fjg”,”wc”,”dcp”,”zq”,”snn”,”mk”,”zl”,”hk”,”lp”),2)
val b=sc.parallelize(List(1,2,2,3,2,1,2,2,2,3),2)
val c=b.zip(a)
c.collect
c.reduceByKey((a,b)=>a+b).collect
partitionBy

sortByKey
val a=sc.parallelize(List(“dog”,”cat”,”owl”,”gnu”,”ant”),2)
val b=sc.parallelize(1 to a.count.toInt,2)
val c=a.zip(b)
c.sortByKey(true).collect
c.sortByKey(false).collect
true按键升序排序
false按键降序排序
cogroup
作用:对多达3个RDD根据key进行分组,将每个Key相同的元素分别聚集为一个集合
例子:
上图对两个RDD进行cogroup
RDD1的V1→1 和RDD2的V1→1,形成V1→((1),(1))
RDD1的V2→2 和RDD2中无键是V2的map,相当于V2→null,形成V2→((1),(null))
RDD1中无键是V8的map,相当于V8→null;RDD2的V8→2,形成V8→((null),(1))
其他的以此类推!
注意图有错,漏了U2→((2),(null))
val a=sc.parallelize(List((“V1”,1),(“V2”,2),(“U1”,1),(“U2”,2),(“U5”,4)),2)
val b=sc.parallelize(List((“V1”,1),(“V8”,2),(“U1”,2),(“U5”,1)),2)
a.cogroup(b).collectAsMap
a.cogroup(b).collect

例子:
val a=sc.parallelize(List(1,2,2,3,1,3),1)
val b=a.map(x=>(x,”b”))
val c=a.map(y=>(y,”c”))
b.collect
c.collect

//单参数的情况,2个RDD聚集
b.cogroup(c).collect

//双参数的情况,3个RDD聚集
val d=a.map(z=>(z,”x”))
b.collect
c.collect
d.collect
b.cogroup(c,d).collect
join
将两个键值对型RDD,键相同的元素,连接起来
val a=sc.parallelize(List(“fjg”,”wc”,”xwc”,”dcp”),2)
val b=a.keyBy(.length)
val c= sc.parallelize(List(“fjg”,”wc”,”snn”,”zq”,”xwc”,”dcp”),2)
val d=c.keyBy(.length)
b.collect
d.collect
b.join(d).collect
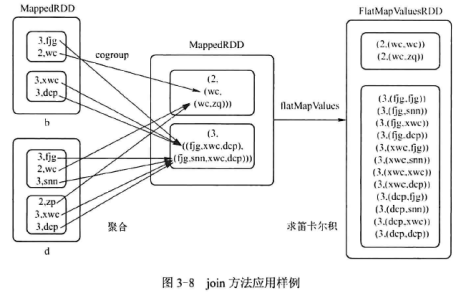
本例中,b和d是两个键值对类型的RDD
对于b中的(2,wc)与d中的(2,wc)(2,zq),键是相同的,因此将它们连接:
(2,(wc,wc)),(2,(wc,zq))
对于b中的(3,fjg)(3,xwc)(3,dcp)与d中的(3,fjg)(3,snn)(3,xwc)(2,dcp),键是相同的,因此将它们连接:
(3,(fjg,fjg))(3,(fjg,snn))(3,(fjg,xwc))(3,(fjg,dcp))
(3,(xwc,fjg))(3,(xwc,snn))(3,(xwc,xwc))(3,(xwc,dcp))
(3,(dcp,fjg))(3,(dcp,snn))(3,(dcp,xwc))(3,(dcp,dcp))
Action算子
collect
将RDD中分散存储的元素,以数组的形式(转换为单机上的scala数组)返回。

例子:
val c=sc.parallelize(List(“a”,”b”,”c”,”d”,”e”,”f”),2)
c.collect
collectAsMap
将元素类型为key-value对的RDD,转换为Scala Map并返回,保存元素的KV结构
val a=sc.parallelize(List((“A”,1),(“B”,2),(“C”,3),(“D”,4),(“E”,5)))
a.collectAsMap
lookup
扫描RDD的所有元素,选择与参数匹配的Key,并将其Value以Scala sequence的形式返回
val a=sc.parallelize(List((“A1”,21),(“A2”,22),(“A3”,23),(“A4”,22),(“A5”,22),(“D1”,22),(“D2”,22)),2)
a.lookup(“D1”)
reduce
reduce(func(x,y))
使用一个带两个参数的函数func(x,y),将原始RDD中元素进行聚合,返回一个结果。
函数func必须满足交换律和结合律!

val a=sc.parallelize(1 to 100)
a.reduce((x,y)=>x+y)
take
从原始RDD中取出前n个元素。首先从第一个分区取元素,如果第一个分区的元素小于n,则继续从第2个分区继续取元素。
val a=sc.parallelize(List(“a”,”c”,”d”,”b”,”e”),3)
a.take(3)
val b=sc.parallelize(1 to 100,5)
b.take(10)
top
从原始RDD中取出排名在前的n个元素
val a=sc.parallelize(Array(1,3,2,4,9,2,11,5),3)
a.top(3)
count
统计RDD中元素的个数。
val a=sc.parallelize(Array(1,3,2,4,9,2,11,5),3)
a.count
takeSample
第1个参数表示抽样方式
true放回抽样(泊松抽样)
false不放回抽样(伯努利抽样)
第2个参数是抽样个数
第3个参数是种子数
val a=sc.parallelize(1 to 1000,2)
a.takeSample(false,10,37)
val a=sc.parallelize(1 to 1000,2)
a.takeSample(true,10,37)
saveAsTextFile
将RDD保存为文本文件,为每个RDD分区产生一个文件。
可以保存在本地文件系统上,也可以保存在HDFS上。
例子:
val a=sc.parallelize(1 to 1000,10)
a.saveAsTextFile(“/home/hadoop/myRdd”)
a.saveAsTextFile(“hdfs://test:9000/user/hadoop/myRdd”)

保存在本地文件系统中了!
cd /home/hadoop/myRdd/
ls
保存在HDFS系统中了!
hdfs dfs -ls /user/hadoop/myRdd
rm -rf /home/hadoop/myRdd/
hdfs dfs -rm -r /user/hadoop/myRdd
saveAsObjectFile

countByKey
统计键值对型RDD 中,键相同的元素,值的个数有多少。
val a= sc.parallelize(List((1,”fjg”),(2,”wc”),(2,”snn”),(3,”zq”),(3,”zq”),(3,”xwc”),(3,”dcp”)),2)
a.countByKey
aggregate
aggregate先将每个分区里面的元素进行聚合,然后用聚合函数将每个分区的结果和初始值(zeroValue)进行聚合操作。这个函数最终返回的类型不需要和RDD中元素的类型二致。
aggregate 有两个函数seqOp 和combOp :都有两个输入参数,一个输出参数;seqOp 函数可以看成是reduce 操作;combOp 函数可以看成是第二个reduce 操作(一般用于聚合各分区结果到一个总体结果) 。由定义可以看出, combOp 操作的输入和l输出类型必须一致。
//分区0 的reduce 操作是max(O, 2,3) = 3
//分区l 的reduce 操作是max(O, 4,5) = 5
//分区2 的reduce 操作是max(O, 6,7) = 7
//最后的combine 操作是0+3+5 + 7=15
// note the final reduce include the initial value
val a= sc.parallelize(List(2,3,4,5,6,7), 3)
a.aggregate(0)((a,b) =>math.max(a, b), (c,d) => c + d)
// 分区0 的reduce 操作是max(3, 2,3) = 3
// 分区1 的reduce 操作是max(3, 4,5) = 5
// 分区2 的reduce 操作是max(3, 6,7) = 7
// 最后的combine 操作是3+3+5+7=18
val z=sc.parallelize(List(2,3,4,5,6,7), 3)
z.aggregate(3)((a,b) => math.max(a, b), (c,d) => c + d)
val z=sc.parallelize(List(“a”,”b”,”c”,”d”,”e”,”f”),2)
z.aggregate(“”)(+,+)
val z=sc.parallelize(List(“a”,”b”,”c”,”d”,”e”,”f”),2)
z.aggregate(“x”)(+,+)
为每个分区返回初始值x,然后再返回该分区的所有字符
第1个分区返回xabc
第2个分区返回xdef
为总的结果首先返回初始值x,然后再返回第1个分区的值xabc,接下来是返回第2个分区的的值xdef,最终返回xxabcxdef
fold
fold与aggregation类似,但是不提供RDD分区汇总函数seqOp,分区汇总也使用函数combOp。
每次对分区内的value聚集时,分区内初始化的值为zeroValue。

//分区0 的reduce 操作是0+1+2+3 = 6
//分区1 的reduce 操作是0+4+5+6 = 15
//分区2 的reduce 操作是0+7+8+9 = 24
//最后的combine 操作是0+6+15 + 24=45
val z=sc.parallelize(List(1,2,3,4,5,6,7,8,9), 3)
z.fold(0)(+)
//分区0 的reduce 操作是1+1+2+3 = 7
//分区1 的reduce 操作是1+4+5+6 = 16
//分区2 的reduce 操作是1+7+8+9 = 25
//最后的combine 操作是1+7+16 + 25= 49
val z=sc.parallelize(List(1,2,3,4,5,6,7,8,9), 3)
z.fold(1)(+)
共享变量
broadcast(广播变量)
存储在单节点内存中,不需要跨节点存储。Spark运行时,将广播变量数据分发到各个节点,可以跨作业共享。
val broadCastvar=sc.broadcast(Array(1,2,3))
broadCastvar.value
accucate(计数器)
允许全局累加操作。accumulator被广泛用于记录应用运行参数。
val zqfAccum=sc.accumulator(0,”zqf test acculator”)
sc.parallelize(Array(1,2,3,4)).foreach(x=>zqfAccum +=x)
zqfAccum.value

若有收获,就点个赞吧
0 人点赞
